
2024-04-17 14:17
无限上下文、2万亿token,它能干翻Transformer?

扫码打开虎嗅APP

本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,编辑:桃子、好困,原文标题:《革命新架构掀翻Transformer!无限上下文处理,2万亿token碾压Llama 2》,题图来自:视觉中国
继Mamba之后,又一敢于挑战Transformer的架构诞生了!
来自Meta、南加州大学(USC)、CMU和UCSD的研究人员提出了全新的神经网络架构——Megalodon(巨齿鲨)。
这是专为有效处理“无限上下文”长度的LLM预训练,以及推理而设计的架构。

论文地址:https://arxiv.org/abs/2404.08801
我们都知道,Transformer架构在处理长上下文时,会受到二次复杂度,以及长度外推能力弱的限制。
尽管已有二次方解决方案(诸如线性注意力,状态空间模型),但它们在预训练效率,甚至下游任务的准确率上,通常还不及Transformer。
Megalodon的出现,就是为了解决无限处理上下文的难题。
同时,它可以同时实现高效训练(减少通信和计算量),以及高效推理(保持恒定的KV缓存)。
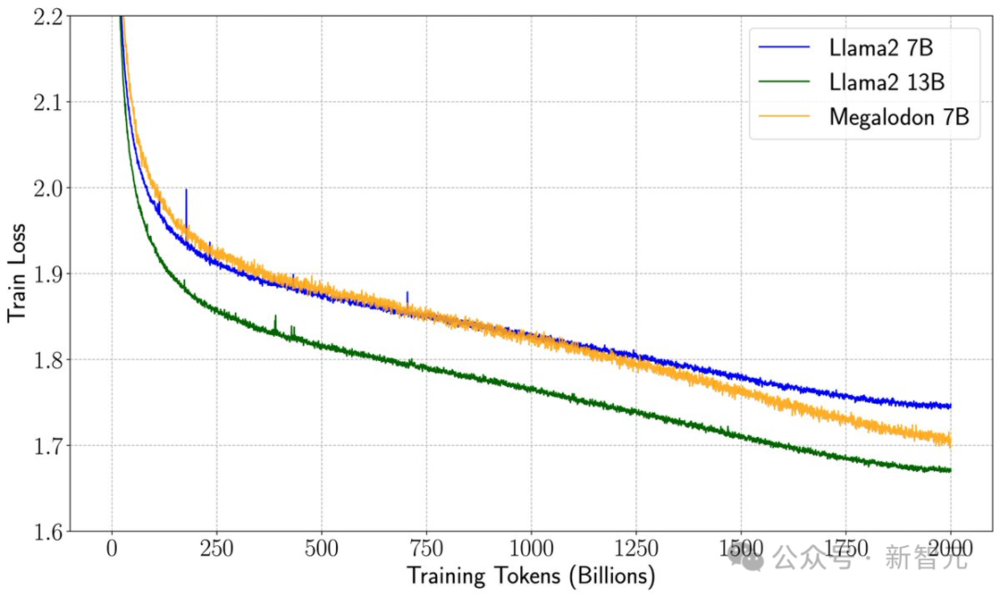
值得一提的是,在与Llama 2的直接比较中,Megalodon在处理70亿参数和2万亿训练token的任务上,不仅训练更高效,而且准确率也超过了Transformer。
具体来说,Megalodon的训练损失为1.70,位于Llama2-7B(1.75)和 13B(1.67)之间。
这一改变范式的创新代表着AI领域的巨大飞跃,Megalodon开启了计算效率和性能的新时代。
GPT-3发布以来最大的里程碑
网友表示,先是谷歌,又是Meta,无限上下文离我们更进一步,LLM将会释放出无限潜力。

还有人认为“无限上下文长度,绝对是游戏规则的改变者”。

更有甚者,初创公司CEO称,“这是自GPT-3发布以来最大的里程碑,但却没有任何动静?
Megalodon就相当于是AGI的基础”。
“Meta的Megalodon是一项突破性进展,对AGI具有重要意义。它的无限上下文长度模拟了人类的认知,实现了无缝任务切换”。

