2021-08-23 22:36


扫码打开虎嗅APP

本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:Lazer, D.等,译者:王涵菁,审校:赵雨亭、梁金,编辑:邓一雪,题图来自:unsplash
在数字时代,我们的社交、运动、购物等日常行为每时每刻都在生成大量数据。如何从这些数据中挖掘出意义,指导我们对自身和世界的认知?近日,Nature 杂志上的一篇观点性评论文章认为,这需要构建新的度量方式,将不可测量的变量变得可测量,该文收录于“计算社会科学”特刊。

论文题目:
Meaningful measures of human society in the twenty-first century
摘要
科学很少会超出科学家所能观察和测量的范围,但有时观察会远超科学理解的范围。21世纪正为人类社会的研究提供了这样一个时刻。今天观察到的人类行为比20世纪末所能想象的要多得多。我们的人际交往、行动和许多日常行为,都有可能被用于科学研究;有时通过有目的的仪器来实现科研目标(例如卫星图像),但更多时候,这些目标实际上是事后才有的想法(例如Twitter数据流)。
在本文中,我们评估了这种大规模仪器的潜力,即通过科学测量及其原理的视角,创造结构化表示和量化人类行为的技术。我们尤其关注的问题是,如何从数据中提取科学性的意义,尽管这些数据往往不是为这些目的而创建的。这些数据提出了概念上、计算上的和伦理上的挑战,需要我们的科学理论复兴,以跟上快速变化的社会现实和捕捉它们的能力。换言之,我们需要新的方法来管理、使用和分析数据。
传感器技术的应用已经在人类活动的许多领域成倍增长,从汽车追踪设备到在线浏览。卫星会定期扫描地球并将其数字化。计算机科学家开发的处理非结构化数据(如文本、图像、音频和视频)技术的发展,使诸如书籍[1]、广播[2]和电视节目[3]等转换成数据成为可能。在21世纪,人们的行为——从流动到信息消费,再到各种各样的人际交往,越来越多地被记录并且有可能被计算处理。过去的通信技术,从邮件、印刷品再到传真,通常只留下很少的耐用、可获得的人工制品;而在过去十年左右的时间里,随着相关的实物被数字化,它们已经成为可以通过计算获得的东西。书籍的数字化就是一个例子,它使我们能够对几百年前的人类表达的大量语料库进行计算分析[4]。
人们常常将这些新数据流的出现和望远镜的发展做类比。正如罗伯特·默顿(Robert Merton,1997年诺贝尔经济学奖得主)的名言:“也许社会学还没有为爱因斯坦做好准备,因为它还没有找到它的开普勒……”[5]默顿这句挑衅性的话是指,社会学还没有建立伟大理论的经验基础。对此,邓肯·瓦茨(Duncan Watts,计算社会科学家)在62年后回应道:“……通过将不可测量的变量变得可测量,移动、网络和互联网通信领域的技术革命有可能彻底改变我们对自己和我们与世界如何互动的理解。默顿是对的:社会科学仍然没有找到它的开普勒。亚历山大·蒲柏(Alexander Pope,18世纪英国诗人)三百年前就曾提出,人类理应研究的对象不在天上,而在我们自己,如今我们终于找到了我们的望远镜[6]。”
我们相信,数字资料有改变社会科学的潜力。然而,将工具化社会的数据流比喻为“望远镜”在一些重要方面是具有误导性的。首先,对社会的研究不同于对星星的研究,因为刻画人类行为的模式在不同时间和地点通常是不同的。第二,由这些数据流中建立起来的测量是值得怀疑的,因为这些数据源建立时并没有考虑到科学目标,因此必须对其进行积极审视。现在我们谈谈第一点;本文的其余部分将讨论第二个问题。
一、社会和测量的不稳定逻辑
经验性社会科学主要侧重于发现人类行为中可被概括的模式,而不是普遍模式。社会科学中旨在从人类行为中发现这种普遍模式的部分(如演化心理学)相对于整个领域来说是微不足道的。管理人类社会规则的不稳定性问题由于收集人们数据的社会技术系统而加剧,这些系统正在积极地(在某些情况下有意地)改变社会科学将要研究的社会世界。通过社会科学家所称的自反性和自我实现的预言,人类通过对所获得的知识(部分是通过仪器)采取行动,积极地改变他们所观察到的世界[78]。
自反性是指将社会现实与我们设计用于解释社会现实的理论和量度联系起来的循环。例如,在选举政治分析中,人们早就发现了“从众”和“劣势”效应,以解释民意调查和预测对投票行为的影响。如果候选人被预测为可能的赢家,更多的人可能会决定投票给他们(从众效应);或者相反,更多的人可能动员起来,增加对被预测会输的候选人的支持(劣势效应)[7]。这些效应反映了测量对态度和行为的影响[8,9],以及我们的测量如何扭曲他们本被设计用来监测的现象。反过来,公共卫生、执法、量刑、教育和招聘等领域的算法决策也会放大这些扭曲。[10,11]
自反性还表现为观察者效应的形式,当人们知道自己被观察时就会改变自己的行为[12,13]。数字技术创造了自反性问题的新版本,放大了社会指标中固有的表现方面。当谷歌在2008年启动流感趋势项目(Flu Trends Project)时,目标是使用搜索查询来估计流感症状在人群中的流行程度。然而,在2013年,这个项目大大高估了流感的峰值水平。其中一个原因是有缺陷的假设,即搜索行为是由外部事件(比如流感症状)驱动的。事实上,谷歌的算法也在推动这些模式:通过尝试通过推荐的搜索词来预测用户的意图,谷歌扭曲了用户原本可以看到的信息[14]。换句话说,对观察到的现象的反应改变了现象本身。
模糊处理策略代表了观察者效应的另一个版本:我们现在可以通过故意添加模糊或误导性信息来干扰数据收集,从而中断测量。模糊处理的例子包括编辑轮廓照片以防止面部识别;在浏览网页时使用虚拟专用网(VPN)来隐藏自己的位置;或者使用群组身份(例如,许多人共用一个用户帐户)来掩盖单个用户行为的细节[15]。这里的自反性循环是因人们意识到行为痕迹被反馈到测量和监视中而产生的,因此该行为的含义是有意被改变的。但在更大的范围上,这类似于受访者对调查人员撒谎。而且,由于了解正在发生的监视以及如何实施模糊处理来解决这一问题所需的技能并不是随机分布在人群中的,因此将数据以此方式改变的个人也不会是随机的。
许多数字测量的不明显性质表明,总体而言,与过去相比,这些新数据源的观察者效应可能不太成问题,例如,进行访谈的人的性别、年龄和种族可能会极大地改变受访者提供的答案[16]。然而,将社会现实与我们用于分析社会现实而设计的量度联系起来的循环已经得到加强——自反性现在已经被嵌入用于监测和预测人类行为的工具中。这就好像哈勃望远镜在观测恒星的同时组织了恒星的位置和行为。例如,社交媒体不仅捕捉人类行为,也有可能改变人类社会的重要模式:例如信息流动的速度、媒体制作的范围以及负责界定舆论的行为者。
组织人类社会的原则是有流动性的,因此一个特定测量的意义也会演变。社会科学必须适应新型数据的部分原因是,新兴的社会技术系统正在降低一些用于衡量人类行为的旧科学工具的重要性。国内生产总值(GDP)和地域流动性等关键概念的现有衡量标准仍受制于20世纪数据的优缺点。如果我们只对旧的衡量标准进行评估,只会复制它们的缺点,把20世纪的金本位误认为是客观真理。例如,考虑一下美国国家选举研究所(American National Election Studies)[17]对有关选举的电台消费的一个标准问题(最初源于1978年):“你会说你在电台听了很多次,几次,或者仅仅是一两次演讲,或者关于‘选举’的讨论?”
