2026-04-12 18:07

速览
本文来自微信公众号: 歪睿老哥 ,作者:歪睿老哥
TechInsights对华为Mate 80 Pro Max搭载的麒麟9030芯片进行了拆解分析。
研究结果明确指出两点
1.中芯N+3工艺的晶体管密度(102MTr/mm²),确实不如三星和台积电之前的5nm,不到125MTr/mm²
2.已经在用DUV多重曝光硬缩最小金属间距了,已经超过了双重曝光的极限,现在用的大概率是自对准四重曝光(SAQP)
麒麟9030到底是啥工艺做出来的?
中芯靠DUV多重曝光,到底能摸到什么水平,未来怎么冲300MTr/mm²的密度(对标台积电的2nm工艺)?
1.先给核心结论:没EUV也能冲,技术路径已经摆明白了
先给不懂参数的兄弟翻译下,300MTr/mm²是什么概念?
就是一平方毫米硅片塞3亿个晶体管。
现在台积电3nm大概也就这水平(267Tr/mm²),最先进的2nm能到3亿以上。
今天这篇核心就是聊:
靠这套DUV多重曝光的路线,没有EUV只靠DUV的情况下,能否摸到300MTr/mm²以上。
先给个结论:完全是可行的,而且路径已经规划好了。
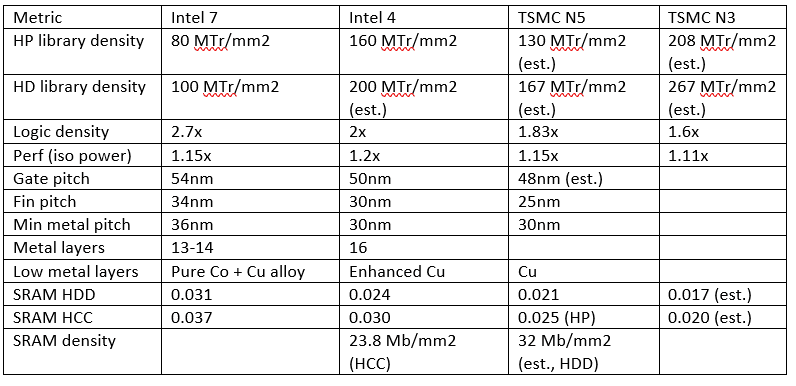
N+2到300MTr/mm²密度工艺缩距路径表
晶体管密度公式:由栅极节距与走线节距(本文取M2)计算;
N+3的走线金属并非最小节距金属。
公式权重:60%为覆盖3个栅极节距的4晶体管NAND单元,40%为覆盖19个栅极节距的32晶体管触发器,最终密度公式为:1.474/(栅极节距×单元高度)。
2nm节点:将切换至埋入式电源轨(BPR),单元高度从6走线降至5走线。
节距匹配:老节点M1节距可小于栅极节距(如2/3栅极节距);但EUV在36 nm节距下存在随机缺陷密度问题,因此M1节距预计放宽至与栅极节距一致。
300 MTr/mm²条件:需44 nm栅极节距、22 nm金属节距,并搭配埋入式电源轨以实现5走线单元。
2.两种技术路线
要把最小金属间距缩到30nm以内,靠DUV不是想缩就能缩的,现在业内已经提了两种成熟方案,都是国内厂商的专利,咱们一个个说。
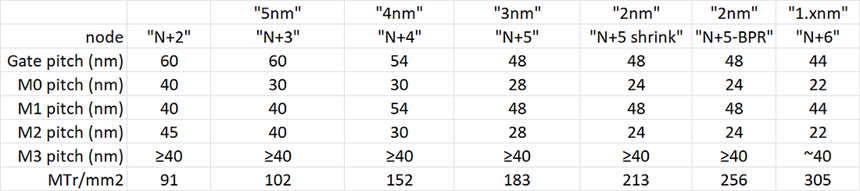
第一种:Double SALELE,八块掩模硬出
先翻译术语,SALELE就是「自对准光刻-刻蚀-光刻-刻蚀」,比传统的双重曝光更精准,Double SALELE就是做两次,直接出四重曝光的效果。

