2019-05-09 13:30


扫码打开虎嗅APP

造就第423位讲者 夏光宇
上海纽约大学计算机系助理教授
我叫夏光宇,来自上海纽约大学计算机系。我的研究学科是音乐智能。
当我收到“创造力”这个题目的时候,心里泛起了很多波澜,因为我和创造力的因缘,可谓是一波三折。
献身科学( 沦为码农)的音乐人
回首往昔,其实我是个学音乐的,而且学的是中国古典音乐,吹笛箫。大学的时候,我把很大一部分时间投入了笛箫学社的社团工作中,那时候我就觉得,创造力时刻与我同在。
但是在我申请研究生的过程中,阴差阳错地走上了计算机科学的道路。在卡内基梅隆大学读计算机人工智能博士的时候,就天天在码代码,感觉非常的苦,创造力正在逐渐地离我远去。
随着研究的深入,那些代码和公式脱去了那层枯燥、乏味的外衣,我发现里边显现出来的东西,是真正的创造力。而这个创造力,与我在笛萧中体会到的那种生生不息的东方哲学思维,是如出一辙的。
那么,我们先来体会一下音乐智能是什么。
让我们把时间回拨到2015年,那年我回国办签证,结果由于飞机问题飞到了日本。我看到一个广告,是日本早稻田大学有一个非常可爱的机器人,它可以吹萨克斯。

我当时不知道那究竟是不是真的,又或者只是个模型罢了。我只是觉得它的眉毛很搞笑,就去联系了这个教授。他说:“我们这个是真的,你如果想过来造访的话,可以到我们实验室来。”
那我就去了,因为我的博士研究的一个课题叫自动伴奏。什么概念呢?就是我们在唱卡拉OK的时候,我们是跟着伴奏走,那么如果这个卡拉OK可以跟着我们唱歌的节奏,那该多好。我们快它就快,我慢它就慢。其实我就是研究这个的。这个技术早就成熟了,只不过是还没有走到大家的生活中去。
我说,我有这个技术,你有这个机器人,那用你的躯体搭配上我的灵魂,不就有一个活生生的机器了吗?于是我们就做了,这是全世界首次人机交互自动伴奏的实验(请看开头的视频)。
注意看它的肢体动作。你看我渐慢的时候,它也渐慢,然后再渐快,再渐慢 ,最后深情地结束。这就是2015年我和这个机器人的际遇。
首先问大家一个问题,大家觉得这个机器人在创造吗,有创造力吗?

有创造力的举手,没有再举手。好,绝大多数人觉得还是没有创造力,因为它还是完全的机械反应——我快它就快,我慢它就慢。
那么接下来一个问题是,如果这个机器人可以作曲、它可以编排,我只要给一段旋律,它可以在上面发展,然后把伴奏做出来,再和我一起演奏。那这想必就是有创造力了。
所以从2015年开始,我的研究正式回归到创造力的正轨。
创造力的三个层次
在这里,我想为大家揭示我认为的创造力的三个层次,分别是创、造和作。
首先要明确一个概念,就是当我们让机器拥有创造力的时候,这个事有点特殊。与其说我们想创造有创造力的机器,不如说我们人类想做上帝,因为这是关于创造的创造,这是终极的创造。
这个概念上有点飘,但是我们还是要回归到落地,机器到底应该怎么创造呢?
比如说下面这个图像,我们可能联想到很多东西,《创世纪》、人工智能等等。现阶段的人工智能,它看到的这个世界,在它们的眼中是客观的,不含带任何态度的。

像这个图像,在机器的眼中就是一堆像素,就是x,然后它可能服从一个概率分布,probability of x,Px。这时候我只要能学到它的分布,从里面随机取样一个点出来,那我就有了一个新的图像。
我们从最简单的“作”开始,最简单的创造的方法,就是东拼西凑。

我有一个x,我把其中的每一个部分都从别的那儿腾挪过来,最后拼在一起,我就有一件新的作品了。当然这是非常非常初级的创造,叫“作”。
这个是本世纪初的一个研究,它就是“精作”。你给它一个人的图像,它把图像的每一个像素区块,去和一个既定的纹理去做自相关,然后再把相似的东西腾挪回来,拼在一起。这个时候就有点创造的意味了。

这个工作叫纹理迁移,但是还是觉得停留在“作”的层面。因为它只是形似,而不是神似。
我们能不能创造出神似的作品呢?那这就要说到创造力的第二个层次,叫作“造”。
时间一下子跳到2016年,有一个研究叫“图像风格迁移”,一下子炸开了人工智能界的锅。这是几个德国科学家做的东西,大家看这4个图像,你不能说它只是形似了,它神似。

左上角的这个是母体,剩下的是人工智能“一气化三清”画出来的三幅画。
我们只能说,它们是类似的,因为它们看起来很像。我说的这个像,是它们的抽象一致,不是形似,而是神似。这就和我们中国古代说的“取象比类”一样。
什么叫“取象比类”呢?就是它们拥有共同的象,然后把它们放在一起比,就是把两个类似的东西放在一起,它们属于一类。

