2021-06-16 17:26


扫码打开虎嗅APP

本文来自微信公众号:Nature Portfolio(ID:nature-portfolio),作者:Alexander J. Gates , Deisy Morselli Gysi , Manolis Kellis & Albert-László Barabási,题图来自:《超体》
在人类基因组计划第一份草图发布的20周年[1,2] ,这是一个回顾该项目种种的契机:它如何推动人类疾病遗传根源的相关研究、改变了药物发现,以及帮助我们修订对基因这一概念本身的认识。

Credit: SciePro / Science Photo Library
本文中,我们将这些影响和趋势进行了提炼,结合了一些数据集来量化已发现和发表的不同类型的遗传因子,以及这些年来基因发现和论文发表模式的改变。我们的分析涵盖了38546个RNA转录本,大约100万个单核苷酸多态性位点(SNP),1660种有报道遗传起源的人类疾病,7712种已批准的和实验性的药品,以及在1900年至2017年间共发表的704515篇科学论文(见附件)。
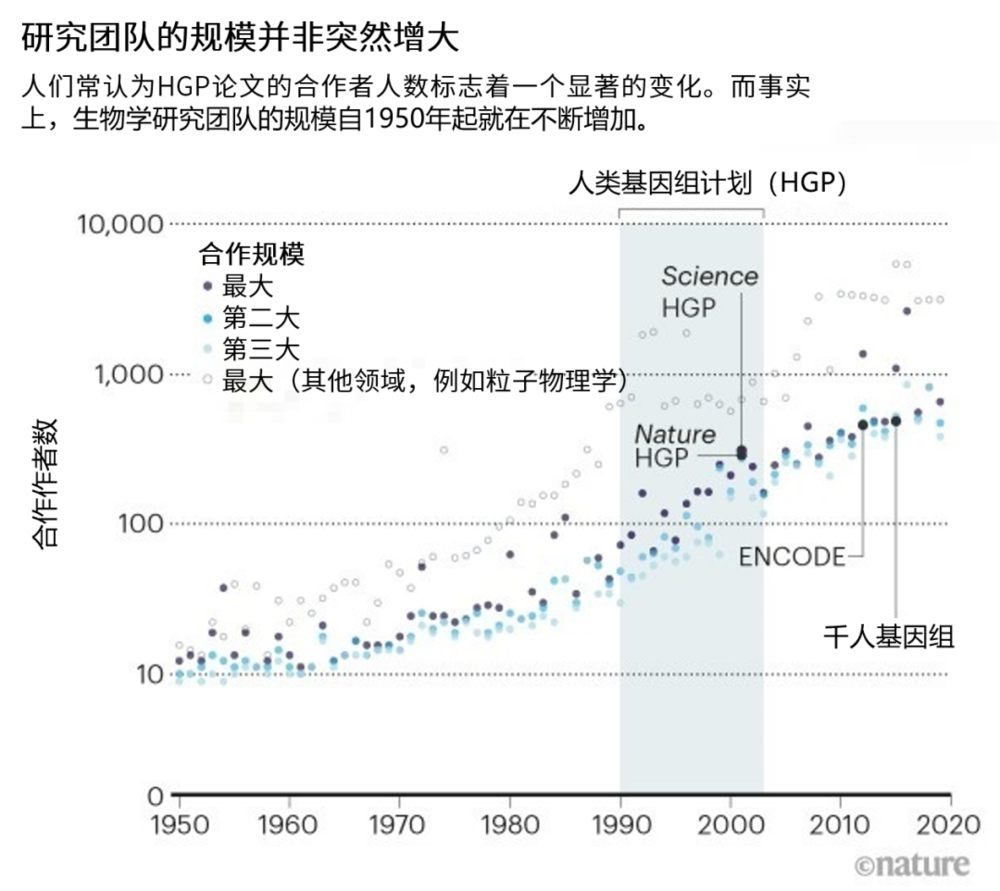
这些结果强调了人类基因组计划(下称HGP)及其全面的蛋白质编码基因目录是如何开启了阐明基因组非编码部分功能的新时代,并为治疗方法的建立铺平了道路。重要的是,随着研究者绘制了细胞构件的相互作用,在传统单基因视角外,这项结果跟进了系统层次上生物学视角的出现(参见“研究团队规模并非突然增大”)。
我们的分析存在局限性。例如,关于基因的起始和结束位置,甚至编码某些基因的确切序列并无定论[3]。一些基因组元件使用多种命名,我们的方法可能未能将其中一些联系起来。此外,作者可能没有将论文和这些基因元件之间的联系添加到数据库中。最后,我们的图表截至2017年,因为一篇文章从发表到被纳入我们用的数据库之间可能存在时间滞后。
