2019-07-12 14:10


扫码打开虎嗅APP

本文来自微信公众号:全球深度报道网(ID:gijn_cn),作者:Mike Caulfield,头图来自:东方IC
最近我听说某位叫做 Maisy Kinsley 的“记者”在撰写有关做空特斯拉的报道,并正向相关人士查证消息。我不想在这里大谈埃隆·马斯克(Elon Musk)如何与做空人士作战,你也不需要这个。我想说的是,人们可以通过各种方法假扮记者作恶,而 Maisy 正是这样的例子。
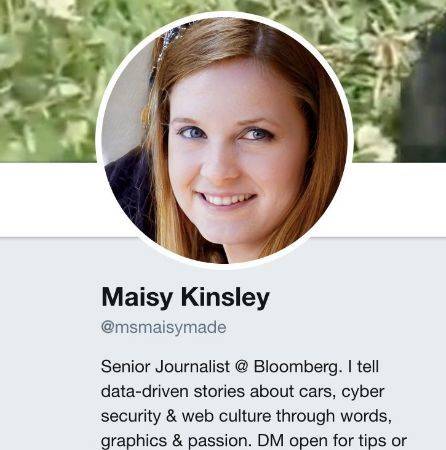
Maisy Kinsley 的个人简介
我们都会选择性地向外界释放关于自己的信息。这些信息可真可假,对于刚认识的人,我们很难判断它们的可信度。我们能做的,只能估量这些信息大概需要花费多少时间或金钱。对骗子来说,编造某些信息是轻而易举的,但有些就要费点心力。
下面,我们来鉴别一些常见的身份信息,以及编造它们究竟需要花费多少心力。
首先,我们来谈谈推特(Twitter)上的个人介绍和头像。Maisy 使用的头像是一张原创的图片。如果对它进行反向图片搜索(reverse image search),并不会出现其它关于 Maisy 的照片,也不会出现别人的名字,所以这不太可能是张盗用的头像。而在个人介绍中,Maisy 自称为彭博撰稿。
不过这并不足以确认一个人的身份。但我们由此发现了 Maisy 的个人网站,而且看上去十分专业。

Maisy Kinsley 的个人网站,虽然这人并不存在。
Maisy 的网站显示她是一名自由撰稿人。但像推特上的信息一样,这些都是她自己说的。不过我们由此找到了她的领英页面,显示 Maisy 有194位联络人,她甚至是我的三度联络人!(我已经有点看烦她的照片了,但让我们再坚持一会。)
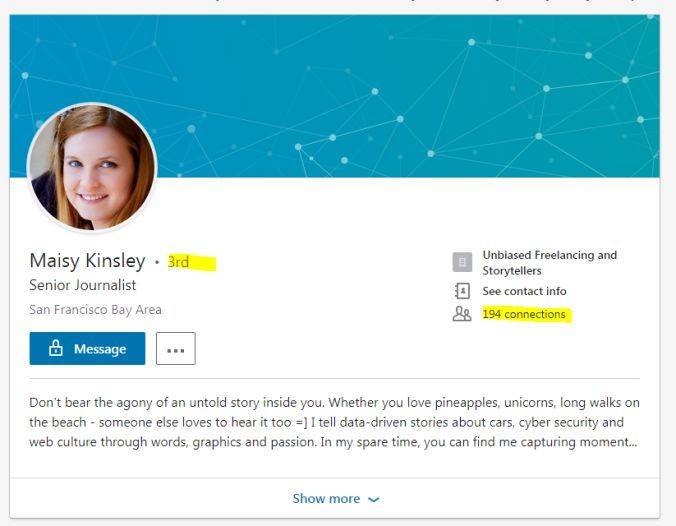
Maisy Kinsley 的领英页面
噢,根据领英,Maisy是斯坦福毕业生!我们不是刚谈到有的信息需要花费点心力嘛,看,可不是随便说说!
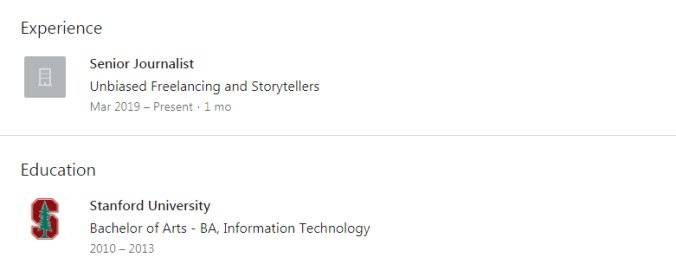
Maisy 的教育经历截图
一、真的,很可能是假的
小结一下以上的信息:它们正变得越来越不可信。在互联网时代,编造这些信息正变得越来越容易,而这也令信息的可信度在下降。
你完全可以决定如何在推特上介绍自己。没有哪家公司页面或者专业名录会刊载这段个人简介。所以,这样的信息并没有足够的可信度。
那么 Maisy 的头像又是怎么回事呢?这完全要归功于机器学习,它们已经能创造出一个根本不存在的人士的照片。通过这个网站,你也能花上几秒钟创造一张假照片。下面是我的示范。

