




2020-10-13 10:34

扫码打开虎嗅APP


本文来自公众号:编程技术宇宙(ID:xuanyuancoding),作者:轩辕之风O,题图来自:视觉中国
一、我是一个AI神经元
我是一个AI神经元,刚刚来到这个世界上,一切对我来说都特别新奇。
之所以叫这个名字,是因为我的工作有点像人类身体中的神经元。
人体中的神经元可以传递生物信号,给它输入一个信号,它经过处理后再输出一个信号传递给别的神经元,最终传递到大脑完成对一个信号的决策和处理。
聪明的计算机科学家们受到启发,在代码程序里发明了我:神经元函数。
在我们的世界里,我只是普普通通的一员,像我这样的神经元有成百上千,甚至上万个,我们按照层的形式,组成了一个庞大的神经网络。
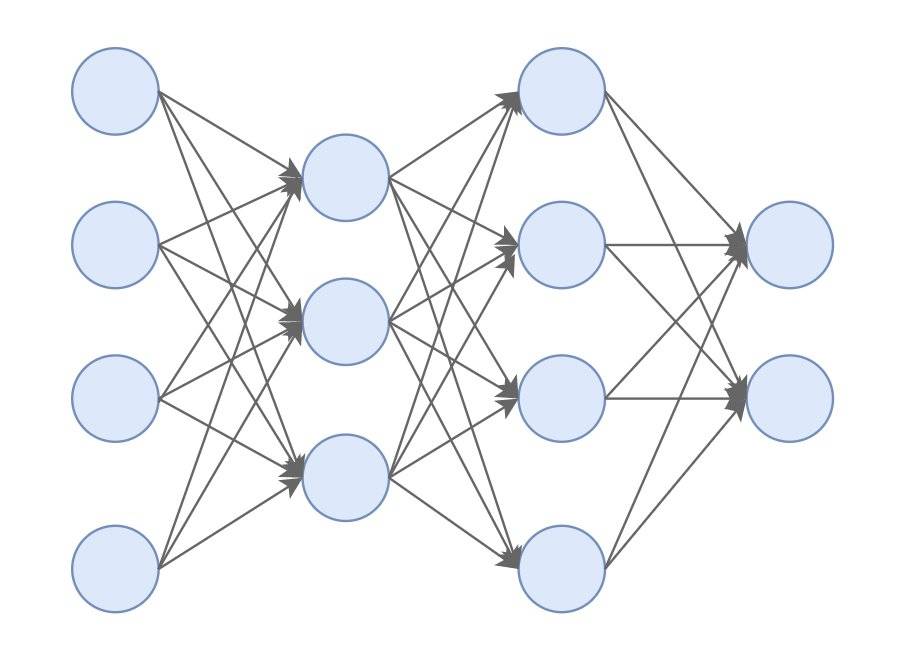
很快我和隔壁工位的大白开始混熟了,他比我来得早,对这里要熟悉的多。
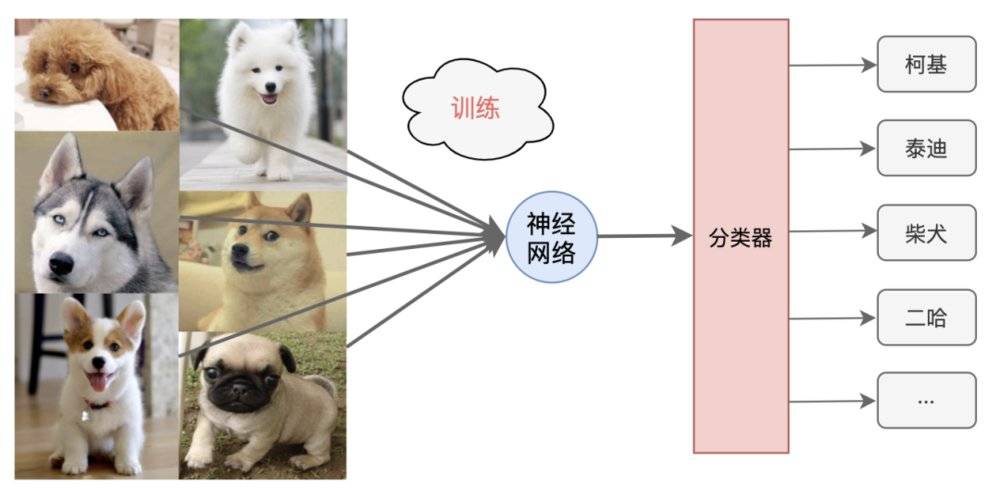
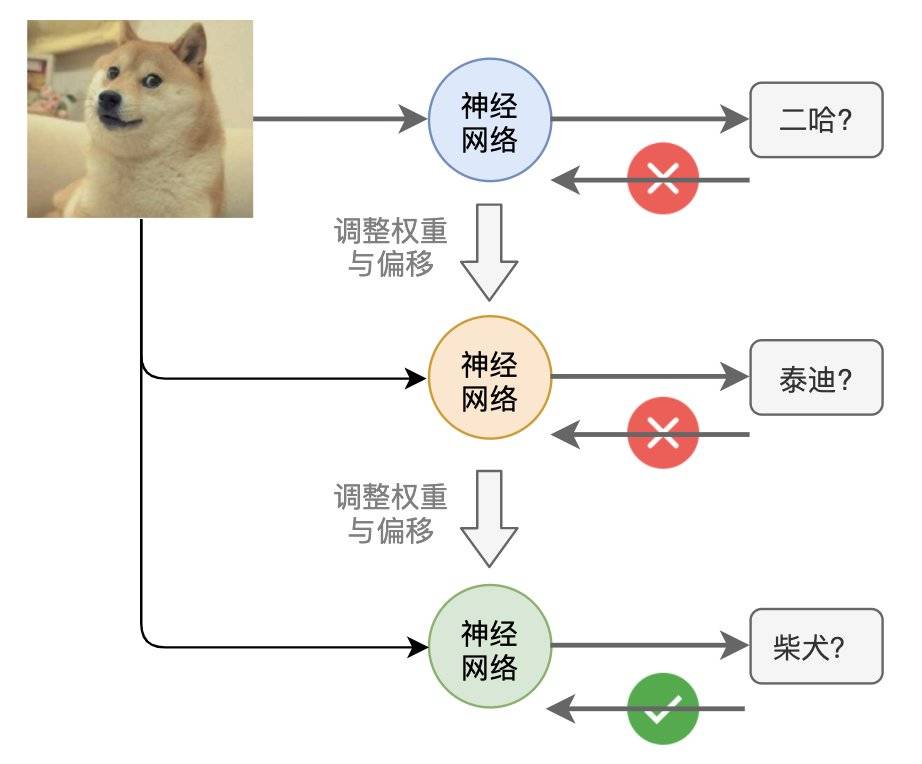
听大白告诉我说,我们这个神经网络是一个图像识别的AI程序,只要给我们输入一张狗的照片,我们就能告诉你这是一只柯基,还是泰迪、柴犬、二哈……
二、神经元结构
在大白的指引下,我很快就学会了怎么工作。
