




2024-03-19 08:54

扫码打开虎嗅APP


作者丨李赓
头图丨视觉中国
英伟达,再次证明了自己独一无二的存在。
作为全球AI行业毫无疑问的“卖铲人”和“铺路人”,英伟达在今天凌晨召开的年度技术峰会GTC上再次展示了自己对于AI发展的“主权”。
简单概括下来,主要包括三点:再次跃升的性能;强悍的生态控制力;迫近兑现时刻的创新潜力。三者相互结合,再次巩固了英伟达在AI时代的统治力。
再次刷新天花板的无敌性能

左侧为全新的B200 GPU,右侧为H200 GPU
先说性能,在上一代Hopper架构发布两年之后,英伟达终于在这次GTC上发布了全新的
Blackwell架构。
从目前种种信息,包括黄仁勋自己的发言来看,Blackwell架构在计算模块上并没有和Hopper存在很大差异,最大的不同在于英伟达采用了类似苹果M系列处理器Ultra的双芯并联设计,用新增加的超高速链路将两颗芯片die通过芯片封装的手段“组合”成了一颗大GPU,从而让全新的B200 GPU实现了单颗GPU 2080亿晶体管的超大规模,再配合多达192GB的HBM3e显存,让B200 GPU直接成为了目前全球最强劲的GPU芯片。
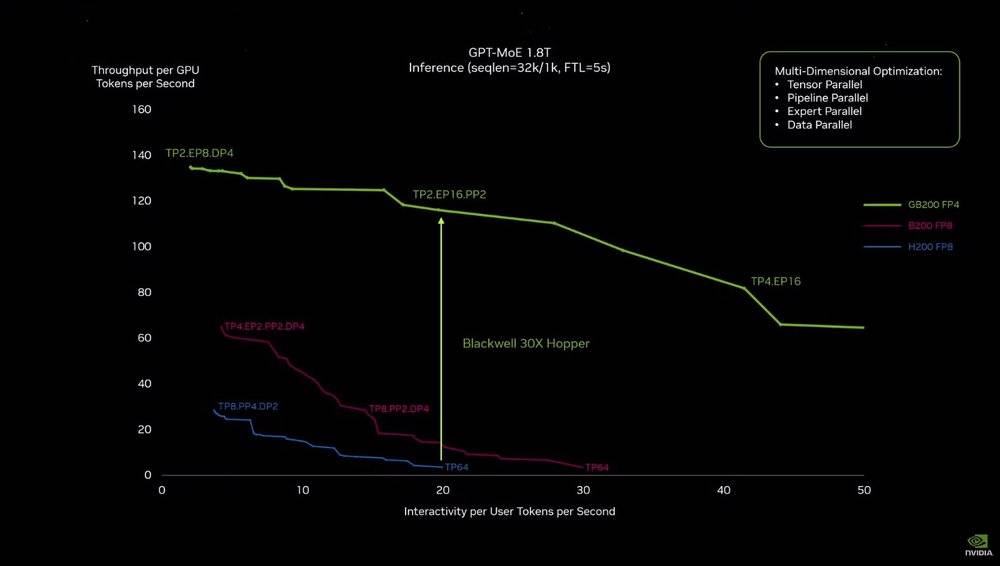
GB200和上一代计算模块的性能曲线差距
但在参数之外,其实际性能的提升却要明显的多:就拿大语言模型推理的实际应用场景来说,将两个Blackwell GPU和一个Grace CPU结合在一起的GB200模块,能够比上一代H200 GPU性能高足足30倍。
性能的提升,直接转化为了功耗的下降,根据英伟达官方给出的参考:同样是在90天内训练出GPT
-MoE 1.8万亿参数模型,Hopper架构的超级计算机需要8000个GPU和15兆瓦的电力,而Blackwell只需要2000个GPU和4兆瓦的电力。

GB200 NVL72机架
在明显更集中的规模和更低的耗能之外,英伟达还再次提升了他们芯片部署的解决方案:不仅将GB200模块设计为极其紧凑的堆叠结构,同时还配上了新一代直接让576个GPU相互连接、双向带宽达到每秒1.8TB的NVLink交换机,结合5000条近两英里长的各种电缆,最终打造成为将36个CPU和72个GPU集成到一起的液冷机架。
这也是全球首个推理性能能够超越1exaflops的电脑机架,同时也是比GB200更大的一颗“GPU”。