论文作者Hao Zhang表示,这是一种全新替代Transformer的架构。

论文作者Beidi Chen称,“注意力虽好,但你不需要完整的注意力机制”。

普林斯顿助理教授Tri Dao表示,“将SSM/RNN/EMA与注意力相结合是获得更高质量、更长上下文和更快推理的方法!Griffin、Jamba、Zamba和现在的Megalodon都是很好的例子”。

革命性架构,训练更稳定
那么,Megalodon架构采用了怎样的设计,才能取得如此优异的表现?
据介绍,它基于MEGA架构进行了改进,并新增了多个技术组件。
首先,复杂指数移动平均(CEMA)组件是一种全新技术,扩展了MEGA中使用的多维阻尼指数移动平均方法到复数域,可以增强模型处理复杂数据的能力。
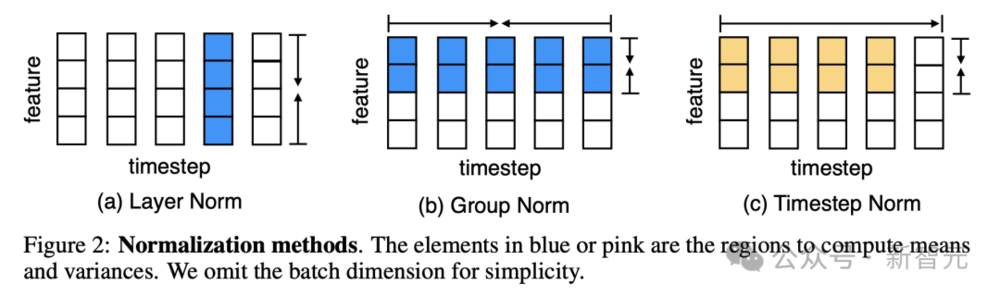
其次,研究人员提出了一种创新的归一化技术——“时间步归一化层”。
它将传统的组归一化技术扩展到自回归序列建模任务中,允许模型在处理序列数据时,进行有效的归一化。
以往,“层归一化”(Layer Normalization)与Transformer相结合性能,虽令人印象深刻。
