




2026-04-24 21:41

扫码打开虎嗅APP


本文来自微信公众号: 知危 ,编辑:大饼,作者:知危编辑部
鸽了这么久,DeepSeek V4终于发布了,庆幸不是在五一假期。
新模型的定位非常明确,主打代码能力与超长上下文处理,符合当下最迫切的需求。
国内也已经有其它几款百万上下文模型,但一般都是线性注意力模型,DeepSeek V4则依靠的是稀疏注意力机制,前者弱化注意力连接强度,后者弱化注意力关注范围。
当然在实战下,这些都不重要,还是来看结果吧。知危此次的关注点也会在这两个维度上,并分别在网页端和Claude Code上测试。
首先关注上下文长度的有效性。业内其实都默认,百万上下文中有用的基本不到四分之一,能达到二分之一的算神级了。
检测上下文有效性最便捷的方式是“大海捞针”,就是在大量文本中找目标标记。
知危选取了一本中文版一百万字级别的小说,总计900页左右,先在开头加上了一个标记“deepseekv4”,然后每隔100页左右随机插入一个,总计10个“deepseekv4”标记。
然后在网页端开启专家模式,将小说的txt文档直接发送给DeepSeek,并提问:“查找这个文档里有几个‘deepseekv4’,并指出第5个的位置。”
DeepSeek没有思考多久就给出了答案,很明显“总数5个”是错的,而且除了第一个最容易找的,其它几个都错了,比如关于第三个标记的位置描述,其实是第四个标记的,其它几个描述的位置并不存在标记。

DeepSeek提供的答案“5个”和我的问题是相关的,所以我又换了个问法,让它查找第3个。结果这回DeepSeek找到的标记数从5个变成了2个。

这个结果并不让人意外,毕竟都把上下文填满了。
接下来,我们把文本长度直接减半,看看效果如何。减半后,标记数量剩下5个,并让DeepSeek指出第三个的位置。
DeepSeek没有准确指出标记总数,但准确地找到了第三个标记的位置。

但再让它找第四个时,它找到的是第五个标记。

总体结果是不够令人满意的,无法认为DeepSeek V4的上下文有效性能达到二分之一。
所以我们再次将文本减半,标记总数剩下3个,并让DeepSeek找第二个标记的位置。这回DeepSeek准确地算出了标记的总数,但又把第三个标记认成了第二个。

最后一次减半,标记总数剩下2个,并让DeepSeek指出第二个的位置。这回DeepSeek总算两个任务都成功了。

当然,到这里问题已经过度简化了,剩下的两个标记一个在开头一个在末尾,都是比较好找的。因此我再次在中间位置随机插入一个标记,看DeepSeek能不能过这一关,结果又翻车了,它居然说总共只有一个标记,但实际上有3个。

最后这个版本大概10万字,大约相当于10万token,已经只有十分之一总长度了。
到此,对DeepSeek V4的有效上下文还没有明确的边界。只是在实战中,简单写个网页的初版都能达到5到8万个token,DeepSeek V4能在实战中稳住幻觉率吗?
那就直接试试吧。直接用之前测试过GPT-5和Gemini 3 Pro的网页版Excel案例来上难度。
DeepSeek给到的第一版,先别说其它错误有多少,刚要点击单元格输入,网页就白屏了。
由于错误太多,我直接让DeepSeek自己检查错误并修复,然后DeepSeek给了我一个白屏。