这种由有限离散单元组成的“媒体消费”结构是广播时代技术的产物。这个问题与今天人们如何访问数字媒体没有多大关系。试图通过问一些问题来捕捉社交媒体的行为是徒劳的,比如“你今天看到了多少条推特?”或者“你的信息流中出现了哪些推特账户?”在定量社会科学早期发展起来的许多衡量行为的方法是:(1)有必要的,考虑到当时的测量限制;(2)立足于明显不同的社会现实。
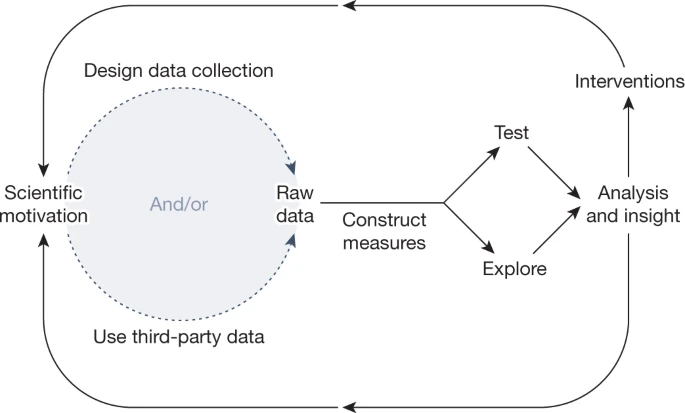
图1. 社会科学中的测量。测量是连接科学动机、数据和洞察、应用的桥梁。
图1总结了测量如何适应一般科学过程。我们将在下面讨论,将这些社会技术系统的数据转化为科学测量的核心挑战。这个讨论将包括两个数据流的启发性例子,它们是许多社会科学研究的基础:来自手机的位置数据和Twitter上的社交媒体帖子。我们现在要讨论的关键问题是,当前需要用大量仪器化的人类行为来衡量什么对象,注意方框1中总结的衡量的关键原则。
方框1 度量的核心原则
度量应该遵循重要问题的定义
度量被观察的现象是以确定相关问题为前提的。重要的问题是由研究问题驱动的,这些问题可能由规范性目标、理论辩论或经验难题所驱动。
度量必须是从数据中积极构建的
为研究目的而设计的仪器常常产生科学数据。但是,为了科学研究以外的目的而收集的数据也经常被学者们改变用途。数据本身并没有意义,无法成为某些理论结构的度量,它们必须通过各种方法进行转换,使它们系统地相互关联,并与科学理论相关联。
科学度量在不断发展的循环中遵循上述原则
科学动机指导研究人员设计数据收集协议,使用第三方数据或开发出这两者的某种融合。在原始格式中,数据提供了经过处理成度量的观察结果,这些观察结果可以用来测试预先设想的假设(以演绎的方式)或从探索性分析中得出新的假设(以归纳的、数据驱动的方式)。这些演绎和归纳分析旨在提供见解,然后反馈到科学动机中,为政策干预提供信息,或者更广泛地来说,推动基础和应用研究。
二、跟踪数据测量什么
使用行为跟踪数据进行测量的目的是,从仪器产生的原始数据中提取意义。所有的科学数据仪器都面临着这个问题,但是当我们使用从为其他目的设计的系统中回收而来的数据时,从原始数据到有意义的度量往往跨度非常大[18]。例如,未经处理的、报告特定纬度和经度的移动电话的移动数据在很大程度上是无趣的,而数据的处理使得我们能够测量接近度、移动和其他与社会相关的概念。
关键挑战是,我们的度量是否准确地捕捉到我们想要检查的构想。它是否与同一对象的其他度量紧密相配?构想和概念之间的潜在偏离是什么(例如,如果测量手机的物理活动,那么遗漏的静态活动有多重要?)。当我们检查假定不相关的构想时,我们的度量是否反映了预期的关联缺失?总的来说,21世纪的观测数据不是为研究而设计的,在能够利用这些数据回答科学研究问题之前,我们需要把这些观测数据与已知的概念联系起来。
度量的意义部分来自于理论。应用现有知识解释数字信号的理论驱动设计可以克服使用仪器化行为数据的许多问题。相反,缺乏理论化的特殊操作会使研究结果难以解释,并且在不同的研究中呈现出不一致。正如前面提到的[19],正规理论不仅有助于产生假设,而且有助于选择一种合适的方式来用大数据度量构想。
举个例子,让我们考虑使用移动流动性数据来研究新冠肺炎的传播。多个研究使用实时旅行数据来追踪武汉到中国其他省份的人员移动[20,21]。研究人员发现,来自武汉的人口流动对于冠状病毒是否流入一个地区具有强烈的预测性。于是当地疾控人员预测了病毒后续的传播。在这些研究中,有一个被很好地理论化过程,其假设是病毒的传播是由个体的接近所驱动的。而选择的理论框架反之也会表明,这些研究结果可以对其他案例有何程度的普适性。也就是说,我们可能会预想到在美国[22]出现类似的模式,但不会是澳大利亚,因为澳大利亚对游客实施了严格的测试和隔离程序。任何给定的实证研究结果在时间和空间上都必然是局部的;需要理论来将任何度量适当地移动到新的地理或时间背景[23,24]。
随着我们使用大量、复杂的数据源和格式进行更多的研究,为新度量的有效性提供见解的方法变得特别有价值。一个很有前景的方法是研究经典的、已被验证的自我汇报量表时,和度量相关概念的新方法相结合。例如,自我汇报的新闻关注度和曝光度可以与眼球追踪结合使用,以捕捉对在线内容的视觉关注[25]。类似三角测量的测量方法也有助于确认新行为构想的有效性和稳健性[26]。研究人员利用手机数据设计了一种基于接近度的测量方法,用来记录人们接近彼此的时间[27]。这些指标可以用于各种各样有用的目的。它们可以作为关系强度的指标,也可以作为一种追踪病毒传染途径的方法。但是,这里有错误的可能性:例如,两个蓝牙信标显示设备互相接近的人,他们可能中间隔着一堵墙,或者可能只是从同一个插座给手机充电。在这样的情况下,三角测量可以通过包含自我汇报的数据来实现,比如向某人的手机发送信息,询问当时附近还有谁。
