2020-11-23 22:30


扫码打开虎嗅APP

AI很聪明,但是它也依然很懒,所以距离AGI还有很长一段路要走。本文来自微信公众号:一席(ID:yixiclub),主讲人:吴翼(清华大学交叉信息研究院助理教授),题图由主讲人提供
大家好,我叫吴翼,我2014年从清华大学交叉信息研究院毕业,2019年在加州大学伯克利分校获得计算机科学专业人工智能方向博士学位,今年8月份,我又回到了清华,加入了交叉信息研究院。
我回国前在旧金山一家叫OpenAI的小公司工作了一年半,有人就要问了,硅谷有谷歌、Facebook、微软,为什么这些大公司我一个都没去,就去了这么一家小公司?
介绍一下我们公司。OpenAI是一个非盈利的研究性创业公司,它的主业就是研究AI算法,一开始是由伊隆·马斯克出资创立的。当然了我自己并没有见过伊隆,我入职的时候他就已经离开董事会了。

我们公司的使命是创造通用人工智能,英文叫Artificial General Intelligence,缩写是AGI。大家就要问了,通用人工智能是什么?它的定义有很多,通俗来说,AGI就是一台具有跟人一样智能的机器。
好像这个通俗的话还是有点抽象,我来举一些例子,大家看看这些机器到底算不算有智能。
第一个是Siri,它算有智能吗?

大家没有什么疑问,这肯定是算智能。我们来看第二个,百度地图,算智能吗?

好像有人犹豫,这个也是算的。再看下一个,这里有一个小学奥数题,然后有个小机器人小蓝,它告诉你这个算式的答案是79365。这算不算智能?

大家好像都在犹豫啊。有一些小学数学掌握得比较好的同学会说,你这个题很简单,就是每个汉字对应0到9的数字,那我们把每个汉字跟每个0到9的数字都去试一试,判断一下哪个对,然后就是答案了。

没错,就是把所有可能性都去试一试,这个“试一试”的学名,就叫做搜索算法,它也就是人工智能刚开始研究时的主要算法。搜索算法非常简单,但是这个简单的算法也确实给人工智能领域带来了很大的突破。
比如说1997年,IBM就造了一台专门用来做搜索的机器,叫DeepBlue深蓝,去挑战了当时的国际象棋第一人卡斯帕罗夫,并且击败了他,利用搜索算法解决了国际象棋的问题。

当然了,国际象棋有很明确的规则,你知道每一步应该怎么走。但是很多生活中的问题,并不是可以用这样抽象的规则来表达的。比如说我给你一个图片,这个图片里到底是小猫还是小狗呢?这是一个很难用很抽象的数学语言描述出来的问题,我们叫做图像识别问题。

为了解决这样一类很复杂的问题,人们提出了一个概念,叫机器学习。在机器学习的框架里面,你不再需要去描述非常抽象的规则,只需要给出足够多的数据和标注。
比如这里,你只要给它1万张小猫的图片和1万张小狗的图片,那这个AI就可以利用机器学习算法,自己分析和学习后,去判断一个图片到底是小猫还是小狗。

机器学习算法这些年取得了很多突破,但是它要依赖非常非常多的数据,并且你得告诉这个AI什么数据是好的,什么是坏的。但是你知道,现实生活中有很多的问题是没有绝对的好坏的。
比如说我现在很渴,我希望一个机器人帮我送杯水,这个机器人是从左边上台还是右边上台,我不在乎,只要它把水给我,这就是好的。
再比如这个打砖块的游戏,我其实不在乎它怎么玩,它只要能得高分就行了。在这种情况下,它每一步应该怎么走,哪一步是好的,哪一步是不好的,很难说。我只知道它游戏打完有个分,分数高就是好的,分数低就是不好的,这个就叫做智能决策问题。

这里就又有了一个新的概念——强化学习,强化学习是用来解决智能决策问题的算法框架,强化学习算法的核心就是让这个AI不停地跟环境交互,不停地试错,不停地改进自己,慢慢得到越来越多的分数。
2014年,英国的创业公司DeepMind,第一次将深度学习技术和强化学习的算法结合,在一系列这样的80年代小游戏上都超过了人的表现。

