




2019-07-08 15:52

扫码打开虎嗅APP


注:前几天,一个DNA分子存储16G维基百科的新闻刷新了我们的三观,引发人们对于未来数据存储的大讨论。近日,布朗大学的研究人员受此启发发现:DNA并不是唯一可以用于数字存储的分子,含有糖、氨基酸和其他小分子的溶液也可以取代硬盘。意外不意外?
图片来自视觉中国,本文来自微信公众号:新智元(ID:AI_era),来源:plos、newscientist
原来,不只DNA能够存储数据,小分子溶液也可以。
上周,报道了DNA数据存储的新闻,不仅16G的维基百科能够存储到一个DNA分子上,就连存储全球的数据也只需要1kg DNA。
而近期,布朗大学的研究人员受此启发并发现:DNA并不是唯一可以用于数字存储的分子。事实证明,含有糖、氨基酸和其他小分子的溶液也可以取代硬盘。

论文地址:https://journals.plos.org/plosone/article/file?id=10.1371/journal.pone.0217364&type=printable
在DNA的下游,代谢组(metabolome)是一个信息丰富的分子系统,它具有不同的化学维度,可以用来存储和处理信息。
为了证明小分子后基因组(small-molecule postgenomic)数据存储的原理,研究人员利用机器人液体处理将数字信息写入化学混合物,并利用质朴分析提取数据。
研究人员还提出了几个存储在合成代谢体中的千字节(kilobyte-scale)级图像数据集,使用多质量逻辑回归可以对其进行解码,其精度超过99%。

布朗大学工程学院教授、该研究的高级作者Jacob Rosenstein说:
这是一个概念验证,我们希望让人们考虑使用更广泛的分子来存储信息,在某些情况下,我们在这个研究中使用的小分子可以比DNA拥有更大的信息密度。
另一个潜在的优势在于,多种小分子可以相互反应形成新的化合物。这为分子系统创造了潜力,不仅可以存储数据,还可以操纵数据——在代谢物混合物中执行计算。
为了上述的想法,研究人员用常见代谢物做了一种混合物——含有糖、氨基酸和其他小分子的溶液,人类和其他生物利用这些小分子来消化食物和执行其他重要的化学功能。
他们的想法是利用混合物中特定代谢物的存在或不存在作为二进制的1和0来编码数字信息。
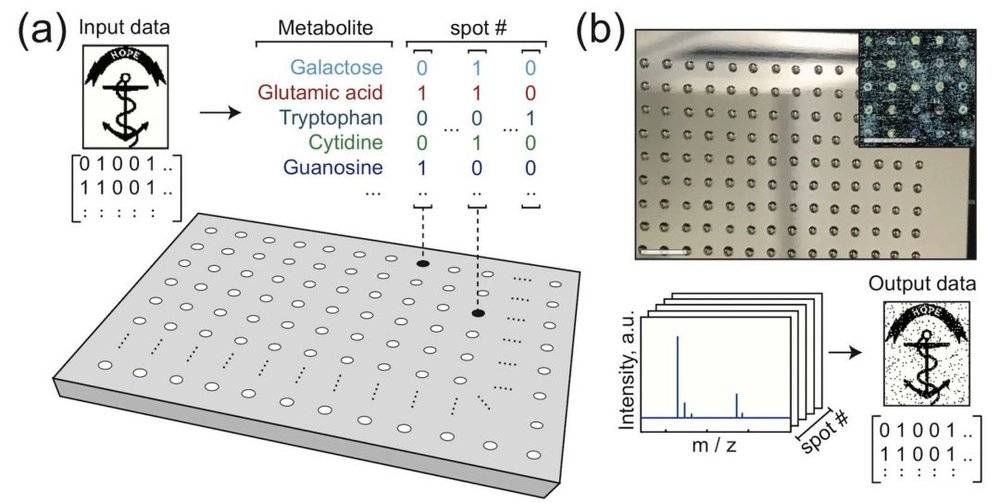
图1 该方法将数字数据的1和0映射到溶液中特定分子的存在或不存在。研究人员使用该方案对图像文件进行了编码。
例如,为了生成北山羊的图像,研究小组使用了6种不同代谢物的混合物,这些混合物由液体处理机器人点缀在一个小金属板上。他们总共制作了1024个液滴,每个液滴中6种代谢物或缺失或存在,提供了足够的二进制信息来编码6142像素的图像。
然后,金属板被烘干,留下微小的代谢物分子点,每个点都保存着数字信息。
然后,这些数据可以用质谱仪读出,质谱仪可以识别存在于板上每个点的代谢物,并对数据进行解码。

研究人员将这张猫的图像保存在小分子溶液中
研究人员通过用质谱仪分析每个点的化学成分,能够以99%的准确率检索到这些数据。他们还用12种代谢物的混合物,解码了一张分辨率更高的猫的照片。
他们使用手掌大小的标准板来编码缩略图大小的图像。但是据Rosenstein介绍,代谢物存储设备的物理尺寸可以更小。
