




2024-05-02 14:00

扫码打开虎嗅APP


本文来自微信公众号:量子位(ID:QbitAI),作者:白交、衡宇,原文标题:《全新神经网络架构KAN一夜爆火!200参数顶30万,MIT华人一作,轻松复现Nature封面AI数学研究》,题图来自:视觉中国
一种全新的神经网络架构KAN,诞生了!
与传统的MLP架构截然不同,且能用更少的参数在数学、物理问题上取得更高精度。
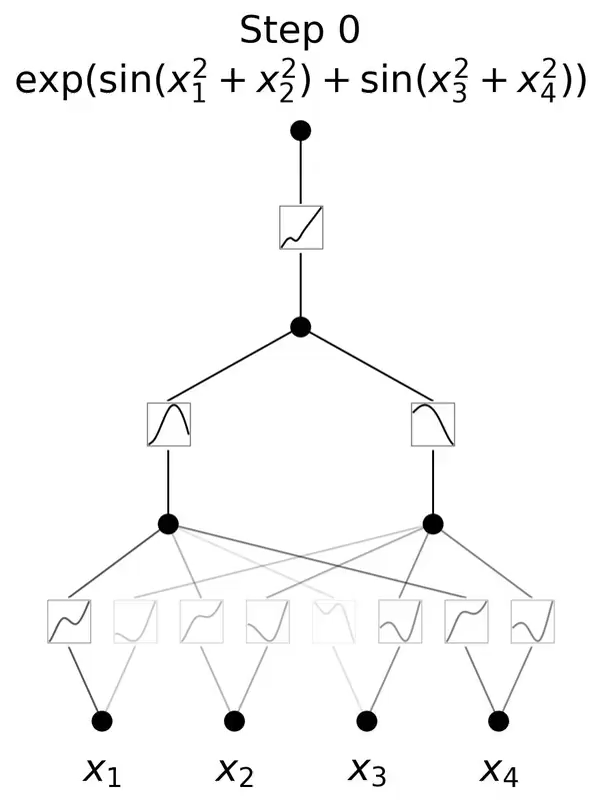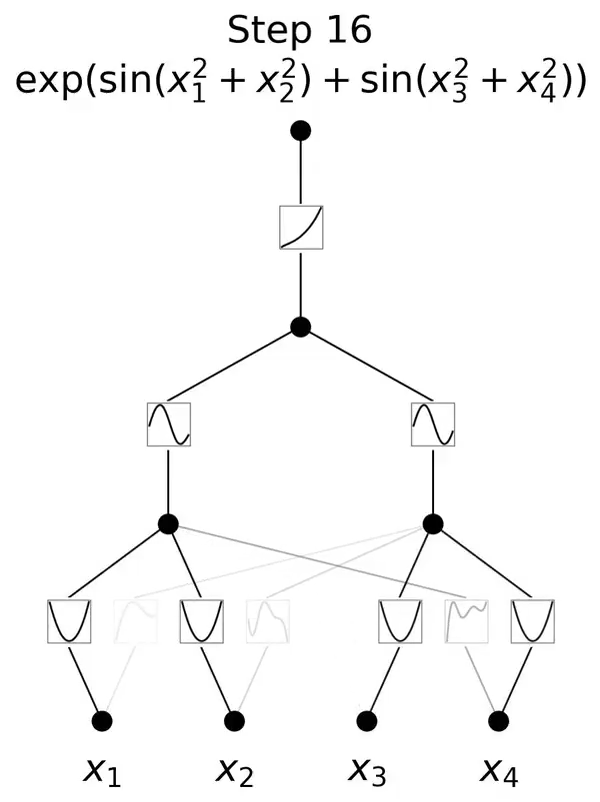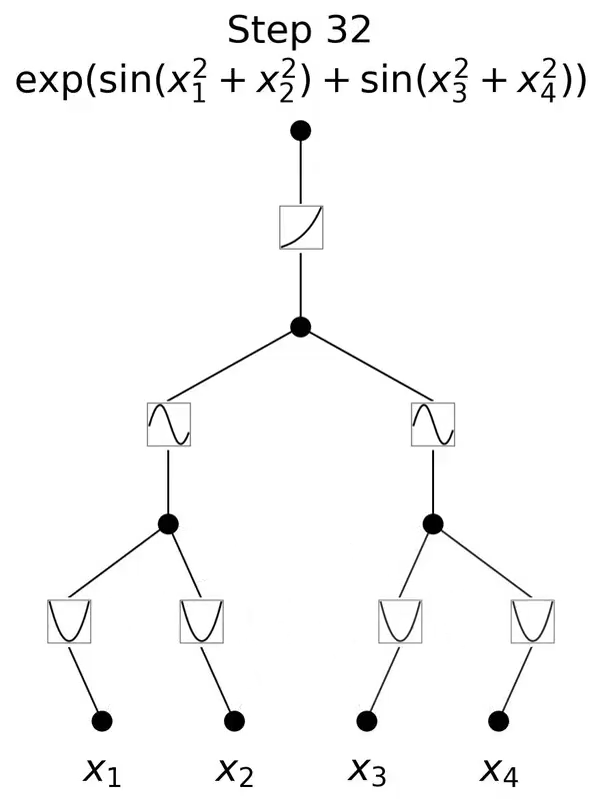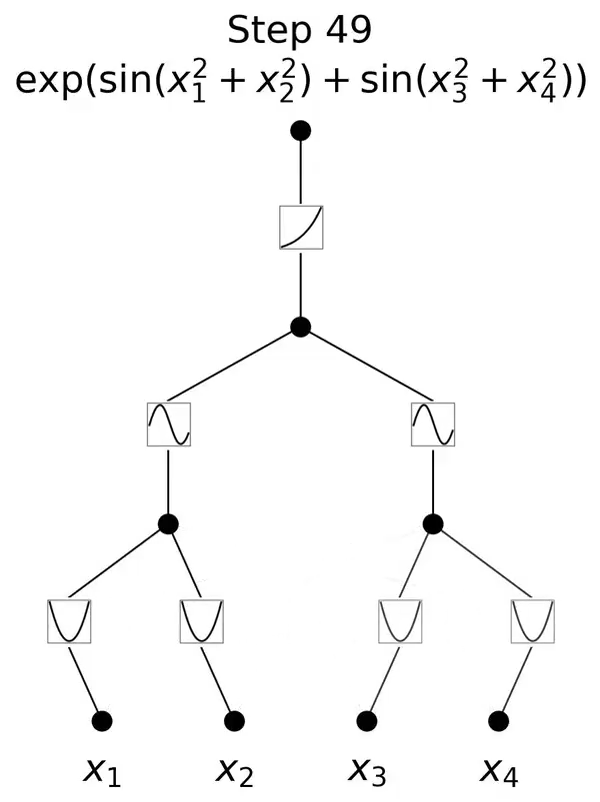
比如,200个参数的KANs,就能复现DeepMind用30万参数的MLPs发现数学定理研究。
不仅准确性更高,并且还发现了新的公式。要知道后者可是登上Nature封面的研究啊。