但很明显,层归一化并不能直接减少时间步长或顺序维度的内部协变量偏移。
另外,“组归一化”(Group Normalization)虽比“层归一化”在CV任务中获得改进,但它却无法直接应用于Transformer的自回归序列建模,因未来信息会通过时间步维度的均值和方差泄漏。
如下图所示,c展示了Megalodon架构中,层标准化和时间步标准化的方法。
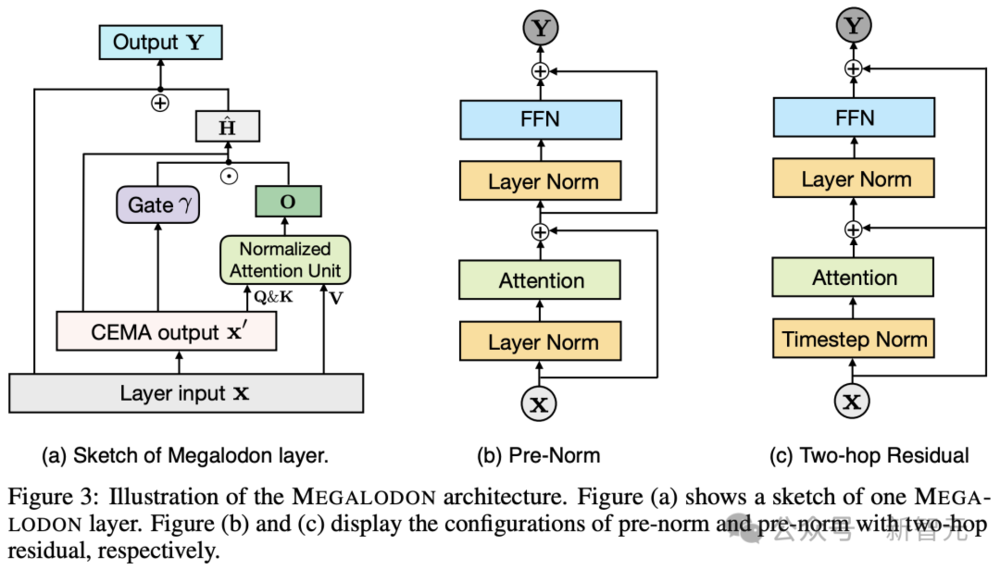
最后,研究人员为了增强大规模LLM预训练的稳定性,提出了将归一化注意力,和带有两跳残差的预归一化相结合的配置。
这种配置可以优化模型的学习过程,提高训练的稳定性。
下图3中,a是Megalodon的完整框架草图。
中间和右边两张图分别介绍了,预归一化和带有两跳残差预归一化的配置。
2T token训练,性能超越Llama2-7B
在具体实验评估中,研究人员将Megalodon扩展到70亿参数规模,并将其应用于2万亿token的大规模LLM预训练中。
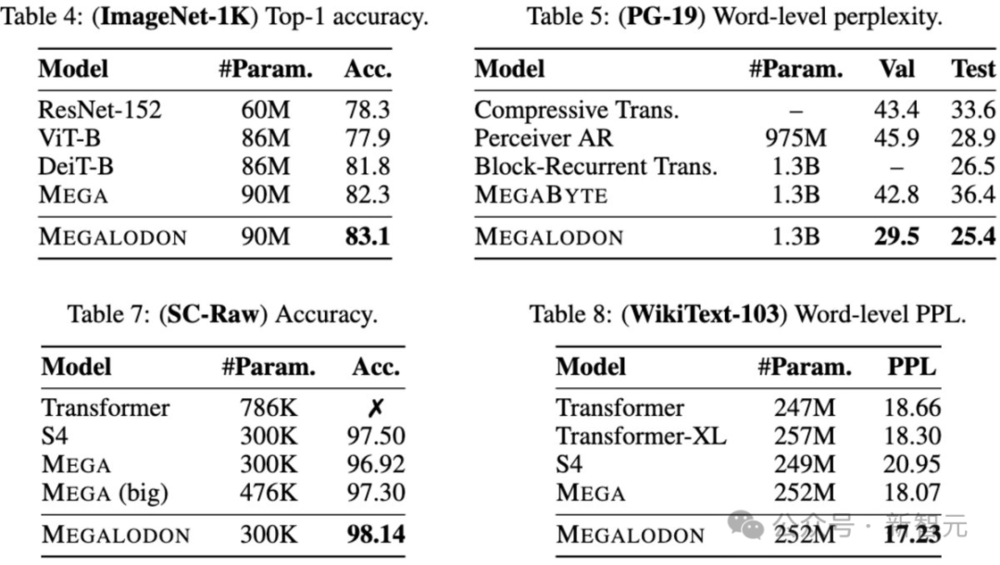
