2021-10-28 21:46


扫码打开虎嗅APP

爬虫与互联网发展相伴,合法、正当地利用这项技术,能够为公众带来福祉;相反,不对爬虫技术应用加以“约束”,则可能让互联网沦为“数字丛林”,侵害各方权益。本文来自微信公众号:财经E法(ID:CAIJINGELAW),作者:殷继,编辑:朱弢,题图来自:视觉中国
在大数据时代,除直接通过用户采集,另一个主要的数据来源就是使用网络爬虫采集公开信息。爬虫的使用到了何种程度?有业内人士称,互联网50%以上,甚至更高的流量其实都是爬虫贡献的。对某些热门网页,爬虫的访问量甚至可能占据了该页面总访问量的90%以上。
从技术角度来看,爬虫就是通过程序去模拟人类上网或者浏览网页或者APP行为,再从中抓取爬虫作者所需要的信息的过程。随着数据产业的不断发展,数据价值的日益高涨,对于数据的争夺日趋激烈。“爬虫”与“反爬虫”成为无休止的“攻防对抗”,一些爬虫违反网站意愿,对网站进行未经授权的访问,获取了网站大量公开或非公开的数据,由此引发诸多法律争议。
10月23日,杭州长三角大数据研究院、上海市杨浦区人民检察院、上海市企业法律顾问协会、浙江省企业法律顾问协会与《财经》商业治理研究院共同发起“长三角数据合规论坛暨数据爬虫的法律规制研讨会”,邀请了多位重量级法律学者、法官、检察官、互联网从业者从“数据爬虫技术与产业影响”、“数据爬虫的民法责任”、“数据爬虫的刑事合规”等不同角度展开讨论。
01 爬虫无处不在
“爬虫应用场景广泛,合规与不合规的场景都有。例如,抓取电商网站的评价数据做市场调研;做数字内容的可以利用爬虫去抓取网络相应内容;抓取裁判文书网数据,进行优化后推出“付费版数据库”;企查查、天眼查也在利用爬虫技术对政府公开数据实现商业使用。”欧莱雅中国区数字化负责人刘煜介绍。
刘煜对爬虫的基本原理进行了解释,通常爬虫会定位网站所有的URL链接,获取页面里的数据,再对数据进行拆解利用。不管在网页端还是移动端,基本爬虫都基于这样的原理。使用爬虫技术对于“爬虫一方”和“被爬虫一方”都具有风险,轻则网站崩溃、重则面临牢狱之灾。
具体来说,对于那些小网站或者技术实力弱的网站,如果爬虫7X24小时持续访问,可能因服务器无法承受激增的流量,导致网站崩溃。更麻烦的是,对编写爬虫的程序员来说,如果爬到不该爬取数据,再利用这些数据,可能属于违法行为。
刘煜表示,在不同场景中,对于爬虫的态度截然不同。例如,搜索引擎爬虫受人欢迎,因为搜索引擎能提高被爬网站的曝光率;但大多数网站也会基于服务器的风险、或者种种商业原因,不希望爬虫抓取数据。拒绝分两种,“反爬”机制,“反反爬”机制。网站可以去制定相应策略或者技术手段,去防止爬虫抓取数据。
网站常见的应对策略是放置Robots协议,该协议由荷兰工程师傅马丁·科斯特(Martijn Koster )在1994年编写,后来成为数据爬取方和被爬取方之间通行的沟通机制。中国互联网协会2012年发布的《中国互联网行业自律公约》中,将遵守Robots协议认定为“国际通行的行业管理与商业规则”。
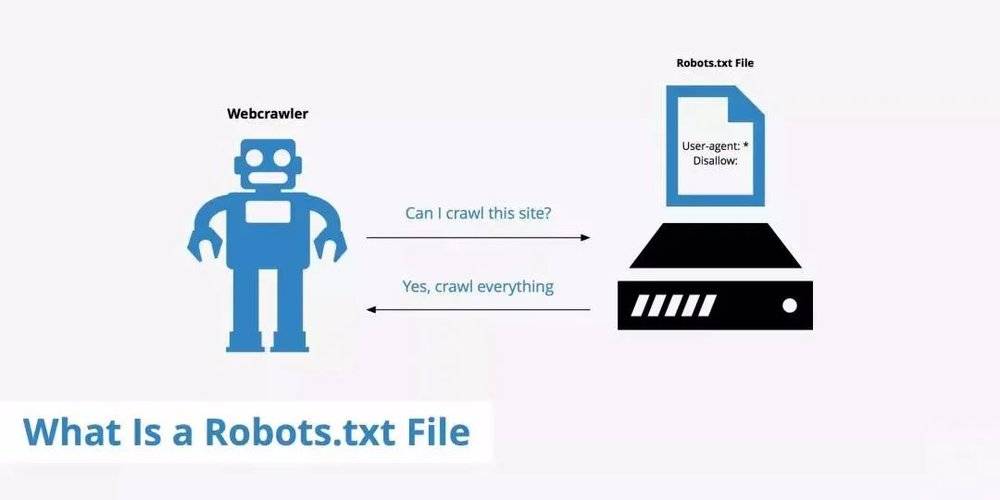
Robots协议是数据爬取方与被爬取方之间的意愿沟通机制
但刘煜称,Robots协议更像君子协议,只能起到告示作用,起不到防范作用。爬虫技术、反爬虫技术、反反爬虫技术一直在迭代,只要网站、App能够被用户访问,就存在被爬取的可能。
恶劣的爬虫手段会造成社会资源和技术资源的浪费,这些资源都来之不易。小红书总法律顾问曾翔表示,有的爬虫会通过“模拟真人访问”或者“通过协议破解”来爬取数据。“这些都是不光彩的手段,被爬取得的网站不得不采取攻防措施,造成不少企业资源的浪费。”
