2020-07-24 08:30


扫码打开虎嗅APP

日前神秘网友利用唇语识别,解读《隐秘的角落》中被改掉的台词,原始内容比想象中更加黑暗。
其实让计算机读唇并不是什么新鲜事,早在 2003 年,Intel 就推出过能读唇的语音识别软件。

目前的唇语识别大体分为四步:通过图像识别找到视频中的说话人,提取连续的口型变化特征。
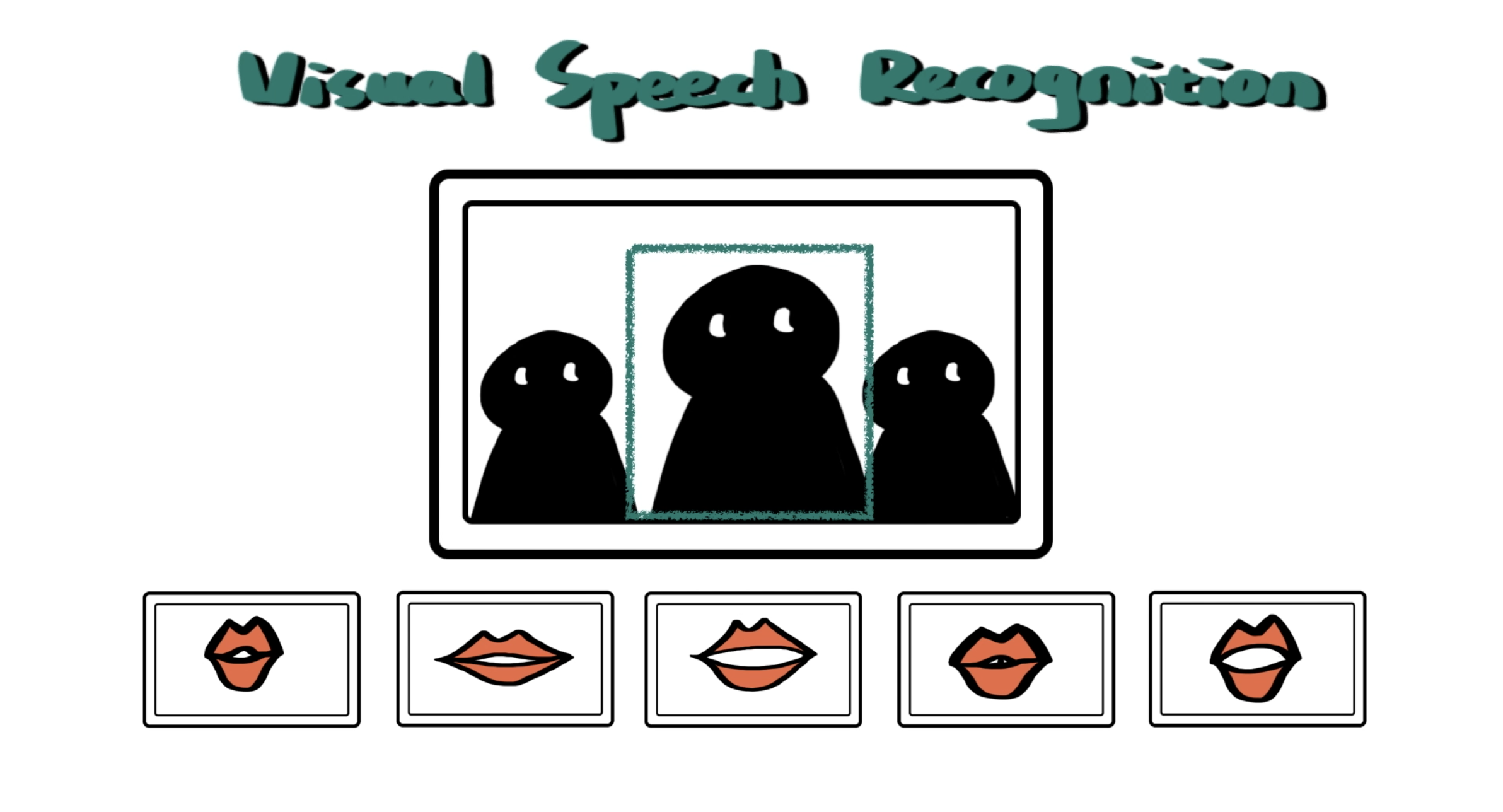
由识别模型找到特征对应的发音,再计算出可能性最大的自然语言语句。