代谢物分子比DNA和蛋白质小得多,而且种类繁多。他说,这意味着它们可以比DNA更密集地表示少量数据。
Rosenstein说:“一旦数据被记录下来,它们就不需要任何能量了。根据分子和环境条件的不同,这些数据可以保存数月或数年。”事实上,在极端温度、压力和机械力等条件下,分子存储可能比电子存储更稳定,这取决于分子的特性。
分子存储还可以使离线存储大量数据成为可能,而不是存储在云中,从而防止黑客入侵。
到目前为止,Rosenstein和他的同事们发明的技术与电子计算机相比速度还比较慢。
研究人员指出,这种技术也有一些局限。例如,当多种代谢物分子被放在同一溶液中时,它们之间会发生化学反应,这可能导致错误或数据丢失。但这个bug最终可能成为一个功能。也许可以利用这些反应来操纵执行数据的计算。
Rosenstein表示:
与DNA相比,我们的代谢物数据具有较低的延迟,从而可以从头到尾快速地读写数据集。”他也补充说 DNA 目前在编码大型数据集方面有优势。
这些想法在研究实验室中使用已经可行,但我们需要加快速度,缩小分析硬件的尺寸,然后才能在实验室外实施。
这类研究挑战了人们在分子数据系统中所看到的可能性。DNA不是唯一可以用来存储和处理信息的分子。认识到还有其他潜力巨大的可能性是令人兴奋的。
将36种不同代谢化合物的试剂级样品(S1文件中的表A)在二甲基亚砜(DMSO,无水)中稀释,标称浓度均为25mM。将一些代谢物首先溶解在替代溶剂(去离子水,可选择加入0.5M或1M的盐酸)中,以促进化合物在DMSO中的溶解。将10μL每种化合物等分到384孔的微量培养板(Labcyte384LDV)上。
在规格为76mm×120mm不锈钢MALDI板上制备化学数据混合物。使用声学液体处理器(LabcyteEcho 550型)将化合物从培养板转移到MALDI板上。仪器标称的单液滴体积为2.5nL,但为了降低液滴体积变化对结果的影响,通常每种化合物使用2滴(5nL)。液滴以标准的2.25mm点距排布,共计1536个位置(32×48)。
将化合物按编好的位置滴到MALDI板上之后,需要将MALDI基质材料添加到每个位置上。我们选择9-氨基吖啶作为基质材料,因为它与代谢物库能够共存,它在小分子体系中具备低背景(low background)特征,同时支持正离子和负离子模式。将MALDI板放置在干燥环境中,大约在一夜时间即可完成结晶(最多10小时)。干燥后,可将板储存在湿度控制柜中,或进行MALDI-FT-ICR质谱分析。
实验中使用傅里叶变换离子回旋共振(FT-ICR)质谱仪(SolariX 7T,Bruker)分析结晶代谢物数据混合物。精确的成分结果是每个频谱上的测量时间的函数。这些实验中通常耗时0.5-1秒,产生的分辨精度<0.001Da。该仪器将连续测量48x32网格上的每种混合物的质谱。测定全部样本只需要不到2个小时。
为了从质谱中读取编码数据,将代谢物存在的概率建模为多个预测质量的组合。利用多项逻辑回归方法,考虑偏移量的自然指数,加上所有识别质谱信噪比之和,每个信噪比均与训练的权重系数相乘。在给定每种代谢物的n个最佳峰值输入的情况下,使用有限记忆BFGS算法来预测逻辑精度评分。
在实验中,对所有代谢组合成分重复以上过程。
实验结果:检索准确率高达99%!