对于基于互联网的研究而言,人们对数字平台上用户行为的基本群体特征和潜在机制的了解相对较少。许多基本概念仍然难以衡量,即使是在为研究人员提供便捷数据访问的在线平台上。尽管近年来有数千篇基于Twitter数据的论文,但社交媒体学者仍然发现,识别个人用户的人口统计特征仍然是一个巨大的挑战。此外,研究人员仍然无法可靠地区分人类和非人类(例如,机器人、集体账户或组织),尽管在这方面已经取得了重要进展[28,29]。因此,Twitter的大部分研究都是对账户或推文进行推断;很少有Twitter的研究可以合理地宣称是在对人类的行为进行陈述。对于关注Twitter上人类行为的研究问题,将用户帐户与管理数据或调查结果联系起来的方法有望在Twitter上识别人类及其人口统计属性[30]。
即使人类是特定行为的来源,但将特定行为归因于特定的人也可能会遇到挑战。例如,在广播电视的早期,受众研究遇到了多成员家庭的挑战[31]。这些案例的数据表明,有人同时喜欢儿童漫画和有线新闻,事实上这涉及两个不同的个体。因此,当行为是人(两个人使用同一个Netflix帐户)或设备(在智能手机和桌面上查看Twitter的同一个人)之间的共享时,技术设备可能会产生误导。进一步加剧的问题是,设备-人的不匹配可能随着时间的推移迅速演变。例如,基于桌面浏览数据的研究表明,新闻消费已经系统地改变,而这可能只是新闻消费从桌面浏览器向移动app的逐步转变的产物[32]。人们对这些不同系统(和设备)的使用缺乏稳定性,这可能使这种随时间推移的比较基本上变得不可能。
使用基于其他数据的模型可以促进对特定行为的测量。例如,某个人用的某一个设备可以从其他数据中建模,且该模型的输出和关于设备用户身份的离散假设相比更不敏感。有线新闻的浏览者可能是祖父母,而Xbox用户可能是孙辈。然而,这些模型中包含的数据总是来自过去,而且度量之间的关系本身就是不稳定的。这是归纳法的基本问题,如果没有形而上学的革命,就无法克服这个问题,我们建议不断更新的度量和模型应该代表我们对这个问题的最佳改进。也就是说,我们应该为我们衡量的偏差做好计划,并对度量如何具体反映当前社会现实进行持续评估。例如,衡量通货膨胀的指标需要评估人们消费的一系列商品是如何随时间变化的。这是一个有用的重新校准,尽管它也说明了这种方法的局限性,因为全新产品的出现(例如2000年时没有人购买智能手机)使得跨时间的消费天生无可比拟。
在互联网的推动下,通信技术的发展也导致了行为的分裂,形成了不同的数据仓库。让我们考虑一个研究问题:“异地同步语音中介通信”对于减少社会孤立感是否很重要。在过去半个世纪里,这种行为不断地分裂成不同的体系,从政府授权的垄断企业(例如,美国的Ma Bell)到寡头垄断企业,再到数不清的互联网提供商。此外,这些系统捕捉到的数据存在系统性偏差是很合理的——任何一个与你通过手机交谈的人都可能与你通过Zoom、Skype或WhatsApp交谈的人有系统性的不同[33]。连上述使用的折磨人的语言结构也反映了社会技术的复杂性:不久前,“异地同步语音中介通信”已被简单地描述为“电话通话”。这种技术碎片化的一个重要后果是,依赖于单一数字设备或服务的测量应相当谨慎地进行解释。我们发现的答案可能与我们在类似但不同的技术中通过测量行为得到的答案有所不同。讽刺地是,由于这种复杂性,通过简单的调查问题可能比通过单一平台的记录更好地准确了解一个人通常与谁交谈。
相反,在不同的数据仓库中观察到的看似相似的行为,实际上可能捕捉到截然不同的现象。正如在调查中用来生成联系人列表的各种名称生成器可以识别不同的社交纽带一样[34],Facebook上的朋友与Twitter追随者或LinkedIn联系人并不代表相同的关系。此外,尽管这些概念之间很可能存在着一些强有力的统计联系,但这些关系中没有一个表示口语或科学上使用的“朋友”。进一步说,这些系统会随着时间的推移而改变,它们允许用户做的事情也会发生变化。这反过来说明,我们网络社会行为、关系和结构背后的因果过程在不断变化。因此,我们现在必须意识到度量的系统变化特性,例如时间有效性和系统间有效性。然后,挑战就变成了发展度量,为给定的研究问题提供随时间或跨系统的某种程度的通用性。
另一个深层次的问题是度量的算法混乱[35]。这里的混乱指的是我们无法区分代表典型人类行为的信号和数字平台的规则产生的信号。在不知道系统是如何设计的情况下,我们很容易将社会动机归因于由算法决定驱动的行为。如果Twitter的信息流突然开始将体育内容的优先级提高,在用户对体育的潜在兴趣没有任何变化时也可能会发现谁赢得了奥运会比赛。这样的变化往往很难被发现,这既是因为它们有时是在未经通知的情况下引入的,也是因为它们可能会不均匀地展开,先影响某些用户群体。这种机制也以更微妙的方式发挥作用,例如,算法提示如何增强自然人类倾向。例如,如果Twitter系统性地建议你回关那些已经关注你的人,那就可以促进我们回报社会关系的自然倾向[36]。更普遍地说,互联网公司的目标是操纵人类行为,以增加其平台上的参与度(如Facebook、Twitter和Instagram)或在其产品上的支出(如Amazon和Ebay)。这些基于机器学习的操作是普遍存在的,任何从平台数据发展度量的努力都需要评估算法扭曲度量和下游分析的程度。由于其重要性,这些算法值得进一步研究[11,37]。