此外,作者还在中/小参数规模的序列建模基准上进行了实验,包括Long Range Arena(LRA)、Speech Commands上的原始语音分类、ImageNet-1K上的图像分类,以及WikiText-103和PG19上的语言建模。
结果显示,在这些任务中,Megalodon在各种数据模式下的表现明显优于所有最先进的基线模型。
数据学习效率
通过训练损失图以及多个benchmark的结果可以看出,Megalodon比Transformer在7B参数下有更好的数据学习效率。
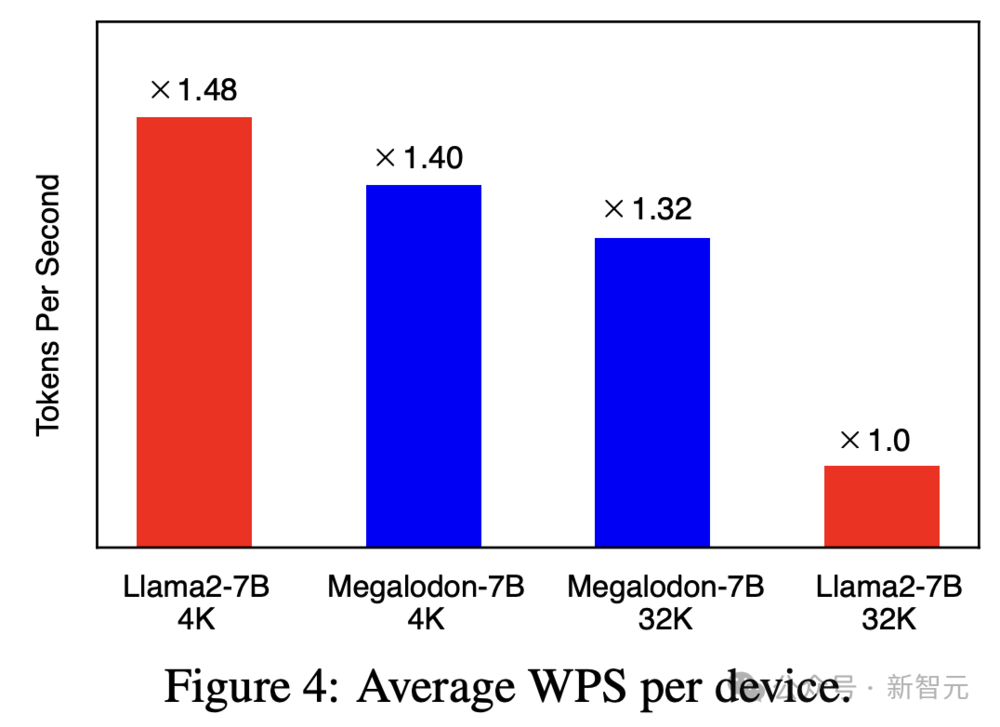
计算效率
针对不同的4K和32K上下文长度,Megalodon这一架构的预训练的计算效率也是非常强的。
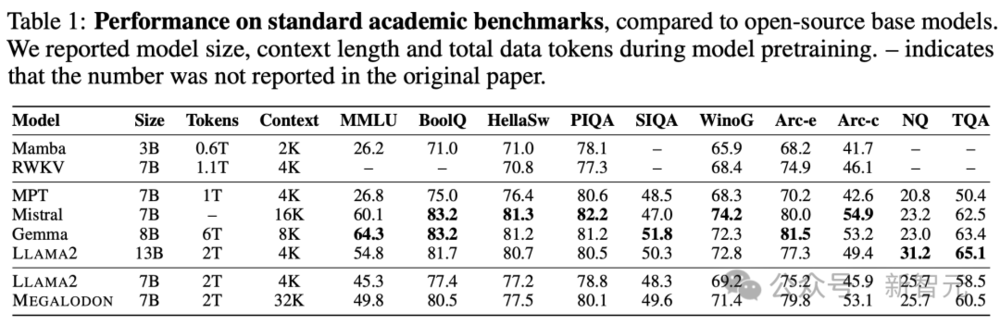
学术基准短上下文评估
具体来说,研究人员在短上下文(4K token)的标准学术基准上,对Megalodon和Llama 2,以及开源基础模型进行了比较。
在相同的2万亿token训练后,Megalodon-7B的表现明显优于Llama2-7B。