我们的合成代谢组由36种化合物组成,包括维生素、核苷、核苷酸、氨基酸、糖和代谢途径中间体。为了将数据写入代谢物混合物中,我们使用声学液体处理器以2.5nL的增量将纯代谢物溶液传输到钢制MALDI板上预先定义的位置。选择2.25 mm节距网格,以与标准wellplate协议兼容。这产生了一个不同代谢物混合物的空间阵列,其中每种混合物中每个化合物的存在(或不存在)编码一位信息。
在蒸发溶剂后,每个数据板包含多达1536个干燥点(图1b),我们可以使用基质辅助激光解吸电离(MALDI)质谱(MS)进行分析。为了预先筛选合成代谢组中的每种化合物,在1400个独特的点上,用36种代谢物的组合混合物写出图版。由于MALDI方案具有化学特异性,因此我们不希望在一组条件下,整个化合物库具有相同的鉴定准确度。我们使用此预筛选来确定具有相同方案的每种代谢物的MS鉴定准确度。
代谢物混合物的离子回旋加速器质谱
使用傅里叶变换离子回旋共振(FT-ICR)质谱仪(SolariX 7T,Bruker)分析结晶混合物阵列。在FT-ICR MS中,脉冲RF激发离子进入周期轨道,其频率由磁场强度和离子质量决定,这使得质量分辨率比飞行时间(ToF)更精细。仪器。在这些实验中,质量分辨率通常为0.001Da。使用FT-ICR MS,即使它们的质量仅相差milli-Daltons ,也可以区分代谢物。
在图2(a)中,显示了包含鸟苷(go)和9-氨基吖啶(9A)基质的斑点的一个正离子MALDI-FT-ICR质谱。质子化的基质加合物在峰1和6(蓝色)处鉴定,连同鸟苷的加合物,标记为(2:Na,3:K,4:2K-H和5:异丙醇(IPA)+ H)。观察到的强度因加合物和种类而异,在图2(b)中,在1024个点上显示了第一个峰值(m / z = 195.0916±0.001处的质子化基质)的强度。
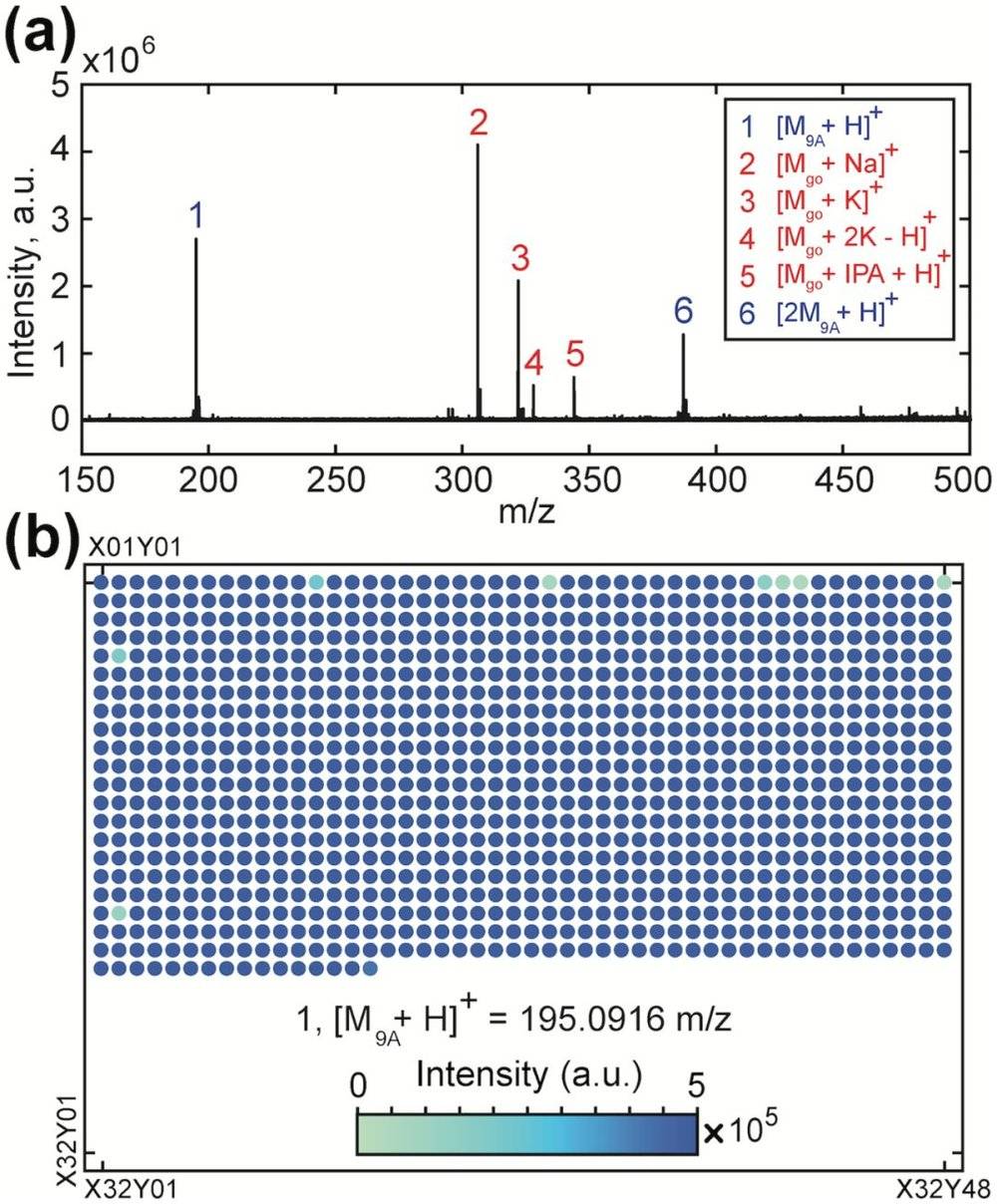
图2.用质谱分析化学数据板。
许多开放获取工具可用于代谢峰的检测和MS质谱的分配。为了清楚地将质谱与二进制数据联系起来,我们考虑了一个基本的检测方案:如果代谢物的质量强度高于某个特定的阈值,则声明它存在,并且其地址的二进制状态设置为1(或0,如果它的质量峰值不存在)。该方法在图2(b)中的1024个斑点中识别出1020个基质质子化峰(≈99.6%)。