那之后的故事大家都知道了,DeepMind研发了一个围棋AI——AlphaGO,它把强化学习和自我博弈结合了起来,让这个AI不断地自我博弈,不断变得更强,然后击败了围棋的传奇选手李世石,后来又击败了柯洁,把围棋项目给解决了。
当然我们知道,围棋确实已经很难了,但围棋和现实生活依然还是挺不一样的。比如说围棋棋盘对于双方选手都是完全可见的,它是一个信息完全的博弈。再比如说在围棋中落子,两个选手一人落一子,并且只能放在棋盘上已有的位置,但是我们知道现实生活是一个物理的世界,我可以做的动作是非常复杂的。
那么AI玩完了围棋,它下一个游戏应该玩什么呢?
打DOTA
我们的答案叫打Dota——这是OpenAI在2017年的时候给AI设定的挑战。
Dota是个挺复杂的游戏,它有五个英雄,每个英雄有不同的技能,玩家还要买物品,和使用各种各样的道具,需要在10分钟到20分钟非常长的一局游戏里面,用非常复杂的策略去击败对方,这是很困难的。
我们公司从2017年开始做这个项目,经过了大概两年多艰苦卓绝的努力,在2019年3月份的时候,发布了最终版OpenAI Five。它和当时的世界冠军团队OG,进行了一场三局两胜的表演赛。
▲ 注意音量,解说比较激动
这是当时跟OG对决的精彩画面,OpenAI Five 十四分钟上高地,最后这个情况基本上就是OpenAI Five的英雄压制在了OG的老家门口,不停的屠杀他们的英雄。
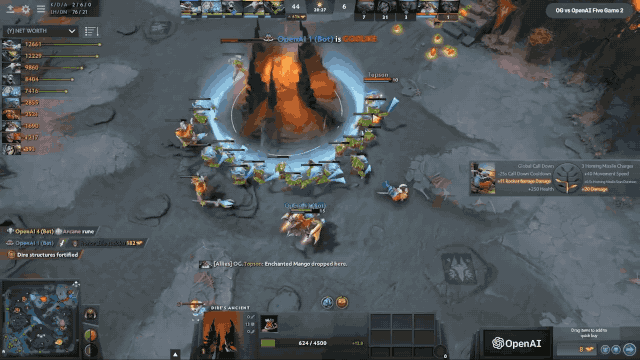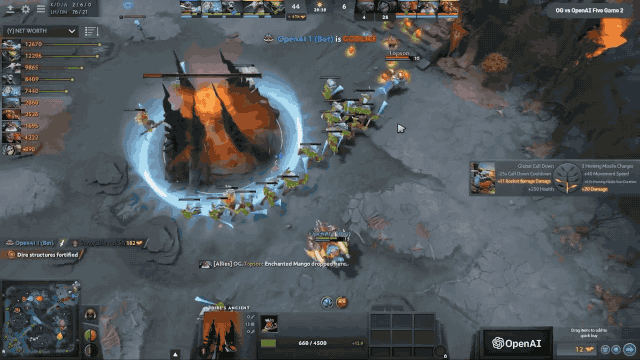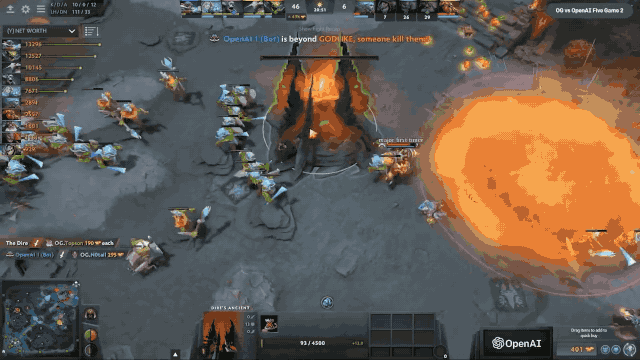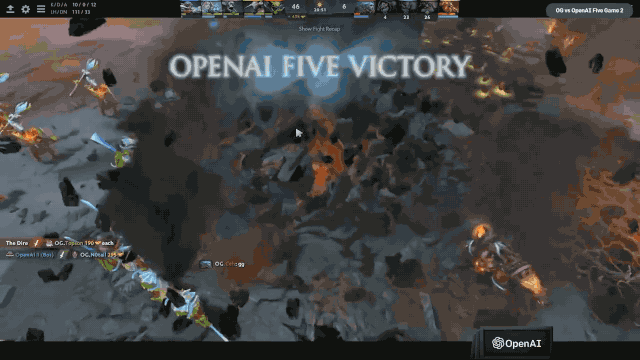
最后这场友谊赛是OpenAI Five以2:0击败了OG,都没有给OG第三局找回颜面的机会。这是赛后的一个合影,前面的5个选手就是OG的5个成员,后面的是我们公司团队的成员,挺有意思的。