尽管对因果推理的深入讨论超出了本文的范围,但我们应该注意到,本文确定的一些度量问题为旨在确定因果关系的研究提出了一个特殊的问题。例如,随着时间的推移,度量缺乏稳定性可能会导致研究人员将焦点结果的变化归因于不相关的外部事件。上文关于谷歌流感趋势的讨论也与此相关。在这种情况下,有一个隐含的假设,即流感与流感相关的谷歌搜索存在因果关系。然而,如果2013年左右,谷歌在流感季节提出流感相关搜索,因为它在其复杂的算法机制中推断这是流感季节,那么对2013年和2008年相同行为的衡量将意味着截然不同的东西。
人类表达和语言的可塑性也对从语言和图像数据中推断态度和观点提出了普遍的挑战[38]。众所周知,Twitter上的情感表达方式很难被计算机解码,因为它们通常会被讥讽、反语和夸张所阻碍[39]。问题的严重程度取决于噪音的结构,同样也取决于什么是重要的,也就是研究问题。
三、追踪数据测量的对象
人类行为是一个多层次的概念,它通常需要个人层面的度量,以推断行为、态度和属性在集体层面的分布。研究问题应该明确一个特定研究的目标群体是什么。这些人口可以包括各种类型的人,也可以是特定于某个地理区域(城市或国家)、特定社区(兴趣团体或公司)或无数其他亚群体(青年、移民或政治家)。特别地,当涉及整个人口群体时,无论是从逻辑还是财务的角度来说,收集关于每个人的数据是不可行的。在这种情况下,研究人员最好收集关于随机样本的数据,这意味着人口的每个成员都有相同的概率出现在样本中。这种理想从来没有被完全实现,在实际世界中,人们对调查请求的答复率低于10%,不同招聘方式的人员可及率参差不齐,与这种理想甚至更不相关[40]。
对于系统级数据,人们可能会认为每个人都被数据代表了,因为所有用户的操作都在数据集中。然而,在这种情况下,采样针对的是那些收集数据的系统的用户和最活跃的成员[41]。这充其量只是对被调查平台的“便利普查”,而不是对整个人口的普查[42]。如果科学目标是对平台上的人做出陈述,那么这个普查可能是令人信服的。然而,任何跨越这一平台的概括都必须被更加批判性地看待。这是Twitter研究的一个特殊问题,Twitter是最常被引用的新兴数据来源,尽管只有约20%的美国人使用它,并且在大多数其他国家甚至更不流行[43,44,45]。重要的是,社交媒体平台的用户并不反映互联网用户的总体人口特征[41],也不反映兴趣等其他属性[41,44,46]。鉴于最近在促进研究人群在其他领域的代表性方面取得的进展[42,47],必须在社交媒体领域仔细思考这些问题[47]。我们还注意到,当应用于大规模数据时,重新校准数据以做出合理总体水平推断的方法可能尤为强大[48]。
当只研究平台用户群体的一个子集时,泛化问题就会被放大。关键的问题是,样本的性质是否以及如何影响推断。例如,正因此,一项对那些在个人资料中包含姓名和位置的Twitter用户的研究[49]提出了一个问题:这些发现是否适用于没有透露这些细节的Twitter用户?类似地,另一项研究[50]也对政治信息的消费模式进行了调查,调查对象是在个人资料中提供党派标签的少数Facebook用户,但调查结果是否适用于那些不透露自己政治倾向的个人?按照社会科学标准,这些研究的样本量相对较大,但这并不能缓解人们对该样本不能代表使用该平台的人群的担忧[51]。随着时间的推移,使用平台的人有时会发生很大的变化(Facebook曾经是哈佛大学本科生的专属领地),这就加剧了这个问题,在这种情况下,这些人口结构的变化本身也会影响平台上发生的事。
其他在普适性方面的关键问题还包括不同的平台引发系统性的不同行为。例如,同一个人在Facebook和Twitter上的表现往往不同[52]。更一般地说,一些人类行为高度依赖于环境,如果我们只能在工作、家庭或宗教环境中观察同一个人,我们可能会对人性做出完全不同的结论。普适性不仅是关于人口的函数,而且是特定观测环境的函数。根据研究问题的不同,这可能是问题,也可能不是问题。一个被明确定义的问题和人群将有助于确定度量结果与研究意图的吻合程度。
最后,我们注意到关键度量问题,即关于抽样的系统偏差是什么。一般来说,我们的数据收集系统偏向于远离少数群体,尤其是边缘人群;此外,我们关于人口的理论问题通常集中在分布的中间。代表性对于理解人类而言是一个极其重要的问题,无论是现在还是过去。有研究分析谷歌图书(Google Books,人类知识最大的数字化集合)的文本,希望得出关于这些文本在几个世纪内的语言变化如何与民族情感的转变相一致的结论[4]。这一语料库作为语言使用的一种表现形式受到了影响,因为它的组成随着时间的推移发生了系统性的变化(例如,在二十世纪,科学文本的代表性要高得多)[1],并且因为即使是一套精心策划的书也会反映出不具代表性的精英的现实。即使是有史以来规模最大的图书馆也无法发现那些虽然在出版文献中没有代表,但仍然有能力采取行动并改变历史进程的人。