虽然我们叫神经元,名字听起来挺神秘的,但实际上我就是一个普通函数,有参数,有返回值,普通函数有的我都有:
def neuron(a):
w = [...]
b = ...
...
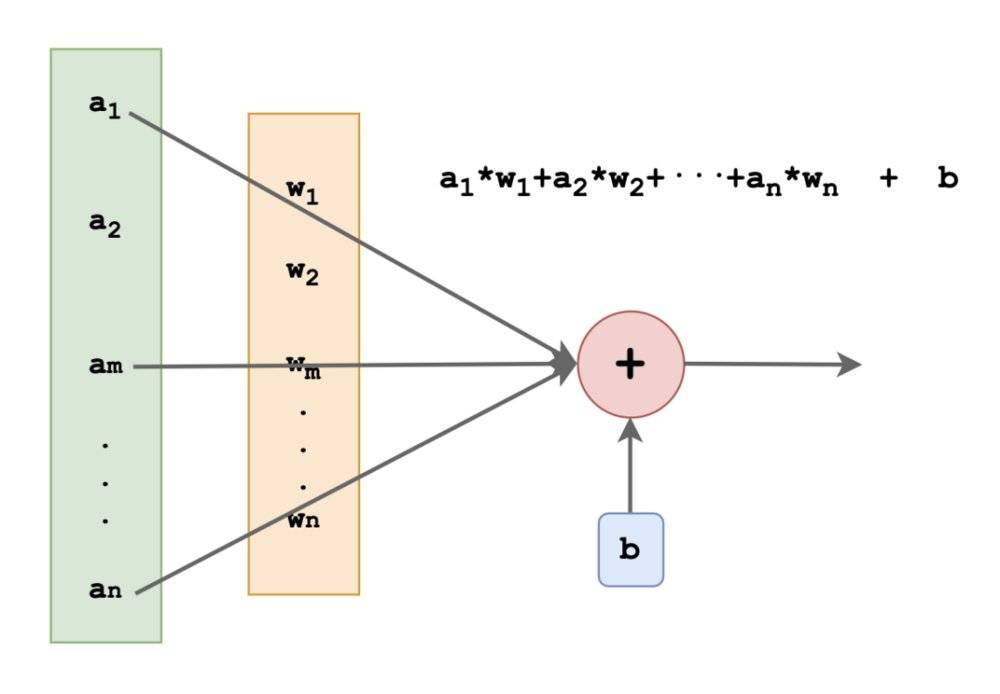
我有一个参数a,这个参数是一个数组,里面的每一个元素我把它分别叫做a1,a2,a3……用这个a来模拟我这个神经元收到的一组信号。
人类的神经元是怎么处理输入的生物信号我不知道,我估计挺复杂的。但在我这里就很简单:我给每一个输入值设定一定的权重,然后做一个简单的加权求和,最后再加上一个偏移值就行啦!
所以我还有一个数组叫做w,就是权重weight的意思,里面的每一个元素我叫做w1,w2,w3……,至于那个偏移值,就叫它bias。
如此一来我的工作你们也该猜到了,就是把传进来的a里面的每个元素和w里的每一个元素做乘法,再加起来,最后加上偏移值,就像这样:
说到这里,我突然想到一个问题,打算去问问大白。
“大白,这些要计算的数据都是从哪里来的呢?”
“是上一层的神经元们送过来的。”
“那他们的数据又是哪来的呢”,我刨根问底地问到。
大白带我来到了门口,指向另外一个片区说到,“看到了吗?那里是数据预处理部门,他们负责把输入的图片中的像素颜色信息提取出来,交给我们神经网络部门来进行分析。”
“交给我们?然后呢?”

