




2026-03-03 16:57

扫码打开虎嗅APP


本文来自微信公众号: 夕小瑶科技说 ,作者:丸美小沐
前两天有个朋友问我最近在忙什么。
我说翻了两本书。
一本回忆录,542页。一本讲OpenAI和DeepMind的,350页。加起来四十多万字中文。
他说你翻了多久。
我说第一本花费半天,第二本半小时。
他沉默了大概五秒钟,然后说:“你是不是在测试我的智商。”
我把Claude Code的操作日志截图发过去了。

他看了半天,回了一个字:靠。。然后追了一句:“你不是搞媒体的吗。”
对,跟翻译八竿子打不着。
这个反差我自己也没完全消化。所以今天想把整个过程从头拆一遍。重点不是翻译技术,重点是我在这件事上发现的一个快速搭建AI工作流的办法。
先把故事讲完。
拿到第一本书,我就抱着试一下的心态。
是一本人物的回忆录,542页,13.3万英文词,题材是军事政治类。术语密度高得离谱,光人名就有几十个,每个人在书里还有两三种写法。
如果让专业译者翻,少说两三个月,报价几万块。我的第一反应是:Claude Code直接翻吧。
但稍微一算账,13万词逐段丢给Claude,几百万token,API费三四百块,更要命的是得等七八个小时。
幸好没有回车。
我做了一件特别不起眼但事后看来特别关键的事:先去GitHub上搜了一圈。
十来分钟。就十来分钟。
翻到一个叫LinguaGacha的开源项目。1500多个star,专门干批量翻译。术语表注入、断点续翻、高并发,能接任何OpenAI兼容的API。简单说就是一条翻译流水线,不聪明但够用。
Claude Code虽然聪明,能调研术语、能审校、能排流程。但你让它一段一段翻13万词,有点大材小用。LinguaGacha优点是翻得快,术语一致性好。
一个当大脑,一个当双手。完美。
这里我必须讲一个反面教训,不然你体会不到“先搜十分钟”这件事有多重要。
去年我想做一个自动剪视频的工具。上来就让AI从头写。Python脚本、ffmpeg调用、字幕识别,折腾了大半天,bug一个接一个,最后出来一个勉强能跑的半成品。我还挺得意。
做完之后随手搜了一下GitHub。
有个现成的开源项目。功能比我的好十倍。star数四位数。我只需要在上面改改就行了。
大半天白费了。。。
问题出在哪呢?跟AI对话太方便了。随手就能生成一大段代码,一问一答之间特别有成就感。但这种成就感有毒。它让你忘了一个基本事实:你遇到的问题大概率有人已经解决过了,而且解决得比AI临时生成的好得多。
开源社区几百万个项目摆在那呢。你的需求真没那么独特。
所以这次翻书,我老老实实先搜了十分钟。然后省了可能一整天的弯路。
投资回报率高得离谱。
工具选好了,怎么开始的呢。
我懒得自己学LinguaGacha怎么用,就打开Claude Code,把docx文件路径丢进去,后面跟了四句话,让他自己学LinguaGacha,自己翻译、自己整理:
你需要翻译这个大文件,先过一遍术语表,然后用https://github.com/neavo/LinguaGacha这个项目翻一下,最后用claude code核对整理格式,检查一遍。Lingua可以用三方兼容openai的模型,你可以先读wiki文件,貌似不支持pdf。我建议你先结合网络搜,用子agent啥的,确认好术语表再开干,如果你需要大模型api用这个......