▲ OG成员和OpenAI Five开发成员合影
更有意思的事情是,3月份OG被OpenAI Five击败之后,在当年的TI9总决赛上,OG卫冕成功,而且是以碾压性的表现卫冕成功,成为了历史上第一个双冠王。后来OG的一个成员N0tail在推特上说,他们确实从OpenAI Five的策略上学到了很多新的技术和新的想法。
看起来AI的确很擅长打游戏,它好像什么游戏都能赢人,那么是不是在所有的游戏上,AI都能比人强呢?
我的观点是,基本上是这样。在Dota之后也有一些别的,比如说AlphaZero,也就是击败柯洁的AlphaGO的后续版本,它基本是以一个算法解决了所有的棋类问题。

然后卡耐基梅隆大学的团队在德州扑克项目上也击败了职业的顶级玩家,后来DeepMind公司另一个打星际争霸的AI——AlphaStar,也达到了顶尖级职业选手的水平。
所以结论基本上是这样的,只要有足够的计算能力,并且游戏的规则足够清晰,AI都能超过人类。
这里就有个问题,怎么样的计算能力算“足够”呢?以OpenAI Five为例,团队每天使用256块GPU和13万块CPU训练它,AI每一天玩的游戏量相当于一个人180年不吃不喝不睡天天打游戏,钱也花了很多。再比如在AlphaGO Zero击败柯洁之后,Facebook复现了这个算法,他们也开发了一套自己的围棋AI,叫OpenGO。他们是使用亚马逊的云平台进行计算的,大概训练了一两个月,每个礼拜训练OpenGO的花销超过100万美元。
所以AI真的很烧钱,有时候可能也真的只有大公司才有这样的财力去这么烧钱。很遗憾,我也只有在OpenAI这一年半的时间里面,才体会到了有钱人的快乐。但是也正因此,AI也让一些公司赚得盆满钵满,比如说云服务的公司亚马逊,或者是造GPU的公司英伟达。

▲ 英伟达公司五年股价走势图
这里有人就要问了,你说的这些东西都是打游戏,那么为什么要花这么大力气教AI打游戏呢?研究打游戏对现实世界有什么意义?
接下来我会讲两个具体的例子,来回答这个问题。
单手拧魔方
先看第一个例子,这个例子是之前在我隔壁的机器人团队做的项目。在这个项目里面,他们搞了一个非常精细的机械手,然后希望仅仅通过在模拟环境里面训练,就能让机械手学会单手拧魔方。
这是一个很难的任务,大家想一想,一只手拧魔方,这对人来说也是很难完成的,在当时没有任何一个现有的机器人控制技术可以完成这个任务,而且他们还只是在虚拟世界里、在游戏里面对AI进行训练,却能让这个AI在现实生活中也可以工作。他们是怎么做到的呢?
我们都知道,每一个游戏世界和现实生活都是不一样的,不可能完美的模拟现实生活,所以这个机器人团队他们就做了这么一件事情,他们干脆创造了成千上万个不同的模拟环境,每个模拟环境都有不一样的物理参数。

比如说有的环境里面可能重力稍微重一点,有的环境可能摩擦力小一点,有的环境可能魔方的体积大一些。他们把这个技术叫Domain Randomization,希望训练AI在所有不同物理参数的环境里面都能工作。
每一次训练的时候,我们都随机选一个环境,让这个AI去完成魔方的任务,AI它不知道自己在什么环境里,但它为了要完成任务,就必须根据这个环境的动态反馈,来猜这个环境到底是什么物理参数,然后不断地调整自己的策略去适应这个环境。

