




2019-06-19 15:58

扫码打开虎嗅APP


Photo by Jon Tyson on Unsplash,本文来自微信公众号:返朴(ID: fanpu2019),撰文:王培(美国天普大学计算机与信息科学系)
近年来自然语言处理的进展不小,各种语音助手和翻译软件已经有些实用价值了。但尽管如此,它们对稍微复杂一点的句子的处理结果还是常被人们作为笑话来说。这不免又让我们想起个老问题:计算机是否有一天真能明白我们的意思?要回答这个问题,我们先得说清什么是“意思”。
早在计算机出现前,“意义”就是语言学、逻辑学、心理学、哲学等领域中的一个关键问题了。研究语言中的意义问题是语义学的范围,而这里语言不仅包括人类历史上形成的“自然语言”,也包括人工设计的“符号语言”,如数学语言、逻辑语言等。
在使用语言进行通讯时,语词和语句是意义的载体。为保证通讯的有效进行,对词句意义的约定需要提前达成。即使在一个系统之内,词句的意义也应当是对其进行处理的根据。明确和稳定的意义在交流和思维中的重要性无需赘言,但怎样才能确定意义呢?
对一个语词或符号来说,最传统的(也是目前最常用的)意义刻画方式有两种:指称和定义。
前者是把它看作语言之外的事物的名称(比如说“鸟”的意思即指所有的鸟),而后者是把它看作语言之内的结构的名称(比如说“鸟”的意思即是“有羽毛的卵生脊椎动物”)。这两种方式常常被结合使用,即用指称的办法确定简单语词的意义,然后用它们定义复杂语词。
尽管这种确定意义的办法很直观、自然,而且对很多问题来说已经够用,但它仍不能完全满足人工智能和认知科学的要求。主要的问题出现在以下方面:
既然在计算机内对符号的处理只涉及其形式,不涉及其指称,人工智能系统似乎无法只用形式化的处理规则把握符号的意义。尽管一个计算机程序可以编辑和存储“两个黄鹂鸣翠柳,一行白鹭上青天”这样的句子,它可能完全不知道“黄鹂”和“白鹭”指什么。
我们所使用的大量词汇(甚至包括那些在科学和数学中的)都是既无明确指称,也没有普遍接受的定义的。这里的例子包括前文《当你谈论人工智能时,到底在谈论什么?》中对“智能”的分析。你最近在考虑哪些问题?其中的主要概念有广泛接受的严格定义吗?
即使是那些意义相对确定的词汇,其定义和指称也常常在历史中演变,并且依赖于使用环境。一个词的“原义”和“现义”可以不同,尽管仍有联系。比如说语言学家们发现很多抽象词汇是从具象词汇中成长起来的,就好像说词汇可以“成长”。
由于在认知系统中语词一般表示为概念,对意义的研究在心理学中对应于各种概念理论。和语义学中情况相似,经典概念理论把一个概念看成一个实例集合,其意义来自定义。一个概念的定义可以是“外延性”的,即列举其中所有实例,也可以是“内涵性”的,即列出其中实例的共同特征。这样的概念定义为判断一个实例是否属于此概念提供了充分必要条件。
毫不奇怪,经典概念理论遇到了和经典语义理论类似的困难:我们所用的概念常常没有明确边界,而且其用法极其灵活,不像“固体”,反像“流体”。关于这方面的讨论,可以看侯世达的《哥德尔、埃舍尔、巴赫:集异璧之大成》和其它著述。当然更直接的例子在我们的生活中俯拾皆是,只不过我们往往视而不见罢了。
在心理学中,经典概念理论的替代方案主要有下面几种:
“原型”理论:概念是由其中大多数实例的共同特征所确定的,而一个实例在多大程度上属于此概念取决于它与这些特征所塑造的“原型”的相似程度。按照这种理论,我们心中有一个“鸟”的原型,由“会飞”,“有羽毛”,“卵生”等特征所塑造。不会飞的鸵鸟仍可被当作一种鸟,只是“隶属度”较低罢了。这可以看成一种“内涵性”方案,只不过概念特征大都成了统计性的,而且均不再是充分必要条件。