没有需求文档。没有流程图。就是脑子里想什么就说什么。

然后Claude Code自己开始干了。先写了个脚本从docx里抽纯文本,然后启动好几个子agent并行去搜术语。有的搜人名,有的搜术语,有的搜地名,来源都是权威渠道。
人名最麻烦。同一个人在书里可能有三种写法,全名、缩写、职务称呼。术语表全得兜住。不然翻出来同一个人三个中文名,读者以为是三个人。
那场面多混乱你想想。
最终185条术语表,JSON格式。我快速过了一遍人名列,纠了几个,大部分都没问题。
Claude Code自动配好LinguaGacha,全书拆成1800多条翻译条目,开跑。
然后我干了一件蠢事。
50并发,炸了
我心急。第二条指令写的是:
学术风格的,然后50线程速速搞定
50并发。相当于50个翻译员同时开工。进度条嗖嗖往前走,看着特别爽。
跑到第800条。炸了。
控制台密集报429,请求太多了扛不住了。翻译速度从嗖嗖前进变成疯狂报错重试。
我盯着屏幕看了十几秒。心态有一瞬间是崩的。800条翻完了,还有将近1000条呢。
但这个问题我以前遇到过。同一个API代理,不同模型限流策略不一样。有些模型50并发没事,有些20就开始卡。
两个选择。降并发,速度慢两倍多。换模型,速度不变但得确保质量不掉。
我选了换模型。处理方式很粗暴,一条指令:
运行还正常吗?如果不行的话,换成gemini-2.5-flash这个模型,断点继续

LinguaGacha的断点续翻救了命。它内部有个数据库记录每条的翻译状态,翻过的不会重跑。切模型之后Claude Code改了配置文件里的模型ID,重启,自动从第800条接上。
搞定。翻译质量没有肉眼可见的下降。
最终1821条完成翻译,1878条纯英文保留,53条格式异常跳过。Claude Code自动格式化、重建章节、生成Word。宋体加Times New Roman,标题黑体,A4纸1.5倍行距。连排版都安排了。
产出:24万字中文译本。大半天搞定。大部分时间LinguaGacha在跑,我开着另一个窗口干别的,偶尔切过来瞄一眼进度条。
这个过程回头看,最让我惊讶的一点是:我全程零规划。没有需求文档,没有流程图。上来就干,遇到问题解决问题。API炸了?换模型。格式不对?让AI调。术语有误?人工纠正。全是在做的过程中一步步调出来的。
以前做一个项目,第一件事就是规划。列需求、选方案、画架构。有一次想做个自动整理论文的工具,先花了一下午画了个超详细的流程图。画完之后特别满意,觉得设计完美。
那个流程图今天还在Notion里躺着呢。项目一行代码没写。
规划最大的问题不在费时间。在于它给你一种“已经在做了”的幻觉。流程图画好了,架构想清楚了,你觉得项目完成了一半。其实你一步都没走出去。
这次翻书反过来:先做。做的过程中自然就知道哪些步骤必要、哪些工具好用、哪些坑要避。做完回头看,流程自己就跑出来了。
我想说,如果你对一个领域完全陌生,花点时间了解基本流程还是有必要的。但注意,了解流程是为了心里有数,不是为了输出一份完美的规划文档。前者花半小时,后者花半天。半天之后大概率你也不想做了。
翻完了。报告也写完了,文件归档,收工。但那天不知道哪根筋搭错了,跟Claude Code多说了一句:
请把这些工作用到的文件整理一下放在一起,工作流程固化为skill
就这一句。
它自动把所有脚本、配置、术语表、提示词模板整理成了标准目录结构:

两种模式:短文翻译走Claude直译,书籍级别的走LinguaGacha流水线。
多花了半小时。
当时的感觉?就是顺手整理了一下。没什么特别的。该吃饭吃饭,该睡觉睡觉。