作为初始演示,我们选择了6种代谢物的库子集,用于将Nubian ibex的6,142像素二进制图像编码为1024个混合物的阵列。伪随机交织后,将数据映射到存在或不存在山梨醇(SO)、谷氨酸(GA)、色氨酸(TP)、胞苷(CD)、鸟苷(GO)和2-脱氧鸟苷水合物(GH)中。如方法中所述,使用FT-ICR-MS对板进行书写和分析。
图3a显示了240个独立点观测到的质谱背景噪声的空间图和直方图。在进一步分析之前,我们将每个质谱除以其背景σ,这样可以更直接地比较多个位置的信号强度。信号强度是样品制备、分析物和加合物的复杂函数。归一化后,6种代谢物的目标峰显示在图3b中。第一行是其数据包含六位[1 0 0 0 0 0]的点,因此仅存在与第一代谢物(山梨糖醇)相关的m / z峰。类似地,显示了五个其他“一次触发”模式,可以无错误地解码。
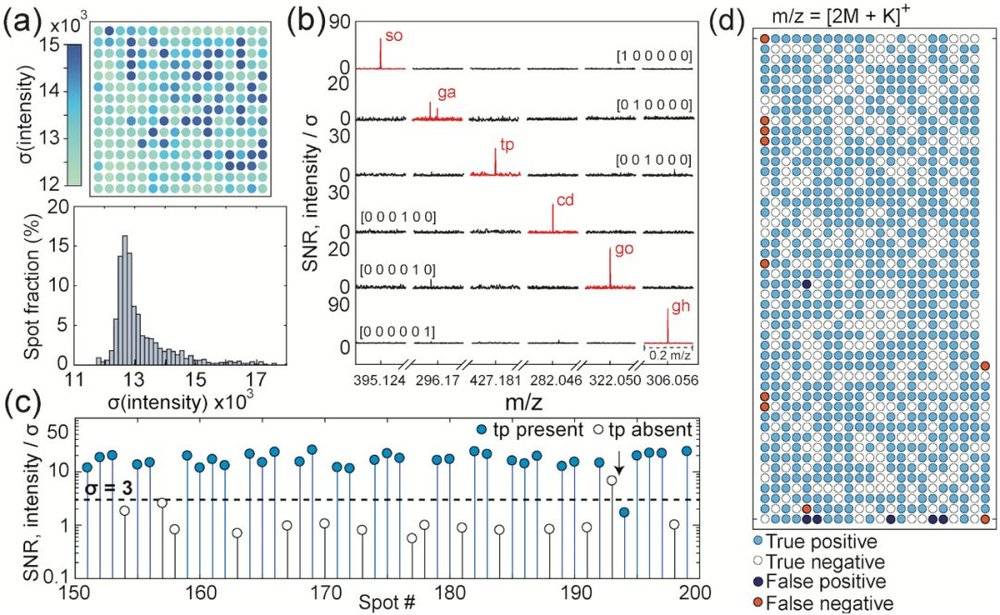
