2024-03-29 20:41


扫码打开虎嗅APP


本文来自微信公众号:海外独角兽 (ID:unicornobserver),作者:Matthias Plappert,编译:Siqi、Lavida、Tianyi,原文标题:《Sora的算力数学题》,题图:由Sora生成
在上个月推出视频生成模型 Sora 后,就在本周,OpenAI 又发布了一系列创意工作者借助 Sora 进行的创作,效果极为惊艳。毫无疑问,就生成质量,Sora 是迄今为止最强的视频生成模型,它的出现不仅会直接对创意行业带来冲击,也会影响对机器人、自动驾驶领域的一些关键问题的解决。
虽然 OpenAI 发布了 Sora 的技术报告,但报告中关于技术细节的呈现极为有限,本文编译自 Factorial Fund 的 Matthias Plappert 的研究,Matthias 曾在 OpenAI 任职并参与了 Codex 项目,在这篇研究中,Matthias 探讨了 Sora 的关键技术细节、模型的创新点是什么又会带来哪些重要影响外,还分析了 Sora 这样的视频生成模型对算力的需求。Matthias 认为,随着视频生成的应用越来越广泛依赖,推理环节的计算需求一定会迅速超过训练环节,尤其对于 Sora 这样的 diffusion-based 模型。
根据 Matthias 的估算,Sora 在训练环节对算力需求就是 LLM 高出好几个倍,大约需要在 4200-10500 张 Nvidia H100 上训练 1 个月,并且,当模型生成 1530 万到 3810 万分钟的视频后,推理环节的计算成本将迅速超过训练环节。作为对比,目前用户每天上传到 TikTok 的视频为 1700 万分钟,YouTube 则为 4300 万分钟。OpenAI CTO Mira 在近期的一个访谈中也提到,视频生成的成本问题也是 Sora 暂时还不能对公众开放的原因,OpenAI 希望做到和 Dall·E 图片生成接近的成本之后再考虑开放。
OpenAI 近期发布的 Sora 凭借极为逼真的视频场景生成能力震惊了世界。在这篇文章中,我们将深入讨论 Sora 背后的技术细节,这些视频模型的潜在影响以及我们当下的一些思考。最后,我们还将分享我们关于训一个 Sora 这样的模型所需要的算力,并展示与推理相比,训练计算的预测情况,这对于预估未来 GPU 需求具有重要的意义。
由 Shy Kids 使用 Sora 创作的创意短片 Air Head
核心观点
本篇报告中的核心结论如下:
• Sora 是一个 diffusion model,它是基于 DiT 和 Latent Diffusion 训练而成的,并且在模型规模和训练数据集上进行了 scaling;
• Sora 证明了 scale up 在视频模型中的重要意义,并且持续地 scaling 会是模型能力提升过程中的主要驱动力,这一点和 LLM 类似;
• Runway、Genmo 和 Pika 这些公司正在探索在 Sora 这样的 diffusion-based 视频生成模型上来构建直观的界面和工作流,而这将决定模型的推广和易用性;
• Sora 的训练对算力规模的要求巨大,我们推测需要在 4200-10500 张 Nvidia H100 上训练 1 个月;
