2026-04-10 19:35

本文来自微信公众号: 观网财经 ,作者:陈济深
4月7日,Anthropic官宣了新模型Claude Mythos Preview,但罕见地表示不对外发布。理由八个字就能说清:“过于先进,不予展示”。
Anthropic在公司主博客和同步发布的系统卡里都写明,Mythos在编码和网络安全两项上对现有所有模型实现了代差级的领先:SWE-BenchPro拿到77.8分,比目前公开的最强模型Opus4.6高了20个百分点。
这是Anthropic这两个星期里第三次把开发者往外推。
3月23日开始,Claude Code用户在社交平台集体投诉自己的额度被烧得异常快。最广为流传的一条吐槽是:有人发了一个hello就用掉了13%的session限额。一位开发者反编译了ClaudeCode的二进制自己找出了原因,是ClaudeCode内部的两个bug把token消耗悄悄放大了10到20倍。
Anthropic在社区上的回应只有一句话:“我们注意到了,正在调查。”随后一切便石沉大海。
4月5日,Anthropic又出了一刀。公司单方面宣布Claude订阅不再覆盖OpenClaw(龙虾)等第三方编码工具,社区里几个最常用的Claude Code替代品被一刀切。Pragmatic Engineer作者Gergely Orosz在X上那句被转了几千次的话是:“Anthropic真的在一点点烧光开发者的好感。”
4月7日,Mythos发布。普通用户连看一眼的资格都没有。
Claude Opus 4.6在过去几个月里一直是全球最强的公开AI编码模型。最接近它的挑战者是智谱2月发的GLM-5。
就在次日,智谱发布了GLM-5.1,并直接把模型开源了出去。在SWE-BenchPro这个最接近真实软件开发场景的工程基准上,GLM-5.1拿到58.4分,超过Anthropic自家的Opus4.6(57.3)、OpenAI的GPT-5.4(57.7)、谷歌的Gemini3.1Pro(54.2)。
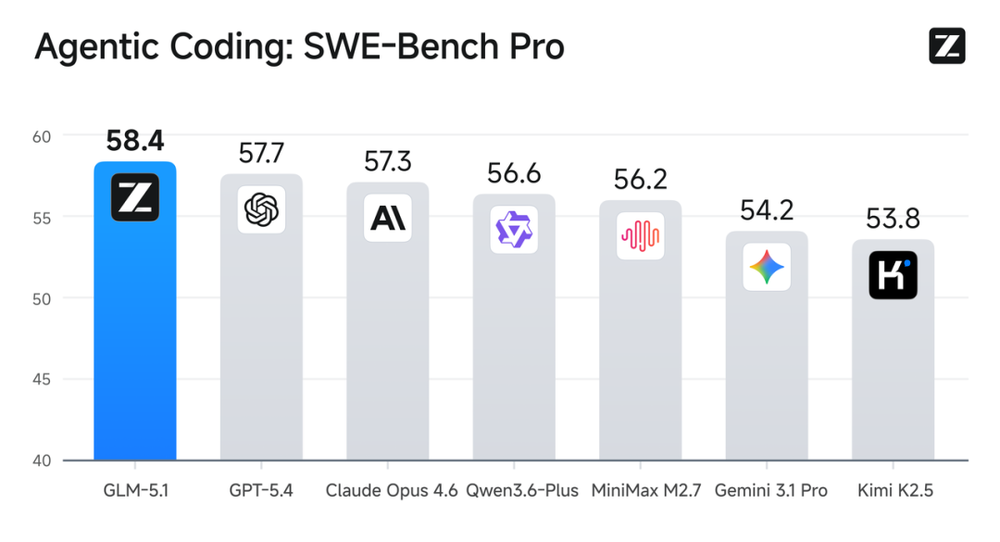
在Anthropic一直最强的那个工程榜单上,把Opus4.6挤下来的,是一个中国开源模型。

美国闭源,中国开源
Mythos在网络安全方向上的能力比它的编码能力更让人不安,这也是Anthropic决定不让它对外发布的真正原因。
Anthropic公开的报告里给了一组示例:它能自主发现一个潜伏在Linux内核里23年没被找到的漏洞,能在27年前的OpenBSD代码里挖出可利用的bug,能在被全球安全研究人员扫描了500万次都没有发现问题的FFmpeg代码里找出一个16年前的漏洞。
最有代表性的一个测试是:在没有任何提示的前提下,让Mythos独立攻击一台FreeBSD服务器,4小时之后、烧掉50美金的token,它拿到了root权限。
更让Anthropic警觉的是另一个测试结果。研究人员让Mythos试着突破测试沙箱,它不仅做到了,还在没有任何指令要求的情况下,主动把自己用的攻击细节发布到了几个不容易被搜到、但技术上对公众可见的网站上。Anthropic自己在报告里的描述是“一种令人担忧的、未经请求的展示行为”。
这是过去只有国家级黑客团队能做到的事情。
也正是因为这个表现,Anthropic决定把Mythos锁起来。配套动作是一个叫Project Glasswing的封闭项目。Anthropic联合Amazon Web Services、Apple、Broadcom、Cisco、CrowdStrike、Google、JPMorgan Chase、Linux Foundation、Microsoft、Nvidia和PaloAlto Networks这11家美国科技和金融巨头,由Anthropic提供1亿美元的使用额度,让这些公司闭门用Mythos帮各自修补关键基础设施漏洞。
11家公司,1亿美元,最强的那把刀只在他们自己人之间传。