图3.质谱背景和噪声考虑因素。
选择阈值3σ作为说明代谢物存在所需的强度。例如,如果我们检查色氨酸[2Mtp+K]+质量(图3c),我们发现该阈值产生96%的正确分类。如图3d所示,还可以对板上的每个点显示该检测方案。板边缘的误差聚类表明MALDI激光位置和液滴点位置之间的微小偏差是误差的来源。
在实践中,一个化合物将与多个峰相关联,并且具有不同的信噪比和用途。对于给定的代谢组,研究人员需要确定哪种m/z峰值最适合识别每个库的元素。
每个高分辨率FT-ICR质谱包含〜2×106 m/z 点。由于质谱空间的大部分是背景,因此首先将特征的数量减少到统计上有用的特征数量。而后研究人员测试了所有质谱的系综平均值(ensemble average)中发现的1444个候选峰,用来确定m/z处的强度对编码数据值的分类精度(图 4a)。
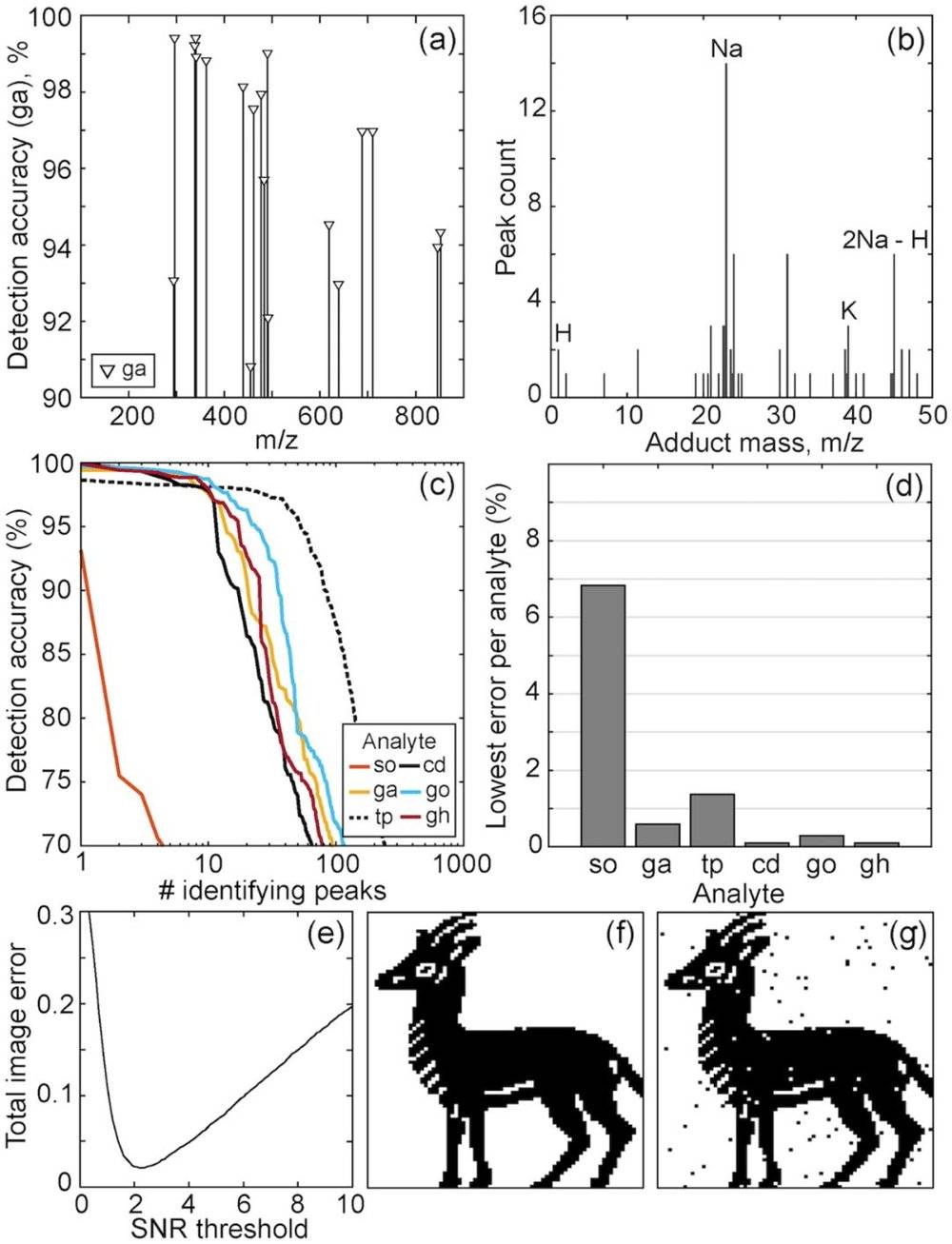
图4
虽然这些峰值的识别没有化学偏差,但许多特征可以归因于已知的代谢物加合物离子。相关加合物质量的直方图如图4b所示。