视频由Alice Grishchenko进行可视化,Alexander J. Gates, Deisy Morselli Gysi, Csaba Both, Manolis Kellis 和Albert-László Barabási进行了研究工作。
不过我们不认为这些问题会影响在此提到的趋势,即基因组研究随时间发生的变化。当控制同时期生物学论文数的增长时,这种趋势仍然存在(参见附图6)。我们没有控制自基因发现以来的时间这一变量,但估计这不会改变我们的结论。
这些关联,让我们看到了HGP前后研究领域变化的缩影。研究开始集中关注少数“超级巨星”蛋白编码基因,这也许有损于那些原本可以在其他基因上进行的有趣工作。基因组的非蛋白质编码部分,以及理解遗传物质和蛋白质之间的相互作用,开始成为研究重点。而药物发现也仅限于少数蛋白靶点。
生物学家很熟悉其中某些趋势,但对其进行量化和可视化,则是一种新思考。
由于不存在一个没有HGP的世界作为对照,因此,我们不能确定这些趋势是否无论如何都会发生。这些进展中也有其他因素的作用,从增强的计算能力到复杂的测序方法。不管怎么说,HGP还是明显促进了持续的基因革命。
Source: Barabási Lab
一、超级巨星基因
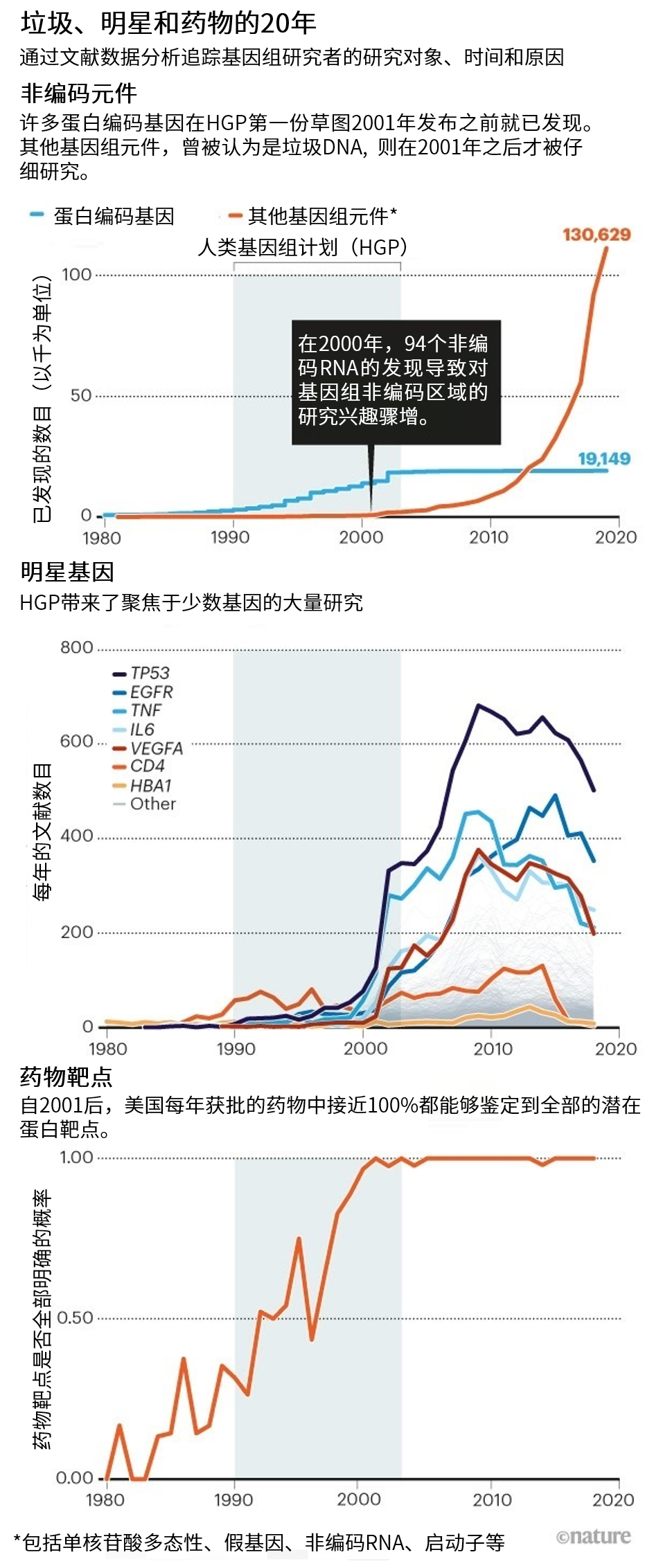
人们普遍认为HGP是深入研究蛋白质编码基因的开始。事实上,2001年的HGP草图,标志着对基因的数十年搜寻告一段落[1,2]。其实首个蛋白质编码基因的证据出现于1902年,当时发现了激素促胰液素(SCT基因)[4],这是DNA结构被发现的50年前,基因组测序普及的75年前。我们的分析表明,从1990年HGP开始,到2003年完成(2001年草图发表后),发现(或注释)的人类基因数量急剧增长。到21世纪00年代中期,蛋白质编码基因的数量忽然趋于平稳,约在2万个左右(参见“垃圾、明星和药物的20年:非编码元件”),远远低于科学界许多人此前所估计的10万个左右[2]。
虽然蛋白质编码基因的发现到达了平台期,但人们对单个基因的兴趣在HGP之后迅速增长。自2001年以来,每年都有1万到2万篇与蛋白质编码基因有关的论文发表(参见附图3)。