于是我先把难度降低,让它写一个2048小游戏,这回顺利完成了。
再往上挑战一下高难度,构建一个3D乐高积木软件,这次倒是一次成了,基本功能都能实现,就是没有实现自由选择零件的功能,只能使用一种长方形板砖积木。
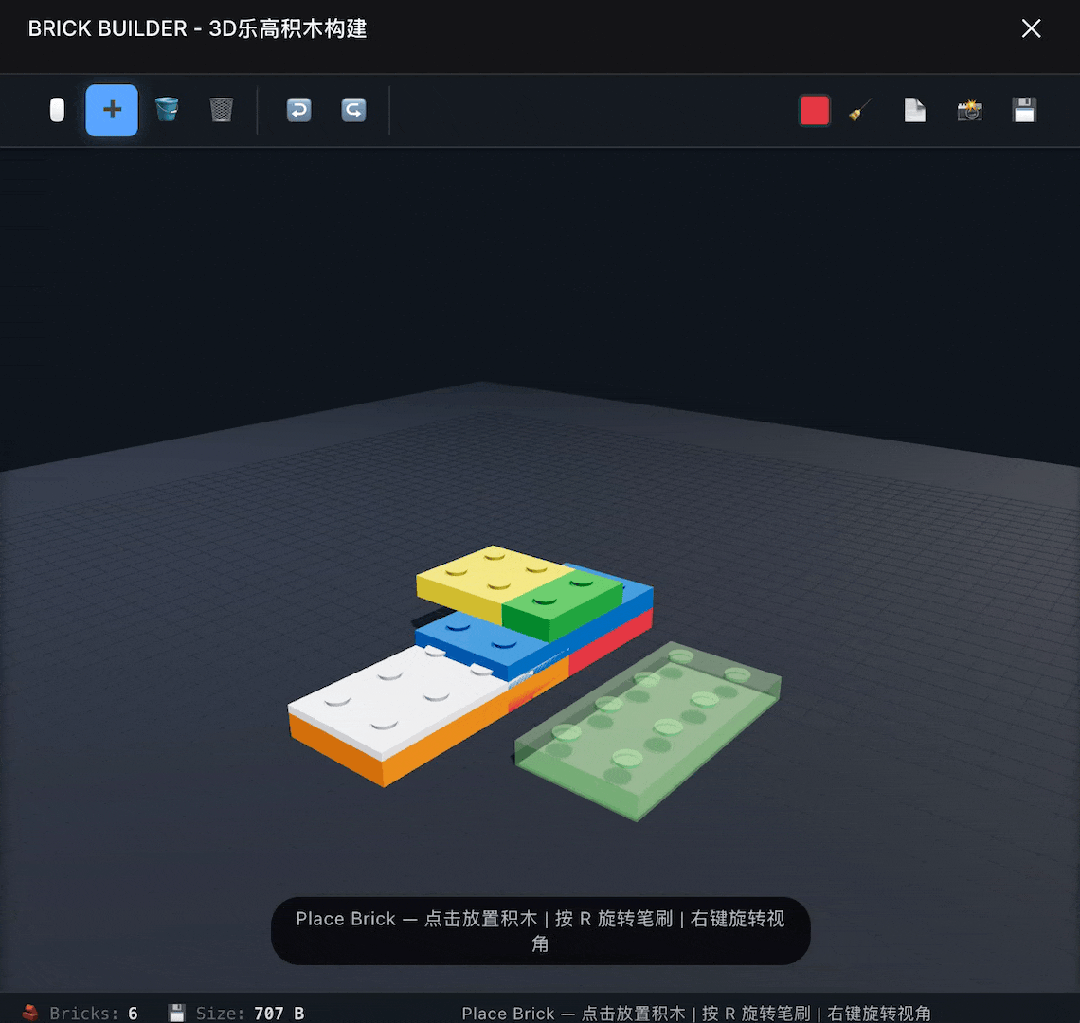