2016 年,牛津大学先是联合 Deepmind 发布 WLAS(Watch, Listen, Attend band Spell )模型,通过使用 5000 个小时的 BBC 新闻节目进行训练,在测试集上可以达到 46.8% 的识别准确率。

随后他们又联合发布了 LipNet,可以在公式化语句上实现 95.2% 的准确率。两年后 Deepmind 发布论文《大规模视觉语音识别》,将词错率进一步降低至 40.9%。
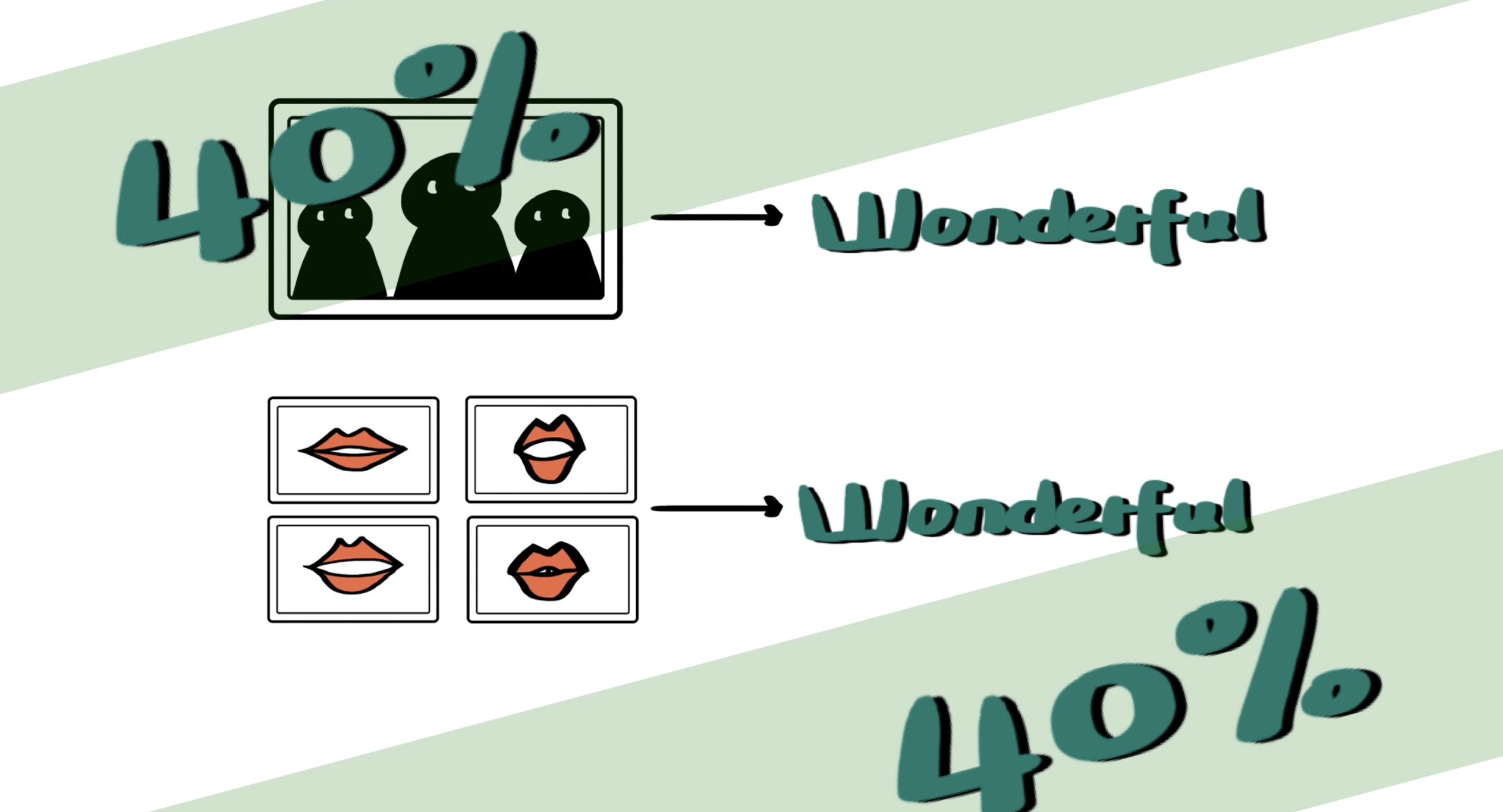
