2020-07-02 11:53


扫码打开虎嗅APP

本文来自微信公众号:把科学带回家(ID:steamforkids),作者:七君,原文标题:《谷歌是怎样扫描2500万本书的?出错图片揭开了谷歌的土味操作》,题图来自:原文供图
我们想要搜索某个网站、某条新闻,在搜索引擎里输入几个关键字就可以了,很方便。一些软件甚至可以通过拍照识别题目,然后给出解答。但是,在网上搜索某本书里的内容却很难,除非这本书已经被转成了电子版。
如果能把市面上的书都变成电子版,那么几千年前古人的思想也能上线,TA的言论和当代明星的发言一样可以通过网络被搜索到。古往今来的思想家一下子就在网络上“重生”,鲁迅曰没曰过什么搜一下都能知道,这是一件利在千秋的好事呀。
谷歌创始人也有这个心愿,联合创始人之一的谢尔盖·布林曾说:“人类几千年的知识,或许是最高质量的知识都在书本里。”
2002年,谷歌启动了雄心勃勃的书籍数字化项目 Project Ocean,想要创立一个全球最大的数字图书馆。谷歌的设想是,只需要一台能联网的电脑,你就可以搜索和阅读数千万本书籍,就和浏览网页一样方便。
2004年,谷歌开始正式扫描。密歇根大学、哈佛大学、斯坦福大学、牛津大学和纽约公共图书馆纷纷加入了进来。
2010年,谷歌宣布要扫尽全世界的1.2亿本书。根据2015年10月28日《纽约时报》的报道,谷歌已经扫描了超过2500万册书籍了。
为了扫描这些书,谷歌年支出4亿美金,设立了专门的扫描中心。在这些扫描中心里,设置着专门的扫描架子,上面配有上千美元的光学镜头,还有用来探测书页曲率的光学雷达LIDAR。
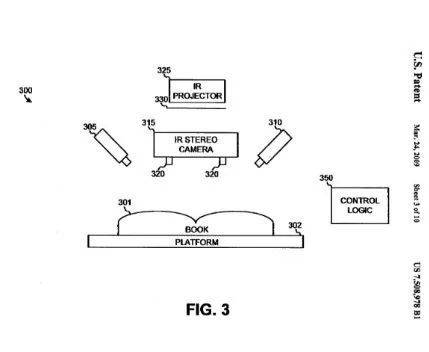
谷歌的7508978专利里采用的扫描技术
为什么不用传统的扫描仪呢?
因为一些书比较老旧,也比较厚,不能暴力压在扫描仪上扫,更不能拆开,只能自然摊开。因为这个原因,扫描完的书页其实是弯曲的,为了自动把页面捋直,谷歌还自主研发了一套技术,并申请了专利7508978。
这个技术叫做光学字符识别(Optical Character Recognition),可以理解为一种后期技术,可以把弯折的书页自动铺平,并把图片里的文字转化为字符,让我们能够用关键词搜索到。随着这个项目技术的进步,一开始一本300页的书要40分钟扫完,现在已经可以做到一小时扫6千页了。
看起来谷歌的扫书技术非常高大上,是吗?
其实,谷歌扫书设备并不是完全的自动化,有一个步骤还是需要手动,那就是翻书。人类操作员翻一页书,踩一下踏板,扫描设备就扫一次。
本来这件事儿是谷歌的商业机密,但是后来被一位叫做 Andrew Norman Wilson 的艺术家曝光了。
Wilson 说,他曾在2007年在谷歌加州的 Mountain View 园区工作过,那些负责书本扫描的员工的工牌颜色和正牌员工不一样,也不能享受他们的福利,比如骑谷歌自行车,免费员工餐,还有公司的班车。后来,他还专门把谷歌图书里出现的戴着套子的手指书页截图收藏了起来,大家来看看——

