




2020-08-17 17:29

扫码打开虎嗅APP


本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:郭瑞东,编辑:曾祥轩,题图来自:《超级马里奥》
导语
近年来,很多AI技术的突破都离不开游戏的影响,不论是古老的围棋还是即时战略类的星际争霸都体现着这样的交融。同时,游戏和AI的跨界合作,还在通过算法,生成新的游戏规则上有所展现,从而让机器学习的算法,具有更强的泛化能力。8月3日的 Nature Machine Intelligence 推出的综述论文,先介绍了游戏行业中的“过程生成”(Procedural content generation)这一概念,从现有应用,和机器学习的关系,以及面临的问题,全面阐述了这一新的跨学科研究方向。
1. 让游戏每一次玩都不一样
通过算法,产生游戏中的背景信息,例如游戏中的关卡,任务,环境等,在游戏界被称为“过程生成”。自从1980年首次提出后,该技术在游戏界得到了广泛地应用。从最简单的俄罗斯方块,到我的世界Minecraft这样的开放游戏,都能见到该技术的身影。
在著名的策略类游戏“席德梅尔的文明”系列中,每一局游戏的地图,都会有所不同,正因如此,使得玩家愿意多次玩该游戏。为了保证每局地图不一致,一种做法是在游戏中预设很多地图,另一种做法是通过算法,每次开始时自动生成地图。显然后者能减少游戏所需的计算机存储空间。

图1:游戏《文明6》产生的随机地图
如何在产生上述地图时,既保证每一局游戏的开局都不同,又确保玩家不会由于开局的随机因素,觉得游戏难度发生显著变化。一种可能的生产方式是元胞自动机,通过玩家给定的参数,算法能够从某一点出发,逐步依据游戏设计者预设的规则,逐格扩展,产生新的地图。
2. 数据增强,机器学习中的过程生成
在机器学习中,要想提升模型的泛化能力,一种常用的技巧是数据增强(data argumentation),即在有监督学习范式下,通过加入基于现有训练数据集,经过特定转换的模拟数据集,从而扩大训练数据集包含的多样性,进而提升训练得出模型的泛化能力。
具体来看,在猫狗图像分类任务中,可以将原图拉伸,翻转,或者裁剪部分区域,再将新生成的数据和原数据一起进行训练。如此训练出的模型,能够更好地提取猫和狗的本质特征,从而使得模型在新数据集上表现更优,稳健型更强。
在强化学习范式下,通过在训练环境中引入随机因素,例如训练扫地机器人时,每次的环境都有所不同,也可以提升模型的泛化能力。而如果将扫地机器人执行的任务看成一次游戏,那么机器学习中的数据增强,就相当于游戏设计中的“过程生成”。两者都是通过随机数据,让玩家能够透过现象看到本质。
3. 数学化的网络科学
在未来会有哪些突破?
在机器学习成为主流之前,AI领域常用的方法是从一系列可能的解中,通过搜索找出(局部)最优解。将该类方法,应用到游戏生成中,下面是一个典型的案例[1],即自动生成超级马里奥的关卡。
具体方法是将游戏的地图分为微观(micro),中观(meso)和宏观(macro)模式,算法的目标是根据不同的难度,设定需要得出的对应宏观模式,之后通过搜索中观模式的组合,组成宏观模式,再通过逐个搜索不同的微观模式组合,得到对应的中观模式。
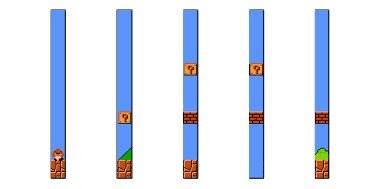