• 在推理环节,我们预估每张 H100 每小时最多能生成 5 分钟左右时长的视频,Sora 这类 diffusion-based 模型的推理成本要比 LLM 高出好几个量级;
• 随着 Sora 这样的视频生成模型被大范围推广应用,推理环节将超过模型训练称为计算量消耗的主导,这里的临界点位于生产 1530 万到 3810 万分钟的视后,此时在推理上花费的计算量将超过原始训练的计算量。作为对比,用户每天上传到 TikTok 的视频为 1700 万分钟,YouTube 则为 4300 万分钟;
• 假设 AI 已经在视频平台上被充分应用,比如在 TikTok 上已经有 50% 的视频由 AI 生成、YouTube 上 15% 的视频由 AI 生成。考虑到硬件使用效率和使用方式,我们估算在峰值需求下,推理环节需要约 72 万张 Nvidia H100。
总的来说,Sora 不仅代表了视频生成质量和功能上的重大进步,也预示着在未来可能会大幅增加推理环节对 GPU 的需求。
一、背景
Sora 是一个 diffusion 模型,diffusion 模型在图片生成领域的应用很普遍,比如 OpenAI 的 Dall-E 或者 Stability AI 的 Stable Diffusion 这些代表性的图片生成模型都是 diffusion-based,而 Runway、Genmo 以及 Pika 等最近出现的探索视频生成的公司,大概率也都是用了 diffusion 模型。
广义上讲,作为一种生成模型,diffusion model 是通过逐步学会逆转一个给数据增加随机噪声的过程,从而学会创造出与其训练数据,比如图像或视频,相似数据的能力。这些模型最初从完全的噪声开始,逐步去除噪声,并细化图案,直到它变成连贯且详尽的输出。

扩散过程的示意图:噪声逐步被移除,直至详细的视频内容显现
Source: Sora 技术报告
这个过程和 LLM 概念下模型的工作方式存在明显不同:LLM 是通过迭代依次生成一个接一个的 token,这个过程也被称为自回归 sampling。一旦模型生成了一个 token,它就不会再改变,我们在使用 Perplexity 或者 ChatGPT 这类工具时就能看到这个过程:答案是一字一字出现的,就像有人在打字一样。
二、Sora 的技术细节
在发布 Sora 的同时,OpenAI 也公布了一份关于 Sora 的技术报告,但报告中并没有呈现太多细节。不过,Sora 的设计似乎很大程度上受到了 Scalable Diffusion Models with Transformers 这篇论文的影响。在这篇论文中,2 位作者提出了一种名为 DiT 的用于图片生成的 Transformer-based 架构,Sora 看起来是将这篇论文的工作拓展到了视频生成领域。结合 Sora 的技术报告和 DiT 这篇论文,我们基本可以准确梳理出 Sora 的整个逻辑。
关于 Sora 的三个重要信息:
1. Sora 没有选择在 pixel space(像素空间)层面工作,而是选择在 latent space(潜空间,也称为 latent diffusion)中进行扩散;
