2020-02-06 12:20


扫码打开虎嗅APP

本文来自微信公众号: 余晟以为(ID:yurii-says),作者:余晟
如果你真的关心2019n-CoV,一定不要过多关注各种所谓自媒体的文章。这些文章大部分都没有调查能力,只能凑字数。无论引起盲目乐观还是盲目恐慌,都不是好事。今天我介绍一些国际接力合作的资源,希望对你有用。
首先登场的是GISAID。

GISAID的全称是Global Initiative of Sharing All Influenza Data(全球共享所有流感数据倡议),由多位顶尖科学家和诺贝尔奖获得者倡导成立。根据网站自述,其使命是:
GISAID力图促进下列数据的国际间共享:所有流感病毒序列、与人类病毒有关的相关临床和流行病学数据,与禽和其他动物病毒有关的地理以及物种特定数据。目的在于帮助研究人员了解病毒如何进化,传播,甚至成为潜在的重大流行疾病。
传统上,流感数据在论文正式发布之前,会遭遇到各种阻碍和限制,GISAID希望打破限制、克服阻碍,来促进数据的共享。
虽然GISAID的初衷关注“流感”,但目前已经把传染疾病也纳入其中,这当然就包括了2019n-CoV。
打开首页就可以看到,起码有三块内容是关于2019n-CoV的。其中1显示目前已经有13个国家开放共享了自己的2019n-CoV的病毒序列,2是全球的感染分布图,3是进一步的遗传变异分析(下面会详细介绍)。
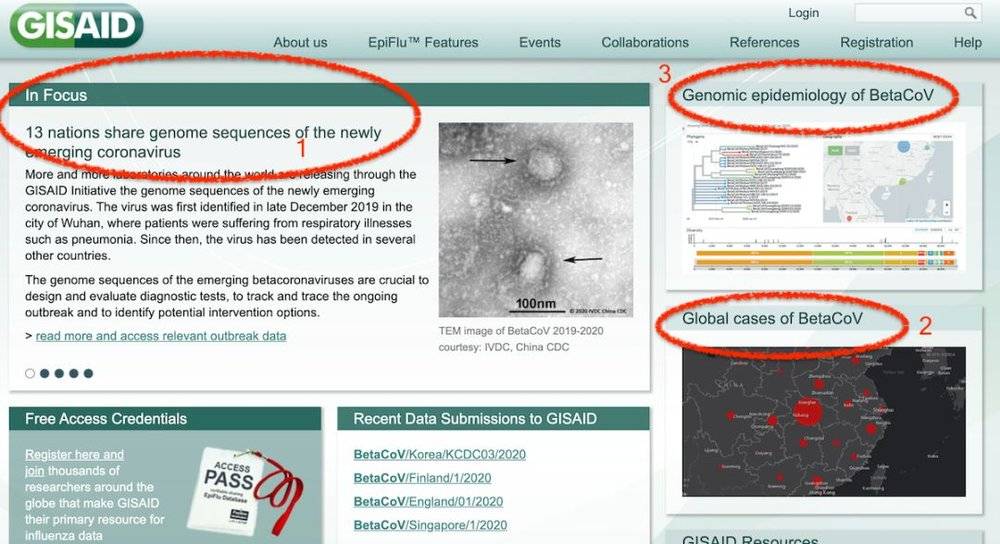
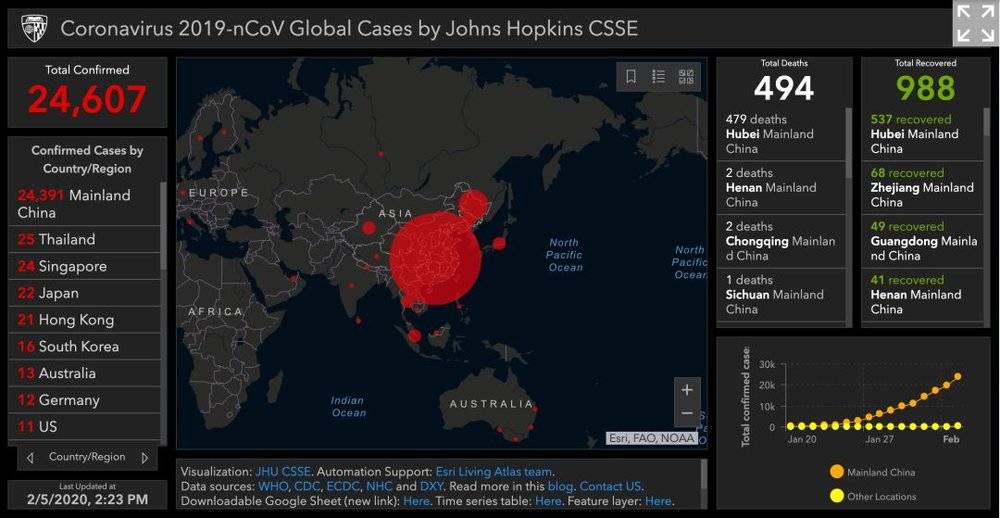
目前,世界各国都有科学家将2019n-CoV的病毒相关数据提供给GISAID,掌握这些数据之后,GISAID提供了约翰·霍普金斯大学制作的,近乎实时的全球病例分布图,这块看板非常清楚,一目了然,看得出来花了心思设计。
值得一提的是,中国的数据来自丁香园。
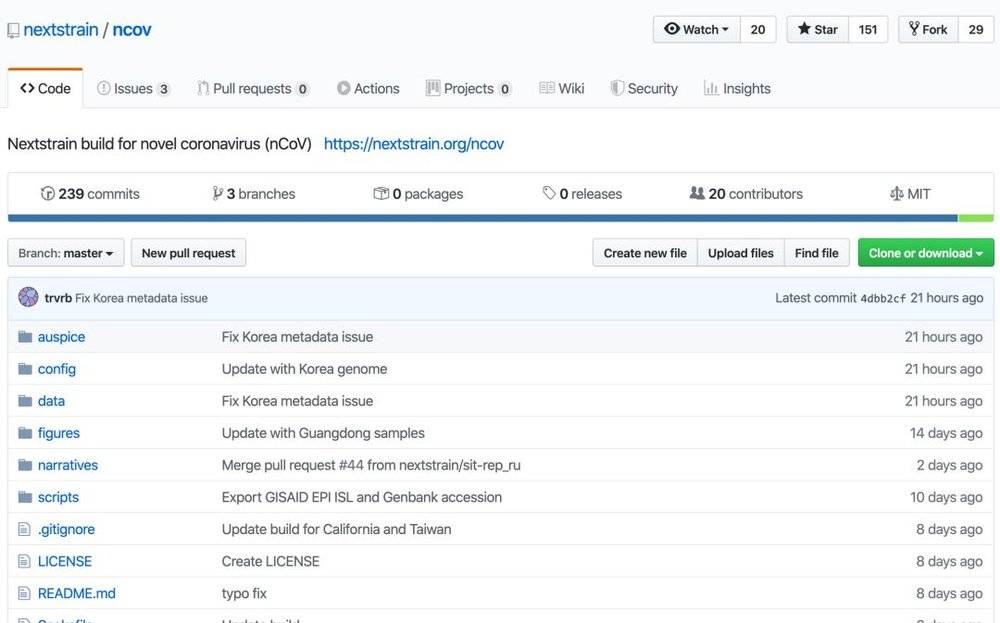