这些代表性问题是二十世纪社会科学方法中的一个主要关切。通过邮件联系受访者系统地排除了无家可归的人群,电话调查排除了没有电话的人群,亲自进行的调查取决于人们对与陌生人这种互动方式的舒适度和信任度。
观察行为流可能受到类似偏差的影响。首先,收集数据的仪器通常是个人拥有的消费品(例如,移动电话或计算机),因此成本是一个障碍。其次,这些工具通常是由针对有钱人的企业商业模式驱动的。第三,当人们选择不使用隐私服务时,那些更关心或更了解隐私问题的人在跟踪行为系统中的代表性可能会降低。
然而,这些数据流具有一些关键的补偿特性。传感器技术可能会填补重要的数据空白,让那些原本会被从地图上抹去的人变得可见。例如,在没有家庭收入和消费调查的情况下,卫星图像被用于建立全球南方(Global South)的财富和贫困指标[53]。现代技术的普遍性意味着,在许多情况下,代表是优于传统的数据收集机制的——拥有一部手机比拥有一个家要便宜。这与杜波依斯(W. E. B. Du Bois )在 19 世纪末和 20 世纪初用于研究非裔美国人个人的行政数据有相似之处[54]。一个实行种族等级制度的行政国家的数据肯定不是中立的,但在提供社会中最危险地位的人的可见度方面仍然具有关键价值。
此外,大样本量允许我们观察数据子集的行为,例如,少数群体(一般意义上的)和统计上不常见但会引发后果的事件(如仇恨言论或错误信息)[49,55,56],在这些案例中,样本量和我们放大较小人群和罕见数据点的能力比样本的代表性更重要[57]。正如帕累托(Pareto)很久以前所观察到的那样,人类的许多行为都集中在人口的微小部分[58];然而,20世纪的方法通常不适合研究这种社会现实。也许21世纪的社会理论将能够利用微观层面的行为数据来理解相互依存的结构如何产生某些宏观层面的模式[59]。
四、测量的获取与道德
与哈勃望远镜的数据相比,来自社会技术系统的新兴数据流提出了两个额外的挑战。首先,哈勃望远镜是由科学机构控制的,其目标想必是回答科学问题。Twitter等平台的制度目标显然不是回答科学问题。因此,第一个问题是,什么是可以被度量的?第二,人类作为研究的参与者提出了道德问题,而遥远的星系显然没有。所以接下来的问题是,应该度量什么?我们将依次解决这两个问题。
根据生成数据的系统的不同,可以测量的内容会有很大不同。设计一个小规模的、依赖于同意参与者的数据收集系统是有可能的[60];然而,访问数百万人的数据通常需要与平台合作。基于互联网的通信数据有着广泛的可用性,其访问规则在不同的数据持有者和时间下有很大的差异。在限制最少的一端,像Reddit和Wikipedia这样的平台允许获取几乎所有的那些终端用户以机器可读的格式可查看的内容。相比之下,像Facebook和Twitter等公司提供的限制访问机制要多得多,它们受到时间、数据量的限制,而且并非所有公开可见的数据都可以通过编程方式访问。
值得注意的是,目前没有一个主要的平台提供关于人们关注的个人层面的数据,这在目前基于互联网的度量中是一个非常大的缺口[61]。此外,没有一个平台能够提供广泛的随机对照试验(以AB试验的形式)的信息访问,这在原则上可以推断其算法对个体的影响[62]。一般来说,任何控制研究人员感兴趣的数据的私人机构,在没有相反规定的情况下,都可以根据自己的选择决定数据访问的条款。像Twitter和Facebook这种平台的行为是公众关心的科学问题的焦点(思考一下:一个平台是否放大了错误信息的传播?平台对仇恨言论的应对举措是什么?),这使这种控制成为一个严重的问题[63]。学术界在这些领域的一项职责就是向公众提供关于这些重要问题的信息。关于什么可以被度量的一个推论必须是:如果被质疑的权力控制着对用来构建“真相”的数据的访问,那么有可能对权力说真话吗?如果没有,是否有可能信任任何允许从给定系统中提取的度量?
新兴的数据来源也带来了新的道德挑战。我们关注的是那些与度量相关的问题,尤其是那些能够且应该被度量的问题。关于跟踪数据伦理以及数据访问的替代模型的更广泛讨论,可在他处获得[18,64,65,66];在此,我们简要介绍五个特别紧迫的问题。
首先,尽管知情同意是对人类参与者研究的基础,但第三方获得的匿名数据通常不被视为“人类参与者数据”,因此不受机构审查委员会的审视。研究人员在收集数据时考虑数据收集场景时的道德义务是什么?在一个最近的例子中,来自极右翼社交网络Parler的超过70Gb的数据在2021年1月初被公开发布,包括GPS衍生的位置数据[67]。研究人员是否能够道德地分析这一数据集是一个引发持续争论的话题,特别是考虑到该网站被用于策划2021年1月6日美国国会大厦暴动。更普遍地说,人们可能不知道不同的系统是如何跟踪他们的,无论是通过手机的移动数据[68],或者浏览数据。那么,当第三方追踪的目标最多只是名义上意识到这一事实时,使用第三方追踪数据的道德准则是什么呢?