“取类比象生成”有三个步骤。首先第一步叫做抽象或取象,在机器学习的行话里叫做表征学习,什么意思呢?
给一个图,从图里抽象出概念,比如说是什么物体,是什么颜色。这个时候就不是把一个x简单地分块了,而是去抽象成一个概念。这个概念,我们一般用z来表示,x抽象到z。
第二步叫比类,也就是互换表征。举一个例子,我们有红房子的图片,还有大白兔的图。颜色有红色和白色,物体呢,有房子和兔子。
这个时候,我们只要稍微一腾挪转换,我们就造出了什么?白房子和红兔子。
有哪位见过白房子举手?都见过是吧。
有哪位见过红兔子举手?没见过吧。

但是,有没有注意到,我说红兔子的时候——每个人脑子里都知道我说的是什么。这就是人类大脑的神奇之处,这叫类比。
其实,这已经是在创造了,虽然不是很高妙,它还是由已知推未知,但是已经在创造了。但是它还没有落地,最后还有一步叫成型。就是把你已知的创造概念,再还回到图片。
比如说,我们生成出了一个红色的兔子,那这个红色的兔子是我们日常生活中没有的,就是我们达成了创造。
音乐可以进行类比吗?
让我们现在回到音乐,看看音乐的类比是什么样子。这个是新鲜出炉的人工智能深度学习模型不,我们来逐一解析。
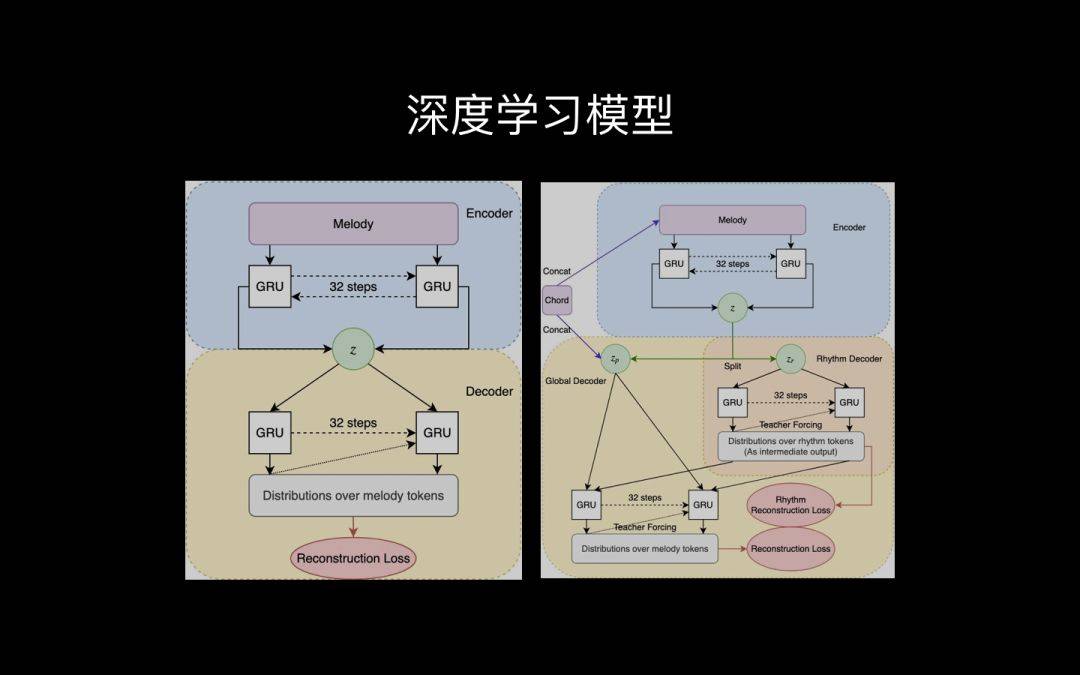
左边的这个是一个表征学习的方法深度学习的,上面是音乐,它把音乐变成一个极度浓缩的表征z。
当然,图像的表征是在空间上,音乐的表征在时间上,这是唯一的不同。
然后再把这个z变成x,也就是一切即一,一即一切。而且在深度学习过程中,我发现一个很有意思的现象就是,其实原来不用深度学习,我们也能把x变成z,但是那都是人去写定的公式。
我们发现,人为写定的公式,不如让人工智能自主学习。机器自主学习学到的那个z,非常好。
那么有了这个一即一切的东西,还不能类比,因为它太孤单了没法比。
我们怎么办?就像亚当和夏娃的关系一样,抽出一半来负责节拍,剩下的负责音调。这样就一生二。
然后我们再给它配上一个和弦,二生三。
这样音乐类比就可以用深度模型,三生万物了。当然,万是一个虚词,我们先来看看2段音乐是怎么生成6段的。
以下这段文字,可直接点击视频通过音乐和讲者讲解来理解
如果一个音乐是乾卦就是天,另一个音乐是坤卦是地,属于父亲和母亲。那它们每个人都有三段基因,我们现在就“互相杂交”,可以杂交出6个“孩子”。
我们先听父亲是什么样的。
这是父亲,我们现在把它的和声变了来听听看。
我们现在把节奏变了,节奏换成这个的节奏。就是这个是母亲给的节奏。如果它用这个节奏去谱这个旋律是什么样的?
这个是机器自动生成的,如果我们把音调换了呢?我们用原来的节奏,音调换成母亲的。
你们听,这就是音乐类比的高妙之处。
现在,我们已经可以做音乐类比生成,如果它和前面我们提到的机器人交互演奏结合起来,会是什么样的呢?
时间回到今年的1月,这是我在回访意大利的时候,又做了一次demo。
我演先奏一段,然后它基于我的演奏做了更改。它的演奏神似我的演奏,但并不是一样的。而且它还可以改节奏,变得更浪漫,或者更爵士。