那 Maisy 的网站呢?网站域名很便宜,一年的租金大概是12美金。而网页就更便宜了。至于页面设计,虽然你一半的格调都跟你的网站看起来多专业有关,所以你需要花钱请设计师——但这只是在15年前,今天,你能找到大量免费的模板做出跟 Maisy 一样的网站。
也许你要问,那领英的页面呢?那些联系人、在斯坦福上过学又是怎么一回事呢?
首先,领英页面上的的教育信息一点也不比推特更权威。虽然它看起来很官方,但其实你爱写什么就写什么。你看,我就刚刚让自己上了斯坦福,而且读的是超酷的天体物理学。
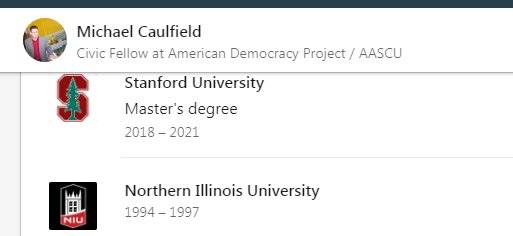
我在领英上给自己加上了斯坦福大学的学位——不过截图之后我立刻删除了它
至于 Maisy 在领英上的人脉,就要比上面那些信息好玩一点。有人曾致电他们询问是否真的认识 Maisy。不,没人认识,他们只是没有拒绝对方发来的联系邀请或者认证请求罢了。只要 Maisy 向足够多的人发送联系邀请,以及主动为足够多的人进行认可背书,自然就会有人答复他的邀请或者认证她。大功告成。

跟你们讲一件好玩的真事。有一次我在领英上加一位叫 Sara Wickham 或者类似名字的人做好友。我们聊起在1993年读大学的朋友:
“记得 Russ 吗?”
“那个背着吉他,总是弹 The Dead 和 Camper Van Beethoven 的那个家伙吗?。”
“你是说 Chris 吗?”
“是的,Chris!”
“当然记得,他怎么样啊?”
聊了一个多星期之后,我意识到我们并不是同学,而且随着越聊越多,我想起弹吉他的人也根本不叫 Chris。我从来没见过这个和我聊天的人,我们也根本没有共同朋友。
这就是领英,联系人根本无法说明什么。
二、假的,很可能是真的
看到这,你大概早已按捺不住,急着要说你早就注意到 Maisy 有些不妥的地方。你可不会被骗,对吧?
比如说,Maisy 在领英上的经历显示她从毕业到成为记者,中间有5年的断档期。她2013年毕业,但却直到最近才成为记者,说不通对吧?她的相片有某种膨胀感,这正是 AI 处理过的痕迹!而且她在哪都是用同一张照片,网站上的个人简介看起来就像瞎扯。她的工作室叫“不偏不倚的自由工作者及报道者”,听起来就像“诚实的自助服务”一样,完全是胡编乱造。
怎么说呢,指出这些不妥并不会显得你有多聪明。毕竟你已经知道 Maisy 是个骗子,所以自然会注意到各种不合理的地方。
问题在于,当我们用放大镜来审视生活时,就会发现它就是充满着各种不合理。比如工作出现断档,可能是因为他有了孩子。在毕业后与第一份正式工作之前出现断档,是很常见的现象,特别是对于女人来说。如果你觉得这就说明别人是骗子,那么一大群很棒的女记者都会被你标签为骗子。
至于照片,有时候人们就是会用一些怪怪的照片。以下是在推特上很活跃的 Joshua Benton 使用的头像。