2. Sora 采用了 Transformer 架构;
3. Sora 似乎使用了一个非常大的数据集。
细节 1: Latent Diffusion
要理解上面的第一点提到的 latent diffusion 可以先来想一个图片是如何被生成的。我们可以通过 diffusion 来生成每一个像素点,但这个过程会相当低效,举例来说,一张 512x512 的图像就有 26 万 2144 个像素。但除了这个方式,我们还可以选择先把像素转化为一个压缩后的潜在表示(latent representation),然后再在这个数据量更小的 latent space 上进行扩散,最后再将扩散后的结果转换回像素层。
这种转换过程能够显著降低计算复杂度,我们不再需要处理 26 万 2144 个规模的 pixle,只需处理 64x64=4096 个 latent representation 即可。这个方法是 High-Resolution Image Synthesis with Latent Diffusion Models 的关键突破,也是 Stable Diffusion 的基础。

将左图的像素映射成右图中网格代表的潜在表示
Source: Sora 技术报告
DiT 和 Sora 都用到了 latent diffusion,对于 Sora 来说,还需要额外考虑的是,视频具有时间维度:视频是一系列图像的时间序列,我们也称其为帧。通过 Sora 的技术报告我们可以看出,从像素层到 latent sapce 的编码既发生在空间层面,即压缩每个帧的宽度和高度,也发生在时间维度,即跨时间压缩。
细节 2: Transformer 架构
关于第二点,DiT 和 Sora 都用最基础的 Transformer 架构取代了被普遍使用的 U-Net 架构。这一点相当关键,因为 DiT 的作者们发现,通过使用 Transformer 架构可以出现可预测的 scaling :随着技术量的增加,不论模型训练时间增加还是模型规模变化,或者二者皆有,都能让模型能力提升。Sora 的技术报告中也提到了同样的观点,只不过是针对视频生成场景,并且报告中还附上了一个直观的图示。

模型质量随着训练计算量的增加而提高:从左到右分别为基础计算量、4倍计算量和32倍计算量
这种 scaling 的特性能够被我们常说的 scaling law 所量化,这也是一个很重要的属性。在视频生成之前,无论是在 LLM 的语境下,还是其他模态中的 autoregressive model,scaling law 都被研究过。能够通过 scale 来获得更好的模型是推动 LLM 迅速发展的关键动力之一。由于图像和视频生成也存在 scaling 的属性,我们应该期待 scaling law 在这些领域同样适用。
细节 3:Dataset
要训练一个 Sora 这样的模型,最后还要考量的一个关键因素是被标注的数据。我们认为,数据环节包含了绝大部分 Sora 的秘密。要训一个 Sora 这样的 text2video 的模型,我们需要视频和其对应的文本描述的配对数据。OpenAI 并没有太多讨论数据集,但他们也暗示了这个数据集很大,在技术报告中,OpenAI 提到:“基于互联网级数据上的训练,LLM 获得了通用能力,我们从这件事上得到了启发”。