图2:超级马里奥中,不同的微观模式,中观及宏观模式示例图
通过逐层的自下而上的搜索,该算法能够根据最初的游戏地图,生成在统计上呈现出相同特征,进而具有相近游戏难度的全新关卡地图。下图是超级马里奥原版的第一关,和由算法生成的第一关。
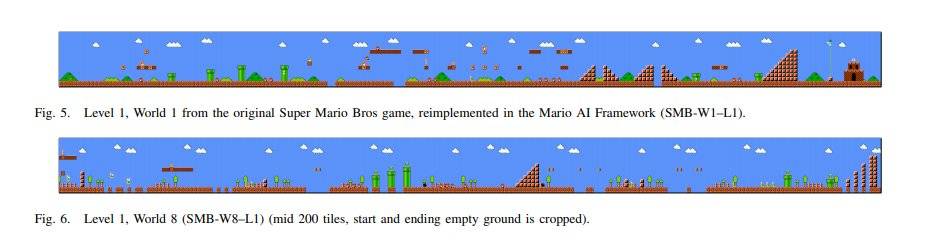
图3:真实和生成的游戏地图对比
未来,研究人员和具有科学头脑的政策制定者或许可以利用这些进展,对尚未观测到的复杂网络现象进行定量预测。
4. 通过深度学习生成新游戏:对抗生成网络的例子
对抗生成网络(GAN)是近五年来,深度学习中进展最快的领域之一。如果将生成新的超级马里奥的任务交给GAN,它会怎样完成?18年的ACM论文给出了回答[2]。
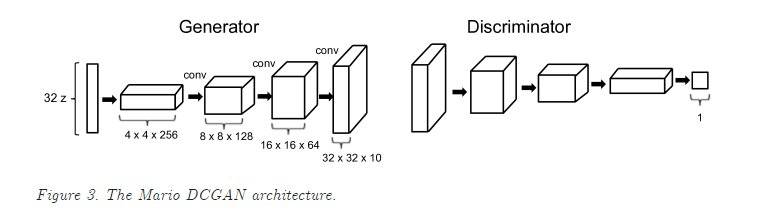
图4:深度卷积对抗生成网络结构示意图
该文采用深度卷积对抗神经网络,使用已有游戏地图的一部分,作为训练数据,通过生成器,产生新的游戏地图,再通过判别器,判断生成的游戏地图,是不是和真实地图类似。之后通过在最初的图片中进行修改,据此迭代,不断改进生成器。