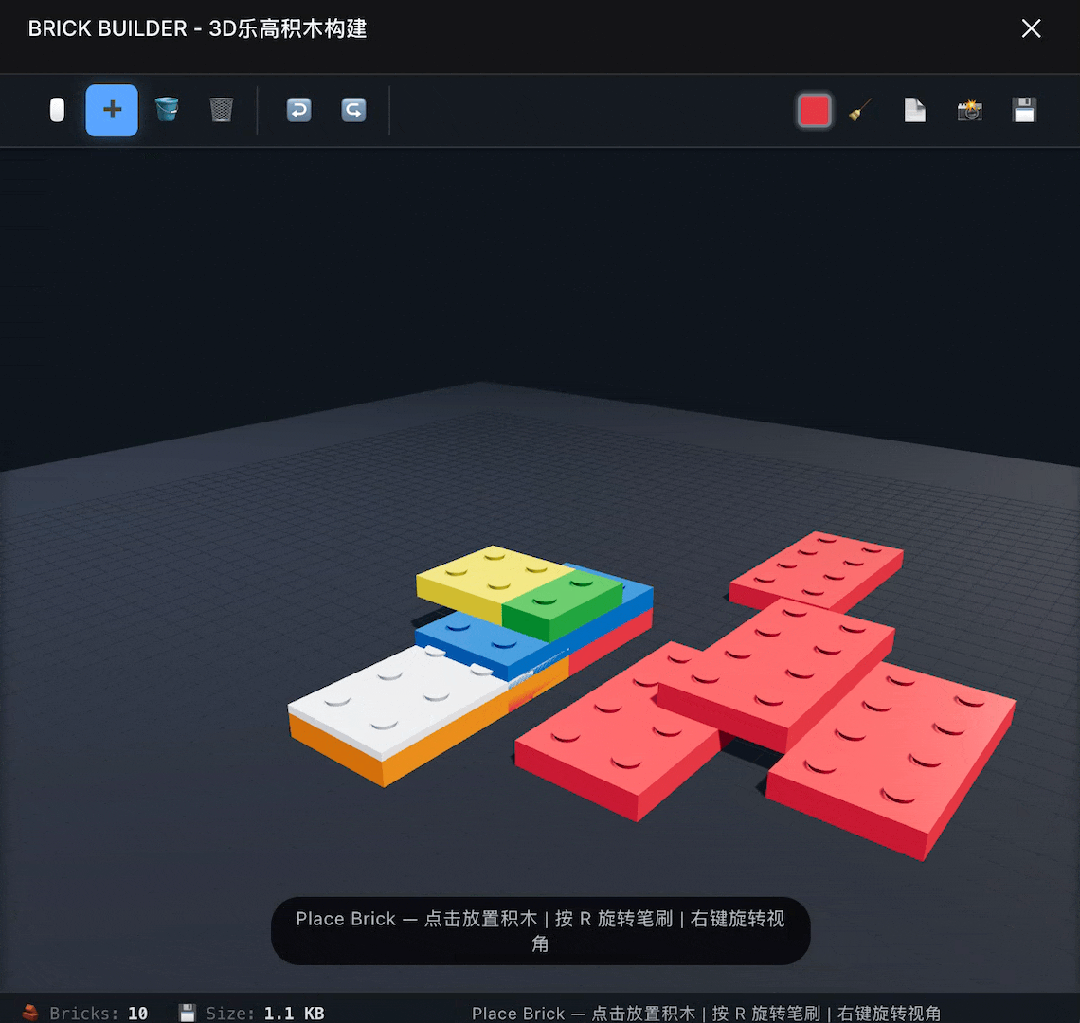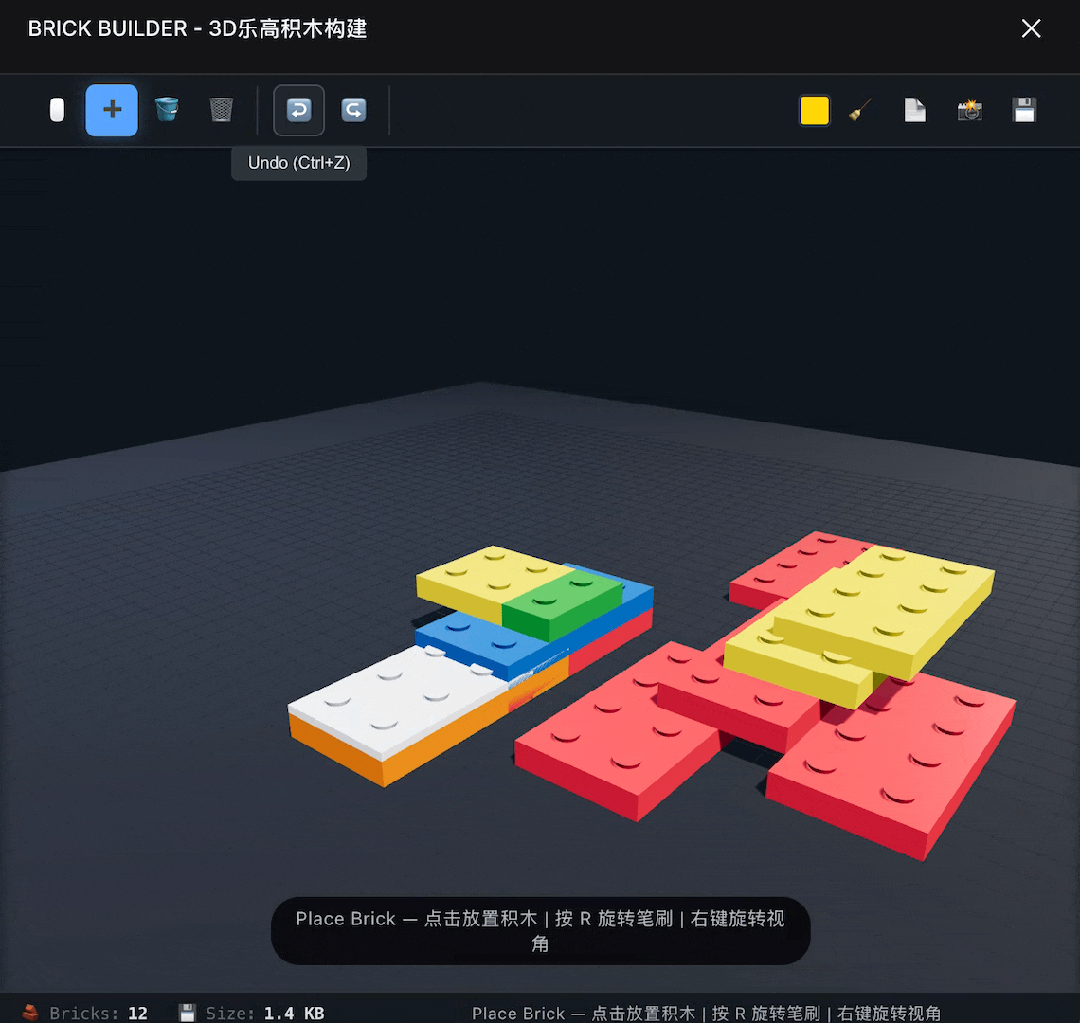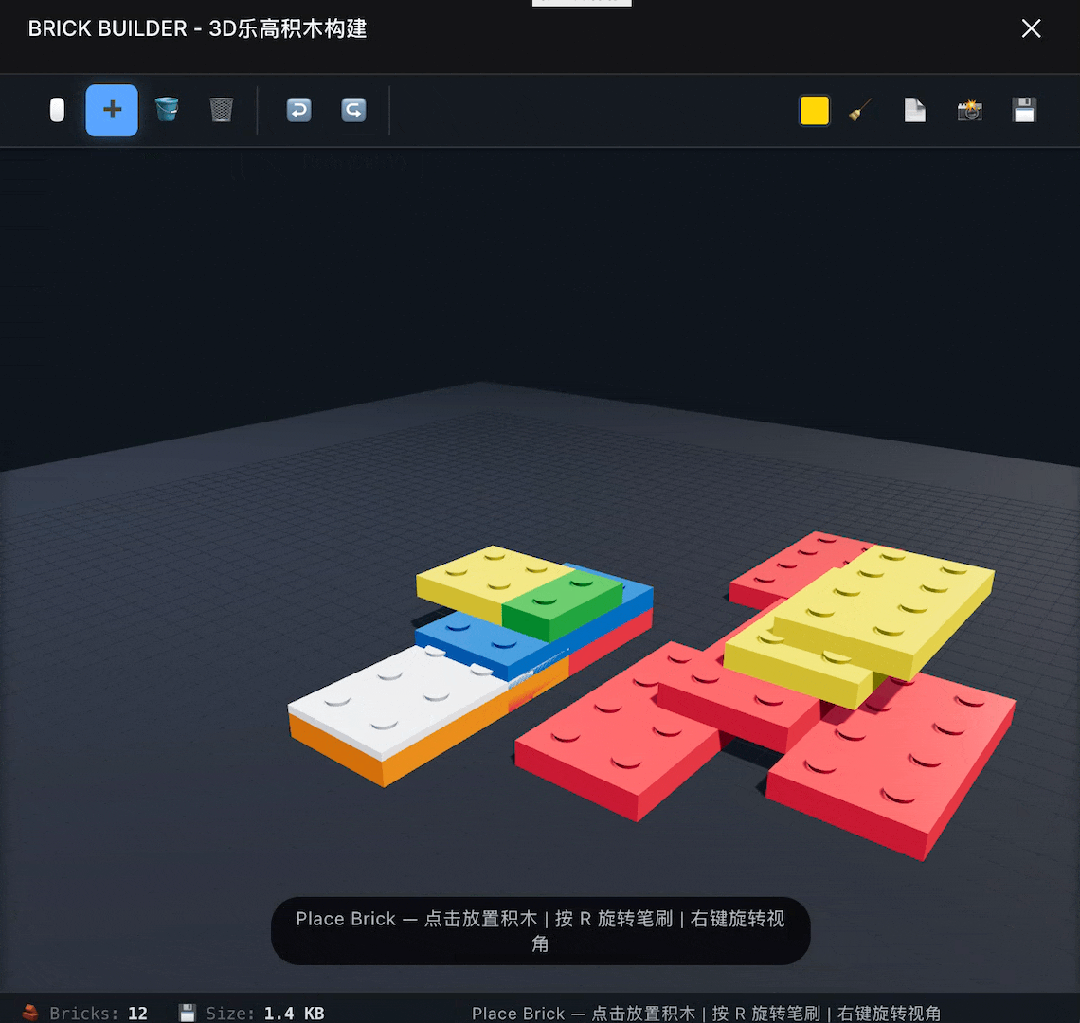
提示DeepSeek修复这个问题后,它给了我没有任何变化的修改版。
再次降低难度,让它生成一个树生长的动画,按照推特上的展示,Qwen 3.6和Gemma 4能很好完成这个任务。
提示词:
用一个包含全屏画布的HTML文件(不使用任何库)来制作一棵树的动画,树从屏幕底部中心实时生长。树干首先向上生长,然后树枝以递归的方式分叉,角度和长度略有随机性。每一代树枝都应该更细,颜色略浅。当树枝达到最终大小时,在枝梢添加一些柔和的绿色小圆圈作为叶子。树完全生长大约需要15秒。使用暖棕色表示木头,使用各种绿色表示叶子,背景为柔和的天蓝色渐变。