第二,行为数据集中的详细程度意味着,对于重新识别工作来说,可靠的匿名化通常实际上是困难的或不可能的[69]。需要注意的是,取消标识的匿名数据可以是无法重新标识的类型,或是可以重新标识的类型。围绕“差分隐私”出现了一些允许向数据集添加噪声的方法,从而一定程度上保证了数据的匿名性,使其能够可靠地进行重新识别[70,71]。然而这里存在一个折衷,因为增强隐私的噪声添加会降低数据的效用。这是Social Science One project 中采用的方法,该项目提供了对Facebook数据[72](方框2)的分析访问。被授予访问权限的团队面临的难题之一是,结果数据是否保留了回答他们问题的价值(注:一些作者参与了Social Science One和Facebook 2020 Election Research Project)。
第三,对于公开可见的行为,比如推特,什么样的隐私期望是合理的?研究人员必须要履行什么样的义务来掩盖这些行为?例如,研究人员什么时候应该避免提及(在出版物或演示中)诸如用户名和完整的社交媒体消息之类的信息,因为可能引起负面关注或骚扰?一些人认为,自动匿名公开数据可能也不是正确的方法,相反,应该咨询内容创作者他们的偏好[73]。
第四,出于两个原因,对个人自主原则的依赖在本质上是有限的。在一个信息和洞察网络化的世界里,一个人透露给其他人的信息经常会溢出。网络媒体的功能,顾名思义,就是促进人际间的可视性[74]。例如,共享电子邮件数据的个人必须提供来自其他个人的信息。剑桥分析公司(Cambridge Analytica)的丑闻表明了这种网络信息披露的危险性,在这件事中,个人使用了Facebook应用,而Facebook应用又提供了访问这些用户朋友行为数据的途径。然而,信息溢出的风险是一个更为普遍的原则,这在数字追踪数据中并不新鲜:个人披露几乎总存在潜在的溢出。例如,一个人的基因数据有可能提供关于其近亲的线索[75];并且几乎所有关于个人的数据都提供了关于他人的信息。一个人对其政治偏好的回应可以让人了解到其他家庭成员的偏好,关于一个人吸毒的信息可以让人了解对此人朋友的潜在吸毒情况。
同样还有个体内的信息推断,这其中所提供的信息(可能是经过同意的)能够做出个人意料之外的推断[76]。实际中的道德结果不可能是禁止所有可能存在信息披露外溢或推断的研究;然而,这确实意味着数据共享和数据可见性通常需要受到重要的限制。数据安全的重要性也需要被重视。
在我们关于“度量对象”讨论的基础上,在试图将基于跟踪数据的研究结果推广到研究平台以外的人群以及参与者的实际生活时,必须格外谨慎[41]。重要的是要找到办法让数字代表性不足的参与者参与进来,特别是当这类研究被用来为广泛的社会或公司政策提供决策依据时。
相反,与传统的二十世纪方法相比,当数字形式的度量能够更好地代表边缘群体时,我们的道德义务就应该是使用它们,正如上文提到的卫星数据的例子所强调的那样。社会面临的选择不是数字技术是否将被用来度量人类行为,而是公司或国家监控之外的任何人何时、如何以及是否能够获得这些数据。理想的情况是,大规模的数字数据源将流入各项度量,为详细政策和有针对性的干预措施提供信息,而不仅仅是一刀切的举措,因为这些举措往往对少数群体效果不佳。
最后,该领域有责任对实践中有问题的度量步骤所产生的决策进行批评。先前发表的一项研究表明,许多医院使用的一种算法存在种族偏见,而这种偏见是由度量误差造成的,这是一个很好的例子,既说明了自动化决策中有缺陷的度量所造成的危险,也说明了良好的科学有可能帮助纠正这些问题[11]。
方框2 数据获取和道德问题
平台控制数据访问的可能影响
研究工具可能会因平台对数据访问的更改而在未经告知的情况下过时。
私人数据持有者可能要求外部研究人员与其密切合作,作为获取数据的一个条件。此外,这种合作成果在出版前可以接受私人数据持有者的审查。在这种平台的直接控制下进行的研究不能成为相关平台的关键见解的来源。
如果研究人员的工作超出了数据持有者的兴趣范围,或者不愿意直接与数据持有者合作,那么他们可能会退而求其次,使用违反平台服务条款的方法。
在保持研究人员独立性的同时,促进获取平台数据的初代范例包括:
Social Science One:这项工作涉及到外部批准和对应用差分隐私的总体Facebook数据的研究资助[72]。
The Facebook 2020 Election Research Project:该项目涉及外部研究人员与Facebook的合作,其中Facebook研究人员使用预先备案的分析计划和外部专家界定的度量进行数据分析,外部专家还监督分析的执行,并享有完全的结果解释权[77]。
道德问题
研究人员在考虑数据收集场景时(例如通过泄密或黑客攻击)的道德义务是什么?
研究团体如何解决数据匿名化技术(例如通过添加噪声)带来的权衡问题?
对于公开可见的行为(如社交媒体帖子),何种隐私期望是合理的?
我们如何管理信息溢出,即从同意的个人收集的数据泄露了关于他人的信息,且他人并不知情或不同意?
我们如何确保边缘群体在研究中得到充分和准确的代表?
五、展望
方框3总结了本文的基本论点。全球社会的大量工具拥有巨大潜力来改变我们对社会世界的理解。然而,人类行为工具化的革命要求了人类行为度量的变革。任何新的度量制度都需要与新旧社会理论的可能性相匹配,在这些高度工具化的社会技术系统中应对度量人类的不稳定性的本质,并开发一种新的人类参与者伦理研究模式,平衡个人权利和集体利益。
方框3 度量的关键问题
什么是重要的?
我们可以度量很多概念。我们必须明确引领我们选择研究问题的思想、价值观、优先次序和原则,以及我们如何构建一个值得研究的课题。
度量的时间、空间、结构和文化完整性是什么?
表面相似的结构可以用非常不同的方式来度量,同样的度量标准可以随着度量它的系统的变化而变化,或者在不同的地理、人口和文化群体中不一致。
谁被度量?
选择使用像社交媒体平台这样的各种系统的人并不是随机的,他们使用这些系统的哪些部分以及使用的积极程度也不是随机的。因此,构成许多研究基础的此类系统用户的跟踪数据可能无法推广到更广泛的人群,甚至无法推广到其他看似相似的平台。
谁有权限度量?
科学受到数据访问权限的限制。这些数据受到创造它们的机构和技术的功能、目的和协议的限制。这些限制永远不会得到完全解决,因此应该成为该领域的核心关切。
度量什么是合乎道德的?
数字数据触及的人比以往任何时候都多,不仅可以收集到在研究中的人的信息,还可以收集到在这些人周围但本身并不在研究中的人的信息。信息外溢问题是网络世界中所有研究的固有问题,它破坏了当前的研究伦理框架中个人自主的基本原则,并大大增加了研究人员维护数据安全的责任。关于同意、隐私和保密的标准和实践必须考虑到这些现实。
参考文献
1.Pechenick, E. A., Danforth, C. M. & Dodds, P. S. Characterizing the Google Books Corpus: strong limits to inferences of socio-cultural and linguistic evolution. PLoS ONE 10, e0137041 (2015).