图5:从最左的图,随机变化,生成右图的几种可能地图,并随机选一个进行下一轮迭代
由此,使得生成的地图中,先不会诸如出现无法跳过的沟等影响可玩性的特征,再逐渐模仿不同难度的游戏关卡中所会出现的障碍物,使得生成的游戏地图具有相近的难度。
相比传统的方法,基于GAN的关卡生成,能够在玩家游戏的过程中,根据玩家的操作,动态地改变下一关游戏的难度,这是传统的基于搜索的方法无法实现的。除此之外,还能按照特定的目标,设计关卡。
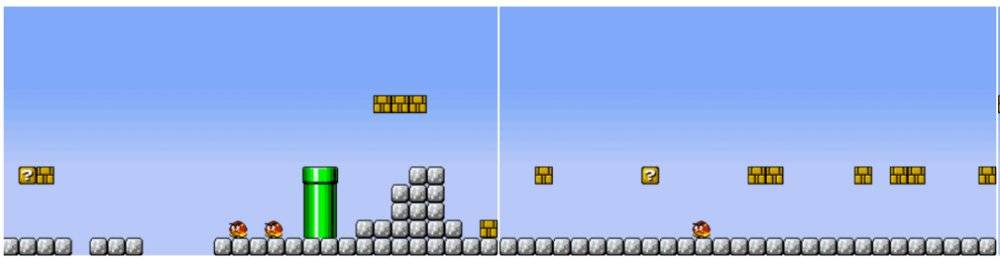
图6:最大化和最小化跳跃的关卡
例如,如果想要玩家在游戏中尽可能多的跳跃,通过修改GAN的约束条件,可以生成左图的地图,而若想要最小化跳跃,则可以生成类似右图的关卡。
5. 通过强化学习生成游戏
另一类生成游戏关卡的方式,是强化学习。如果要用强化学习生成超级马里奥的地图,算法需要一个估值函数,计算不同游戏图片,距离理想的关卡有多远。和GAN类似,强化学习范式下,同样是从随机的关卡开始,不断改进,通过迭代完善设计。不同的是,由于估值函数的存在,每一次的改变不是随机的,而是有方向的。
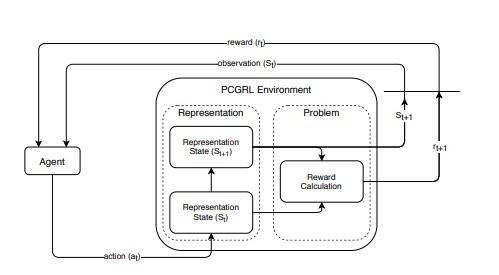
图7:强化学习生成游戏的流程图
上图中[3],关键的一点是如何对游戏的设计进行表征,不同的表征,决定了设计出的游戏关卡会具有不同的特征。上图中的估值函数,除了判断相比上一次,本次生成的游戏关卡是不是更优,还会判断生成的关卡是否是“可玩的”,如果是,则停止迭代。
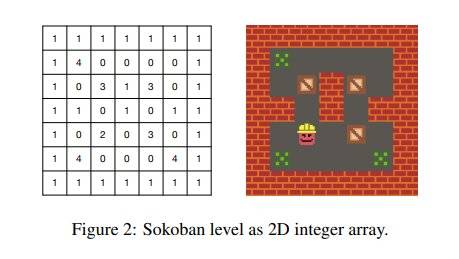
图8:推箱子游戏地图的二维表征
例如推箱子这个游戏,玩家通过上下左右,操纵小人行动,推动箱子到指定的位置,则算通关,上图是推箱子地图的二维矩阵表示。每轮迭代,修改的就是左图的矩阵。
设计游戏关卡的智能体(agent),需要在给定箱子和目标的距离时,让小人走的步数尽可能多,从而提升游戏的难度,这就是前文提到的奖励函数。
而如何判断每张地图需要多少步才能走完,则需要智能体通过搜索完成。如果搜索时,智能体只能记住这一步所走格子和改变的那个格子状态,那么称之为狭窄表征;如果能记住运行方向上的每个格子以及自己改变了那些格子的状态,称之为Turtle式的表征;而如果能记住当前格子周围所有格子的状态,称为宽表征。
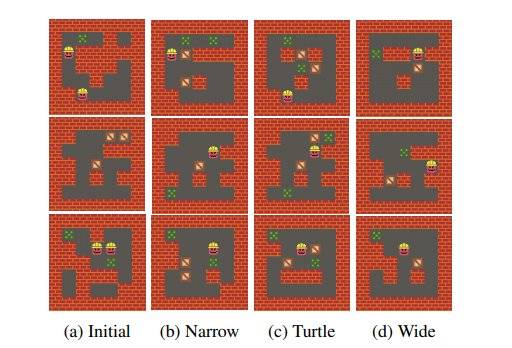
图9:相同初始条件下,不同表征生成的游戏关卡难度不同
上图中,最左列是初始的随机游戏地图;之后的三列,分别是不同表征下,生成的游戏关卡。如果将18部以内就能完成的关卡定义为简单难度,那么不同的表征下,产生的简单关卡的比例分别是86.7%,88.3%,以及67.5%,由此说明不同的表征方式会设计出游戏的难度。
在强化学习的框架下进行游戏设计,该文指出了3条经验,一是需要初始条件不同,二是需设定合适的估值函数,三是每次迭代变化的比例要小,以免算法收敛到相近的解,使得生成的关卡大同小异。
6. 提升走路机器人的可靠性,让它玩游戏通关
与通过机器学习,提升游戏中关卡生成相对应的,是利用生成的关卡,来提升机器学习模型的鲁棒性。下面的例子,来自Uber的AI实验室[4],该研究的目标是训练一个能够双足站立行走的机器人操控算法。
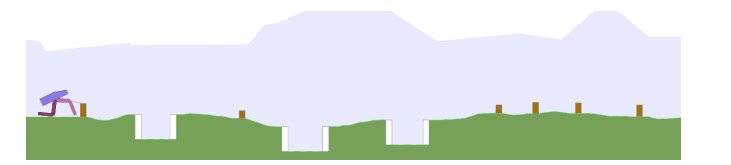
图10:双足行走的机器人面对的不同类型的环境,例如深谷,斜坡,障碍物等。
传统上,通过进化算法,能够训练操控算法适应不同的环境。但是通过生成一组包含大量斜坡的训练环境,再生成一组包含大量深谷的环境,可以定向地训练操控算法在特定环境下,该如何行走,从而使得算法能够逐个攻克不同环境中面对的障碍。

图11:训练能够持续下台阶,跳过行进路线中深谷的算法示意图
在训练过程中,如果在某类障碍中遇到困难,训练算法,会生成类似的环境副本,让智能体先在该环境副本中学习如何越过障碍,之后,再在原环境中行走。
通过引入环境副本,在相同的计算量下,由于智能体采取了更好的,在环境副本中学到的走路姿势,能够获得更高的得分,并有更大的几率,在挑战更高的路段上走完全程。由此提升了算法的泛化能力。