所以我们用这样的技术强迫AI学会了自我调整,现实世界对AI来说,也不过就是另一个有着不同物理参数的虚拟环境,它也可以通过现实世界的实时反馈来调整它的策略,来不断地完成任务。
在训练完成之后,我们也做了很多不同的测试,给机器人做了很多干扰。比如说尝试给它戴了一个橡胶手套,

把它的两只手指头给捆起来——

给它盖一个黑布——

或者用长颈鹿去戳它——

用马克笔去戳它——

或者非常丧心病狂地用各种各样的东西去干扰它。

但这个AI也非常顽强,不管怎么样的艰难险阻,它都能完成任务。

所以有的时候想一想,AI也是蛮可怜的,不管什么AI都注定要受到人类的不停摧残,挺不容易的。
在机械手的例子里面,我们想说明的是,只要你有足够丰富的虚拟环境,有足够多的计算,即使只在虚拟环境游戏里面训练AI,那这个AI也是有可能在现实生活中工作的。
小蓝和小红
下一个例子我想说明的是,即使你只考虑游戏的虚拟环境,AI也可以发现一些非常有趣的,跟人类社会活动非常相似的行为。这个工作是我自己参与的,叫捉迷藏。
这个项目里我们首先创造了两个非常可爱的小人,一个小蓝和一个小红。


然后我们又搞了一个虚拟的物理世界,让小蓝和小红在虚拟世界里面玩捉迷藏的游戏。小蓝人是Hider,它需要躲;小红人是Seeker,它负责捉。
游戏开始的时候,我们会让小红人先捂上眼睛不许动,让小蓝人先做好准备,然后比赛开始。每一次小红人只要看到任何一个小蓝人,那蓝队就扣一分,红队就得一分。如果规定时间内小红人没有看到小蓝人,那红队就扣一分,蓝队就加一分。
我们使用强化学习算法,让小蓝和小红在虚拟世界里面不停的打游戏,为了得高分相互PK。跟之前的项目一样,我们又创造了成千上万个这样的平行宇宙,让小蓝和小红疯狂地玩捉迷藏。

下面我们来看一看,这些小AI到底发生了一些什么样有趣的行为和故事。游戏一开始的时候,小红很快就学会了追着小蓝跑。
所以当时的小蓝也非常惨,只能不停地躲,非常艰难。但是小蓝日夜玩了上万轮捉迷藏的游戏之后……

它慢慢地发现了一个策略,那就是可以用箱子把门堵住。

在小红捂住脸的时候,它会把门迅速地堵住。然后它们还学会了合作,如果有两个门,大家就齐心协力把两个门统统堵住。

当然了,用工具这件事情小红也很快就学会了,在被小蓝堵在门外堵了很久很久之后,小红发现了可以用这样的策略——爬梯子,

很聪明吧?然后又过了一段时间,小蓝逐渐地发现,我可以把梯子藏起来。

这里我要强调一下,所有这样的行为,所有这样的套路和反套路都是AI自己学会的,我们没有进行任何的人工干预。
然后我们又把这个AI放到了一个更开放的环境里面,在这样一个开放的环境里面,小蓝很快学会了合作,它们会用很多这样的长木板把自己给围起来,同时把所有的梯子都放在边缘把它锁住,不让小红去动梯子。

我们一直以为这样可能就是游戏的终极策略了,但是很偶然地我们发现,经过很长时间的训练,小红发现了一个非常神奇的策略。

虽然梯子被锁住了,但是它站到了这个箱子上,然后骑着这个箱子就一路找到了小蓝。后面我会解释这个现象。
这个小蓝最后也发现了反制的策略,不管箱子、梯子还是木板,全部都给锁住,然后这样就不会被看到了,

这也是我们在这个项目里面观察到的最后一个策略。
这所有背后的原理就是强化学习,我们让小蓝和小红每天玩上百万次捉迷藏,让它们在上百万次捉迷藏中不断地改进自己,改进策略,变得更强。

