2024-08-30 20:29


扫码打开虎嗅APP

本文来自微信公众号:量子位,作者:金磊、一水,题图来自:AI生成
Deepfake(深度伪造),再度深陷舆论的风波。
这一次,用这项AI技术犯罪的严重程度被网友直呼是“韩国N号房2.0”,魔爪甚至伸向了众多未成年人!
事件影响之大,直接冲上了各大热搜、热榜。


早在今年5月,《韩联社》便通报过一则消息,内容是:
首尔大学毕业生朴某和姜某,从2021年7月至2024年4月,涉嫌利用Deepfake换脸合成色情照片和视频,并在通信软件Telegram上私密传播,受害女性多达61人,包括12名首尔大学学生。
仅是这位朴某便用Deepfake合成了大约400个色情视频和照片,并与同伙一起分发了1700个露骨的内容。
然而,这件事情还只是Deepfake在韩国泛滥的冰山一角。
就在最近,与之相关的更多细思极恐的内幕被陆续扒了出来。
例如韩国妇女人权研究所公布了一组数据:
从今年1月1日到上周日,共有781名Deepfake受害者在线求助,其中288名(36.9%)是未成年人。

而这个“N号房2.0”也是非常恐怖的存在。
据《阿里郎》进一步的报道:
一个与Deepfake相关的Telegram聊天室,竟吸引了220000人,他们通过篡改妇女和女孩的照片来创建和分享伪造的图像,受害者包括大学生、教师,甚至是军人。
不仅是受害者有未成年人,甚至加害者也有大量的青少年。
不仅如此,这次舆论的兴起过程也非常drama。
因为肇事的韩国男性们(以下简称韩男)可以说是非常的猖獗,有舆论苗头的时候,他们就会稍微“克制”一下:

有些韩男对这件事的态度较为恶劣,甚至有初中男生公开写道“不用担心,你不够漂亮,不至于被Deepfake”这种话。

于是乎,韩国女性们(以下简称韩女)的反击开始了。
她们将“阵地”转向韩国之外的社交媒体,例如在X上,有人发布了制作Deepfake学校的地图:

还有韩女在微博中发布“求救贴”:


随着舆论在各大社交媒体上发酵,韩国政府也出面做出了表态:
目前已经有超过200个学校受到Deepfake影响;计划将Deepfake犯罪的刑期从5年提高到7年。
据了解,韩国警方已成立特别工作组,专门应对深度伪造性犯罪等虚假视频案件,该工作组将运行到明年3月31日。
Deepfake已逐渐进化
事实上,最新Deepfake技术已经进化到了“恐怖”阶段!
生图AI Flux以一组真假难分的TED演讲照片,引起千万X(前推特)网友在线打假。(左边由AI生成)

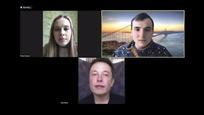
深夜直播的“马斯克”,也吸引了上万群众围观打赏,甚至搞起了网友连麦。
要知道,整场直播仅用一张图片就能实现实时换脸。

这一切果真如网友所言,Deepfake已将科幻照进现实。

其实,Deepfake一词最早起源于2017年,当时一名Reddit用户“Deepfakes”将色情女演员的面部替换成了一些美国知名演员,引起一片争议。
而这项技术可以追溯到2014年,Goodfellow与同事发表了全球首篇介绍GAN的科学论文。
当时就有迹象表明,GAN有望生成仿真度极高的人脸。

后来随着深度学习技术的发展,自动编码器、生成对抗网络等技术逐渐被应用到Deepfake中。
简单介绍下Deepfake背后的技术原理。
比如伪造一个视频。其核心原理是利用深度学习算法将目标对象的面部“嫁接”到被模仿对象上。
视频由是连续的图片组成,因此只需要把每一张图片中的脸替换,就能得到变脸的新视频。
这里要用到自动编码器,在应用于Deepfake的情况下输入视频帧,并编码。

△图源:维基百科
它们由编码器和解码器组成,编码器将图像减少到较低维的潜空间,解码器从潜表征中重建图像。
简单说,编码器将一些关键特征信息(如面部特征、身体姿势)转换成低维的潜在空间表示,而解码器将图像从潜在表示中恢复出来,用于交给网络学习。
再比如伪造图像。
这里主要用到生成对抗网络(Gan),它是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。(此方法也可以用于伪造视频)