如果认为GISAID只提供了这点信息,那就错了。GISAID的目的是“共享”,所以它不会只提供成品报告,而是像开源软件运动一样,开放了元数据,所以外界可以这些共享数据作为基础,进行各种二次开发。
因此,有程序员在著名的源代码托管网站上创建了一个项目ncov,将元数据维护在其中。
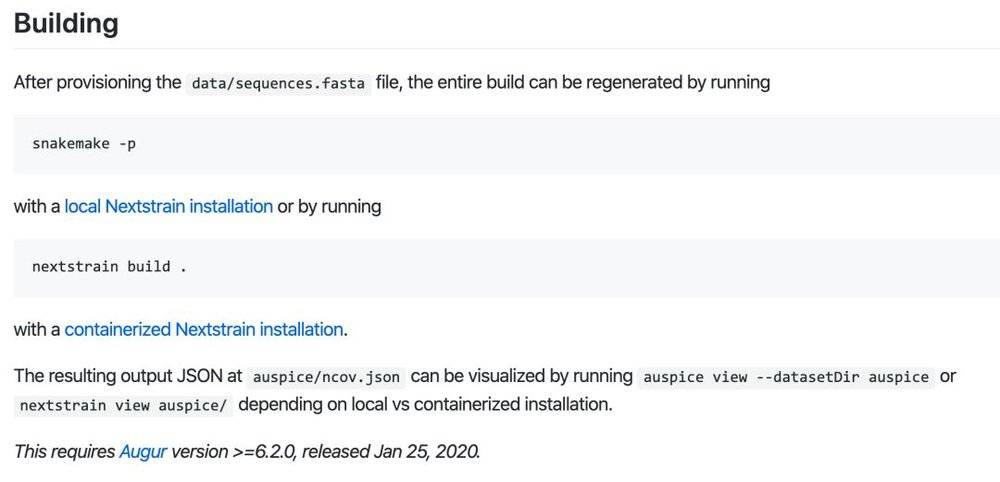
注意上面说的是元数据,根据GISAID的规范,真实的序列数据需要用户自己去GISAID下载(也是免费的),而不能直接由ncov来提供。下载完成之后的内容类似下面这样:
>Wuhan/WIV04/2019
attaaaggtttat...
>USA/IL1/2020
attaaaggtttat...
>Wuhan/WIV06/2019
ccttcccaggtaa...
其中>开头的行对应的是data/metadata.tsv中基因序列的名字,而attaaaggtttat之类就是检测出来的基因序列。有了这些数据,你可以在本地机器上使用下面的命令来生成json文件,然后用auspice或者nextstrain来做可视化。