“范例”理论:概念是由其中的代表性“范例”所确定的,而一个实例在多大程度上属于此概念取决于它是否和某个范例相似。比如说“鸵鸟”、“黄鹂”、“白鹭”都可以成为“鸟”的范例,而它们不必被整合为一个唯一的原型。鸸鹋被当成成鸟,因为它有些像鸵鸟。这可以看成一种“外延性”方案,只不过概念中的实例不再被一一列出。
“理论”理论:概念是由其在一个“理论”(即信念体系)中所扮演的角色来确定的。比如说“羽毛”的意义依赖于我们对鸟类的知识,包括其在护体、飞翔等方面的功能。这可以看成一种“内涵性”方案,只不过这里概念特征体现为在信念体系中的位置和作用,而且同一个概念中的实例未必在各方面均相似。
就像在心理学中常见的情况那样,这些理论各有证据,而心理学家们尚未就如何确定概念的意义达成共识。
作为一个智能理论的一部分,参考资料[2]给出了一个新的概念模型,下面姑且称之为“纳思模型”。这个模型的基本想法是以从经验中形成的概括关系作为概念的意义。
如果甲概念被乙概念所“概括”,这通常可以被表达成“甲是一种乙”,比如“黄鹂是一种鸟”。在这种关系中,主项“黄鹂”揭示了谓项“鸟”的部分外延(实例),而谓项“鸟”又同时揭示了主项“黄鹂”的部分内涵(特征),因此在这个模型中外延和内涵是概括关系的两个方面。这个关系可以向两个方向延伸,即一个“是一种”关系中的谓项可以同时是另一个“是一种”关系中的主项,比如“鸟是一种动物”。这样一来,单靠这个关系就可以构造一个概念层次结构,其中“高层”概念更抽象(外延更大,内涵更小),而“低层”概念更具体(外延更小,内涵更大)。
在概括关系中,主项和谓项都可以是由其它项组成的“复合项”。比如在“乌鸦是一种黑色的鸟”中,谓项“黑色的鸟”就是由“黑色的”和“鸟” 组成的。借助复合项,其它概念关系可以被改写成意义相同的概括关系。比如说“唐僧和孙悟空是师徒”可以改写成“唐僧是孙悟空的师父”和“孙悟空是唐僧的徒弟”,这里“孙悟空的师父”和“唐僧的徒弟”都是复合项。
尽管在上面的例子都是中文的,其中表达的关系是概念间的关系,而非语词间的的关系。这里的“项”是概念在系统中的标识,并不依赖于特定的自然语言。比如说“乌鸦是一种黑色的鸟”可能实际上在系统中被表示成“t1978 → t135”。
当然自然语言中的词语也有对应的概念,比如系统中可以有“‘乌鸦’是一个名词”和“‘乌鸦’由两个字组成”这样的概念关系,但这里的“‘乌鸦’”和前面例子中的“乌鸦”指不同的概念。为简单起见我们称“‘乌鸦’”为“词语项”,因为而它指向一个语言中的词语,因而可以在系统间的通讯中使用。
与此相反,“t1978”为“内部项”,因为它们只能在一个系统之内被使用。词语项通常被用来表达内部项,如“‘乌鸦’ 表达t1978”,但这个“表达”关系是“多对多”的,即不同的词语项可以被用来表达同一个内部项,而同一个词语项也可以被用来表达不同的内部项。
并非所有内部项都可以直接表达在一个自然语言当中。实际上我们常常找不到合适的词来准确表达自己心中的想法。即使是那些和系统经验直接联系的概念也不一定有对应词语,尤其是其中一些概括了特定的感知觉模式(比如“红”与“黑”),也有些关联于特定的操作或行动(比如“推”与“敲”)。
在这些概念之中,上述概括关系同样发挥重要作用,虽然其外延或内涵中包括不能完全被言语表达的感知、操作成分。下面的示意图简略地表现了一些内部项(t开头的)、词语项(中文和英文)、感知项(图片)间的概括及表达关系。
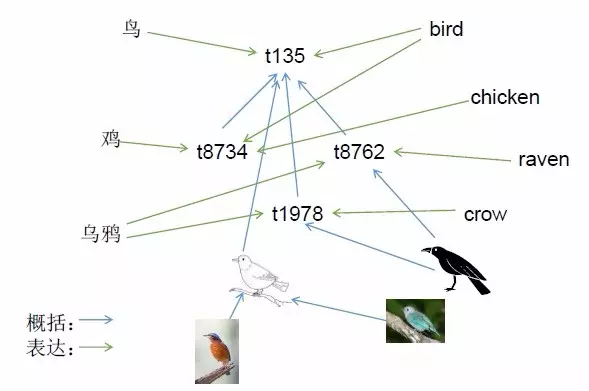
综上所述,一个项和其它项的关系(或者说它所标识的概念和其它概念的关系)体现在它的外延(它所概括的那些项)和内涵(那些概括它的项)之上,而其总和就构成了这个项(或者说它所标识的概念)在此刻对此系统的意义。如果它是个词语项,那么它的外延和内涵就是该词语的意义。