Source: Sora 技术报告
OpenAI 还公布了一种用详细文本标签为图像注释的方法,这种方法被用来收集 DALLE-3 数据集,简单来说,这个方法是在数据集的一个带标签的子集上训练一个标注模型(captioner model),然后再使用这个模型来自动完成对其余数据贴的标注。Sora 的数据集应该也用到了类似技术。
三、Sora 的影响
1. 视频模型开始被应用到实际中
在细节和时间连贯性角度,Sora 生成的视频质量毫无疑问是很重要的突破,例如,Sora 可以正确处理视频中的物体暂时被遮挡时保持不动,并且能够准确生成水面反射效果。我们相信,Sora 目前的视频质量对于特定类型的场景已经足够好了,这些视频可以被用到某些现实世界的应用中,比如 Sora 可能很快就会取代一些对视频素材库的需求。
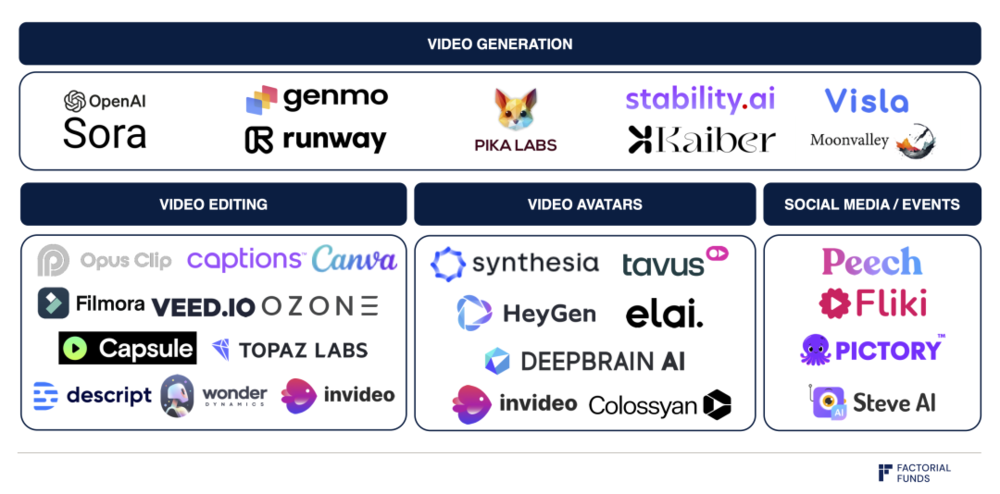
视频生成领域图谱
不过,Sora 依旧还面临一些挑战:我们目前还不清楚 Sora 的可控性如何。因为模型输出的是像素,所以编辑一个生成出的视频内容相当困难且耗时的。要让模型变得有用,围绕视频生成模型搭建出直观的 UI 和工作流也很必要。如上图所示,Runway、Genmo 和 Pika 以及其他视频生成领域的公司已经在解决这些问题了。
2. 因为 Scaling ,我们可以加快对视频生成的预期
我们在前面讨论到,DiT 这篇研究中的一个关键结论是模型质量会随着计算量的增加直接得到提升。这一点和我们已经在 LLM 中观察到的 scaling law 很相似。我们因此也可以期待,随着模型在更多计算资源上得到训练,视频生成模型质量会迅速得到进一步提升。Sora 很有力地验证了这一点,我们预计 OpenAI 以及其他公司都会在这方面加倍投入。
3. 合成数据生成与数据增强
在机器人以及自动驾驶等领域,数据本质上还是一种稀缺资源:在这些领域没有一个到处都是机器人帮忙干活或者开车的“互联网”一般的存在。通常情况下,这两个领域的一些问题主要是通过在模拟环境中训练、在现实世界中大规模收集数据来解决,或同时结合两者。然而,这两种方法都存在挑战,因为模拟数据往往是不符合现实的,而在现实世界中大规模收集数据的成本非常高,并且收集足够多小概率事件的数据也具有挑战。

如上图所示,可以通过修改视频的一些属性来增强视频,如将原始视频(左)渲染成茂密丛林环境(右)Source: Sora 技术报告
我们相信,像 Sora 这样的模型在这些问题上可以发挥作用。我们认为,Sora 这类模型有可能被直接用来生成 100% 合成的数据。Sora 还可以被用来进行数据增强,也就是将对现有视频的展现方式进行各种各样的转换。
这里提到的数据增强实际上已经可以通过上面的技术报告中的示例来说明了。原始视频中,一辆红色汽车行驶在一条森林道路上,经过 Sora 的处理,视频变成了汽车在热带丛林的道路上行驶。我们完全可以相信使用同样的技术再渲染,还可以实现昼夜场景转变,或者改变天气状况。
4. 模拟和世界模型
“世界模型(World Models)”是一个很有价值的研究方向,如果模型足够准确,这些世界模型可以让人们直接在其中来训练 AI agent,又或者这些模型可以被用来规划和搜索。