在函数拟合、偏微分方程求解,甚至处理凝聚态物理方面的任务都比MLP效果要好。
而在大模型问题的解决上,KAN天然就能规避掉灾难性遗忘问题,并且注入人类的习惯偏差或领域知识非常容易。
来自MIT、加州理工学院、东北大学等团队的研究一出,瞬间引爆一整个科技圈:Yes We KAN!


甚至直接引出关于能否替代掉Transformer的MLP层的探讨,有人已经准备开始尝试……


有网友表示:这看起来像是机器学习的下一步。
让机器学习每个特定神经元的最佳激活,而不是由我们人类决定使用什么激活函数。

还有人表示:可能正处于某些历史发展的中间。

GitHub上也已经开源,也就短短两三天时间就收获1.1kStar。

跟MLP最大、也是最为直观的不同就是,MLP激活函数是在神经元上,而KAN把可学习的激活函数放在权重上。

在作者看来,这是一个“简单的更改”。

从数学定理方面来看,MLP的灵感来自于通用近似定理,即对于任意一个连续函数,都可以用一个足够深的神经网络来近似。
而KAN则是来自于 Kolmogorov-Arnold 表示定理(KART),每个多元连续函数都可以表示为单变量连续函数的两层嵌套叠加。

KAN的名字也由此而来。
正是受到这一定理的启发,研究人员用神经网络将Kolmogorov-Arnold 表示参数化。
为了纪念两位伟大的已故数学家Andrey Kolmogorov和Vladimir Arnold,我们称其为科尔莫格罗夫-阿诺德网络(KANs)。

而从算法层面上看,MLPs 在神经元上具有(通常是固定的)激活函数,而 KANs 在权重上具有(可学习的)激活函数。这些一维激活函数被参数化为样条曲线。
在实际应用过程中,KAN可以直观地可视化,提供MLP无法提供的可解释性和交互性。

不过,KAN的缺点就是训练速度较慢。
对于训练速度慢的问题,MIT博士生一作Ziming Liu解释道,主要有两个方面的原因。
一个是技术原因,可学习的激活函数评估成本比固定激活函数成本更高。
另一个则是主观原因,因为体内物理学家属性抑制程序员的个性,因此没有去尝试优化效率。

对于是否能适配Transformer,他表示:暂时不知道如何做到这一点。

以及对GPU友好吗?他表示:还没有,正在努力中。

再来看看KAN的具体实现效果。
神经缩放规律:KAN 的缩放速度比 MLP 快得多。除了数学上以Kolmogorov-Arnold 表示定理为基础,KAN缩放指数也可以通过经验来实现。

在函数拟合方面,KAN比MLP更准确。

而在偏微分方程求解,比如求解泊松方程,KAN比MLP更准确。

研究人员还有个意外发现,就是KAN不会像MLP那样容易灾难性遗忘,它天然就可以规避这个缺陷。
好好好,大模型的遗忘问题从源头就能解决。

在可解释方面,KAN能通过符号公式揭示合成数据集的组成结构和变量依赖性。

人类用户可以与 KANs 交互,使其更具可解释性。在 KAN 中注入人类的归纳偏差或领域知识非常容易。

研究人员利用KANs还重新复现了DeepMind当年登上Nature的结果,并且还找到了Knot理论中新的公式,并以无监督的方式发现了新的结不变式关系。


DeepMind登上Nature的研究成果
Deepmind的MLP大约300000 个参数,而KAN大约只有200 个参数。KAN 可以立即进行解释,而 MLP 则需要进行特征归因的后期分析。并且准确性也更高。
对于计算要求,团队表示论文中的所有例子都可以在单个CPU上10分钟内重现。
虽然KAN所能处理的问题规模比许多机器学习任务要小,但对于科学相关任务来说就刚刚好。
比如研究凝固态物理中的一种相变:安德森局域化。

好了,那么KAN是否会取代Transformer中的MLP层呢?
有网友表示,这取决于两个因素。
一点是学习算法,如 SGD、AdamW、Sophia 等——能否找到适合 KANs 参数的局部最小值?
另一点则是能否在GPU上高效地实现KANs层,最好能比MLPs更快。

最后,论文中还贴心地给出了“何时该选用KAN?”的决策树。

那么,你会开始尝试用KAN吗?还是让子弹再飞一会儿。
项目链接:https://kindxiaoming.github.io/pykan/
论文链接:https://arxiv.org/abs/2404.19756
参考链接:
[1]https://twitter.com/ZimingLiu11/status/1785483967719981538
[2]https://twitter.com/AnthropicAI/status/1785701418546180326
本文来自微信公众号:量子位(ID:QbitAI),作者:白交、衡宇