尽管纳思模型不排除系统可能有“先天”概念和信念,其中概念的意义仍主要来源于经验。如果一个系统对“苹果”毫无经验,那这个词对它就完全没有意义。在得知“苹果是一种水果”后,这个词以及相应的概念就开始有意义,包括“是一种水果”和通过推理从其中导出的信念,比如“是植物”和“可以吃”等。随着对“苹果”了解的增加,它的意义还可能包括其形状、颜色、味道、手感等等,以至于其栽培技术,甚至和某些历史人物的关系。简而言之,“苹果”的意义就是系统对其经验的总和,包括直接经验和间接经验,言语表达的和感知运动性的,表示成一组以“苹果”为主项或谓项的概括关系。
当系统运用一个概念去解决当前问题的时候,由于时间的限制它一般不可能使用这个概念的全部意义(除非这个概念极其简单),而只能其中的一部分,这就造成了“当前意义”和“一般意义”的区别。前者通常仅是后者的很小部分,而其内容选择受很多因素影响,包括有关信念的确定程度,简单程度,以往的有用程度,和当前情景的相关程度等等。
由于这些因素在不断变化,同一个概念在不同时刻常常在系统中有不同的当前意义。在经验足够丰富之后,有些概念中会形成相对稳定的“基本意义”或“本质”,从中可以推出此概念意义中的其它部分,而在其它一些概念中可能就找不到这种“内核”,以至于不能为系统提供太大效用。由此可见,不同的概念对系统的价值是不一样的。
在这个模型中,“新”概念可能以下列方式出现:
经验中出现以前没见过的词语或感知觉模式,如初次听到或见到“鸸鹋”。
生成复合项以对经验进行“压缩表示”,如把“停止信号是红的”和“停止信号是灯”合并成“停止信号是红灯”。如果这种组合以前没被系统考虑过,那么“红灯”就是一个系统生成的新概念。
如果一个概念的意义在一段时间中发生了不可逆转的重大变化,比如说某个“非基本意义”变成了“基本意义”,可以说它已经演变成一个新概念了。比如说“短信”的意义在当下和二十年前就很不一样。
后面两种方式常常使得复合项在反复出现或发挥重要作用后逐渐被作为一个整体来使用,以至于其意义越来越无法还原为其成分的意义。比如说在某些情景中说“红灯”可能与“红”和“灯”均无关系了。这可以被看作对前文《计算机能有创造性吗?》的补充:计算机不仅能创造新方法,也能创造新概念。
由于概念和语词的意义均由相关的经验决定,而不同的系统总是有不同的经验,所以意义从根本上说是私人的和主观的。尽管有相似经验的系统会有相似的概念,达到完全相同一般是不可能的。
意义的“客观性”成分主要是通讯和社会化的产物,因为这些过程为不同系统提供了相似的言语经验和社会经验,并促使它们按照约定和习俗使用语词。你要想别人明白你的意思,你最好按大家所能接受的方式使用语言,尽管你的独特经历会使你对词语的使用方式产生新想法。
比如说,在《人工智能:何为“智”?》中,我一方面挑战了“智能”这个词的常见用法,另一方面又试图为这个词提出一个新的工作定义,并为此在原词义的“深处”寻找根据。社会范围的语义变化正是由此类相互冲突的“差异化”和“规范化”的努力所共同造成的。一方面,大部分个人的“语义出轨”被矫正或漠视了,但总有一些新奇的语词使用方式引起越来越多的共鸣,以至于或远或近地流传开来,甚至最终成为“标准语义”的一部分。
在这种过程中,“墨守成规”和“标新立异”都是有理由的,因为前者维护了语言的存在,后者推动了语言的发展。在一个具体例子上的角力结果则要看双方的力量对比了。
上面介绍的这个“纳思模型”和传统的语义理论有根本的不同。
目前,很多人依然把计算机看作一个“物理符号系统”,以为其中的符号只能通过指称外部世界事物来获得意义。为解决这个“指称”或“解释”超出系统本身掌握的问题,常见的对策是用感知运动模式为符号提供“根基”。这仍是试图在指称语义的框架内解决意义问题,问题是语词的意义通常是不能完全还原成感知运动模式的(尽管有时以其为主要成分)。