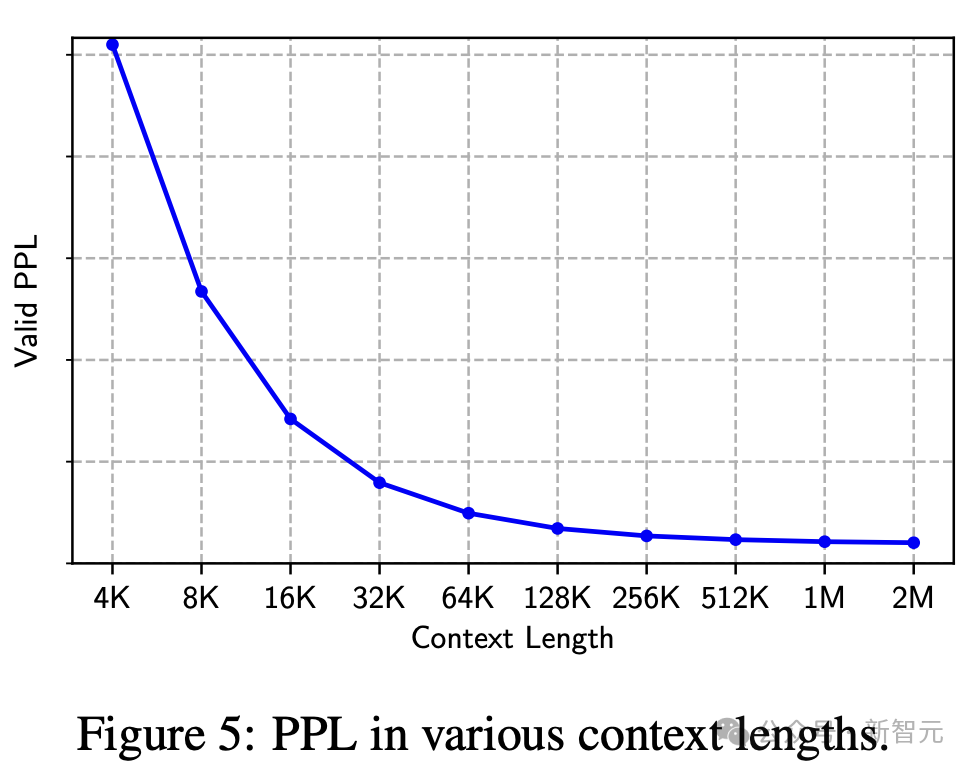
长上下文评估
针对不同长上下文的困惑度,证明了Megalodon可以利用很长的上下文进行下一个token预测的能力。
图5显示了,验证数据集在4K到2M各种上下文长度下的困惑度(PPL)。
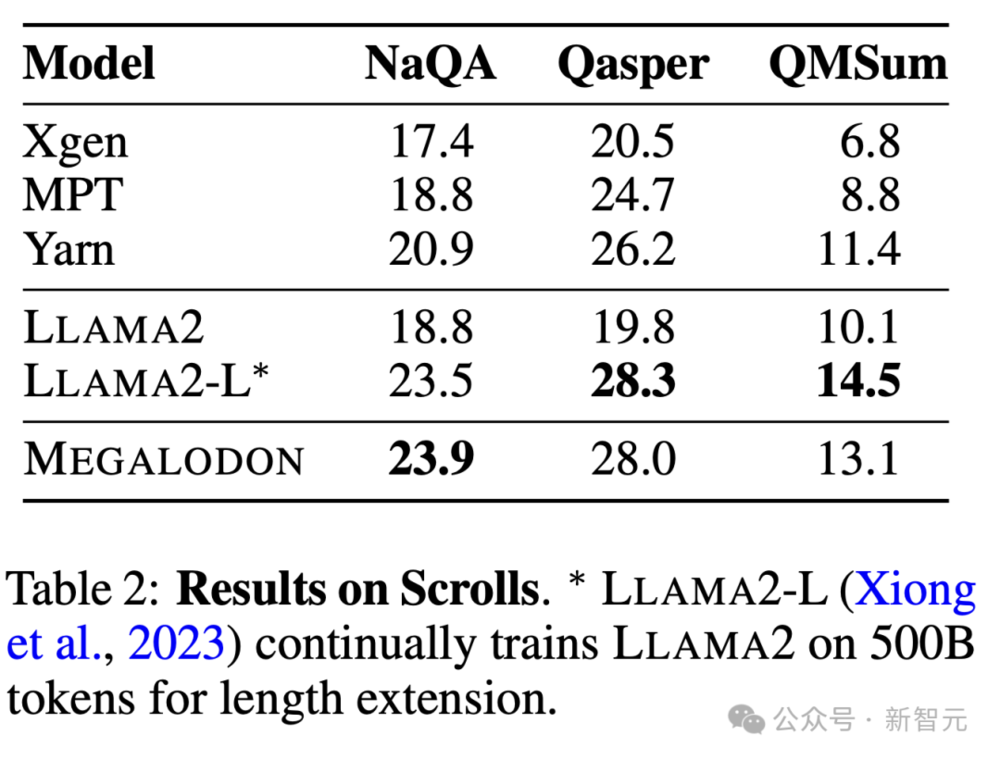
在Scroll数据集中的长上下文QA任务中,Megalodon在NaQA上获得最佳F1,并与Llama 2 Long相竞争。
中等规模基准评估
在Long Range Arena(LRA)的测试中,新架构显著缩小了分块注意力和全注意力之间的性能差距。
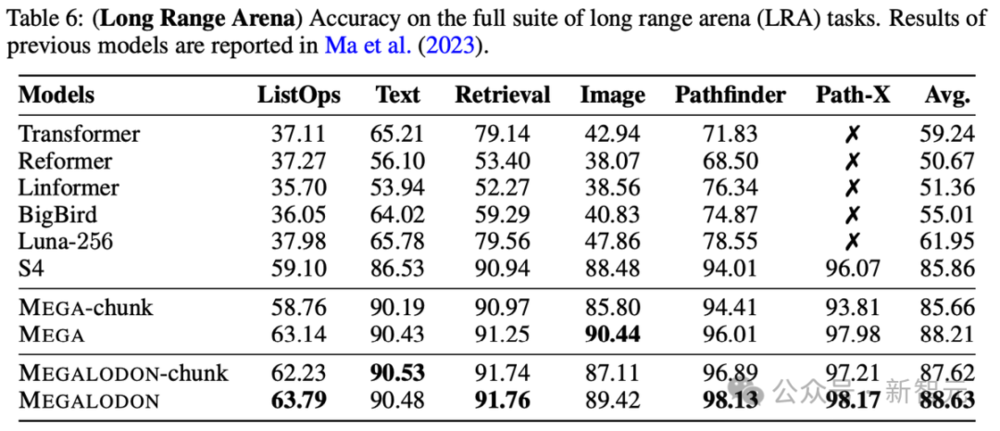
其他评测集,如原始语音分类、ImageNet-1K、WikiText-103和PG-19的结果如下:
一些感想
这里quote一下这项研究原作者的一些感悟和经历:
这个工作从有想法到最终完成,经历了近两年的时间。期间经历数次失败,也学习到了很多大规模预训练时代正确做科研的方法。