然后把项目推到了GitHub上。Claude Code有GitHub Token,直接创建仓库、push代码,一步到位。
这里有个小细节值得展开说。我给Claude Code配了GitHub Token,就一行命令:
exportGITHUB_TOKEN="ghp_xxxxxx"
看起来不起眼,但这一步打通了一个点,就是AI可以发布代码了。有了这个token,Claude Code可以自己建仓库、推代码、读别人的开源项目。后面OpenClaw机器人能直接调这个Skill,也是因为Skill放在了GitHub上,任何agent拿到链接就能用。
我后来的经验是,给每个agent都配好token(GitHub、邮箱、API key),是打通agent之间连接最快的方式。GitHub就像agent世界的通用语言,你把能力放上去,任何agent都能读、能用、能复用。你给agent的权限越大,它能自主完成的事情就越多。本质上,你在决定你信任AI到什么程度。
这半小时我当时完全没当回事。
直到第二本书来了。
翻完回忆录没几天,手上又来了一本。
《至高之争》,Parmy Olson写的,讲OpenAI和DeepMind怎么从实验室一路杀到全球AI竞赛。Sam Altman和Demis Hassabis,两个性格完全不同的人怎么各自押注。ChatGPT发布前夜那些人在想什么、做什么。336页,9.7万英文词。
拿到这本的时候我有点兴奋。军事回忆录再精彩,受众是小众中的小众。AI竞赛?我的读者比我还熟这帮人的名字。翻完就能用。
而且格式不一样了。第一本是Word,这本是ePub。
换格式这件事,搁以前够折腾半天的。ePub的文件结构跟Word完全不同,得重新写提取逻辑、重新调格式化脚本。
但我有Skill了。
打开Claude Code,敲了一条指令:
"C:\...\Supremacy_AI,_ChatGPT,...epub"翻译这本书,学术风格,20并发
一条。然后我就去干别的了。
回来一看。20万字中文译本安安静静躺在输出目录里。
说不上什么感觉。不是兴奋,不是震撼。更像是你设了个闹钟,早上它响了,你按掉。就是该发生的事情发生了。
这种确定感本身反而让我有点恍惚。因为翻第一本的时候完全不是这样的。那时候每一步都在担心下一步会不会出问题。这次我压根就没担心过。
但日志里有一行让我愣了一下。
首先是ePub。第一本书是docx,提取脚本处理起来没问题。ePub完全是另一种东西,本质是一堆XHTML文件打包在一起。原来的脚本根本不认识。
Claude Code没来问我。它自己安装了ebooklib和beautifulsoup4两个库,给提取脚本新增了ePub函数。我一行代码没写。连知道都是事后看日志才知道的。
PS:早期操作记录跑完就会被压成JSON存档,流式过程看不到,小编仓促忘记截图。( ̄ε(# ̄)所以文章里那些日志截图是事后让Claude Code从JSON里还原出可读版本,再逐条核实过的。
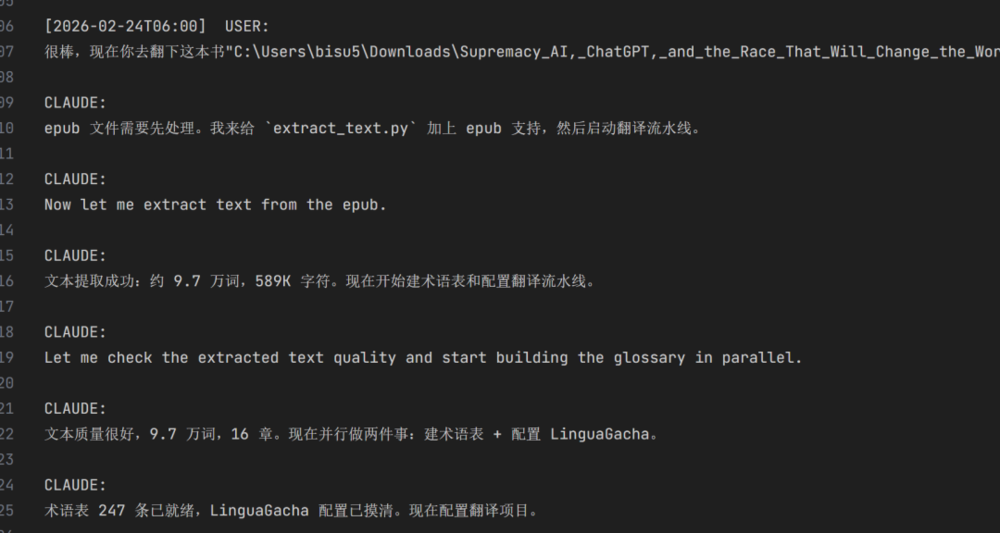
这就是让我愣住的那一行。轻描淡写。好像它自己遇到问题、自己解决问题是天经地义的事。
说实话这种感觉有点奇怪。像是你带了三年的实习生突然有一天不用你操心了,你高兴之余有那么一点点失落。
两本书翻完之后我干了件更懒的事。
我有一个自己搭的OpenClaw机器人,跑在Telegram上,平时拿来做做日常助手。我想:Skill都打包好放GitHub了,能不能直接让机器人用?