第一个算法称为生成器,输入随机噪声并将其转换为图像。
然后,该合成图像被添加到真实图像流(例如名人图像)中,这些图像被输入到第二个算法(称为判别器)中。
判别器试图区分样本来源于真实还是合成,每次注意到二者之间的差异时,生成器都会随之调整,直至最终再现真实图像,使判别器无法再区分。
然而,除了让外观上看起来无法区分,当前的Deepfake正在施展“组合拳”:声音克隆也升级了。现在,随便找一个AI工具,只需提供几秒原音,就能立马copy你的声音。
用合成声音伪造名人的事件也层出不穷。

此外,1张图生成视频已不再新奇,而且目前的工作重点在于后续打磨,比如让表情、姿势看起来更自然。
其中就有一项唇形同步技术(Lip syncing),比如让小李子开口说话。

如何识别Deepfake?
虽然Deepfake现在已经很逼真了,但下面还是给大家介绍一些识别技巧。
目前网络上大家讨论的各种方法,归纳起来就是:
不寻常或尴尬的面部姿势
不自然的身体运动(肢体畸变)
着色不自然
音频不一致
不眨眼的人
皮肤的衰老与头发和眼睛的衰老并不相符
眼镜要么没有眩光,要么有太多眩光,并且无论人如何移动,眩光角度都保持不变。
放大后看起来很奇怪的视频
……
得,列文虎克看了直呼内行,不过单凭肉眼观察着实有点费人了!
更高效的方法还得是,用魔法打败魔法——用AI检测AI。
国内外知名科技企业均有相关动作,比如微软就开发了一种身份验证工具,可以分析照片或视频,并对其是否被操纵给出评分。
OpenAI此前也宣布推出一款工具,用于检测由AI图像生成器DALL-E 3创建的图像。
在内部测试中,该工具在98%的时间内正确识别了DALL-E 3生成的图像,并且能以最小的影响处理常见修改,如压缩、裁剪和饱和度变化。
芯片制造商英特尔的FakeCatcher则使用算法分析图像像素来确定真假。
而在国内,商汤数字水印技术可将特定信息嵌入到多模态的数字载体中,支持图像、视频、音频、文本等多模态数字载体。官方称这种技术能保证超过99%的水印提取精度,且不会损失画质精度。
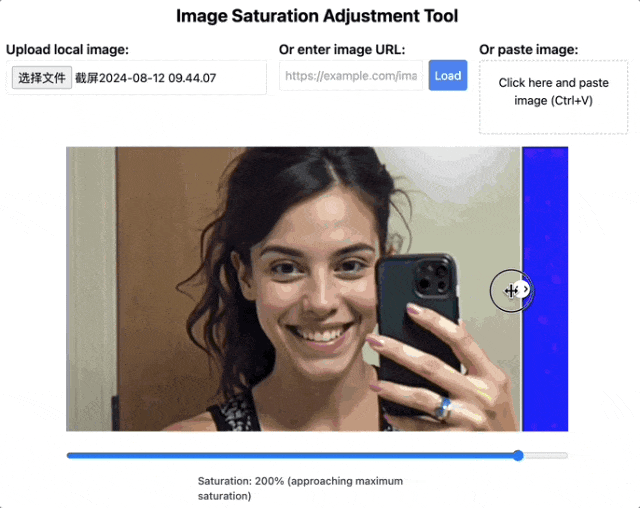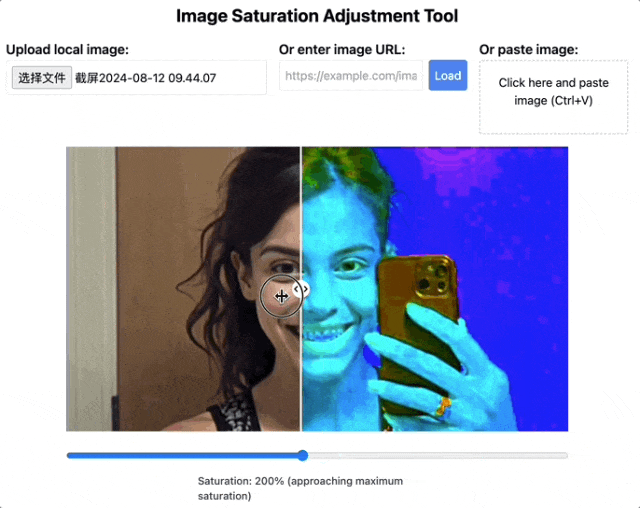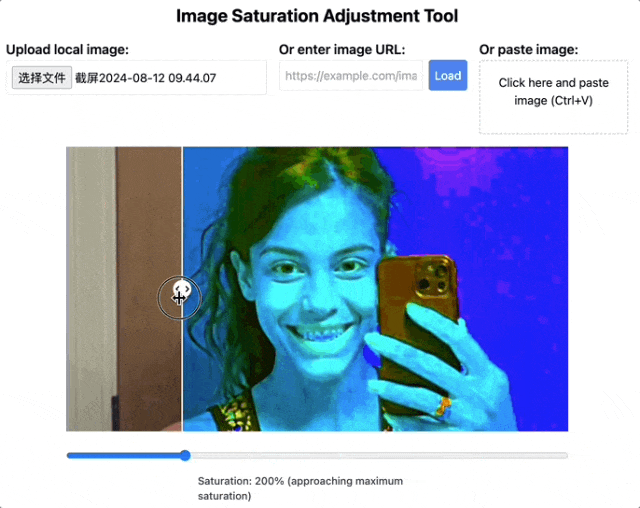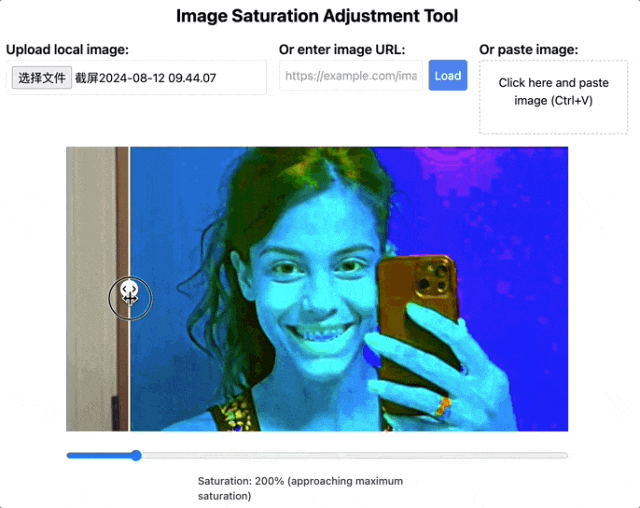
当然了,量子位此前也介绍过一种很火的识别AI生图的方法——调整饱和度检查人物牙齿。
饱和度拉满下,AI人像的牙齿就会变得非常诡异,边界模糊不清。
Science发文:需要标准和检测工具
就在8月29日,Science也发表了一篇文章对Deepfake进行了探讨。