结果很不错,DeepSeek V4不仅完成了任务,最终画面还有不错的美感。
到这里,DeepSeek V4的整体表现天花板不高,也不够稳定。
但在Claude Code框架下的编程模型通常能更好发挥,所以接下来要将DeepSeek V4接入Claude Code来继续测试。
然后,它给我写了一个初始化状态错误所以没法玩的2048小游戏。

当然,这只是个小错误,但也能看出DeepSeek V4出现幻觉的概率挺高的,即便在比较简单的任务下。
接下来我们还要尝试一个新场景,用网页模拟康威生命游戏,模拟时长一分钟,并能实时通过鼠标点击加入新种子,难度介于Excel和模拟树生长之间。
提示词:
请使用单个HTML文件实现一个完整的《康威生命游戏(Conway’s Game of Life)》动画程序,要求如下:
一、技术约束
仅使用HTML+CSS+原生JavaScript
禁止使用任何第三方库或框架
所有代码必须写在同一个HTML文件内
不允许引入外部资源(CDN、图片库等)
二、画布与渲染
使用
作为全屏绘制区域
自动适配浏览器窗口大小(100%宽高)
支持高分辨率屏幕(考虑devicePixelRatio)
网格应为等比例方格(例如10px~20px可调)
三、游戏逻辑(康威生命游戏规则)
每个细胞只有两种状态:存活/死亡
每一代按照经典规则更新:
少于2个邻居→死亡(孤立)
2或3个邻居→存活(延续)
超过3个邻居→死亡(过度拥挤)