达到70-100%范围内检测精度的峰数如图4c所示。选择每种代谢物的最佳表现峰值,并应用2.5σ的检测阈值,足以恢复约2%累积读/写错误的数据(图4e)。 相应的输入和输出数据图像如图4f和4g所示。
假设鉴别峰值是部分不相关的(如图D所示),利用每个代谢组的多个m/z峰来寻求改进是合理的。这样的策略将在更复杂的代谢组中变得越来越重要。
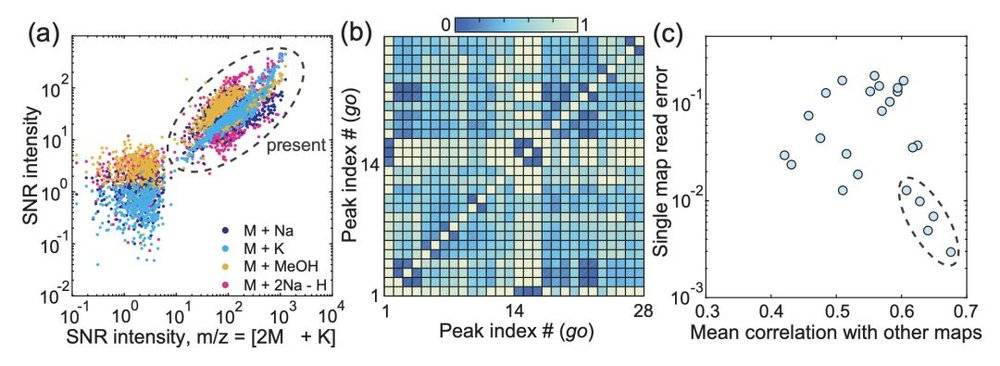
图D
研究人员使用类似6kb ibex图像类似的技术,从埃及坟墓中编码了17424位的猫图像(使用了1452个点),其中包含库中12个代谢物子集的数据混合物(图5a)。他们使用这些数据来扩展解码方案,使其包含多个m/z特性。
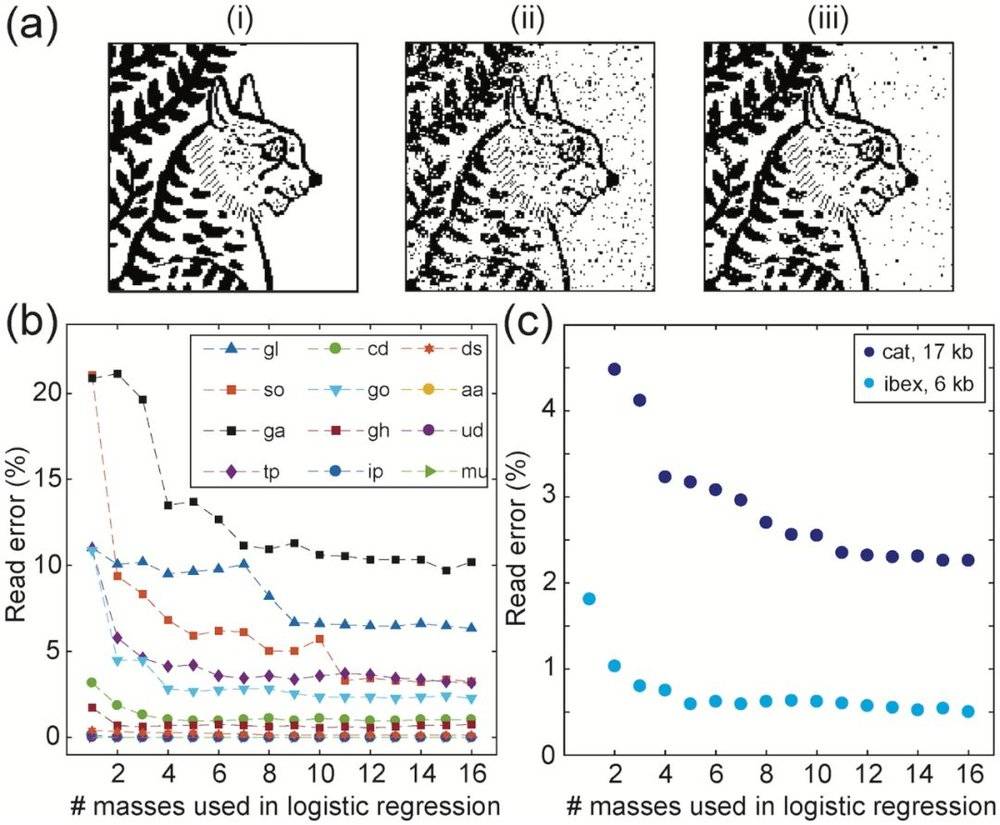
图5
在确定一组统计鉴别峰之后,研究人员使用1到16个表现最好的峰进行逻辑回归。多质量回归对整个cat图像的读取准确率为97.7%(图5c)。
图4和图5中的数据的累积读取错误率显示为逻辑回归中使用的质量数的函数。