像 Sora 这类模型以一种隐式学习(implicitly learning)的方式从视频数据中学习到了对现实世界运作方式的基本模型。虽然这种“涌现式模拟(emergent simulation)“目前存在缺陷,但仍旧让人感到兴奋:这件事表明我们也许可以通过大规模地使用视频数据来训练世界模型。此外,Sora 似乎还能够模拟非常复杂的场景,比如液体流动、光的反射、纤维和头发的运动等。OpenAI 甚至将 Sora 的技术报告命名为 Video generation models as world simulators ,这清楚地表明他们相信这是模型会产生影响的最重要的方面。
最近,DeepMind 在自己的 Genie 模型中也展示了类似的效果:只通过在一系列游戏视频上训练,模型就学会了模拟这些游戏,甚至创造新的游戏的能力。在这种情况下,模型甚至能够在没有直接观察到行为的情况下,学会根据行为来调整自己的预测或决策。在 Genie 的例子中,模型训练的目标仍旧是能在这些模拟环境中进行学习。

视频来自 Google DeepMind 的 Genie: Generative Interactive Environments 介绍
综合来看,我们相信,如果要在现实世界任务基础上去大规模训练类似于机器人这类具身 agents , 像 Sora 和 Genie 这样的模型一定能够发挥。当然,这种模型也有局限性:因为模型是在像素空间中训练的,模型会模拟每一个细节,包括视频中的风吹草动,但是这些细节和当前的任务完全无关。虽然 latent space 是经过压缩的,但它仍然需要保留很多这类信息,因为需要保证能够映射回 pixel,所以目前还不清楚在 latent space 中是否能有效地进行规划。
四、算力估算
我们很关注模型训练和推理过程中分别对计算资源的需求,这些信息可以帮助我们去预测未来需要多少计算资源。不过,因为有关 Sora 的模型大小和数据集的详细信息非常少,要估算出这些数字也很困难。所以我们在这一板块的估算并不能真正反映实际情况,请审慎参考。
1. 基于 DiT 推演 Sora 的计算规模
关于 Sora 的详细细节相当有限,但我们可以再次回顾下 DiT 这篇论文,并参照 DiT 论文中的数据来推断 Sora 所需的计算量的信息,因为这篇研究很显然是 Sora 的基础。作为最大的 DiT 模型,DiT-XL 有 6.75 亿个参数,并使用了大约 1021 FLOPS 的总计算资源进行训练。为了方便理解这个计算量的大小,这个计算规模相当于使用 0.4 个 Nvidia H100 运行 1 个月,或者单张 H100 运行 12 天。
目前,DiT 只用于图片生成,但 Sora 是一个视频模型。Sora 最长可以生成 1 分钟的视频。如果我们假设视频的编码帧率为 24 帧每秒(fps),那么一个视频就包含多达 1440 帧。Sora 从 pixel 到 latent space 的映射中对时间和空间维度都同时进行了压缩,假设 Sora 使用的是和 DiT 论文中相同的压缩率,即 8 倍压缩,那么在 latent space 中就有 180 帧,因此,如果我们把 DiT 的数值进行简单的线性外推到视频上,就意味着 Sora 的计算量是 DiT 的 180 倍。