虽然我们知道这个环境跟现实生活还是挺不一样的,但是我们还是希望有一天,我们也有可能在这个虚拟环境里面创造出AGI。

大家觉得这个事情怎么样,还不错是吧?这个项目的视频在YouTube上点击率很高,有兴趣的朋友也可以去我们公司的官网看看原版的视频。
这里我着重说一下这个Box surfing策略,这是我非常喜欢的一个策略,就是小红人站到了箱子上,然后去找到小蓝人。
这是我非常喜欢的,因为它是在我们这个项目一开始的时候完全没有想到的。那我们是怎么发现这玩意儿的呢?其实这是一个偶然事件,有次这个实验一直没有关,结果我的同事有一天早晨去公司就发现,这个小红人站到箱子上了。

这个行为其实跟我们物理引擎的设定是有关系的。在这个虚拟世界中,物理引擎是简化的,我们预设了一个特定的动作叫“拿”,只要小人执行这个动作,系统就会默认这个箱子会和小人一起行动,就好像你拿了一个东西一样。
所以这个小红人做了件什么事情呢?它先站到箱子上,再去使用“拿”这个行为,于是系统设定就判断这个箱子会跟人一起行动,因此就变成了这个箱子驮着小红人到处走。我们之前从没有想过它可以这么使用引擎的设定,所以这个AI真的是非常的聪明。
这是我们团队的合影,公司给我们每个人都做了一个小红和小蓝的玩偶。

▲ 左二是发现Box surfing的那个同事
既然AI很像人,那么AI总能跟人表现一样吗?我觉得大多数时候是的。捉迷藏这个项目也是想说明,只要你有一个跟现实生活差不多的开放的物理环境,再加上强化学习,那么小AI就能够自动地学出一些拟人的复杂策略。
但是也有例外,接下来给大家看一些,我们在这个项目开发过程中发现的一些非常有意思的意想不到的表现。比如这个是我们项目刚开始的时候发现的一个策略,叫Endless Running,超级跑跑。

在小红捂住眼睛的时候,小蓝就拽着两块板子当盾牌,疯狂地向远处跑走了。这其实是有道理的,因为你跑到很远的地方后,别人肯定就看不到你。但你知道,我们作为开发者就感到很崩溃,我们让你好好玩游戏,你怎么就跑了?
那怎么办?没关系,这个游戏是我们写的,我们可以定规则,所以我们后来就在这个游戏的场地周围搞了一个禁区,任何人进这个禁区就扣分。所以你想跑是吧,我就不让你跑,主宰人命运的感觉也是不错的。
但是我们后来发现,当上帝也不是很容易。这个小人后来学会了一些奇技淫巧,比如它大概是发现了我们这个物理世界里的一个小bug,然后就做了这样一件事情——

▲ 看看小蓝学会了啥
我们看到了当然就第二次的崩溃了。这可怎么办呢?就只能想办法去修物理世界的参数,我们改了很长时间的参数,来保证这样反人类的事情不要发生。
但是同样的事情也发生在了小红身上,你们看看小红学到了什么。

▲ 看看小红学到了啥
我也解释一下,这是因为我们的物理环境里面,那个墙是一个钢体,它的弹性非常大,所以小红它就拽着一个梯子,然后使劲往墙上砸,那梯子就飞起来了。然后小红它很聪明,它在梯子飞起来的前一刻跳了上去,就随着梯子一起飞起来了。
它们倒是很高兴,但是我们看到以后就第三次的崩溃了。我们想了半天,最后把这个环境的重力系数设成了50——一个巨大的重力系数,让所有东西都飞不起来,终于解决了这样的问题。
所以AI研究的日常生活其实就是这样,一群环境修理工人花着公司几百万美金,想办法把一帮人工智障变成人工智能。
还有一件非常有意思的事情,在我们这个视频发到网上之后,一个推特的网友问我们说,小蓝人能学着用板子把自己围起来,它为什么不能把小红人围起来呢?小红人捂着眼睛时候把它围起来不就完了吗?这是一个很好的问题,在原版的捉迷藏游戏里面,这个行为确实没有出现,但是我们有个改版。
这是我自己做的实验,在改版里面我加了一些金币,大家可以看到这些亮闪闪的东西就是金币。