ncov项目创建于1月19日,到现在已经有20名贡献者,239次提交,150个star,29个fork。值得一提的是,贡献者中不乏中国程序员的身影。而且,已经有人将报告翻译为中文版本。
你大概注意到了,上面出现了一个名字Nextstrain。它也是一个开源项目,目的是从病原体的基因序列中挖掘科学和公共健康的价值,根据公开的数据提供及时的查看方式,以及强大的分析和可视化工具。

目前我们看到的许多疫情报告,都是基于医学的统计数字,而比较少流行病学的分析。流行病学的分析需要关注病毒是如何传播的,传播链条是什么,在传播过程中有没有变化…… 这些信息,可以通过走访、筛查获得,也可以通过基因序列获得。
关于2019n-CoV,该网站基于GISAID的开放数据不断更新分析报告,最新的报告是1月30日的,有中文版。
查看该报告可以发现,科学家已经通过基因序列的比对,找出了病毒的变异树(有点像源代码的分支管理)。因为病毒在复制时可能发生变异,而变异会累积下来,所以通过比对基因序列,就可以分析出病毒样本的继承关系,得到病毒的发展图谱。
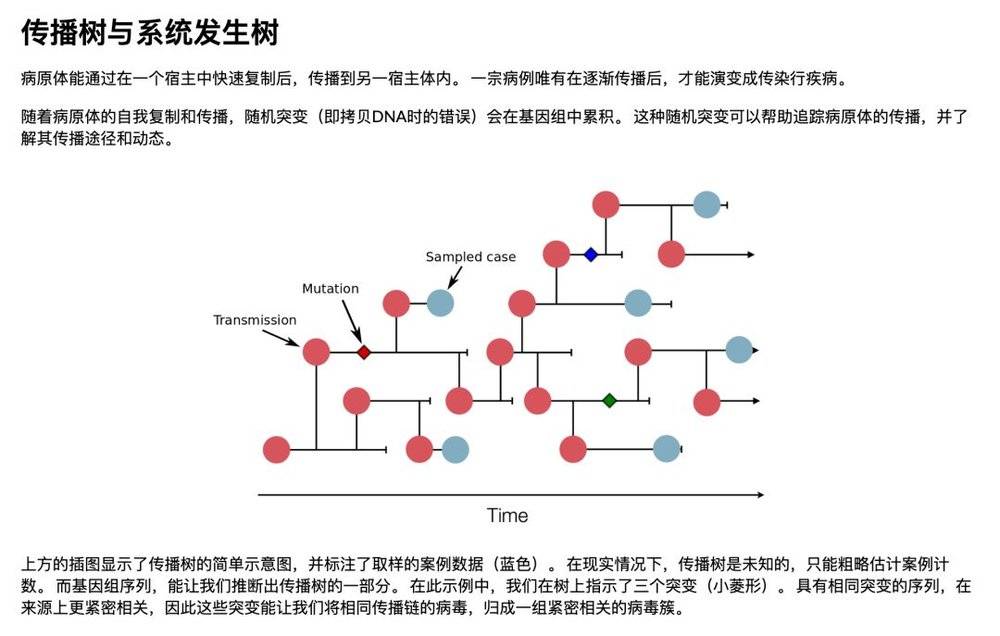
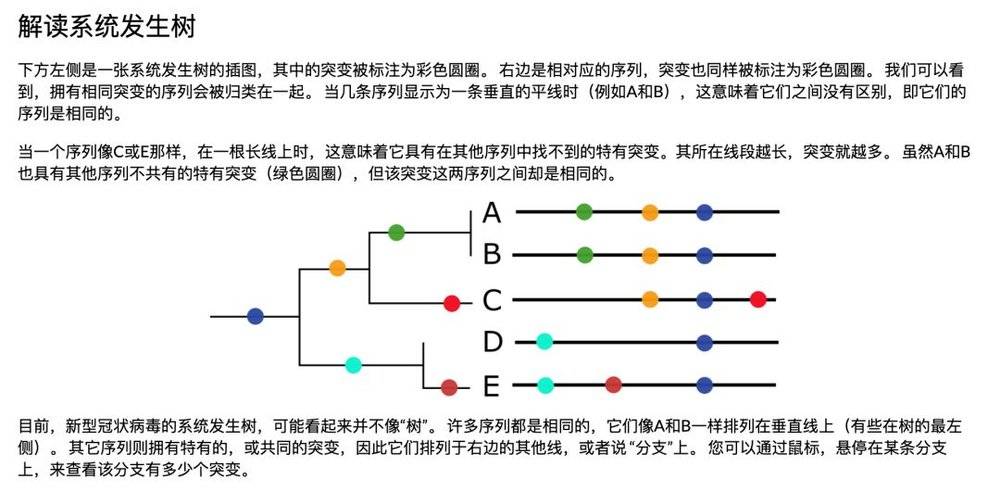
根据已经公开的42株病毒序列比对发现,有少数病毒的基因序列仍然保持不变,而其它病毒的基因序列已经发生了突变,突变的数量从1个到7个不等。
其中值得关注的是,有一组样本包含广东的一例和美国的四例,已经发生了累积的突变,最多的突变(7个)也来自这一组,这说明病毒在离开武汉之后已经开始累积突变。
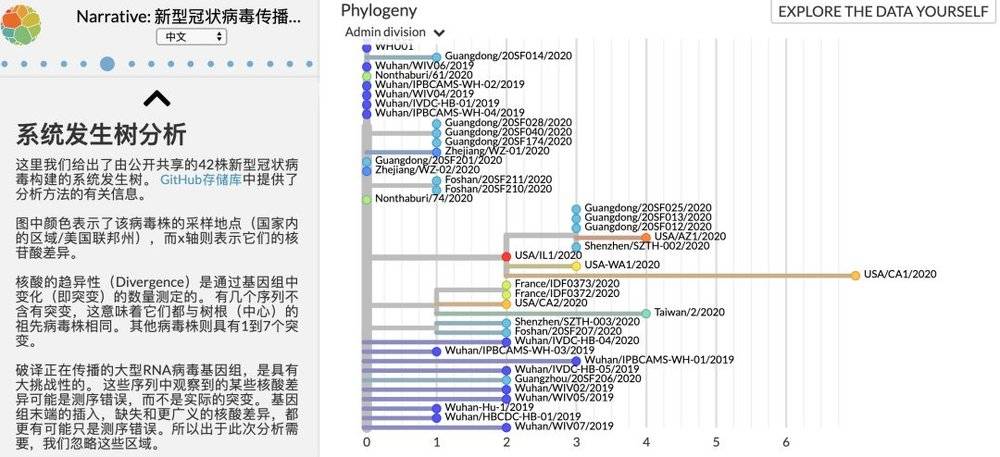

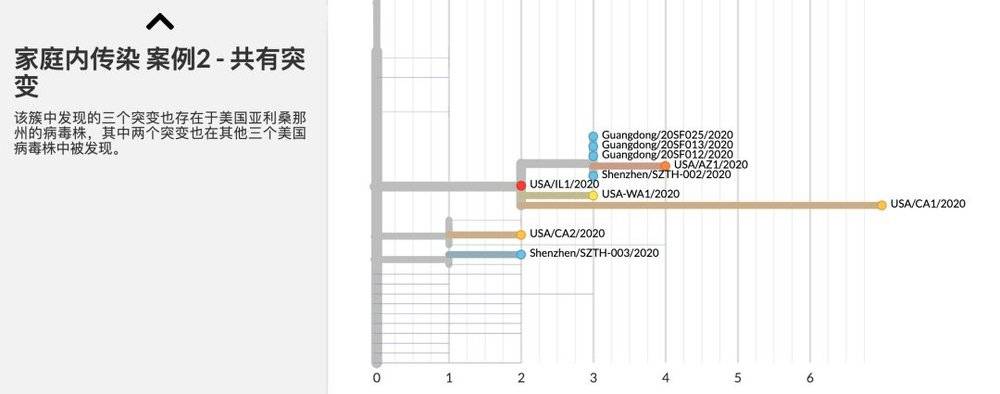
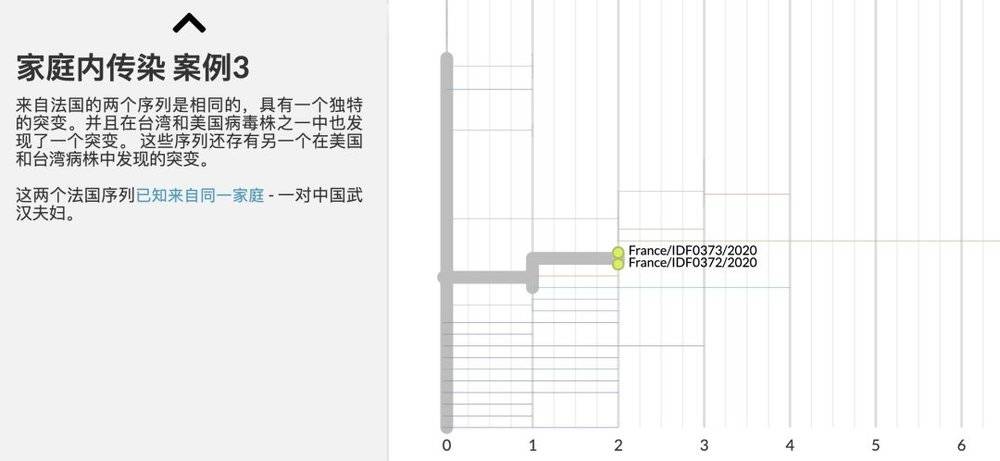