2. Dietrich, B. J., Hayes, M. & O’Brien, D. Z. Pitch perfect: vocal pitch and the emotional intensity of congressional speech. Am. Polit. Sci. Rev. 113, 941–962 (2019).
3.Dietrich, B. J. Using motion detection to measure social polarization in the U.S. House of Representatives. Polit. Anal. 29, 250–259 (2021).
4. Michel, J.-B. et al. Quantitative analysis of culture using millions of digitized books. Science 331, 176–182 (2011).
In this study, 4% of all books that have been published were digitized and used to examine changes in phonology, word use and the adoption of new technologies over long periods of time.
5.Merton, R. K. in Social Theory and Social Structure 39–72 (Free Press, 1968).
6. Watts, D. J. Everything Is Obvious: Once You Know the Answer (Crown Business, 2011).
7. Simon, H. A. Bandwagon and underdog effects and the possibility of election predictions. Public Opin. Q. 18, 245–253 (1954).
8. Mutz, D. C. Impersonal Influence in American Politics (Cambridge Univ. Press, 1998).
9. Westwood, S. J., Messing, S. & Lelkes, Y. Projecting confidence: how the probabilistic horse race confuses and demobilizes the public. J. Polit. 82, 1530–1544 (2020).
10. O’Neil, C. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy (Crown, 2016).
11. Obermeyer, Z., Powers, B., Vogeli, C. & Mullainathan, S. Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 447–453 (2019).
12. Landsberger, H. A. Hawthorne Revisited (The New York State School of Industrial and Labor Relations, 1958).
13. Mayo, E. The Human Problems of an Industrial Civilization (Routledge, 2004).
14. Lazer, D., Kennedy, R., King, G. & Vespignani, A. The parable of Google Flu: traps in big
data analysis. Science 343, 1203–1205 (2014).
15. Brunton, F. & Nissenbaum, H. Obfuscation: A User’s Guide for Privacy and Protest (MIT Press, 2015).
16. Davis, D. W. The direction of race of interviewer effects among African-Americans: donning the Black mask. Am. J. Pol. Sci. 41, 309–322 (1997).
17. American National Election Studies. 1978 Time Series Study https://electionstudies.org/ wp-content/uploads/2018/03/anes_timeseries_1978_qnaire_post.pdf (1978).
18. Salganik, M. J. Bit by Bit: Social Research in the Digital Age (Princeton Univ. Press, 2017). 19. Patty, J. W. & Penn, E. M. Analyzing big data: social choice and measurement. PS Polit. Sci. Polit. 48, 95–101 (2015).
20. Kraemer, M. U. G. et al. The effect of human mobility and control measures on the COVID-19 epidemic in China. Science 368, 493–497 (2020).
21. Jia, J. S. et al. Population flow drives spatio-temporal distribution of COVID-19 in China. Nature 582, 389–394 (2020).
22. Badr, H. S. et al. Association between mobility patterns and COVID-19 transmission in the USA: a mathematical modelling study. Lancet Infect. Dis. 20, 1247–1254 (2020).
23. Munger, K. The limited value of non-replicable field experiments in contexts with low temporal validity. Soc. Media Soc. 5, 1–4 (2019).
24. Deaton, A. & Cartwright, N. Understanding and misunderstanding randomized controlled trials. Soc. Sci. Med. 210, 2–21 (2018).
25. Vraga, E. K., Bode, L., Smithson, A.-B. & Troller-Renfree, S. Accidentally attentive:
comparing visual, close-ended, and open-ended measures of attention on social media.
Comput. Human Behav. 99, 235–244 (2019).
26. Guess, A., Munger, K., Nagler, J. & Tucker, J. How accurate are survey responses on social media and politics? Polit. Commun. 36, 241–258 (2019).
27. Aleta, A. et al. Modelling the impact of testing, contact tracing and household quarantine on second waves of COVID-19. Nat. Hum. Behav. 4, 964–971 (2020).
28. Echeverría, J. et al. LOBO: evaluation of generalization deficiencies in Twitter bot
classifiers. In Proc. 34th Annual Computer Security Applications Conference 137–146 (ACM, 2018).
29. Ferrara, E., Varol, O., Davis, C., Menczer, F. & Flammini, A. The rise of social bots.
Commun. ACM 59, 96–104 (2016).
30. Hughes, A. G. et al. Using administrative records and survey data to construct samples of Tweeters and Tweets. Public Opin. Q. https://doi.org/10.1093/poq/nfab020 (2021). 31. Napoli, P. M. Audience Evolution: New Technologies and the Transformation of Media
Audiences (Columbia Univ. Press, 2011).
32. Yang, T., Majó-Vázquez, S., Nielsen, R. K. & González-Bailón, S. Exposure to news grows less fragmented with an increase in mobile access. Proc. Natl Acad. Sci. USA 117, 28678–28683 (2020).
33. Haythornthwaite, C. Exploring multiplexity: social network structures in a computer-supported distance learning class. Inf. Soc. 17, 211–226 (2001).
34. Campbell, K. E. & Lee, B. A. Name generators in surveys of personal networks. Soc. Netw. 13, 203–221 (1991).
35. Wagner, C. Measuring algorithmically infused societies. Nature https://doi.org/10.1038/ s41586-021-03666-1 (2021).
36. Healy, K. The performativity of networks. Eur. J. Sociol. 56, 175–205 (2015).
37. Rahwan, I. et al. Machine behaviour. Nature 568, 477–486 (2019).
38. Neuendorf, K. A. The Content Analysis Guidebook (Sage, 2017).
39. Davidov, D., Tsur, O. & Rappoport, A. Semi-supervised recognition of sarcasm in Twitter
and Amazon. In Proc. 14th Conference on Computational Natural Language Learning 107–116 (Association for Computational Linguistics, 2010).