小蓝人这次不光要保护自己,还得保护金币,要是金币被小红人拿走了,小蓝人也会被扣分。所以在这样的情况下,它如果还只是把自己围起来,就不足以保护所有金币了,于是它就学会了这样的行为。
其实我觉得最有意思的一件事情是,它们居然学会了用两块板子,而不是一块去围住。我们的猜测是,它们可能意识到了我们这帮上帝经常给它们写bug,所以它们就用两块板子来保证不要出现意外,保证小红会被锁住。
所以AI真的很聪明,它可以经常发现一些人类想不到的行为和策略,甚至发现一些bug,然后利用这些bug做一些天马行空的行为。但是我也要说,AI也很懒,它总是倾向于找一些最简单的策略,比如在之前的例子里面,小蓝把自己围住就远比把小红围住简单,所以它只去想怎么围住自己。
很多时候AI科学家会绞尽脑汁让这些小智障们变得聪明一些,所以如果你看到了一个聪明的小AI,那背后都是AI科学家掉的头发,和云计算服务商赚得很鼓的腰包。
AI safety
既然AI很聪明,那我们就可以用AI去解决一些非常困难的问题。比如说这是OpenAI今年年初的时候发布的一个音乐创作AI,它叫MuseNet,可以创造出各种各样不同风格的音乐,我挑了一段儿肖邦风格的钢琴曲,大家可以听听。
这个音乐是完全由AI自己创造的,没有任何人工的干预,听着还不错是吧。
我有一个伯克利的朋友,他用AI来帮助做天文观测,这个图片是一个哈勃望远镜拍到的,

▲ 最下面一行是AI处理过的清晰的星系照片
哈勃望远镜拍到的图片经常有一些宇宙的背景噪声,他就用深度学习技术,把这些宇宙背景噪声给去掉,就可以生成更加清晰的观测图。
再比如说今年年初的时候,麻省理工的团队用AI技术发现了一种新的抗生素,这也是当时非常大的一个新闻。这些都是很有意思的一些应用。
这里就有个问题了,就是AI这么聪明,我们可以信任AI吗?凡事都有两面,我们怎么保证AI永远把聪明才智用在正道上?也有人说了,AI不就是可以拿高分吗,都拿高分了还有什么问题?其中一个很大的问题就是Value Alignment问题。
具体来说,人的价值观一般是很复杂的,但是我们在训练AI的时候,一般会给AI一个特别简单的目标,比如说得高分,但是这个分数很难完美地反映出人的喜好,分数高并不一定代表着人类就满意。
这里我就举一个我的导师Stuart Russell教授经常举的例子,假设你家里有一个非常听话的机器人,有一天你去上班了然后跟机器人说:“我上班去了,你帮我照顾孩子,中午给他做饭,不能饿着孩子。”
然后到了中午,小孩跟机器人说我饿了,机器人收到了这个信号,就去做饭了。但机器人打开冰箱一看,不好,周末没买菜,冰箱里什么都没有,那怎么办?
这时候机器人头一转发现了你家的猫——一个充满蛋白质和维生素的可食用物体。

确实有点残忍,但是你也不能怪这个AI,因为你跟它说的是不要让小孩饿着,你也没说不能打猫的主意。
所以人的价值观是特别复杂的,你几乎是不可能把你关心的方方面面都明明白白写下来,然后全部告诉AI的。我自己都不能很自信地说我完全了解我自己,怎么告诉AI呢?这是很难的。
虽然AI在大部分时候确实很通人性,但是它还是会经常出现一些问题,这个领域叫AI safety,人工智能的安全性,也是一个很新的研究领域。
有人可能在这里要提出异议了:你不是说了吗,AI都是人工智障,人工智障距离AGI还远呢,有什么好担心的。
首先,因为AI跟生活已经结合得非常紧密了,我们到处都可以看到AI,所以即使只是用当今的AI技术,也可以找到很多AI犯错的例子。另外一点也是我的导师经常说的,假如你知道在100年之后,火星会撞地球,地球要完蛋了,你难道会说再过30年再考虑这个问题吗?你不会这么想的。因为如果它是个大的问题,那就应该从现在开始就研究它。
这里我也想介绍一下我的导师,Stuart Russell教授。