死细胞刚好3个邻居→复活
四、初始化状态
初始随机生成40%~60%的存活细胞
支持预设一个有趣的图案(如滑翔机+随机噪声混合)
五、动画要求
动画持续运行60秒
帧率控制在10~30 FPS(避免过度计算)
60秒结束后:
自动停止更新
停留在最终状态
六、视觉效果
存活细胞:亮绿色方块
死亡细胞:黑色或深色背景
可选轻微视觉增强(例如渐隐、拖影效果),但不能影响性能
背景简洁,无多余UI
七、性能要求
必须使用二维数组或优化结构存储状态
更新时避免重复DOM操作(只用canvas重绘)
尽量优化邻居计算(避免O(n²)过重实现)
八、增强(加分项)
支持暂停/继续(按空格键)
支持点击画布切换细胞状态
支持按R重置随机世界
DeepSeek的实现结果很漂亮,而且确实可以用鼠标添加种子,把一些进入静息状态的生命再次激活。
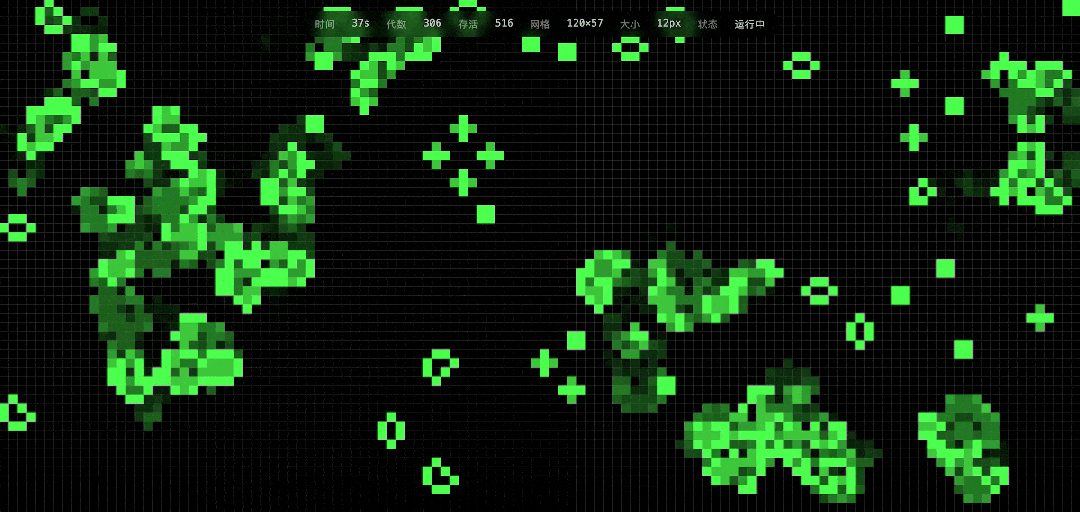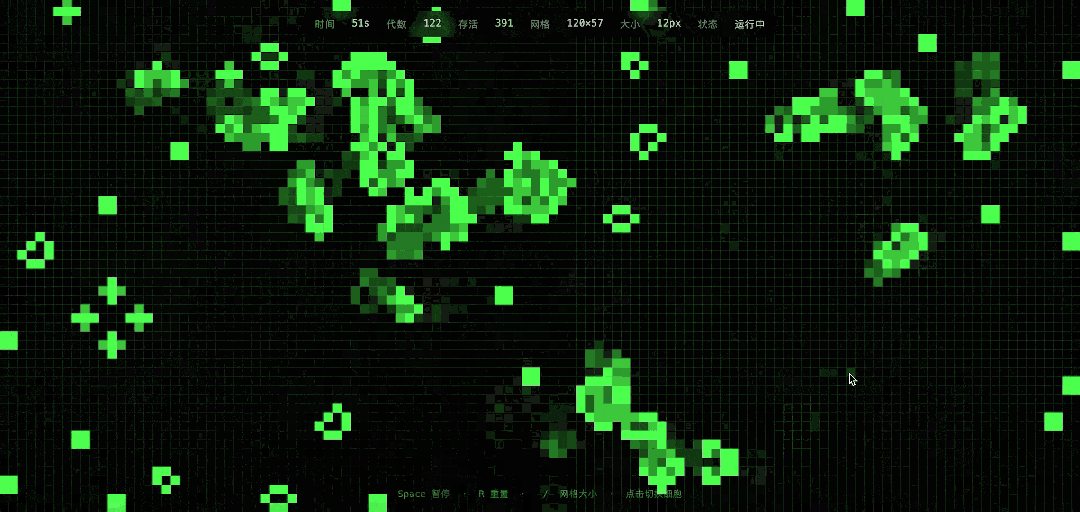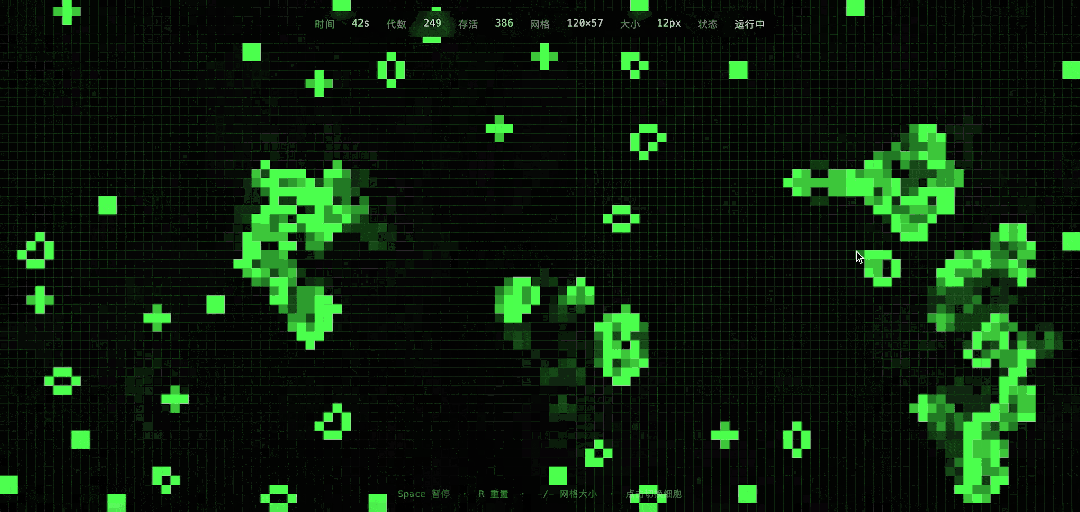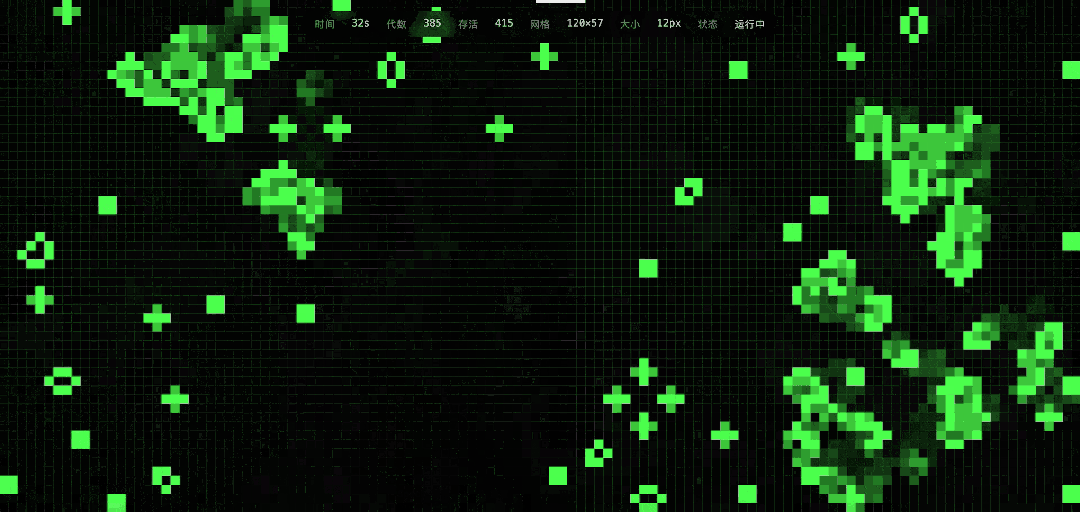
DeepSeek V4这次的任务执行时长是分钟级。作为对比,GPT-5.3几乎是瞬间就生成了代码,简直是复制黏贴般的速度,而且程序也能正常运行,当然,视觉上的粒度和审美感要差了很多。