此外,我们相信 Sora 的参数量远超 6.75 亿,我们预估,200 亿规模的参数量也是有可能的,这意味着从这个角度,我们又得到了 Sora 的计算量是 DiT 30 倍的猜测。
最后,我们认为训练 Sora 所使用到的数据集比 DiT 用到的要大得多。DiT 在 256 的 batch size 下训练了 300 万个步骤,也就是总共处理了 7.68 亿张图像。不过需要注意的是,由于 ImageNet 只包含了 1400 万张图像,所以这里涉及到相同数据的多次重复使用。Sora 似乎是在一个图像和视频的混合数据集上进行的训练,但我们对数据集的具体情况几乎一无所知。因此,我们先简单假设 Sora 的数据集是由 50% 的静态图像和 50% 的视频组成的,并且这个数据集比 DiT 使用的数据集大了 10~100 倍。不过,DiT 对相同的 datapoint 进行了重复训练,在存在一个可用的、更大规模的数据集的情况下,DiT 的这种做法可能是次优的。因此,我们把计算量增加的乘数给到 4 到 10 倍更为合理。
综合以上信息,同时考虑到我们对数据集计算规模不同水平的预估,可以得出以下计算结果:
公式:DiT 的基础计算量 × 模型增加 × 数据集增加 × 180 帧视频数据产生的计算量增加(只针对数据集当中的 50%)
• 对数据集规模保守预估情况下:1021 FLOPS × 30 × 4 × (180 / 2) ≈ 1.1×1025 FLOPS
• 对数据集规模乐观预估情况下:1021 FLOPS × 30 × 10 × (180 / 2) ≈ 2.7×1025 FLOPS
Sora 的计算规模相当于 4211 - 10528 张 H100 运行 一个月的计算量。
2. 算力需求:模型推理 VS 模型计算
另外一个我们去关注计算的重要部分是训练和推理环节计算量的对比。理论上讲,训练环节的计算量即便巨大,但训练成本是一次性的,只需要付出一次即可。相比之下,虽然推理相对于训练需要的计算更小,但模型每次生成内容时都会产生,并且还会随着用户数量的增加而增加。因此,随着用户数量的增加和模型的广泛使用,模型推理变得越来越重要。
因此,找到推理计算超过训练计算的临界点也很有有价值。
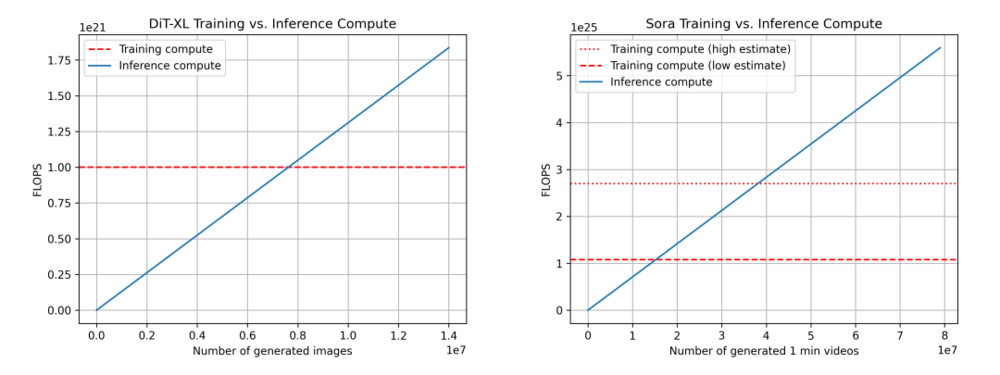
我们比较了 DiT(左)和 Sora(右)的训练与推理计算对比。对于 Sora,基于上述估计,Sora的数据并不完全可靠。我们还展示了两个训练计算的估计:一个低估计(假设数据集大小乘数为 4 倍)和一个高估计(假设数据集大小乘数为 10 倍)。
对于上述数据,我们再次使用 DiT 来推断 Sora 的情况。对于 DiT 来说,最大的模型 DiT-XL 每一步推理使用 524×109 FLOPS,而 DiT 使用生成一张图片会经过 250 步的 diffusion,即总共是 131×1012 FLOPS。我们可以看到,在生成 760 万张图片之后,最终达到了“推理-训练的临界点”,在此之后,模型推理开始占据计算需求的主导地位。作为参考,用户每天向 Instagram 上传约 9500 万张图片。