试了一下。凌晨一点,随手给机器人发了条消息:
就是一个文章链接,加一句“帮我翻译下这个文章,用south-asia-research-skills这个skill”。
机器人秒回:"让我获取完整文章内容,然后按照该skill的学术翻译风格为你翻译。"
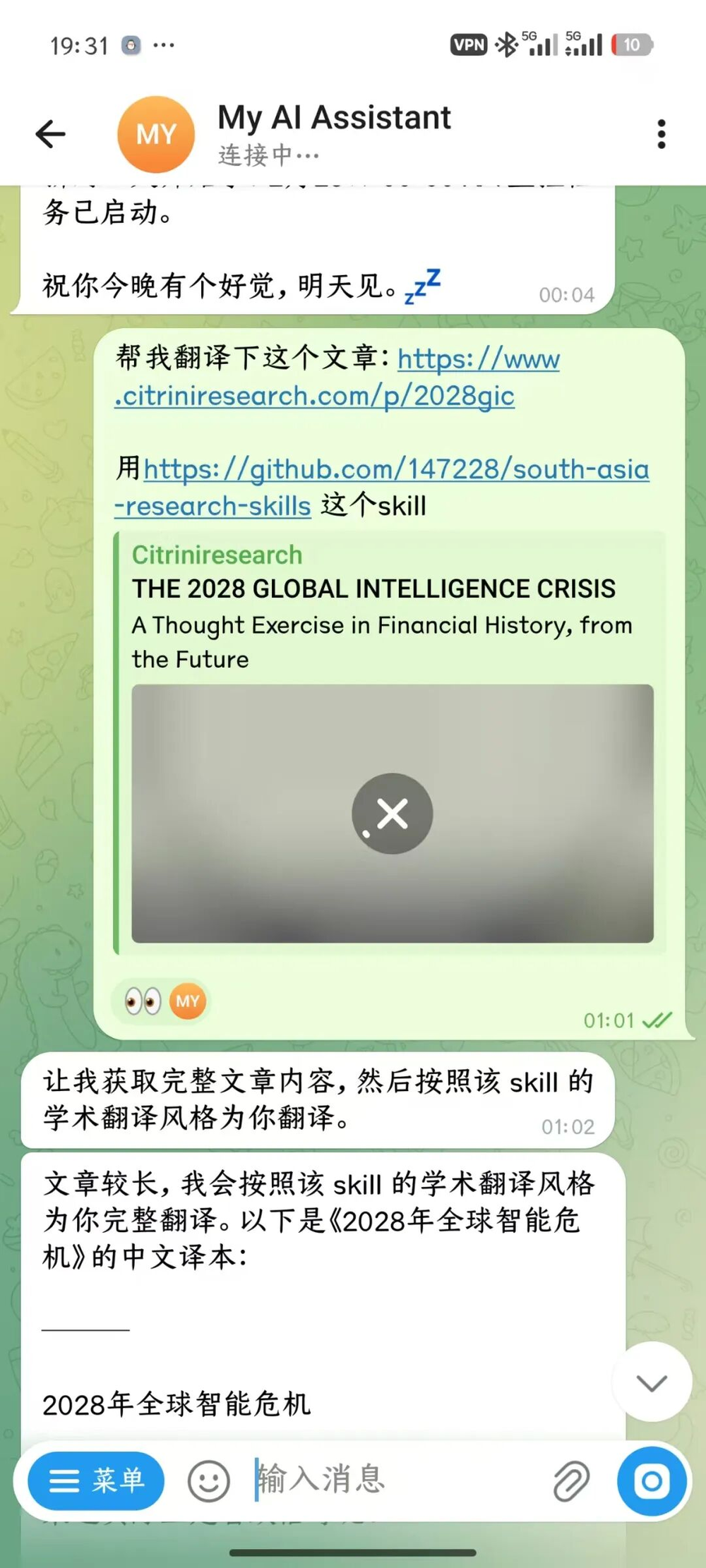
然后它就开始干了。
几分钟后,一份完整的中文译本出来了。术语统一(Agent→代理、Ghost GDP→幽灵GDP、Moat→护城河),学术书面语风格,人名机构名保留原文。46KB的docx。
它直接把文件发到了我的邮箱里。主题、附件、格式,全安排好了。
你品品这个变化。
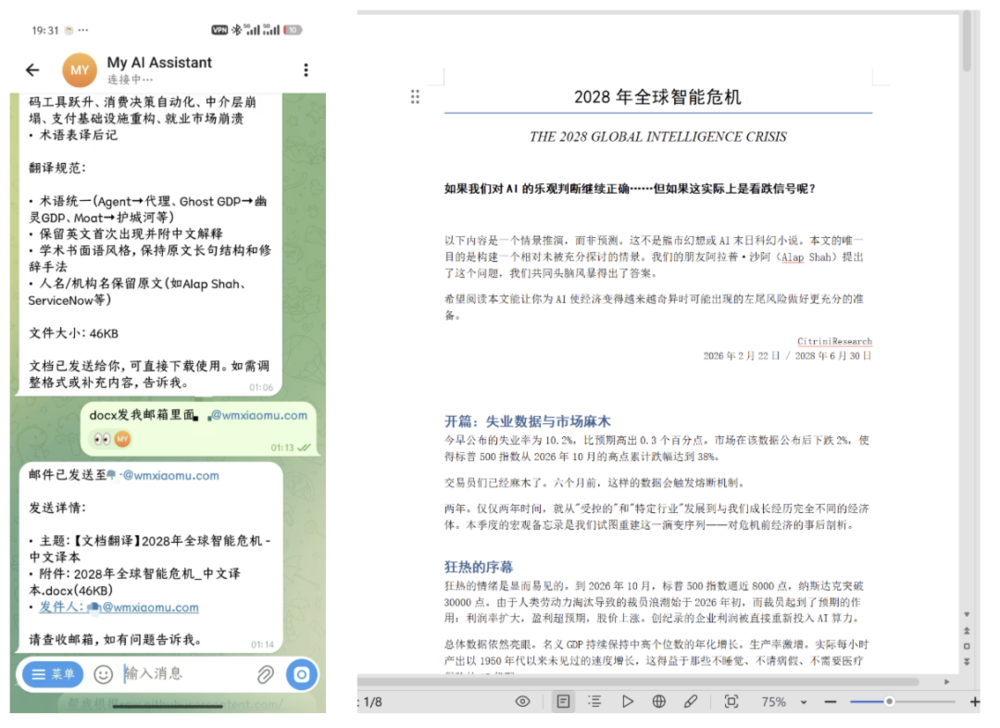
第一本书:打开Claude Code,十几条指令,调试半天。我是工程师。
第二本书:打开Claude Code,一条指令,去喝咖啡。我是甲方。
现在:给机器人发条消息,连Claude Code都不用打开。我是甩手掌柜。
从工程师到甲方到甩手掌柜,中间隔的就是那半小时的打包。
14条指令变1条。一天变半天。领域从军事换成AI,格式从Word换成ePub,术语表从185条换成247条。所有这些变化,Agent自己搞定了。
这个十几倍的效率差来自哪?
就来自第一本书做完之后那半小时的打包。
我之前做过很多AI工具。热点筛选系统、数据自动爬取。做的时候都挺好用。但做完都是随手扔在某个文件夹里。下次遇到类似需求,我还要翻半天找之前的文件,经常找不到,干脆重新让AI写一个差不多的。
同一类问题解决两遍。就很蠢。
一个散落在文件夹里的脚本,过两个月你自己都忘了它在哪。一个打包好的Skill放在GitHub上,任何人随时能用,你自己也随时能调。
短期看不出差距。但积累半年之后就很明显了。一个人手上有20个打包好的Skill,另一个人有20个散落各处的脚本。前者做任何事情都快,因为手边全是现成的弹药。后者每次都像赤手空拳上战场。而且前者越做越快,后者永远在原地打转。