GB200 DGX Superpod
而在这台超强机架的基础上,英伟达还能进一步扩大它的规模,拿被GB200“更新”的DGX Superpod(英伟达自己的超级计算机解决方案)来说,就由8套机架系统组成,总共拥有288个CPU、576个GPU、240TB内存和11.5exaflops的FP4计算能力。
这套系统最多还能进一步扩展至数万颗GB200规模,这些充沛的算力,全部通过英伟达自己的800Gbps网络设备连接在一起,形成更大规模的集群,也再次刷新了同类产品的性能上限。
黄仁勋在现场演讲时就自豪地表示:“亚马逊、Google、微软和甲骨文都已计划在其云服务产品中提供基于NVL72机架的产品。”可以预见,国外的云计算即将刮起新一轮的英伟达新GPU抢购潮。
充分发挥英伟达优势的新AI生态系统
早在AI还以自动驾驶为主旋律的时期,英伟达就已经开始向车企客户推广其云端服务解决方案。而为了满足AI大模型时代的模型共享、模型定制化、模型运行、云计算支持在内的一系列问题,英伟达在这次GTC上推出了全新的“英伟达推理微服务(NIM)”。
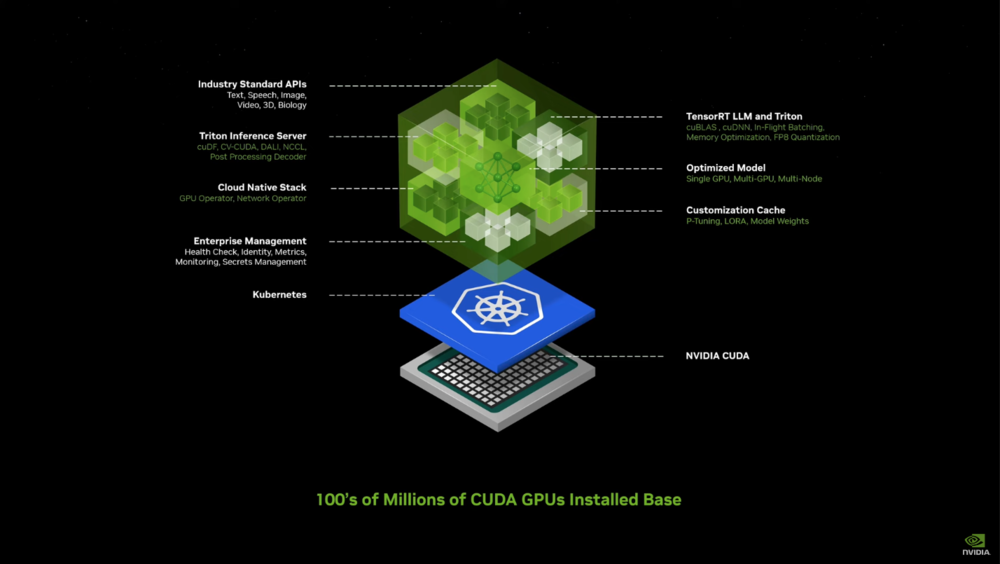
英伟达推理微服务(NIM)
NIM在构建的过程中,充分借鉴了K8S(Kubernetes)这些年的成功经验,将行业API,AI算法支持库、云端架构支持、AI算法加速、定制模型、定制存储、企业管理等诉求都注入到一个小的“容器”中,进而将AI模型的成果打包和部署过程高度简化。
如果说容器化的理念已经很可怕,那么更可怕的是这套解决方案,与目前AI行业智能体发展趋势的契合度。
早在去年,在ChatGPT能力之上二次开发的AutoGPT就曾大火过一波,当时AutoGPT的策略是通过ChatGPT的多次循环,实现对复杂目标的拆分和分散寻找答案。但随着后来的实践,整个行业其实已经看到了其能力的局限性——单靠语言大模型并不能解决所有问题。
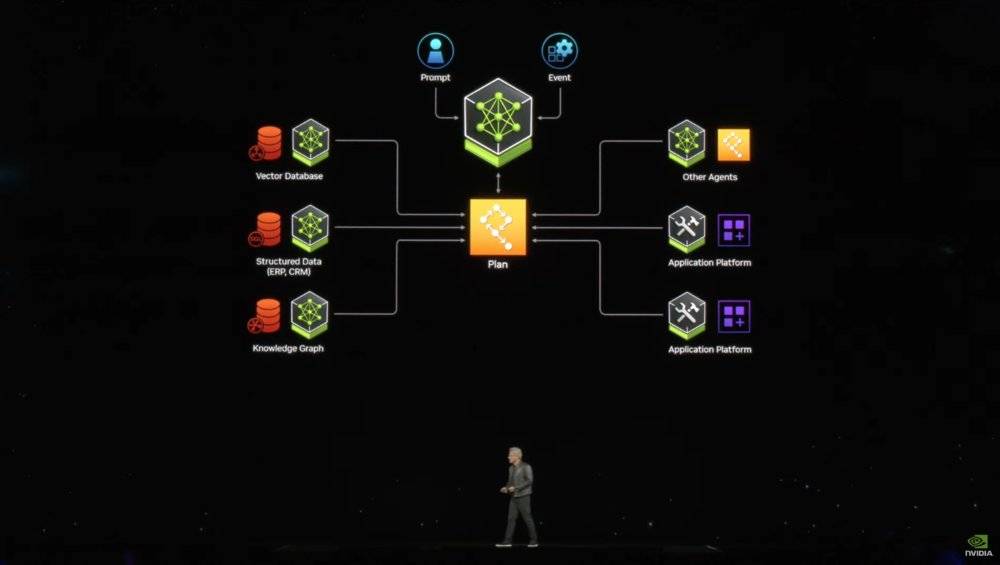
NIM应用运行模式构想
而目前行业内比较赞同的解决方案,就是在不断提升基础大模型能力的基础上,不断针对小的场景,提供专门的数据和目标,优化出解决一些问题的模型,也可以叫做“智能体”。通过这些“智能体”数量和覆盖的累积,以及基础大模型的调度能力,最终让AI实现“自我计划、自我协调”的进阶人工智能水平。更形象的说,就是一个输入框解决用户的绝大部分需求。
而持续为云端提供充沛AI运行能力的英伟达,显然有推进这套机制的资本。
在有望加速全行业AI应用落地之余,英伟达的这套NIM体系,还将把各种有潜力的AI模型和应用,紧紧地绑定在英伟达有着明显优势的云端算力性能和成本之上,进一步对抗由智能手机厂商发起的端侧攻势,让其紧握远期实现通用人工智能(AGI)的先机。
根据英伟达官方目前公布的计划,NIM体系将在NVIDIA AI企业版中首发,虽然NIM本身不收费,但是NVIDIA AI企业版收费不低,单GPU的使用权限包年就需要4500美金,小时租金为1美元每小时。
迫近兑现、充满潜力的其他应用创新
在本次GTC之上,除了芯片和硬件解决方案的更新,还有AI生态上的全新想法,英伟达也按照惯例展开了几个应用层面的创新案例。但如果你看过前几年的GTC,你肯定会觉得有点眼熟。