通过这个项目,研究者们也体会到了在大模型时代做新的模型架构时要注意的问题。总结来说:
对于两个不同模型架构的比较必须要在数据完全相同的条件下才有说服力。当数据不同的时候,哪怕不同的比例很小(<10%),最后的结果也可能有明显的差别。包括training loss和下游任务的结果,都受到训练数据的很大影响。
对于不同的架构,一定要在模型得到充分训练的条件下的比较才有意义。例如对于7B大小的模型,2T的训练数据几乎是基本要求。有的模型可能在数据少的时候表现得很好,但是数据规模增大后反而落后其他模型。因此,对于大模型架构的比较,结果有说服力的前提是充分的训练。
对于架构差别很大的模型,传统的基于flops的scaling law的比较意义在降低。原因是两个不同架构的模型,即使有相同的flops,他们的实际速度可能差几倍。这个和架构算法本身是不是适合在最先进的GPU上计算有很大的关系。因此,真正贴合实际的比较方法是像本文中那样分成数据学习效率和计算效率两个方面。但是这样在实际中对于研究员的工程能力有很高的要求。在大模型时代,新算法的开发已经和系统等方面高度结合在一起。
参考资料:
https://arxiv.org/abs/2404.08801
https://zhuanlan.zhihu.com/p/692682649
本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,编辑:桃子、好困

 04:54
04:54









 02:03
02:03
 12:33
12:33
 13:10
13:10
 01:51
01:51
 05:44
05:44
 11:57
11:57
 01:41
01:41
 32:45
32:45
 06:21
06:21