曾翔说,对内容平台而言,遭遇爬虫攻击极易对于自身以及用户享有的知识产权造成侵害。通常爬取都是有目的的,如果爬取到核心商业机密,可直接用到其他地方形成竞争优势。另外,在他看来,爬虫还涉及到对于互联网公共秩序的破坏。“爬取的数据能否有效利用,是否被置于监管之下,这些数据流向何方,都是非常大的问号。”
02 爬虫的民事责任判定
“技术是中立的,但技术应用永远不是中立的。”新浪集团诉讼总监张喆表示,在讨论爬虫技术原理时,更重要的是看爬虫技术用来干什么,看它的行为本身是否具有正当性。
近期,北京市高级人民法院(下称“北京高院”)对“今日头条诉微博不正当竞争案”作出二审判决。此案中,微博因在Robots协议中设置黑名单,限制字节跳动公司抓取相关网页内容被诉。法院认为,微博是在行使企业自主经营权范畴内的正当行为,并不构成不正当竞争,同时撤销一审判决等。张喆表示,司法机关对Robots协议评价是“一体两面”的。
在2020年北京高院对“360诉百度不正当竞争案”做出判决时,认为百度在缺乏合理、正当理由的情况下,不得以主体作为区分,去限制访问搜索引擎抓取网站网页内容(太拗口了,简单点)。而在“今日头条诉微博不正当竞争案”中,法院确立的原则是,企业有权在自主经营范围内去限制其他访问者,只有在违反公共利益以及侵犯消费者权利的时候,才有可能被认定其行为不正当。
在华东政法大学法律学院教授、数据法律研究中心主任高富平看来,爬虫和数据产业是连一起的,现在所谓的数据公司谈及的数据智能、大数据分析基本上是抓取数据,再进行挖掘分析。现在普遍认为爬虫是项中立性的技术,但更多时候,使用者是为实现“不劳而获”的目的。
高富平认为,不谈论数据合法生产者具有控制权,难以对爬虫合法性进行判断。国内外爬虫的合法性边界探讨,主要着眼从数据爬取的手段、目的两个方面。
从手段上来看,爬虫无视网站的访问控制,或者假扮为合法访问者,会被认为是不合法的;从目的上来看,数据爬取一方是否对被爬取一方提供的部分产品或服务进行“实质性替代”,如果属“实质性替代”,则目的便是不合法。
网站合法积累数据资源,那么网站生产端就可以对其进行控制使用,更重要的是承认数据控制者可以基于商业目的来开放数据,通过许可使用方式、交换、交易等方式让数据能够被更多人使用。”高富平对此补充道,“基于数据合法生产者具有控制权的前提,就可以对于那些无视Robots协议的爬取者进行打击。”
上海浦东法院知识产权庭法官徐弘韬认为,Robots协议与数据流转有两个问题需要考虑:第一,“互联互通”与数据共享之间的度如何把握;第二,当下各互联网产业经营者采取的Robots协议策略是否可能导致数据孤岛。互联互通的实质在于确保数据有序流转,而不是强行要求互联网产业经营者对己方平台内的数据资源向竞争对手全面开放。在“互联互通”的语境下,“有序”和“流转”同等重要、缺一不可,需排除假借“互联互通”妨碍公平竞争、危害用户数据安全的行为。
在某新媒体公司爬取微信公众平台数据案中,杭州互联网法院已经亮明观点。网络平台设置了Robots协议,希望在竞争过程中还是能遵守竞争规范,或者至少能保持一个互相尊重互相遵守协议,才是有序的基础。
在上述案件中,法院认为,任由第三方爬虫工具爬取公众号信息会打击平台创造积极性,并扭曲大数据要素市场竞争机制;从消费者利益角度,未经授权爬取信息并进行展示,未能尊重信息发布主体的意愿;从公共利益角度,被告爬取信息后未深度挖掘、创新,也无更深层次的应用,未能提升社会整体公共利益,加之爬取数据来源并非正常,难谓正当。