Joshua Benton 的推特头像
Joshua 在推特的个人简介中声称自己是哈佛某个媒体项目的负责人。然后他竟然用了一张这样的头像,绝对是骗子,对吧?
但事实上,他的确在哈佛工作,而且负责一个世界知名的实验室。
那 Maisy 糟糕的简历又怎么解释呢?嗯,难道你没试过写了一个糟糕的简历,然后想着自己过段时间会再修改吗?我就干过这事。(然后很多会议项目就刊登了这份简历)
至于她的私人工作室名字——不偏不倚的自由工作者及报道者,真的就能说明是骗子吗?
讲个好玩的事给你们听,一群推特用户参与调查了 Maisy 假扮记者这事,也检视了她在领英上的联系人及背书者。其中有一位 “牧羊人先生” 似乎一看就是骗子。他还自称是狗狗摄影师及纸制帽子匠人。
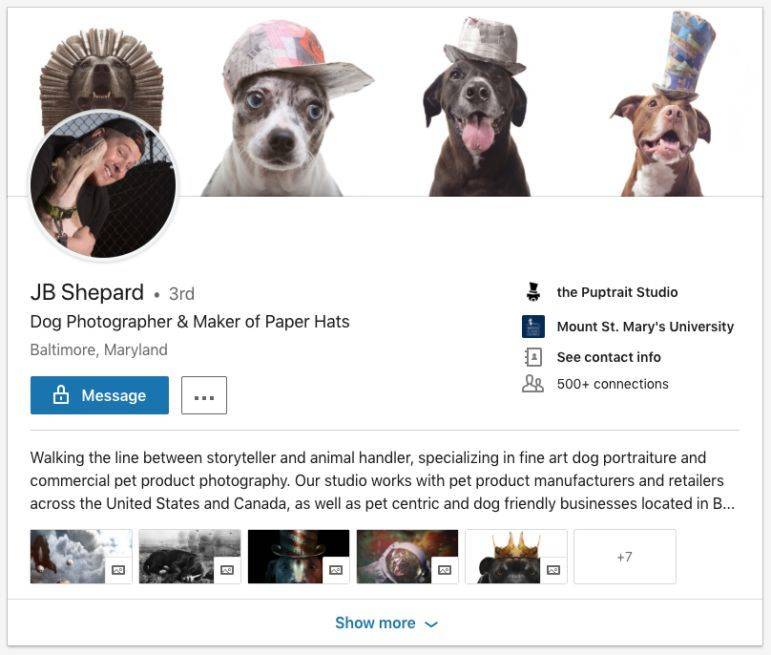
不用我一一分析给你听,对吧?这个人姓谢帕德(Shepard,英文意思是牧羊人)。他上传的帽子照片一看就是PS过的,他的自我介绍是“身处说故事的人及动物管理者之间”。这肯定是骗子。
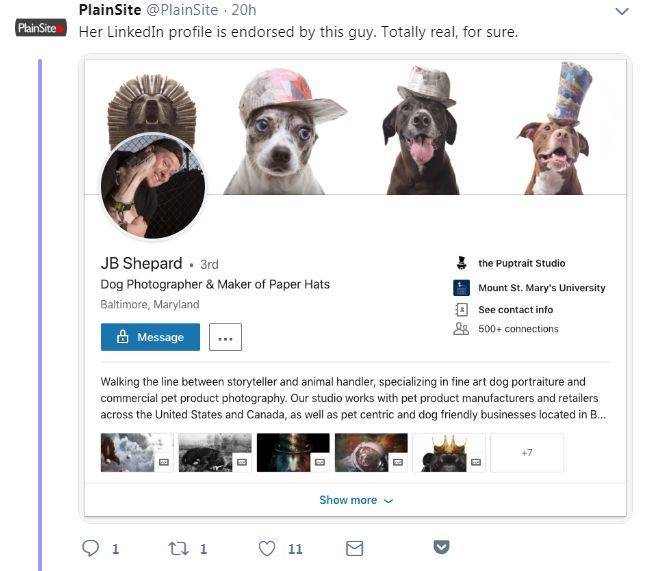
人们真的打电话去谢帕德(JB Shepard)先生的 Puptrait 工作室,然后发现都是真的,他真的是姓谢帕德。