端到端也好,基于单词也罢,不同语言的唇语识别模型准确率一般在 40% 左右。在图像识别准确率动辄 90% 以上的今天,唇语识别的准确率为什么这么低?
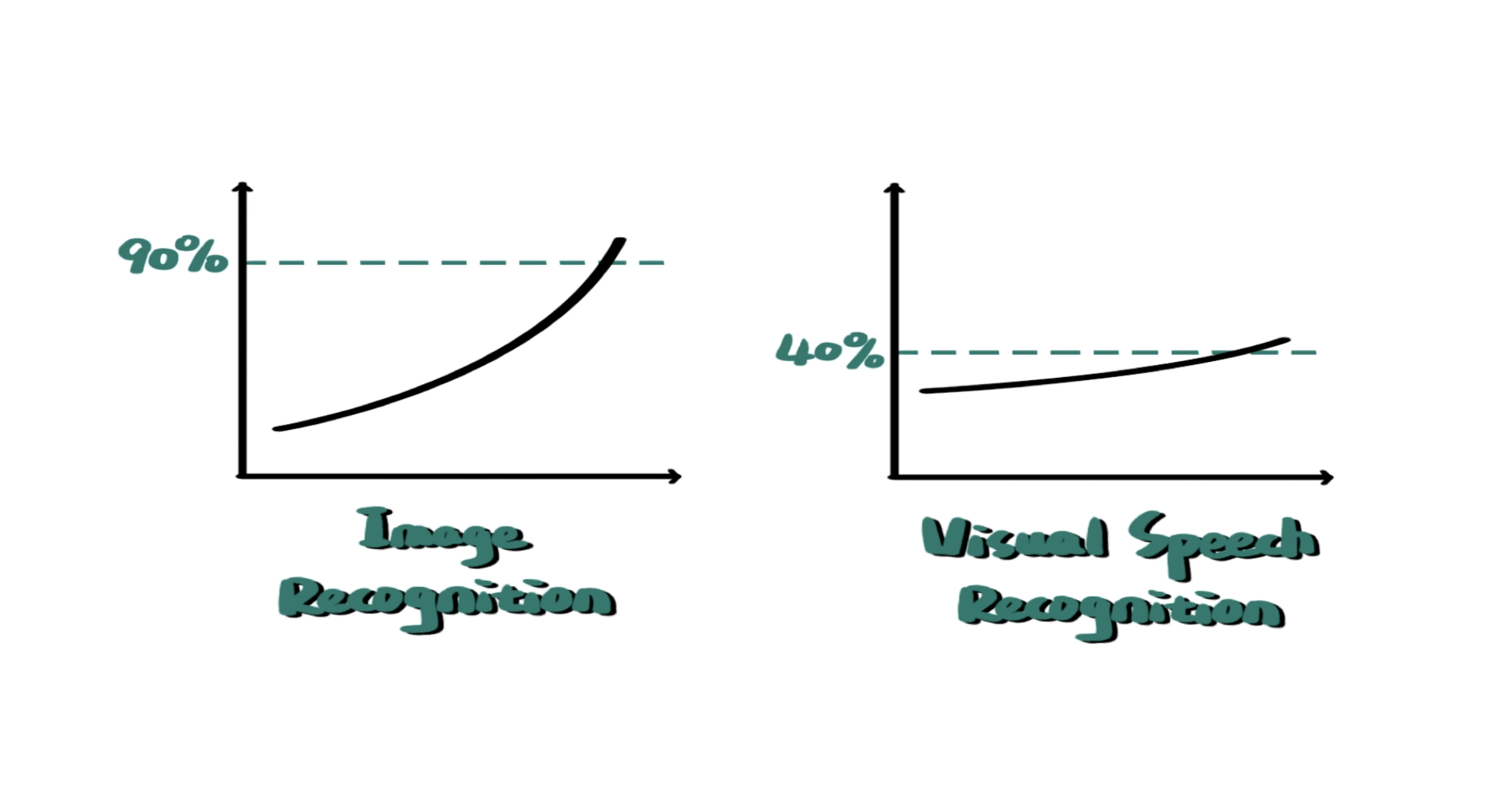
那是因为读唇本身准确率就很低。
很多在听觉上完全不同的声音,在唇部动作上几乎一致。
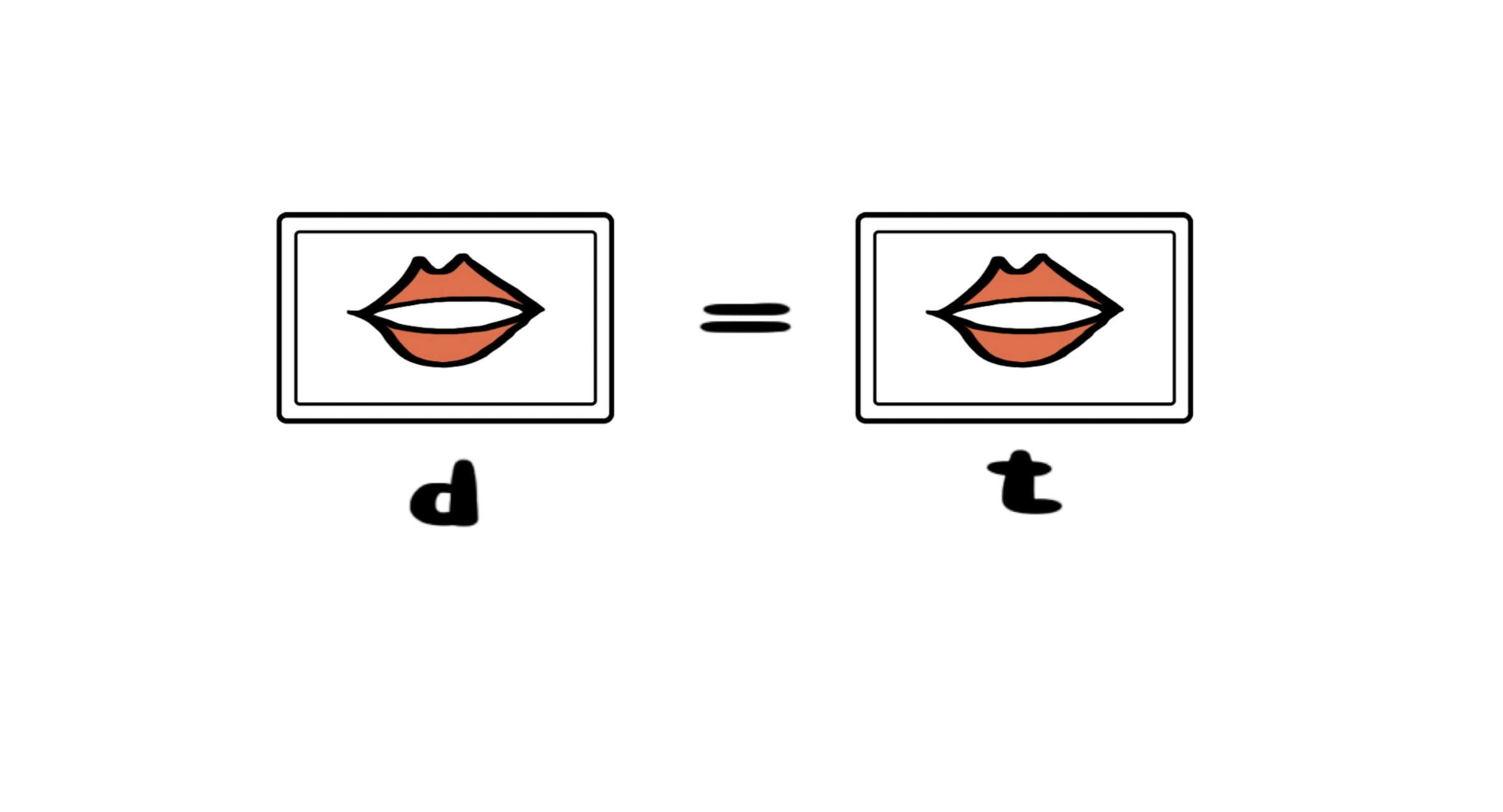
有经验的专业读唇者,会借助语境、上下文、表情、手势等边缘信息帮助还原语言。

但即使是人类中最为熟练的读唇师,也只能解读 40%-50% 左右的唇语。

准确度这么低,唇语模型有什么用?
最大的应用是为语音识别提供帮助。还记得鸡尾酒会问题吗?如果背景声太过嘈杂,或是多人共同谈话,语音识别的准确率会受到很大影响。唇语识别可以通过定位说话人提供更多语言信息,从而提升语音识别的准确率。

 01:18
01:18
 32:45
32:45
 13:10
13:10
 05:38
05:38
 07:12
07:12
 01:24
01:24
 01:13
01:13
 16:10
16:10
 08:28
08:28
 01:13
01:13