数字孪生地球台风气象模拟
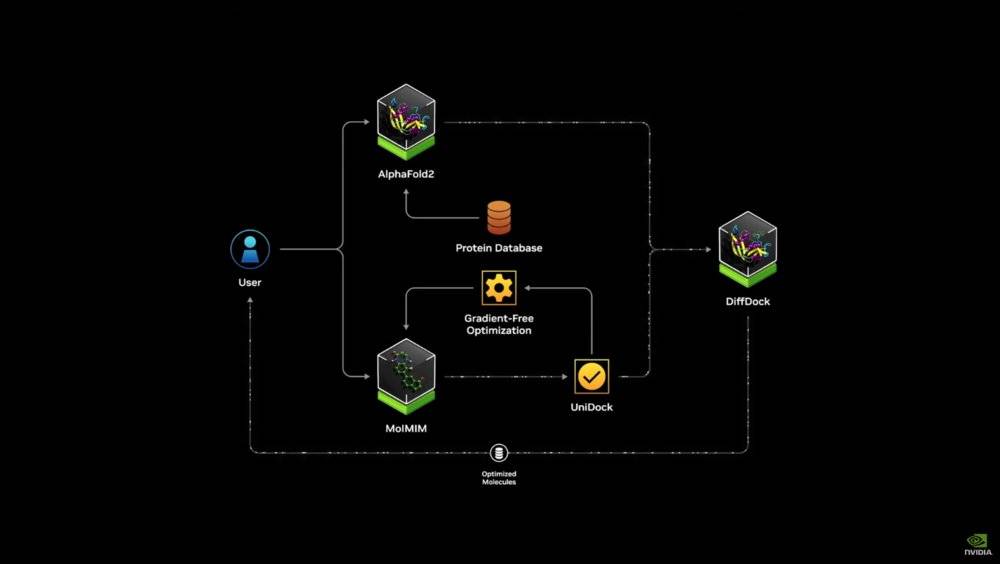
全新升级的蛋白质定制解决方案DiffDock

进一步由更强大计算能力和算法武装的机器人/自动驾驶生态
例如通过更大的AI算力,在更大的尺度上对全球的天气进行学习预测,进而对台风等突发天气实现2公里精度的实时预测;又比如已经探索了很多年的蛋白质折叠研究;还有机器人领域的全生态尝试等等。
这些“旧”赛道在AI能力的提升下,其实都展现出了一定的新成果。
就拿机器人来说,英伟达此次全新推出了人形机器人基础模型Project GR00T,不仅可以通过人类的语言、视频和真实演示(传感器)来学习人类动作,还能够在GPU模拟的虚拟世界中,通过AI的自我摸索来进行动作的训练。
随着AI集群的能力不断提升,虚拟世界中的模拟复杂度已经从最早期的单机械手上升到人形机器人整体。很显然,其实用价值也在随着计算能力、AI能力不断跃升。
写在最后
英伟达之所以如此强大,主要体现在“远见”之上。尤其是持续依靠“前沿技术+下重注”引领全行业技术进步,持续享受到技术变革、产品变革的红利。
就拿这次英伟达全新打造的GPU来说,能够如期更新,必然和英伟达自己主动将AI应用于芯片研发制造流程中有着紧密的关联。因为就在今天,台积电和新思科技(EDA巨头之一)已经宣布将使用英伟达的计算光刻技术,通过集成的英伟达cuLitho平台来加快芯片制造速度。
考虑到英伟达针对未来的布局实在众多,例如这次发布会上也被提到的“Earth Two”数字孪生地球项目,量子计算SDK(软件开发工具包)“cuQuantum”等,蛋白质定制研发工具Diffdock,人形机器人项目Project GR00T,6G城市研究云平台等等。
这些技术变革带来的红利,仍将支撑英伟达继续坐稳全球AI行业,乃至整个科技行业的龙头。