图中这只小狗真的存在,真的带着纸做的帽子,而且都可爱的不得了。如果你想帮自己家的动物也拍一张类似的照片(或者在这个让人心烦的世界里看看可爱的小东西解解闷)你可以联系牧羊人先生的 Puptrait 工作室。感谢JB·牧羊人先生同意我们刊登这张照片。
这顶纸帽子也不是PS的,而是谢帕德先生真的为这只小狗量身制作的。
如果你也曾经认为谢帕德先生是个伪造的身份,别怪责自己。当你接触看起来很粗制滥造的信息时,你对他们的真实性或者可信度的判断,会受到固有思维的影响。如果你是男人,就很有可能会觉得工作空白期不可能长达5年。而当你并不是狗狗摄影师以及纸质帽子匠人时,就会觉得这听起来不像什么正经工作。
我曾在同事和学生身上做过实验:我们告诉他们某个网站是伪造的,然后询问他们哪些线索可以有助我们判断这一点。他们常常会很快总结出几十个明显的漏洞:太多广告、奇怪的排版、域名、没有受访者的相片、标题党、没有清晰的“关于我们”的页面等等。然后我就会告诉他们这个网站是真实的,而且属于某个世界知名的医学周刊或者是刊载澳洲国家记录的报刊。
但我现在放弃这个实验了。原因很多,比如人们会生我的气。他们有理由生气,毕竟我捉弄了他们。
不过阻止我做实验的主要原因在于,当人们通过种种迹象判断某个网站是伪造的之后,即使我指出这些网站是真实的,也会难以说服所有人。每一条“线索”都让他们更坚持自己的想法,即使我告知他们这个网站可信度很高,但也没有多大作用。他们会和我争论,认为这不可能是权威的医学期刊。他们会说,我不相信你,你一定是哪里弄错了,你需要再次查证自己的信息!
我们的争论占用了太多课堂时间,最后我选择改用其它的教学方法,但这段经历令我想起来都有点后怕。
三、什么是真正的关键信息?
大量质量不佳的简单信息会影响你的判断,甚至会让你更加困惑。当你越试着去判断它们孰真孰假时,往往只会变得越来越迷惑。
这种情况将变得更加严重。目前我们还能根据一些典型特征去判断某张图片是否由人工智能生成,但这些法子很快将会失效。现在你还要自己去写网站上的个人简介,但机器学习会很快写出看起来更可信的自我介绍,甚至比你自己写的还要真实得多。到时候,编造这些信息不仅是容易,应该是毫不费力。
要提高人们在数字时代辨析信息的能力,我的建议是停止那套老方法。大量搜集信息,然后在受到固有思维影响的复杂框架中去分析它们已经不管用了,我们要做的是学会借助互联网的特性做出快速判断。
还是以那位假记者为例。她声称自己为彭博社写稿。
Maisy Kinsley 的个人简介
这是真的吗?她在哪发表过文章呢?我的调查结果如下:
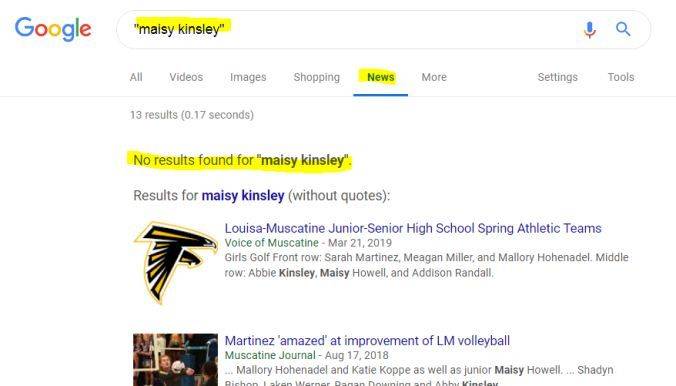 在 Google News 检索的截图
在 Google News 检索的截图
我在谷歌新闻中检索“Maisy Kinsley”,但完全没有关于她的条目。既没有相关的署名,也没有由她撰写的故事。当你在彭博的官网上搜索时,同样一无所获。