徐弘韬认为,数据是内容产业的核心竞争资源,内容平台经过汇总分析处理后的数据往往具有极高经济价值。如果要求内容平台经营者将其核心竞争资源向竞争对手无限开放,不仅有违“互联互通”的精神实质,也不利于优质内容的不断更迭和互联网产业的持续发展。
徐弘韬表示,对非搜索引擎爬虫的正当性判断,可以归纳为四个要素:第一看是否尊重被抓取网站预设的Robots协议;第二看是否破坏被抓取网站的技术措施;第三看是否威胁用户数据的安全;第四从创造性与公共利益的衡量。
徐弘韬特别指出,包括身份数据、行为数据等在内的用户数据,不仅仅是经营者的竞争资源,同样具有个人隐私属性,而此类数据的集合更涉及社会公共利益。如果在抓取数据时危害用户数据安全,其行为不具正当性。
03 爬虫涉及刑事合规
刑事合规,最初起源于美国,是指国家以刑法为工具,为推动企业开展合规管理,建立的一套督促机制、约束机制和激励机制。
2020年,在最高人民检察院推动下,深圳、浙江、江苏、上海等地基层检察机关积极探索企业刑事合规。为了鼓励更多企业进行合规改制,“刑事合规不起诉”这一全新的刑事诉讼制度在全国铺开,尝试选取有可能建立合规的涉罪企业,通过企业认罪认罚、承诺建立合规计划,进而对企业采取不起诉措施。
上海市人民检察院第二分院第三检察部副主任吴菊萍表示,刑事合规主要是为了给涉案企业一个整改自救、重新出发的机会,也是为了保证社会经济的高质量发展。而目前很多企业所关注的刑事合规更多的是在探讨其经营行为如何避免刑事风险。吴菊萍认为,企业利用爬虫技术来做数据分析,就应当注重如何落实刑事合规。
吴菊萍表示,“除了木马病毒程序等本身就不合法的技术,我们评判一项与爬虫技术相关的行为是否构成犯罪,首先要看行为人用爬虫技术干了什么事情,有没有社会危害性,然后再去评判该行为是侵入计算机信息系统,还是非法获取计算机信息系统数据,再看爬取的数据涉及的是企业数据还是公民个人信息,分别适用相关罪名。”
其中,还需要考虑到被爬取数据的法律属性到底是财产还是仅仅只是数据。吴菊萍表示,这在司法实践中存在较大争议。“比如,我们有个以非法拘禁的方法强迫对方交付虚拟货币的案件,刑事上认定为非法拘禁罪,否定了虚拟货币的财产属性,民事上判返还财产,认可了财产属性。”她认为,数据在数字经济发展中是一个重要的生产要素,本质上应当具备财产属性,但当前的法律和司法实践还没有完全跟上。
华东政法大学教授张勇对爬虫可能涉及到的犯罪行为进行分类:从可能侵犯到的权益上看,包括计算机系统安全、个人信息、版权、国家秘密、商业秘密、市场竞争秩序等;从爬取方式来看,可能危害到计算机信息系统安全,非法获取公民个人信息,非法获取商业秘密,破坏版权技术保护措施等;从爬取结果来看,存在不正当竞争类、侵犯著作权类、侵犯人格权类等问题。”
《财经》E法在裁判文书网检索到54份与爬虫相关的刑事判决,涉及多项罪名。其中,被认定为侵犯公民个人信息罪的有26份;非法获取计算机信息系统罪10份;传播淫秽物品牟利罪5份;破坏计算机信息系统罪3份;提供侵入、非法控制计算机程序、工具罪3份;侵犯知识产权罪3份;非法侵入计算机信息系统罪、开设赌场罪、盗窃罪、诈骗罪各1份。
本文来自微信公众号:财经E法(ID:CAIJINGELAW),作者:殷继,编辑:朱弢

 10:27
10:27









 04:29
04:29
 07:22
07:22
 05:03
05:03
 21:24
21:24
 14:30
14:30
 02:41
02:41
 05:38
05:38
 05:30
05:30
 06:48
06:48