纳思模型中的项可以被叫做“符号”,但它对系统的意义不依赖于一个外在的指称或解释,而是体现于它和其它符号在系统内部的联系。这种联系是对系统经验(包括但不限于感知运动经验)的选择性总结,而非不变的定义或理论。系统对这种符号的处理不仅是基于其形式的,同时也是基于其意义的。这样的系统不仅可以理解符号的意义,而且可以改变和创造符号的意义。在这个模型里指称语义仍然有用,但仅限于为数学等领域中的“纯抽象概念”提供使用途径。
前面提到的各种概念理论其实都是试图用关系刻画概念,只是“原型”理论用内涵关系,“范例”理论用外延关系,而“理论”理论主要用信念体系中的关系(尤其是因果关系)。因为纳思模型考虑所有概念关系,前述理论均可看成其特殊情况。对一个特定概念来说,其意义的确可能主要由某一类关系来确定,但更常见的情况是各类关系均有贡献。
其实把“意义”看作“全部关系的总和”远不是个新想法。以往哲学、心理学、人工智能中都有过类似的思路,但因为其中的一些弱点,没有成为意义理论的主流。
纳思模型是建立在对这些弱点的解决之上的。一种常见的批评意见就是把这种确定意义的方式看作系统内的循环定义,而与外部世界无关。纳思模型中的概念不是被其它概念所定义,而是被经验到的概念关系刻画。比如知识“苹果是一种水果”既没有用“苹果”定义“水果”,也没有用“水果”定义“苹果”,而是用二者的关系同时贡献于它们的意义,而这个关系来自于外部世界。把“意义”说成“全部关系的总和”的另一个问题是太笼统,不足以解决具体问题。
对此,纳思模型的对策是将各种概念关系统一表示和处理为概括关系及其变种。最后一种意见是质疑我们在用一个概念时怎么可能把所有其它概念都牵扯进来。在这一点上,纳思模型的不同之处在于它指出系统在使用一个概念时一般只涉及其部分意义,而这又同时解释了意义的情景相关性。
纳思模型的计算机实现已经展示了这个模型的可行性,尽管仍有很多细节问题有待解决。据此模型,概念和语词在一个人工智能系统中是有意义的,而其意义是由系统的相关经验确定的。由于经验上的差别,计算机对一个语词的理解不会完全和人一样,但这种差别并不妨碍计算机用自然语言和人交流,并完成越来越复杂的语言处理工作。
那些仍以“图灵测试”作为人工智能定义的人可能认为上述结论说明“真正的”人工智能是不可能的,但他们往往忘了人与人之间由文化、性别、年龄等差异造成的不解和误解比比皆是,而在各个领域中对于什么是某个词语的“真正意义”的辩论也从来没停止过。
当年阿Q以为城里人把“长凳”叫成“条凳”是错得可笑,而类似的想法至今仍未断绝。
参考资料:
[1] Stephen Laurence and Eric Margolis, Concepts and cognitive science, in Concepts: Core Readings,
Eric Margolis and Stephen Laurence (Editors), Cambridge, Massachusetts: MIT Press, 1999
[2] Pei Wang and Douglas Hofstadter, A logic of categorization, Journal of Experimental & Theoretical Artificial Intelligence, 18(2):193-213, 2006
版权声明:本文由《返朴》原创,欢迎个人转发,严禁任何形式的媒体未经授权转载和摘编。
《返朴》,致力好科普。国际著名物理学家文小刚与生物学家颜宁联袂担任总编,与几十位学者组成的编委会一起,与你共同求索。关注《返朴》(微信号:fanpu2019)参与更多讨论。二次转载或合作请联系fanpu2019@outlook.com。