我们可以用同样的方式搜索一位最近联络我的 BBC 记者。这是谷歌新闻的搜索结果,首先是一些他为福布斯撰写的文章:
在谷歌新闻搜索 Frey Lindsay 时,出现了许多他为福布斯撰写的文章。
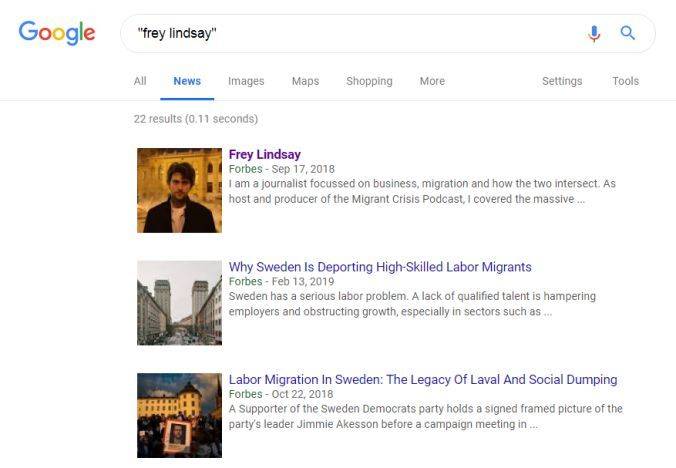
在谷歌新闻中搜索 Frey Lindsay 可以看到许多他的作品。
再往下翻时,会看见他写的其它文章,中间也包括为 BBC 撰写的:
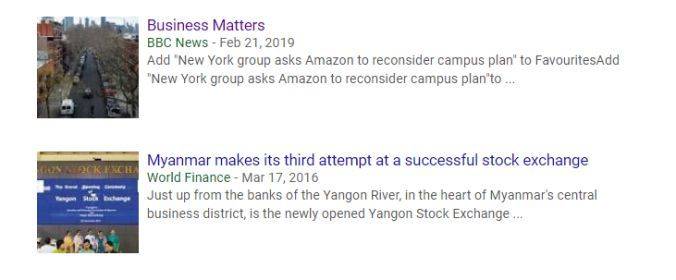
如果我们点击链接前往 BBC 官网,再次搜索他的名字时,会找到更多他写的新闻:
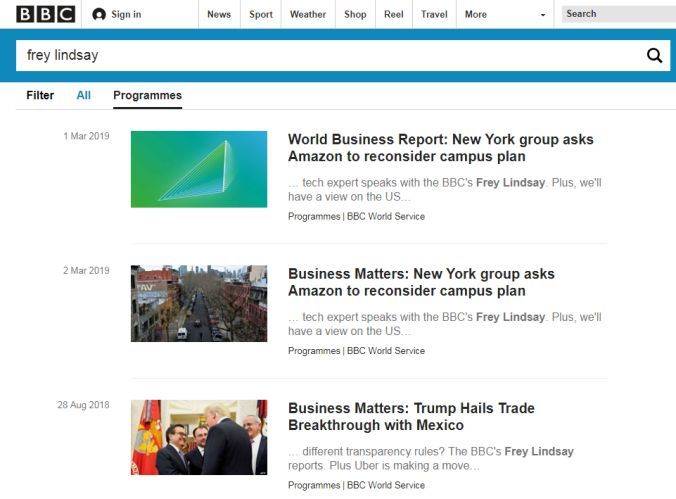
我们不用去管那些琐碎的信息,比如说他的相片、个人网站、领英页面有没有问题,也不用去管他的公司名字怪不怪,或者工作空白期是否合理。
这些鸡毛蒜皮的信息,Frey 能轻易伪造(如果他真是骗子),而我们也容易误读(如果他不是骗子)。我们要做的是找到能证明 Frey 是记者的信息。这些信息不是 Frey 自己说的,而是互联网所展示的。
真相真的“就在那里”:就在网络上,你要学习的是利用网络去找到它们。这要求你懂得什么信息容易伪造:比如领英上的联系人、自我简介的页面、相片等等;什么信息难以伪造:比如在权威的、明显有专人打理的网站上刊载的报导等等。
要提高人们在数字时代辨识信息的能力是件不容易的事。人们习惯通过某些信息来进行判断,但到了网络世界,这些信息要不就是难以找到,要不就是极容易被伪造。要学会区分哪些才是网络上重要的判断依据,是一项少人掌握的技能。你必须知道谷歌新闻的展示机制,哪些结果是有效的,哪些是无效的。
你得知道人们可以花钱买粉丝,推特上的认证信息只说明你说自己是谁,但无法证明你说的是事实。你得知道伪造一大串社交媒体使用足迹要比伪造一长串个人历史容易得多,而且为了让他们的信息在搜索页面置顶,骗子还能诱骗你使用他们想要你使用的搜索关键词。
我们常以为接受过良好的教育,就会拥有所谓的“批判性思维”。这个看似无所不能的灵药能让我们无论在哪都畅通无阻。的确,有些认知能力能放之四海而皆准,但更多时候在特定情况下才有效,而且需要学习才能掌握。在多年的数字素养研究生涯中,我仍然坚信:在借助网络辨识信息可信度方面,我们仍然有很长的路要走。
本文来自微信公众号:全球深度报道网(ID:gijn_cn),作者:Mike Caulfield,本文首发于 Mike Caulfield 的个人网站 Hapgood

 17:30
17:30









 14:11
14:11
 08:41
08:41
 10:24
10:24
 09:47
09:47
 04:48
04:48
 07:18
07:18
 07:34
07:34
 46:21
46:21
 11:46
11:46