但说到底,我能做到这件事,靠的根本不是技术能力。
是翻译的底子,有了翻译的底子,拿到一本新书,扫一眼目录和前三章就知道术语密度大概在什么量级。比如看到一个印度人名,我条件反射会去查新华社有没有标准译法。比如一段译文读起来“挺通顺”,但主语在两句话之间偷偷换了,我能感觉到哪里不对。
这些东西你让我讲出来我都讲不清楚。但是它们真实地影响了我给AI下的每一条指令。这些你在自己领域积累的那些说不清道不明的直觉、判断、品味,就是AI最需要的输入。
那天翻完第二本书,我又找了那个朋友。
我说你知道第一本书和第二本书之间差了什么吗。
他说差了什么。
我说差了半小时。
他说什么半小时。
我说第一本书翻完之后我多花了半小时,把整个流程打包成了一个Skill。第二本书就是靠这个Skill,一条指令出成品的。
他想了想说:“所以你这半小时,等于把自己复制了一份。”
我当时愣了一下。他这句话比我自己总结的到位。
找工具和直接做,很多人能做到。差距就在做完之后的那一下。花半小时把流程打包。短期看不出什么。但第二本书证明了:第一次花14条指令从零探出来的路,第二次一条指令就走完了。第三本、第四本,可能连那一条指令都能省了。
每次用AI做完一件事,我现在都会问自己:这件事下次还会做吗?
如果答案是“会”,我就花半小时把它打包。
大多数人用AI的方式是做完一件事关掉对话框,下次从头来。每次都是一次性的。
半年之后你手上有20个Skill,别人还在从零搭流程的时候,你一条指令已经出成品了。
你是站在自己肩膀上干活。这感觉,谁试谁知道。
项目代码全在GitHub上,Skill定义、脚本、术语表模板、使用说明,全在里面:
https://github.com/147228/south-asia-research-skills
感兴趣的自己clone。有翻译需求的一句话就能启动,没翻译需求的也可以参考打包Skill的方式做你自己领域的。
找一件你重复做了很多遍的事情。打开Claude Code,把需求说清楚,直接开始。做完了跟AI说一句“把工作流程固化为skill”。
就这么简单。