对于 Sora,我们推算出 FLOPS 为 524×109 FLOPS × 30 × 180 ≈ 2.8×1015 FLOPS。如果我们仍然假设每个视频有 250 个 diffusion 步骤,那么每个视频的总 FLOPS 为 708×1015 FLOPS。作为参考,这大约相当于每小时每张 Nvidia H100 生成 5 分钟的视频。在对数据集做保守预估的情况下,达到“推理-训练临界点”需要生成 1530 万分钟的视频,在对乐观估计数据集规模的情况下,要达到临界点则需要生成 3810万分钟 的视频。作为参考,大约每天有 4300 万分钟的视频被上传到 YouTube。
此外还需要补充一些注意事项:对于推理来说,FLOPS 并不是唯一重要的。例如,内存带宽也是另外一个重要因素。此外,也有团队在积极研究减少 diffusion 的步骤,这也会带来模型计算需求的降低,也因此推理速度会更快。FLOPS 的利用率在训练和推理环节也可能有所不同,这也是一个重要考虑因素。
Yang Song, Prafulla Dhariwal, Mark Chen 和 Ilya Sutskever 在 2023 年 3 月发表了 Consistency Models 研究,研究指出 diffusion 模型在图像、音频和视频生成领域取得了重大进展,但是存在依赖迭代采样过程、生成缓慢等局限性。研究提出了一致性模型,允许多次采样交换计算,从而提高样本质量。
3. 不同模态模型推理环节的计算需求
我们还研究了不同模型在不同模态下每单位输出的推理计算变化趋势。研究目的是不同类别的模型中推理的计算密集度会增加多少,这对计算规划和需求有直接的影响。由于它们在不同模态中运行,每个模型的输出单位都不同:Sora 的单个输出是一个长达 1 分钟的视频,DiT 的单个输出是一张 512x512 像素的图像;而对于 Llama 2 和 GPT-4,我们定义的单个输出是一个包含 1000 个 Token 文本的文档(作为参考,平均每篇维基百科的文章大约有 670个 token)。
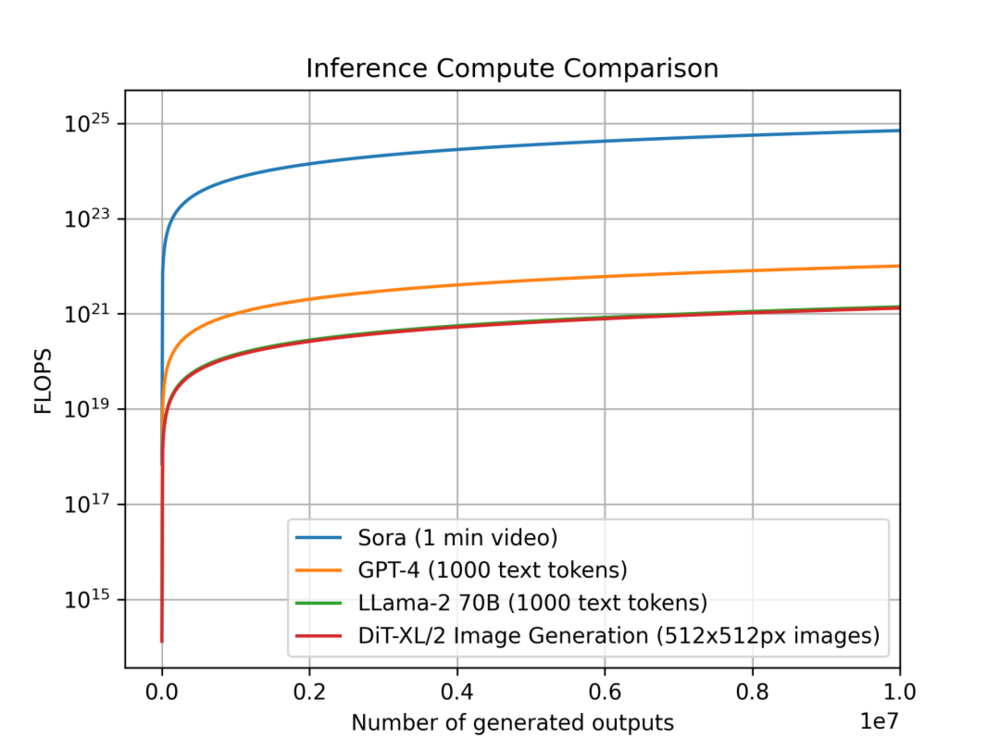
模型每个单位输出的推理计算对比:Sora 每单位输出 1 分钟视频, GPT-4 和 LLama 2 每单位输出 1000 个 Token 的文本, DiT 每单位输出一张 512x512px 的图像,图片显示出 Sora 的推理估计在计算上要多耗费几个数量级。
我们对比了 Sora、DiT-XL、LLama2-70B 和 GPT-4 ,并使用 log-scale 绘制了它们的 FLOPS 对比图。对于 Sora 和 DiT,我们使用上文中的推理估计,对于 Llama 2 和 GPT-4,我们基于经验选择用 “FLOPS = 2 × 参数量 × 生成的 Token 数量” 来做一个快速估算。对于 GPT-4,我们则首先假设模型是一个 MoE 模型,每个专家模型有 2200 亿参数,并且每次前向传播都会激活 2 个专家。需要指出的是,GPT-4 相关的数据并不是 OpenAI 确认的官方口径,仅作为参考。