然而,这种兴趣主要集中在少数几个基因上。在1990年之前,HBA1是研究最多的,因为它编码成人血红蛋白中的一种蛋白质。从1990年开始,人们的注意力转向了CD4(根据发表的出版物的累积数量判断),因为这种蛋白参与T细胞免疫并作为HIV的细胞受体。然而,与2001年HGP草图发布之后对单个基因的关注激增相比,对这两个基因的关注则显得微不足道。针对一些超级明星基因,包括TP53、TNF和EGFR,每年都有数百篇文章发表,而其他大多数基因却很少受到关注(参见“深度影响”和“垃圾、明星和药物的20年:明星基因”)。我们发现,截至2017年,22%的基因相关论文只关注了1%的基因。

Source: Barabási Lab
当然,对具有重要生物学意义的基因进行深入研究是合理的。TP53就是一个很好的例子——它对细胞的生长和死亡至关重要,倘若被抑制或改变则会导致癌症。在超过50%的肿瘤序列中都发现了这种基因的变异。从1976年到2017年,共有9232篇文献提及了TP53(参见附图4)。
人们可能会认为,对同一基因了解得越多,就越有动力去探索基因组的其余部分。然而,过去20年所发生的却恰恰相反,更多关注被加诸于少数的基因。尽管这一问题在基因组草图发布十周年[5]之际已被提出,但仍未得到根本方向上的改变。
我们先前对从人类社会网络到万维网等其他截然不同的系统所做的研究表明,基于社会因素的“富者越富”动态理论[6,7],可以解释这种巨大的不平衡。随着关注TP53的论文数量增加,进一步的TP53相关工作越能保证获得资金、指导、工具和引用,因为这是一个安全的赌注(参见附图4)。在网络科学中,这种现象被称为偏好依赖。事实上我们发现,关注特定基因的年度新论文数量,与先前有关该基因的文献数量成线性关系(参见附图6)。
生物学目前面临的一个挑战是理清下一步研究什么的动机。研究人员的资金、时间和精力投入,是投到最重要或最紧迫的事情上,还是投到有望赢得更多资金和赞誉的雷同领域?