这篇文章认为,Deepfake所带来的挑战是科学研究的完整性——科学需要信任。
具体而言,就是由于Deepfake逼真的造假,以及难以检测等原因,进一步威胁到对科学的信任。
而面对这一挑战,Science认为应当“两手抓”,一是使用Deepfake的技术道德标准,二是开发精准的检测工具。
在谈及Deepfake与教育发展的关系时,文章认为:
尽管Deepfake对科学研究和交流的完整性构成重大风险,但它们也为教育提供了机会。
Deepfake的未来影响将取决于科学和教育界如何应对这些挑战并利用这些机会。
有效的错误信息检测工具、健全的道德标准和基于研究的教育方法,可以帮助确保Deepfake在科学中得到增强,而不是受到Deepfake的阻碍。
总而言之,科技道路千万条,安全第一条。
One More Thing
当我们让ChatGPT翻译相关事件的内容时,它的反应是这样:

嗯,AI看了都觉得不妥。
参考链接:
[1]https://en.yna.co.kr/view/AEN20240826009600315
[2]https://en.yna.co.kr/view/AEN20240828003100315?input=2106m
[3]https://en.yna.co.kr/view/AEN20240829002853315?input=2106m
[4]https://www.arirang.com/news/view?id=275393&lang=en
[5]https://www.science.org/doi/10.1126/science.adr8354
[6]https://weibo.com/7865529830/OupjZgcxF
[7]https://weibo.com/7929939511/Out1p5HOQ
本文来自微信公众号:量子位,作者:金磊、一水

 07:41
07:41







 08:08
08:08
 08:28
08:28
 08:14
08:14
 07:12
07:12
 07:34
07:34
 16:10
16:10
 15:28
15:28
 05:33
05:33
 09:39
09:39