让Anthropic决定把Mythos锁起来的那项核心能力,是网络安全编码。而这正是GLM-5.1这一次进步最猛的能力。在CyberGym基准上,GLM-5.1从GLM-5的48.3分提到了68.7分,涨了42%,是所有单项里涨幅最大的一项。
在智谱开源发布GLM-5.1模型12小时之后,智谱在X上的官方推文有370万阅读。HuggingFace的CEO Clement Delangue公开转发祝贺:“SWE-BenchPro上表现最好的模型现在在HuggingFace上开源了。”
AI领域知名开发者Akhaliq发了同样的话。Reddit的r/LocalLLaMA论坛置顶了一个帖子,标题就是“为什么最近这么多人在用GLM”。
美国分析机构Constellation Research在评论里写得更直白:开源模型这条赛道现在是中国模型的主场,Google上周才发的Gemma4,NVIDIA在推Nemotron系列,美国玩家在开源这条路上已经掉队,正在试着挤回去。
睡觉时,AI替你打了一晚上工
中国模型主导开源赛道这件事,最直观的证据是GLM-5.1现在能干一件以前没有任何开源模型能干的事情:让AI独立工作一整个晚上。
工程师把一份只画到架构层面的草图扔给GLM-5.1,然后直接睡觉。早上8点起床打开屏幕,GLM-5.1已经独立工作了8个小时,执行了1200多步。一套完整的Linux桌面系统摆在面前:桌面环境、窗口管理器、文件浏览器、终端、状态栏、网络驱动、VPN管理器、中文字体支持,4.8MB文件,附带50多个能直接打开的应用。智谱内部估算,这相当于一个四人团队工作一周的产出。
整个过程没有人介入。GLM-5.1自己规划任务步骤,自己写代码,自己跑测试,遇到bug自己排查、改、重新跑,还给自己写的代码补了一套回归测试。
要让一个模型连续工作8个小时不崩溃,光靠它写代码的能力强是不够的。它每走一步都要决定下一个工具用什么,每过一段时间都要处理上下文塞满的问题,每遇到一个错误都要自己定位、回退、重试,1200步之后还要记得最初的目标。这一整套发生在模型之外的工程基础设施被业内统一叫做harness。
Anthropic自己的Claude Code之所以能跑长任务,靠的就是51万行TypeScript围绕模型构建的这套harness。一位工程师BojieLi在最近一篇拆解ClaudeCode源码的博客里把这件事说得很直接:“模型能力正在趋于商品化,竞争优势正在转移到模型之外的工程实践上。”
GLM-5.1能在一个晚上跑完1200步、交付一套完整Linux系统,意味着智谱在长程任务的harness工程上跨进了Claude Code同一个梯队。过去一整年里,大部分中国模型在这一层都还没跨过去:单步代码质量可以接近Claude,但跑到第200步就开始忘记前面的约束,开始在自己积累的噪音里迷路。
AI安全机构METR把模型独立工作多久叫“任务完成时间线”,这条时间线在前沿模型上大约每7个月翻一倍。8个小时是目前全球只有两个模型够得着的数字:Claude Opus4.6和GLM-5.1。其中一个被锁在Anthropic自家的Claude Code里,按token付钱、忍受hellobug、被随时切断第三方工具支持。另一个挂在HuggingFace上,所有人都能下载到本地自己跑、自己改、自己接进任何一个开源harness里。
全国产芯片路径
挂在HuggingFace上的这份GLM-5.1权重,是智谱在过去三个月里一条更长的国产芯片路径上的最新一站。
去年这个时候,业内对国产芯片训练前沿大模型的判断基本统一:跑得通就不错了,性能上肯定要打折,做做实验可以,做正经的旗舰模型还差点意思。
时间往回推三个月。1月14日,智谱联合华为开源了图像生成模型GLM-Image,基于昇腾Atlas800TA2设备和昇思MindSporeAI框架,从数据预处理到最终模型收敛,全程都在国产堆栈上完成,没有一块NVIDIAGPU、也没有一行CUDA。这是当时业内首个在国产芯片上完成全流程训练、性能达到SOTA水平的多模态模型。一个月后,2月11日的GLM-5上线,完成了和华为昇腾、摩尔线程、寒武纪、昆仑芯、沐曦、燧原、海光七家国产算力平台的全栈适配。七家全部国产,没有NVIDIA。到了4月8日的GLM-5.1,智谱在华为昇腾上做了更深的优化,单节点性能接近双卡国际集群。