40. Groves, R. M. Nonresponse rates and nonresponse bias in household surveys. Public Opin. Q. 70, 646–675 (2006).
41. Hargittai, E. Potential biases in big data: omitted voices on social media. Soc. Sci. Comput. Rev. 38, 10–24 (2020).
42. Lazer, D. & Radford, J. Data ex machina: introduction to big data. Annu. Rev. Sociol. 43, 19–39 (2017).
43. Correa, T. & Valenzuela, S. A trend study in the stratification of social media use among urban youth: Chile 2009–2019. J. Quant. Descr. Digit. Media 1, https://doi.org/10.51685/ jqd.2021.009 (2021).
44. Mellon, J. & Prosser, C. Twitter and Facebook are not representative of the general population: political attitudes and demographics of British social media users. Res. Polit. 4, 1–9 (2017).
45. Beisch, N. & Schäfer, C. Internetnutzung mit großer Dynamik: Medien, Kommunikation, Social Media. AS&S (2020).
46. Hargittai, E. & Litt, E. The Tweet smell of celebrity success: explaining variation in Twitter adoption among a diverse group of young adults. New Media Soc. 13, 824–842 (2011).
47.Henrich, J., Heine, S. J. & Norenzayan, A. Most people are not WEIRD. Nature 466, 29 (2010).
48.Wang, W., Rothschild, D., Goel, S. & Gelman, A. Forecasting elections with non-representative polls. Int. J. Forecast. 31, 980–991 (2015).
49.Grinberg, N., Joseph, K., Friedland, L., Swire-Thompson, B. & Lazer, D. Fake news on Twitter during the 2016 U.S. presidential election. Science 363, 374–378 (2019).
50.Bakshy, E., Messing, S. & Adamic, L. A. Exposure to ideologically diverse news and opinion on Facebook. Science 348, 1130–1132 (2015).
51.Meng, X.-L. Statistical paradises and paradoxes in big data (I): law of large populations, big data paradox, and the 2016 US presidential election. Ann. Appl. Stat. 12, 685–726 (2018).
52.Hargittai, E., Füchslin, T. & Schäfer, M. S. How do young adults engage with science and research on social media? Some preliminary findings and an agenda for future research. Soc. Media Soc. 4, 1–10 (2018).
53.Blumenstock, J. Don’t forget people in the use of big data for development. Nature 561, 170–172 (2018).
54.Battle-Baptiste, W. & Rusert, B. (eds) W. E. B. Du Bois’s Data Portraits: Visualizing Black America (Princeton Architectural Press, 2018).
55.Siegel, A. A. et al. Trumping hate on Twitter? Online hate speech in the 2016 US election campaign and its aftermath. Quart. J. Polit. Sci. 16, 71–104 (2021).
56.Allen, J., Howland, B., Mobius, M., Rothschild, D. & Watts, D. J. Evaluating the fake news problem at the scale of the information ecosystem. Sci. Adv. 6, eaay3539 (2020).
57.Foucault Welles, B. On minorities and outliers: the case for making big data small. Big Data Soc. 1, 1–2 (2014).
58. Newman, M. E. J. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 46, 323–351 (2005).
59. González-Bailón, S. Decoding the Social World: Data Science and the Unintended Consequences of Communication (MIT Press, 2017).
60.Stopczynski, A. et al. Measuring large-scale social networks with high resolution. PLoS ONE 9, e95978 (2014).
61. Lazer, D. Studying human attention on the Internet. Proc. Natl Acad. Sci. USA 117, 21–22 (2020).
62.Aral, S. & Eckles, D. Protecting elections from social media manipulation. Science 365, 858–861 (2019).
63.Puschmann, C. & Burgess, J. The politics of Twitter data. HIIG Discussion Paper Series No. 2013-01 http://www.ssrn.com/abstract=2206225 (2013).
64.Chen, W. & Quan-Haase, A. Big data ethics and politics: toward new understandings. Soc. Sci. Comput. Rev. 38, 3–9 (2020).
65.Breuer, J., Bishop, L. & Kinder-Kurlanda, K. The practical and ethical challenges in acquiring and sharing digital trace data: negotiating public–private partnerships. New Media Soc. 22, 2058–2080 (2020).
66. Zook, M. et al. Ten simple rules for responsible big data research. PLOS Comput. Biol. 13, e1005399 (2017).
67. Greenberg, A. An absurdly basic bug let anyone grab all of parler’s data. Wired (12 January 2021).
68. Valentino-DeVries, J., Singer, N., Keller, M. H. & Krolik, A. your apps know where you were last night, and they’re not keeping it secret. The New York Times https://www.nytimes. com/interactive/2018/12/10/business/location-data-privacy-apps.html (10 December 2021).
69. Sweeney, L. Simple demographics often identify people uniquely. Privacy Working Paper 3 https://dataprivacylab.org/projects/identifiability/paper1.pdf (Carnegie Mellon University, 2000).
70. Wood, A. et al. Differential privacy: a primer for a non-technical audience. Vanderbilt J. Entertain. Technol. Law 21, 209–276 (2019).
71. Dwork, C. & Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 9, 211–407 (2013).
72. King, G. & Persily, N. A new model for industry–academic partnerships. PS Polit. Sci. Polit. 53, 703–709 (2020).
73. Bruckman, A., Luther, K. & Fiesler, C. in Digital Research Confidential: The Secrets of Studying Behavior Online (eds Hargittai, E. & Sandvig, C.) 243–258 (MIT Press, 2015).
74. Marwick, A. E. & boyd, d. Networked privacy: how teenagers negotiate context in social media. New Media Soc. 16, 1051–1067 (2014).
75. Bieber, F. R., Brenner, C. H. & Lazer, D. Finding criminals through DNA of their relatives. Science 312, 1315–1316 (2006).
76. Zheleva, E. & Getoor, L. To join or not to join: the illusion of privacy in social networks with mixed public and private user profiles. In Proc. 18th International Conference on World Wide Web 531–540 (2009).
77. Miller, G. As U.S. election nears, researchers are following the trail of fake news. Science (26 October 2020).
78. Merton, R. K. The self-fulfilling prophecy. Antioch Rev. 8,193–210 (1948).
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:Lazer, D.等

 14:58
14:58









 15:05
15:05
 01:24:58
01:24:58
 18:38
18:38
 31:30
31:30
 10:14
10:14
 13:55
13:55
 32:32
32:32
 29:07
29:07
 20:47
20:47