图12:机器手玩魔方的过程示意图
另一个通过游戏来提升AI泛化能力的例子,来自马斯克的openAI实验室,是训练机器手玩魔方[5],通过强化学习和卷积神经网络,借助玩魔方这样一个封闭环境下的任务,研究者提升了对机械手的控制和手眼协调能力,提升了机械手在实际应用场景下的泛化能力。
在强化学习中,通过生成新的游戏关卡,也可以提升训练的游戏AI的可泛化性[6],对比在单一难度,人类设计的关卡,以及由算法设计的关卡上训练的游戏AI,结果显示,基于算法设计的关卡,需要更少的训练时间,能取得更高的训练精度。
7. 过程生成面临的六个挑战与机遇
该综述的最后一部分,讨论游戏规则生成相关研究目前面临着那些挑战。
首先是相比传统的机器学习问题,训练数据集偏小,例如超级马里奥中,只有36个由人手工设计的关卡。
其次是相比生成游戏中的某个组成部分,由算法产生完整的游戏还相对困难。目前较为成熟的生成完整游戏的案例,是基于生成语言模型CPT-2,产生完整的文本式冒险游戏。这是由于一个好的游戏,本身就会相当复杂,并难以使用一个简单的公式来衡量可玩性。
第三点是通过持续的生产新的游戏关卡,让智能体实现终身学习。通过不断改进已学到的策略,过程生成可以让智能体不断适应越来越复杂的环境。
第四点是如何在强化学习范式下,基于过程生成,产生标准的数据集和对应任务金标准。之前的强化学习任务,大多是人类设计的电子游戏。未来,可以让算法设计出新的任务,这些任务会模拟动物及人类在真实环境下所遇到的问题,从而更加准确地能够考察强化学习模型是否学到了人类认知能力的本质。
第五是如何让游戏中的关卡设计,能够不止应用到模拟环境,还能应用到真实场景中。一个脑洞的例子是:通过算法生成类似极品风车的游戏环境,让算法在游戏环境中,先做到尽可能安全的驾驶,之后在训练真实无人驾驶的算法时,借鉴模拟算法所具有的特征。
第六点则是,如何将过程生成的本质,即通过让学习环境多样化,提升智能体的泛化能力,应用到诸如人类学习,神经科学等其他领域。例如未来的智能课堂中,要想做到因材施教,就可以通过自动设计的游戏化交互,提升学生的学习效率。
总结来看,对于应对复杂系统带来的挑战,仿真建模与试错,一个是高屋建瓴的重构出全局特征,另一个是自下而上的生成相应的认知地图。而游戏领域的过程生成,则是打通了上述两条路,通过模仿多主体之间已有的模式,产生更多样化的环境,从而避免试错过程变成了管中窥豹井底观天。
不论对于强化学习,还是有监督学习,引入过程生成,都可以作为一种升级版的数据增强技巧,提升模型的泛化能力。另一方面,在使用机器学习,产生游戏的过程中,所应用的技术,所展现的能力,不止能用于游戏相关的问题,对众多其他机器学习领域的任务都有借鉴意义。
参考资料:
[1] Steve Dahlskog and Julian Togelius. A multi-levellevel generator. In 2014 IEEE Conference on Computational Intelligence and Games, pages 1–8. IEEE,2014.
[2] Volz, V. et al. Evolving mario levels in the latent space of a deepconvolutional generative adversarial network. In Proc. Genetic andEvolutionary Computation Conf. 221–228 (ACM, 2018)
[3] Khalifa, A., Bontrager, P., Earle, S. & Togelius, J. PCGRL: procedural contentgeneration via reinforcement learning. Preprint at https://arxiv.org/abs/2001.09212
[4] Wang, R., Lehman, J., Clune, J. & Stanley, K. O. Paired open-ended trailblazer(poet): endlessly generating increasingly complex and diverse learningenvironments and their solutions. In Proc. Genetic and Evolutionary
[5] Akkaya, I. et al. Solving Rubik’s cube with a robot hand. Preprint https://arxiv.org/abs/1910.07113 (2019).
[6] Justesen, N. et al. Illuminating generalization in deep reinforcement learningthrough procedural level generation. In NeurIPS 2018 Workshop on DeepReinforcement Learning
原文题目:Increasing generality in machine learning through procedural content generation,原文地址:https://www.nature.com/articles/s42256-020-0208-z
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:郭瑞东,编辑:曾祥轩