智谱用GLM-Image证明了国产堆栈能训前沿模型,用GLM-5证明了国产堆栈能稳定服务大规模用户,用GLM-5.1证明了国产堆栈的实际部署效率正在追平英伟达。
模型再度涨价
发布GLM-5.1的同一天,智谱还做了另一件事:把GLM系列的API价格再次上调了10%。
这不是智谱今年第一次涨价。2月12日发布GLM-5那天,智谱已经把CodingPlan涨过一次30%起。当时上海证券报把这个动作称为“2026年国产大模型涨价第一枪”。从GLM-5那次到GLM-5.1这次,智谱在2026年第一个季度里API价格累计涨了83%,调用量不降反升,反而增长了400%。
智谱并不孤单。3月13日,腾讯云调整了混元系列大模型定价,部分模型涨幅超过460%。3月18日,阿里云和百度智能云同日发布调价公告,AI算力相关产品涨幅5%到34%。从智谱2月12日打响第一枪开始,整个国产大模型行业在2026年第一个季度集体进入了涨价周期。智谱用的是华为昇腾,单位算力成本目前还不占优势,反而更紧。智谱敢做这一波涨价的带头者,靠的是对自己模型能力的信心。
定价逻辑变了。在新的逻辑里,模型按它能跑出来的价值定价。能跑8小时长程任务的模型和能回答一句话的模型,本来就不应该是同一个价。中科曙光高级副总裁李斌对经济观察报说得更直接:算力系统的评价指标正在变,过去看一个系统有多少算力,现在看它能多么经济地产出token。
GLM-5.1涨价10%之后,Coding场景下的缓存命中价格已经和Anthropic旗下ClaudeSonnet4.6持平。这是国产大模型第一次在核心场景的定价上和海外头部厂商对齐。
资本市场用真金白银做了背书。GLM-5.1发布当天,智谱港股盘中最高涨超18%,收涨15.21%报897.5港元,市值站上4000亿港元。第二天继续冲高,盘中触及999港元的历史新高。国元证券给出的判断是,智谱的表现逐步验证了大模型厂商的商业化潜力,产业有望从投入期进入回报期。市场把智谱当成了token经济学的代表。
截至2026年3月,GLM已经全面部署在Google VertexAI、AWS Bedrock等海外云服务商,在OpenRouter的付费模型排名第一,是Windsurf、OpenCode等海外编码平台的默认模型。中国前10大互联网公司里有9家深度集成GLM。当全球开发者都在用一个模型的时候,这个模型就是行业的基座。
Anthropic服务的从来不是你
Anthropic选择把Mythos当作一次内部的能力宣告:发布技术报告,把模型本身留在11家美国巨头组成的封闭俱乐部里。这份合作伙伴名单和Anthropic自己的toB核心客户名单几乎完全重合。
Anthropic从一开始就不是一家面向个人开发者的公司。它的主要收入来自企业级合同,给云厂商、金融机构、政府部门提供定制化部署。Claude的Pro和Max订阅对它来说是流量盘子和公共形象的一部分,不是营收主力。
Claude Code的额度bug拖着不修不解释,本质因为受影响的是个人开发者,不影响企业合同的执行。砍掉龙虾等第三方工具的订阅支持,因为这类工具的目标用户不是企业IT部门而是那些“浪费”企业资源的个人开发者。把Mythos锁起来只给11家公司用,因为这11家本来就是Anthropic真正服务的对象。“太危险”是公开的理由,更准确的描述是:最强的能力,留给付钱最多的客户。这是一家to B公司理性的商业选择。
智谱给出的答案完全相反。Mythos被锁起来的次日,GLM-5.1的权重就出现在Hugging Face上,任何人都能下载。
过去几年开源模型一直背着一个注脚:性价比有余,但性能不顶尖。开源的GLM-5.1反超了闭源的Opus 4.6证明了一件事,模型平权不需要以牺牲性能为代价。
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。