将这些技术应用于早期的ibex数据集,可以实现<0.5%的错误率。但是,重复测量斑点会导致数据丢失。研究人员还发现,每次连续读取数据板都会增加<1%的误差(图E)。
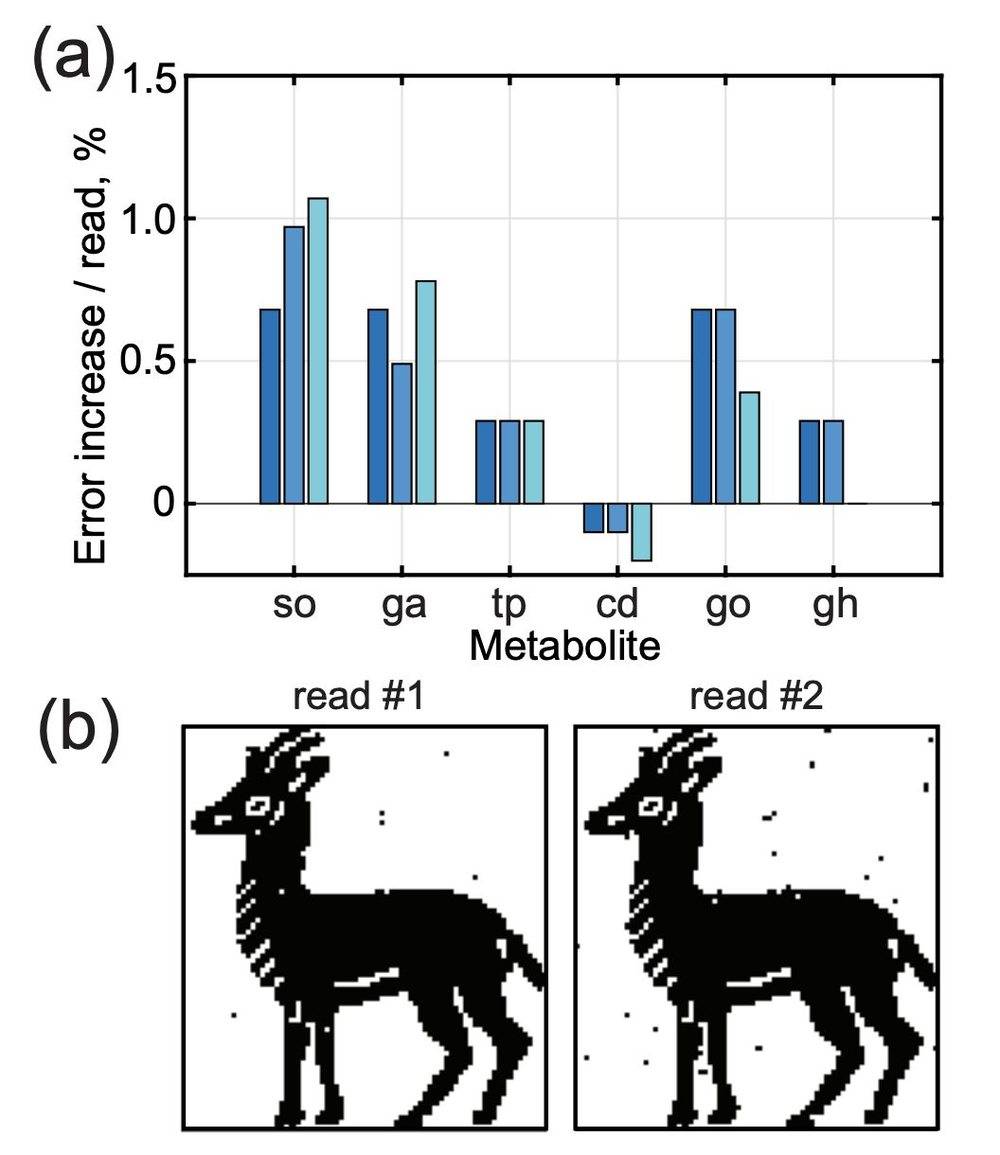
图E
使用不同的板进行训练可以获得相同的精度而不会过度拟合(图F)。
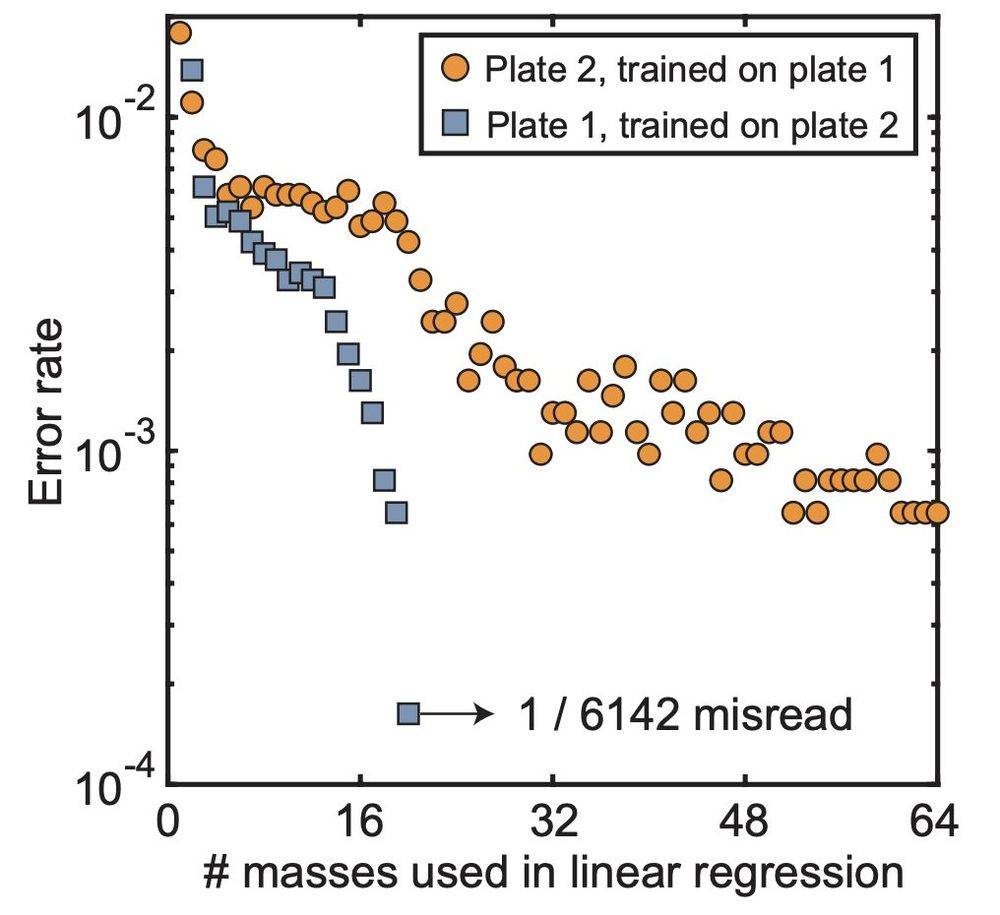
图F
总而言之,上述实验表明:代谢组是一种可行且强大的表示数字信息的媒介。
参考链接:
https://www.newscientist.com/article/2208439-data-can-now-be-stored-inside-the-molecules-that-power-our-metabolism/
https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0217364
本文来自微信公众号:新智元(ID:AI_era),来源:plos、newscientist