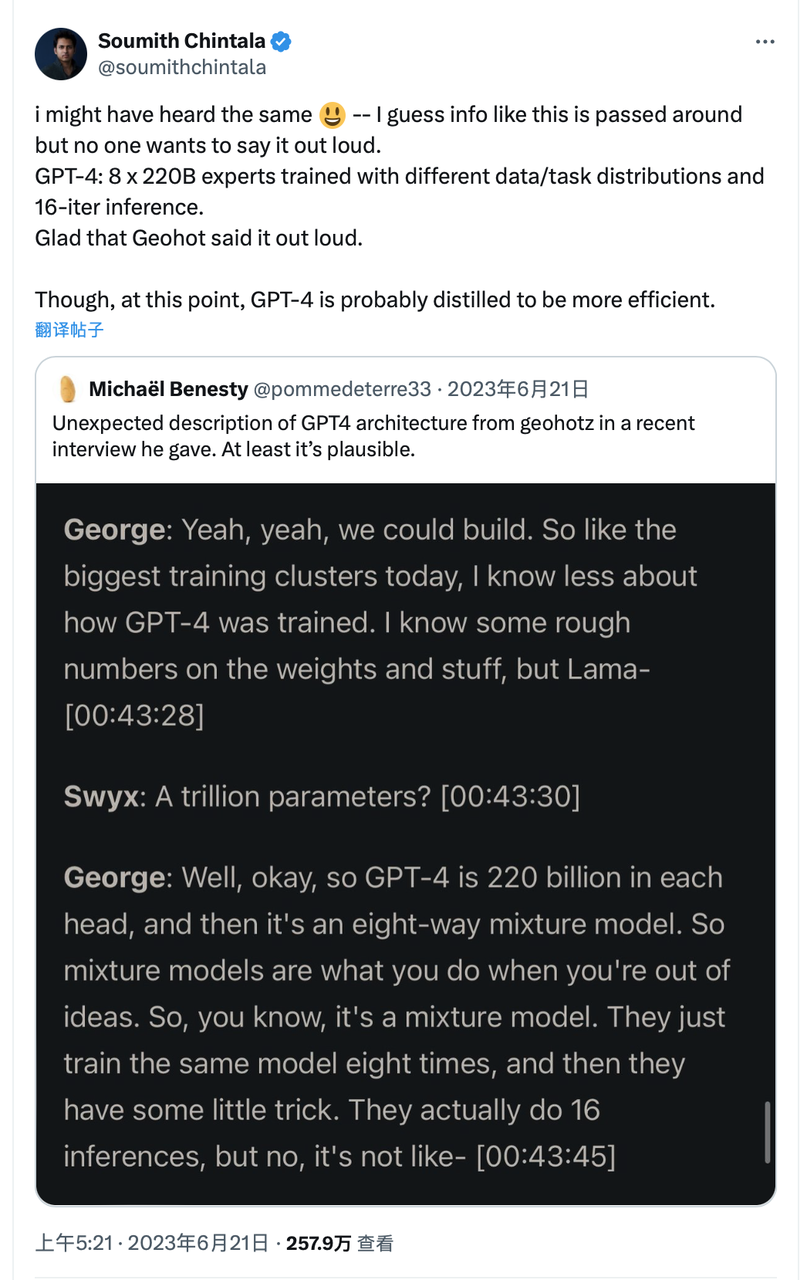
Source: X
我们可以看到,像 DiT 和 Sora 这样的 diffusion-based 的模型会在推理环节消耗更多算力:拥有 6.75 亿参数的 DiT-XL 在推理环节的消耗差不多和 700 亿参数的 LLama 2 相同。更进一步我们可以看到,Sora 的推理消耗比 GPT-4 还要高出好几个数量级。
需要再次指出,上述计算中使用到的很多数字都是估算的来,依赖于简化的假设。例如,它们没有考虑 GPU 的实际 FLOPS 利用率、内存容量和内存带宽的限制,以及像推测解码( speculative decoding )这种更进阶的技术方法。
当 Sora 得到大范围应用后的推理计算需求预测:
在这一部分,我们从 Sora 的计算需求出发,来推算:如果 AI 生成的视频在 TikTok 和 YouTube 这样的视频平台已经被大规模应用,为了满足这些需求,需要多少 Nvidia H100。
• 如上文,我们假设每张 H100 每小时可以制作 5 分钟的视频,相当于每张 H100 每天可以制作 120 分钟的视频。
• 在 TikTok 上:当前用户每天上传 1700 万分钟的视频(3400 万条总视频数 × 平均长度 30 秒),假设 AI 的渗透率为 50%;
• 在 YouTube 上:当前用户每天上传 4300 万分钟的视频,假设 AI 的渗透率为 15%(主要是 2 分钟以下的视频),
• 那么 AI 每天制作的总视频量:850 万 + 650 万 = 1500 万分钟。
• 需要支持 TikTok 和 YouTube 上创作者社区所需的总 Nvidia H100 数量:1500 万 / 120 ≈ 8.9 万张。
但 8.9 万张这个数值可能偏低,因为还需要考虑到下面的多种因素:
• 我们在推算中假设的是 100% 的 FLOPS 利用率,并没有考虑内存和通信瓶颈,50%的利用率会更符合实际,也就是说实际的 GPU 需求是我们估算数值的 2 倍;
• 推理需求并不是沿着时间线均匀分布,而是有突发性的,尤其还要考虑到峰值情况,因为需要更多的 GPU 来保证服务。我们认为,如果考虑峰值流量的情况,又要给 GPU 需求数量一个 2X 的乘数;
• 创作者可能会生成很多个视频再从中选择最好的一个上传,如果我们保守假设平均每个上传的视频都对应 2 次生成,则 GPU 需求量又要乘以 2;
• 总的来说,在峰值流量下,需要大约 72 万张 H100 才能满足推理需求。
这也验证了我们所坚信的,即随着生成 AI 模型变得越来越受欢迎并被广泛依赖,推理环节的计算需求将占据主导,对于像 Sora 这样的 diffusion-based 模型,这一点尤为明显。
同时还需要注意的是,模型的 scaling 也将进一步大幅推动推理计算的需求。不过另一方面,通过推理技术的优化以及其他对整个技术栈的优化方式,可以抵消部分这种增加的需求。

视频内容制作直接推动了对 Sora 这类模型的需求
本文来自微信公众号:海外独角兽 (ID:unicornobserver),作者:Matthias Plappert,编译:Siqi、Lavida、Tianyi