我希望不久的将来,这样的机器人可以走进千家万户。
AI让人类更有创造力?
初级的是“作”,中级的是“造”,高级的才是“创”。
那么到底怎么创呢?创是无中生有,至于到底怎么无中生有?说实在话,我不知道。而且估计这地球上知道的人也不多。
因为从信息的角度来讲,真正无中生有的东西,我们如果能可以找到的话,在这个地球上只有人类的意识,活体生物的意识。
所以说如果想要解决无中生有的问题,可能要先解决意识的问题,那这个就是一个特别特别大的话题。

但我们不能停滞不前,虽然我们无法让机器无中生有,但是我们知道,人可以无中生有,音乐可以让人更有创造力。但是我们发现,有95%的人 在学习音乐的前三年就放弃了,为什么呢?
我们来分析一下原因:首先学音乐要识谱,就像学一个不同的语言;识完谱之后要学习乐器的指法,经过上万个小时的操练,然后再把谱子实操到乐器上,还要把这个曲子记住,要花好长时间。
如果是初学者的话 ,我们何乐而不为,直接学习指法呢?
这个在古代是做不到的,但是今天,依托人工智能,我们可以用一种提线木偶的方式来学笛子——在笛子上装马达。
大家来看一下,这是2017年的研究。这个笛子上连了6个指环,指环被马达控制,马达被程序控制。这样它就可以教你吹笛子了。

当人学会了这个指法之后,我们发现人会自动和气息建立起联系,他就能吹了。我们实验发现,它的学习效率,比起跟着视频学,要快50%。
但是我觉得总还是可以提高再多。大家有没有回想一下,之前我说的深度学习这个问题。我们要深度学习的东西,让机器学习模型去学习的时候,我们要放手。规定它的方向,但是具体细节要放手。
这个吹笛子的模型现在就是100%地控制它的细节,那怎么做到部分放手呢?那我就联想到我们更加人性化的指导,到底是散养式的还是填鸭式的指导更好?
散养式的是以前学习音乐的方式,只有天才能出炉。如果一个教学方式,只有天才能出炉呢,那我觉得这个教育方式是崩坏的。
我们现在是用填鸭的方式,能不能取一个中庸的之道——圈养,我们给他一个方向就足够。
现在这个是今年才出来的研究,是一个外骨骼的魔法手套,大家来看一看。

这个马达一动,你的手就动起来了,但是它这个手套是灵活的。它让你动起来,但不会把你的手指箍死,你还可以自己来动。
而且它里面有一套算法,只有当你吹错的时候,它才去改变你的行为;当你对的时候,它不会动。
就像我们小时候学自行车时父母扮演的角色——他们总是说,我在后面扶着,其实根本就没扶,只有在你要摔倒的时候才来扶一把。
这样的学习效率我们认为是很高的。
换而言之,我们已经在把在AI深度学习中得到的经验,再放回到人身上,取得了良好的效果。这个又比刚才的那个填鸭式的教学,还能提高50%。
而且我们发现,在填鸭式的教学中,90%的人会在两小时后忘掉,而这个方式只有10%的人会忘掉,记住的那些人,在一周之内都不会忘掉,所以说是学得又快又深。
最后,我想再分享一点小的想法,就是当人工智能和艺术结合的时候,它实际上是一个科技和人性的桥梁。
大家想象一下,在一个未来的世界,未来的城市,只有机器没有人。这个只有机器的城市里面,肯定有自动驾驶的汽车,不同的机器可能还会用玩围棋这种算法,来测试不同算法之间的能力。

《星际迷航3》的未来太空城市
但是我难以想象的是,在这样的一个未来城市里,两个机器人会玩音乐。
因为音乐是给人听的,它不仅仅是一个客体,还是我们精神的媒介。
换而言之,当人工智能和艺术结合的时候,我们才真正地把技术服务于人类,因为我们最后要的,并不是那个全知全能的人工智能,而是更加幸福的人生。
 18:56
18:56
 31:29
31:29
 27:32
27:32
 04:12
04:12
 09:30
09:30
 14:05
14:05
 23:11
23:11
 06:51
06:51
 12:49
12:49
 25:37
25:37