Double SALELE工艺步骤示意图
流程其实不难懂:
1.第一次光刻刻蚀出第一组线,做侧墙隔离,然后用第二块掩模切出需要的间隙
2.第三块掩模利用侧墙对位,刻出第二组线,第四块掩模切间隙——这是第一轮SALELE
3.再来一轮一模一样的流程,就得到了四倍密度的线
但这个方案有个最大的问题:太费掩模了。光做线就要4块掩模,切间隙还要再加4块,总共要8块掩模,成本直接拉满,不是最优解。
第二种:Double SADP,只要4块掩模,砍半成本
这个方案其实就是级联两次自对准双重曝光(SADP),同样出四重曝光的效果,但是掩模直接砍了一半。
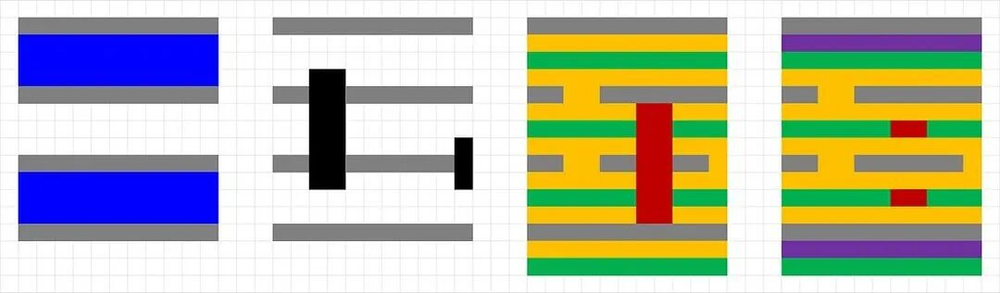
Double SADP工艺步骤示意图
流程更简单:
1.芯轴上做第一层侧墙,切间隙后完成第一次SADP,得到第一组金属线
2.再在第一层侧墙的侧壁上做第二层侧墙,填充间隙之后切间隙,间隙就成了第二组金属线
3.宽线最后用第四块掩模单独做就完了
好处就是SADP一次就能把线密度翻一倍,切间隙也能一次切两根,所以总掩模数从Double SALELE的8块降到了4块,成本直接降一半,明显更划算。
3.必须上对角线FSAV网格,不然通孔根本做不出来
金属间距缩到30nm以下之后,下一个问题就来了:通孔(就是连接不同层金属的小洞)怎么做?
我给你算个数:就算是High-NA EUV,瑞利分辨率极限也就15nm,金属线宽都到15nm以下了,直接打通孔?
先不说分辨率,随机缺陷(就是曝光光子不够,该曝光的没曝光)就能把良率干没了。
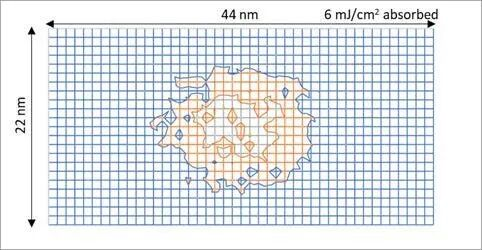
22nm×11nm通孔光子密度示意图
最小通孔间距本来就不能做到跟金属线间距一样小,而且布线也不需要那么密,所以对角线通孔网格+全自对准通孔工艺就成了必须的选项。

传统网格vs对角线通孔网格对比图
那需要多少块掩模呢?
如果用ArF浸没式DUV硬来,最多要4块,但用对角线网格加LELE双重曝光,最多再加一块修边掩模就够了,比硬怼省太多。

不同节点通孔多重曝光方案示意图
4.切金属线的掩模,也给你算明白了
除了通孔,切金属线(就是把不需要的金属线切断留出间隙)也很费掩模,这里给兄弟们算清楚:
如果用Double SADP做M0和M2层,只要2块切掩模就够
如果用Double SALELE,最先进的1.xnm节点最多要4块
如果是SALELE做M1和M3层,最多也是4块

Double SALELE金属层切掩模数量示意图

SALELE金属层(M1/M3)切掩模数量示意图
有意思的是,就算用DUV四重曝光,成本也比EUV双重曝光更低,这就是走DUV多重路线的核心优势之一。
5.最终算帐:路径选对了,掩模数量根本不会炸
最后把M0到M3所有层的掩模加起来算总帐,结果很有意思:
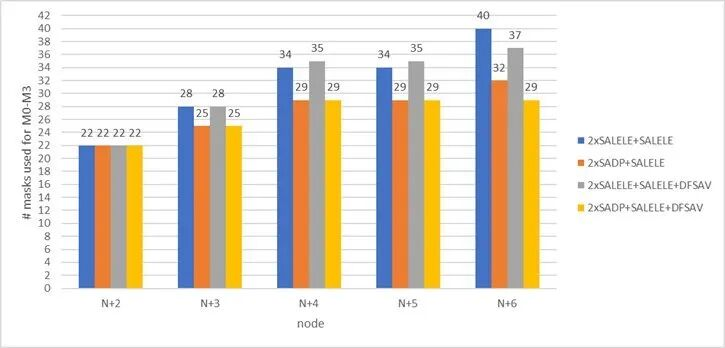
不同工艺方案各节点总掩模数量对比图
统计M0~M3层在不同方案下的掩模增量,结果如图8:
双重SALELE方案掩模数量始终高于双重SADP方案;
N+6节点(M1节距44 nm、M0/M2节距22 nm)采用FSAV对角双重曝光+修整掩模,可节省3块掩模;
最佳情况
N+2→N+4仅增7块掩模,直至N+6总量不变;
最差情况
N+5后掩模持续增加,N+6高达18块;
N+5可视为N+4的直接缩微版,不增加掩模。
几个核心结论:
1.Double SALELE全程都比Double SADP费更多掩模,Double SADP更优
2.对角线网格加LELE双重曝光,N+6节点能省3块掩模,最优方案下N+2到N+4只加7块掩模,总数量到N+6都不涨
3.最差方案硬怼的话,N+6要涨到18块掩模,成本直接上天
4.N+5其实就是N+4缩一缩,根本不需要加掩模,过渡非常顺滑
所以说白了:只要提前规划好几代节点的路线,掩模数量完全可控,成本也能扛得住。
6.最后总结
很多人都觉得没EUV就做不出先进工艺,这次拆解给所有人证明了:
靠DUV多重曝光+合理的技术规划,照样能摸到最先进节点的密度水平,路径走通了,接下来就是一步步落地的事。
对咱们普通人来说,不用纠结什么时候能量产。
你得知道:中国芯片行业不是只有「搞EUV」这一条路,这种另辟蹊径、在现有条件下啃出一条路线的思路,才是最值钱的。
参考文献:https://semiwiki.com/semiconductor-services/techinsights/365118-forwarded-this-email-subscribe-here-for-more-kirin-9030-hints-at-smics-possible-paths-toward-300-mtr-mm2-without-euv/
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。