二、垃圾基因并非垃圾
早在HGP之前,就存在激烈的辩论:绘制基因组中被称为“垃圾DNA”或“暗物质”的大量非编码区域是否有价值?在很大程度上这要感谢HGP:现在人们认识到,人类基因组中的大多数功能序列并不编码蛋白质。相反,诸如长链非编码RNA、启动子、增强子和无数基因调控序列等元件共同作用,使基因组能够发挥功能。发生在这些区域的突变不会改变蛋白质,但会扰乱蛋白表达的调控网络。
获得人类基因组草图之后,非蛋白编码元件的发现骤增。到目前为止,其增长已经超过了蛋白质编码基因发现的五倍之多,而且没有放缓的迹象。同样,在我们数据集覆盖的时间段内(1900年至2017年;参见附图3a),有关这些元件的论文也在增加。例如,关于调节基因表达的非编码RNA的论文就有数千篇。
HGP还提供了一种人类遗传变异(包括单核苷酸多态性)编目的方法。其他一些主要工作也大幅削减了分析数千个个体间共同差异的成本;其中包括国际HapMap项目[8](第三阶段和最后阶段于2010年完成)和千人基因组组项目[9](于2015年完成)。这些数据集,加之统计分析的进展,开拓了对无数特征的全基因组关联研究(GWAS),包括身高[10]、肥胖[11]和对复杂疾病(如精神分裂症)的易感度[12]。
现在每年有超过3万篇文章将单核苷酸多态性和某种特征联系起来。这些关联的很大一部分位于曾被忽略的非编码区域(参见附表3)。
细胞功能依赖于遗传物质和蛋白质之间或强或弱的联系。绘制出关联网络是对孟德尔观点的补充。迄今为止,已经有超过30万个调控网络相互作用被绘制出来,涉及蛋白质与非编码区或与其他蛋白质的结合。
三、药物发现
大约在20世纪80年代之前,药物的发现很大程度上是出于偶然。它们的分子和蛋白质靶点通常是未知的。直到2001年之前的任何一年,清楚知道某种药物所有蛋白质靶点的概率都不超过50%。HGP改变了这一点。目前在美国,每年获得许可的几乎所有药物靶点都是已知的(参见 “垃圾、明星和药物的20年:药物靶点”)。
Source: Barabási Lab
HGP揭示了大约20000个蛋白质可作为潜在药物靶点,我们发现到目前为止其中只有大约10%——2149个——是已获批药物的靶点(参见附表4和附图1)。其余90%的蛋白质组,药理学尚未涉及[13]。我们数据集中,实验药物将这个数字增加到3119(参见附图2)。同样,这些靶点所受到的关注也是不均衡的。目前批准的所有药物中有5%(99种不同分子)以参与细胞生长和增殖的蛋白质ADRA1A为靶点。
正如前文所提到的,这种倾斜有其缘由。有些蛋白质可能对人类健康更重要,或更可能作为药物靶点。有些可能无法成药。但还是有可能,如果研究人员、资金提供者和出版商不那么厌恶风险的话,会有更多的蛋白质值得作为药物靶点进行探索。
也就是说,大多数成功的药物并不直接针对个别疾病基因[14]。相反,它们的靶点在蛋白质一两次相互作用之后,调控的是发生错误部分的后果。例如,对可用于治疗COVID-19的现有药物进行大规模筛选发现,只有1%有希望的候选药物针对病毒蛋白,大多数调控的是不直接参与SARS-CoV-2病毒活性的人类蛋白[15]。这类网络中的药物具有巨大的潜力。
四、窥见生命的网络
总之,我们认为HGP更重要之处在于开创了基因组学的新时代,甚于蛋白质目录本身。正如复杂系统理论所表明的那样,对组件的精确调查是必要的,但尚不足以充分理解任一系统。复杂性来自于组件之间交互的多样性。经过20年以HGP为基础的研究,生物学家目前对定义生命的网络结构和动态有了初步的认知。
附件:https://media.nature.com/original/magazine-assets/d41586-021-00314-6/18835258
参考文献:
1. Venter, J. C. et al. Science 291, 1304–1351 (2001).
2. International Human Genome Sequencing Consortium. Nature 409, 860–921 (2001).
3. Portin, P. & Wilkins, A. Genetics 205, 1353–1364 (2017).
4. Bayliss, W. M. & Starling, E. H. J. Physiol. 28, 325–353 (1902).
5. Edwards, A. M. et al. Nature 470, 163–165 (2011).
6. Bianconi, G. & Barabási, A.-L. Europhys. Lett. 54, 436 (2001).
7. Barabási, A.-L. & Albert, R. Science 286, 509–512 (1999).
8. The International HapMap Consortium. Nature 426, 789–796 (2003).
9. The 1000 Genomes Project Consortium. Nature 526, 68–74 (2015).
10. Lango Allen, H. et al. Nature 467, 832–838 (2010).
11. Speliotes, E. K. et al. Nature Genet. 42, 937–948 (2010).
12. Lencz, T. et al. Mol. Psychiatry 12, 572–580 (2007).
13. Wishart, D. S. et al. Nucleic Acids Res. 46, D1074–D1082 (2018).
14. Yildirim, M. A., Goh, K.-Il, Cusick, M. E., Barabási, A. L. & Vidal, M. Nature Biotechnol. 25, 1119–1126 (2007).
15. Gysi, D. M. et al. Preprint at https://arxiv.org/abs/2004.07229 (2020).
原文以A wealth of discovery built on the Human Genome Project — by the numbers标题发表在2021年2月10日的《自然》的评论版块上
本文来自微信公众号:Nature Portfolio(ID:nature-portfolio),作者:Nature Portfolio
 05:31
05:31








 13:16
13:16
 08:15
08:15
 11:28
11:28
 23:56
23:56
 02:50
02:50
 25:06
25:06
 04:04
04:04
 05:33
05:33
 08:30
08:30