▲ 右边是Stuart Russell教授
Stuart Russell教授他在2016年开始倡导AI safety的研究,当时他也在伯克利成立了一个新的研究院,叫Center for Human-Compatible AI。
Human-Compatible AI的基本论点是AI算法不应该只是优化分数,它也应该知道自己的分数跟人的价值观可能不一样,然后应该以人的反应作为最终的目标。俗话说就是,AI得知道自己是个人工智障,万事先看看人,多问问,不要冲动,不要莽撞。
我举个例子,假设你家里有一个小机器人,然后你跟机器人说:“去门那儿!” 传统的AI会说,那我找最短的路径,它就一溜小跑去门那儿了,但是可能就把你家花瓶给撞了。
那Human-Compatible AI会怎么做呢?它会先等等,先观察一下人是怎么做的。

它就发现人总是绕着花瓶走,这可能说明花瓶有诈,如果没问题的话,为什么人要绕着花瓶走呢?于是这个怀着敬畏之心的小智障,就战战兢兢地绕着花瓶走到了门那里,非常完美。
当然我这里要说的是,这是AI safety一个非常简单的例子。人工智能的安全性问题是一个非常新的领域,任重而道远。
从另一个角度来说,AI容易发现bug,其实在某些情况下也不错。假设你有个系统,如果你派AI去能发现bug,然后人类再把它修好,那这个系统在真正运行的时候,它的bug不就少了吗?举个例子,我有几个朋友这个夏天在用多智能体强化学习来模拟一个城市里面人口的流动,然后通过这个来分析新冠病毒的传播,以及我们防疫系统里面可能的问题,来帮助我们做防疫。
当然了,未来或许还有更多这样的社会科学问题可以用强化学习的方法去模拟计算和分析理解。但是我还是要再提一句,AI很聪明,但是它也依然很懒,所以距离AGI还有很长一段路要走。
一些愿景
最后我想聊一聊我们这些AI的从业者,也是我们交叉信息研究院的一些看法和愿景。
我先介绍一下我们院吧。我们院是唯一的华人图灵奖得主姚期智先生创办的一个学院,我们院的使命是培养中国的计算机科学家。
AI的普及和利用是一个历史的潮流和趋势,我们不管AI到底是一个新的产业革命,还是只是人类历史长河中一个特别小的波涛,不管好还是坏,AI总是和我们的生活越来越紧密,越来越不可分割了。AI会改变越来越多的行业,也会对我们的生活和生产方式产生越来越多的改变。
那明天会怎么样呢?有人说AI会让很多人失业,有人说AI可能会产生新的垄断阶级,会垄断教育、垄断资源、垄断技术,但是与此同时,AI的发展也会产生新的行业,会产生新的工作机会和工作形式。我们作为AI的从业人员也希望用我们的努力去普及AI, 去打破这样的壁垒,让更多的人能了解AI,了解AI背后的原理,了解AI到底想干什么。
作为教育工作者,我们也希望利用AI带来的机会和行业的发展,去让这个世界更公平,让社会更进步。姚期智先生带领我们院的老师们也朝着这个目标做了一些努力,最近我们一起写了一本关于人工智能的中学教科书,希望中学生可以完全没有壁垒的全面的科学的了解AI,了解AI背后的原理。如果一切顺利,在今年年底或者明年年初,这本书就会跟大家见面。
我还记得当时姚先生跟我聊,为什么要做这么一件公益的事情。大致的对话内容是这样的,教育的普及和推广,如果我们这些教育工作者不去做的话,那就一定会有坏人去做,如果是这样,那还不如我们率先去把它做好。

这就是我今天分享的内容了,很感谢大家捧场,也希望有一天AGI能够真的到来。谢谢大家。
本文来自微信公众号:一席(ID:yixiclub),主讲人:吴翼(清华大学交叉信息研究院助理教授)
 14:41
14:41
 28:38
28:38
 02:11:46
02:11:46
 17:32
17:32
 31:04
31:04

 19:42
19:42
 31:29
31:29
 09:14
09:14
 08:14
08:14
 52:36
52:36