当然,谷歌也不是没试过全自动扫描。从公开的专利记录来看,谷歌的一个叫做 Dany Qumsiyeh 的工程师就曾设计了一款价格很并夕夕的全自动扫描仪。
这个小哥造的自动扫描仪原型机只需要1500美金的材料费。使用的字符数字转化软件也都是开源的,意思就是不要钱。
它工作起来是这样的——

书被架在一个三角形的金属架上面来回运动。在经过这条缝的地方,下方传感器会扫描页面——

在书经过这个开口的地方,就会翻页。

这个翻页的技术看起来也很简单,就是用吸尘器一样的装置把一页纸吸住,然后让它自动滑到三角架的另一边去。

小哥用了50来本不同类型的书做了测试,其中60%的书都能用这款扫描仪扫。整体来看300页的书只要半小时就能扫好。
不过可惜的是,这款原型机在扫描时,45%的书出现了折页或撕破的情况。
虽然小哥的全自动扫描仪在2011年被谷歌申请了专利(US8711448B1),不过谷歌允许任何人无偿使用这种设计,看来是不太看好它的前景了。

谷歌允许无偿使用这种全自动扫描仪设计 图片来源:code.google.com/archive/p/linear-book-scanner/
难道说都2020年了,世界上还没有真正的全自动扫描仪吗?
有是有,但是贼贵,而且出错率未知。世界上第一台全自动扫描仪是瑞士4DigitalBooks 公司制造的DL (Digitizing Line) scanner,斯坦福大学在2001年入手了一台。

4DigitalBooks 公司制造的全自动扫描仪
Kirtas 公司也有全自动扫描仪,是靠一个类似人手的机械臂上的真空吸口翻页的。


但是,Kirtas 家的扫描仪可不便宜,价格最低的型号也要9千美金一台,家用是不太可能了。约翰霍普金斯大学在2008年购入了 Kirtas 家出的一台APT 2400。上海商学院的古籍部也曾入手一台用于无接触扫描古籍。
另外一家比较大的自动扫描仪公司出品的 Treventus ScanRobot 也是一页一页吸纸,边吸边扫描。这个机器刚上市的时候价格达到了10万美金。

2012年,东京大学的 Ishikawa Oku 实验室也研发了一款更为华丽的全自动扫描仪 BFS-Auto。

它每分钟最多只能扫300页,尚未达到量子波动速读的水平

但是,它却可以实时追踪页面的3D形态,页面色彩和曲度可以自动数码矫正。

东京大学的这款全自动扫描仪翻书不是靠吸,是靠吹,机器吹,不是嘴巴吹。

根据该实验室的测量,这个翻书仪的成功率达到了100%。希望这种自动扫描仪能早日平民化,这样学生党就不需要扛着一手提箱的书上学了,复习查资料也会更方便。
当然,以上都是技术层面的探讨,数字化书内页还有很大的法律风险。
因为动静太大,2011年谷歌陷入了和出版商以及作者的官司,原告们不希望谷歌将自己的作品无偿地公开化,供人免费搜索和浏览。
虽然2013年谷歌赢了官司,但看起来这个图书项目陷入了死胡同,总之现在我们不清楚谷歌是否还在继续扫书,新扫的书是否能被大家看到。其他财力和技术没这么雄厚的搜索引擎就更不用提了。
诸子百家的肉身虽然已经上了天,他们的思想什么时候才能全体上“云”端呢?
请介绍一下你在谷歌的工作。
我就说3点:
一,我做的是谷歌工程师也无法解决的事;
二,和程序员一样,我用的是人类区别于其他动物的最重要的解剖结构;
三,我的工作是保密的,谷歌不希望别人知道。
本文来自微信公众号:把科学带回家(ID:steamforkids),作者:七君

 07:20
07:20



 08:35
08:35


 13:18
13:18
 11:03
11:03

 11:57
11:57

 09:31
09:31
 12:02
12:02

 13:40
13:40
 06:25
06:25

 09:23
09:23