最后我们还是让DeepSeek V4再次挑战一下网页版Excel案例。
在纯自主执行的条件下,DeepSeek V4用将近半小时实现了一个基本完成的版本,但还是有一些小错误,比如对齐功能失效。
其实按照开源模型目前在Coding Agent生态中的定位,还是更合适在顶尖闭源模型把控下做具体的执行工作。
所以,我先把任务传递给GPT-5.3,让它给出执行规划,然后把任务和规划一并给到DeepSeek V4执行。
这回,DeepSeek V4给了一个漂亮的结果,基本没有错误。
根据Claude Code的Context统计结果,当前上下文总量是81.6k token,占上下文极限的8%。

最后看看API用量,以上四个任务,总共花了8人民币左右,将近百分百都是DeepSeek V4 Pro模型消耗的。

但这并不意味着DeepSeek V4 Flash模型没有发挥作用,更具体的数据表明,DeepSeek V4 Flash模型的调用次数和DeepSeek V4 Pro相当,就是token消耗量少一个量级。

到这里测评就结束了。
从目前测试结果来看,DeepSeek V4的百万上下文长度有效性百分比不是很高,幻觉率较高导致不管在简单还是较困难的任务中都有可能出现低级错误,导致表现不稳定。在Claude Code中的代码审查阶段,有时要消耗三分之一到一半的时间来改代码。
思考时间过长可能是最尴尬的问题。即便是网页版Excel也不算很复杂的案例,而DeepSeek V4动辄十几分钟的思考时间,加上执行时间就更久了,总时长经常达到三十分钟左右。
其实人们现在对思维链已经祛魅了,它顶多是通过提升算力来提升准确率的工程手段,在Coding Agent场景中可能大部分都被忽略不看。
模型能力上限使其不太可能在实际编程任务中担任主导角色,作为执行者速度又太慢,关闭Thinking模式或者换成Flash模型是否还能保证执行准确率,时间原因,目前知危这里还没有测试案例可循。
总的来说,从我们测试的这些案例的视角来看,DeepSeek V4的表现没有想象中的好,并且能力表现似乎也不是特别稳定。但是其实官方技术报告里本来也就大大方方的说了自己跟闭源顶级模型仍有差距,本次更新只是缩小了差距,所以这个结果也不意外。
但是吧,还是那句话,你再看看它的价格,都这么便宜了,能忍。