“咱们这个神经网络就像一台精密的机器,我们俩只是其中两个零件,不同的权重值某种意义上代表了对图片上不同位置的像素关心程度。一旦开动起来,喂给我们图片数据,我们每一个神经元就开始忙活起来,一层层接力,把最终的结果输出到分类器,最终识别出狗的品种。”
三、神经网络训练
正聊着,突然,传来一阵广播提示音,大家都停止了闲聊,回到了各自工位。

“这是要干啥,这么大阵仗”,我问大白。
“快坐下,马上要开始训练了”,大白说到。
“训练?训练什么?”
“咱们用到的那些权重值和偏移值你以为怎么来的?就是通过不断的训练得出来的。”
还没说到几句话,数据就开始送过来了。按照之前大白教给我的,我将输入数据分别乘以各自的权重,然后相加,最后再加上偏移bias,就得到了最后的结果,整个过程很轻松。
我准备把计算结果交给下一层的神经元。
大白见状赶紧制止了我,“等一下!你不能直接交出去”。
“还要干嘛?”
大白指了一下我背后的另一个家伙说到:“那是激活函数,得先交给他处理一下。”
“激活函数是干嘛的”,我问大白。
“激活,就是根据输入信号量的大小去激活产生对应大小的输出信号。这是在模仿人类的神经元对神经信号的反应程度大小,好比拿一根针去刺皮肤,随着力道的加大,身体的疼痛感会慢慢增强,差不多是一个道理。”
听完大白的解释,我点了点头,好像明白了,又好像不太明白。
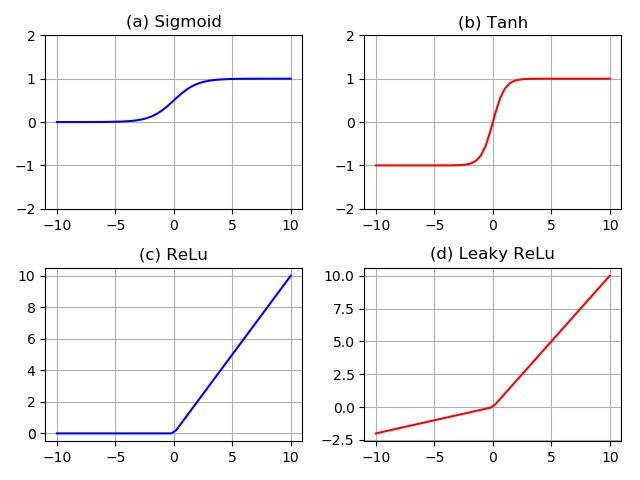
后来我才知道,这激活函数还有好几种,经常会打交道的有这么几个:
sigmoid
tanh
relu
leaky relu
激活函数处理完后,总算可以交给下一层的神经元了,我准备稍事休息一下。
刚坐下,就听到大厅的广播:

随后,又来了一组新的数据,看来我是没时间休息了,赶紧再次忙活了起来。
这一忙不要紧,一直搞了好几个小时,来来回回重复工作了几万次,我都快累瘫了。
四、损失函数 & 优化方法
趁着休息的空当,我又和大白聊了起来。
“大白,刚刚咱们这么来来回回折腾了几万次,这是在干啥啊?”
大白也累的上气不接下气,缓了缓才说到:“这叫做网络训练,通过让我们分析大量不同品种狗的图片,让我们训练出合适的权重和偏移值,这样,我们就变得会认识狗品种了,以后正式工作的时候给我们新的狗的图片,咱们也能用学到的知识去分辨啦!”
“那到底是怎么训练的,你给我说说呗”,我继续问到。
“你刚才也看到了,广播里不断通知更新权重和偏移值。这训练就是通过不断的尝试修改每一层神经元的权重值和偏移值,来不断优化,找到最合适的数值,让我们对狗的种类识别准确率最好!”,大白说到。
“不断尝试修改?这么多神经元,难不成看运气瞎碰?”
大白给了我一个白眼,“怎么可能瞎试,那得试到猴年马月去了。咱们这叫深度学习神经网络,是能够自学习的!”
他这么一说我更疑惑了,“怎么个学习法呢?”
“其实很简单,咱们先选一组权重偏移值,做一轮图片识别,然后看识别结果和实际结果之间的差距有多少,把差距反馈给咱们后,再不断调整权重和偏移,让这个差距不断缩小,直到差距接近于0,这样咱们的识别准确率就越接近100%。”
“额,听上去好像很简单,不过我还有好多问题啊。怎么去衡量这个差距呢?具体怎么调整权重偏移呢?调整幅度该多大好呢?”,我小小的脑袋一下冒出了许多的问号。
大白脸上露出了不可思议的表情,“小伙子,不错嘛!你一下问出了神经网络的三个核心概念。”
“是哪三个?快给我说说”
大白喝了口水,顿了顿接着说到,“首先,怎么去衡量这个差距?这个活,咱们部门有个人专门干这活,他就是损失函数,他就是专门来量化咱们的输出结果和实际结果之间的差距。量化的办法有很多种,你空了可以去找他聊聊。”

“那第二个呢?”
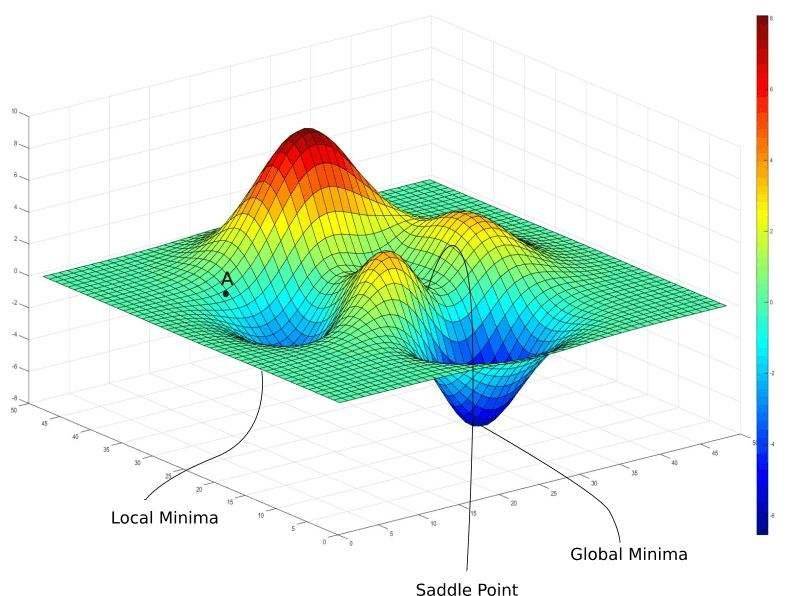
“第二个,具体怎么调整,这也涉及到咱们神经网络中一个核心概念,他就是优化方法,咱们部门用的最多的是一个叫梯度下降的方法。那玩意儿有点复杂,一时半会儿给你说不清楚,大概差不多就是用求导数的方式寻找如何让损失函数的损失值变小”,大白继续耐心的解释着。
“好吧,那第三个核心概念是什么?”
“你刚不是问调整幅度吗?这个调整幅度太小了不行,这样咱们训练的太慢了,那得多训练很多回。太大了也不行,要是一不小心错过了那个最优值,损失函数的结果就会来回摇摆,不能收敛,所以有一个叫学习速率的数值,通常需要程序员们凭借经验去设定。”
我还沉浸在大白的讲解中,广播声再次响起:

看来程序员修改了学习速率,我只好打起精神,继续去忙了,真不知道何时才能训练达标啊。
本文来自公众号:编程技术宇宙(ID:xuanyuancoding),作者:轩辕之风O