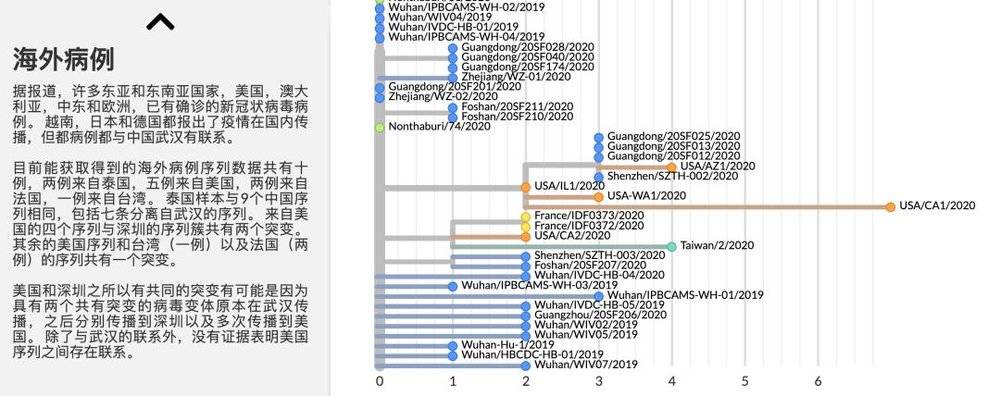
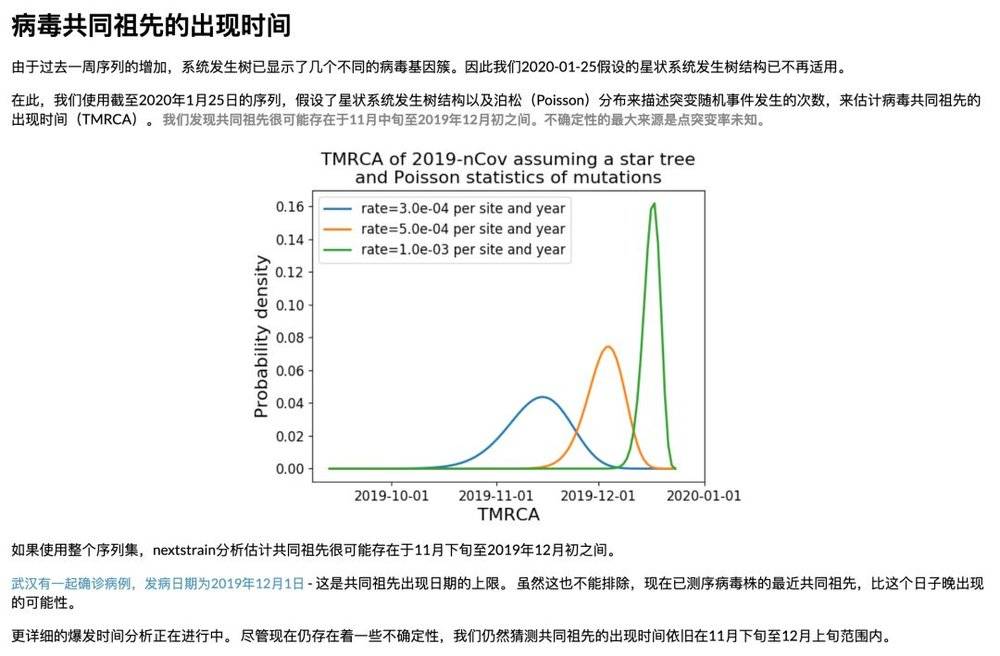
虽然目前还没有证据证明突变会改变病毒的行为,病毒的突变是正常的客观现象,但我们都不能掉以轻心。
最后我想说,经常有很多人说“正能量”,我也赞成“正能量”有用。但是“正能量”不只限于我们自己的动人故事,也应该让大家知道“吾道不孤”,在这个世界上的其它地方,还有许多聪明的头脑在无私奉献,在用科学的方法,接力协作,并肩作战,解决人类共同的难题。
你说,是这样吗?
本文来自微信公众号: 余晟以为(ID:yurii-says),作者:余晟

 08:30
08:30









 05:31
05:31
 08:15
08:15
 14:20
14:20
 07:49
07:49
 07:42
07:42
 11:58
11:58
 02:23
02:23
 06:24
06:24
 05:47
05:47

