2026-05-08 14:39

本文来自微信公众号: 集智俱乐部 ,作者:面博士
如果AI不再仅仅是“被动响应”,
而是能够“自我成长”?
在人工智能的发展史中,我们是否已经触及了静态模型的天花板?想象一个场景:你部署了一个精密的科研助理智能体,它在上线之初表现完美,但当全新的科研算法发布、或是实验工具库更新时,它却因为固化的逻辑而变得束手无策,必须等待人类专家进行繁琐的手动重构。这种“部署即巅峰、随后即落后”的尴尬局面,正是当前大模型应用面临的核心瓶颈:我们的系统是早熟且静态的,而现实世界却是动态且不断演化的。那么,我们能否创造出一种像生物一样,能够在交互中学习、在反馈中进化、甚至能够自主制造工具的智能系统?这一设想正随着“自我进化AI智能体”研究的兴起而逐渐变为现实。
范式迁移:
从离线预训练到多智能体自主演进的四个阶段
要理解自我进化AI智能体(Self-Evolving AI Agents)的深远意义,必须将其置于大语言模型发展的宏大背景中。研究者指出,智能系统的演进正经历着一场从“冻结状态”到“完全自主”的范式变迁,这一过程可以清晰地划分为四个阶段。
第一阶段是模型离线预训练(Model Offline Pretraining,MOP),这是所有智能系统的基石。在这个阶段,模型在大规模静态语料库上进行预训练,随后以一种固定、冻结的状态被部署。这意味着模型一旦离开训练实验室,其知识和能力便不再更新。
第二阶段是模型在线适配(Model Online Adaptation,MOA)。为了弥补离线预训练的局限,这一阶段引入了部署后的适配技术,如监督微调、低秩适配(LoRA)或人类反馈强化学习(RLHF)。通过标签、评分或指令提示,基础模型可以进行更新,以更好地符合特定任务或人类偏好,但这依然主要集中在参数层面的微调。
第三阶段是多智能体编排(Multi-Agent Orchestration,MAO)。随着任务复杂度的提升,单一模型已难以为继,研究界开始协调多个智能体通过消息交换或辩论提示进行协作。虽然这一阶段解决了复杂任务的拆解与执行,但智能体之间的协作模式、通信协议和工具链依然是人为预设且固定的。
第四阶段,也是目前最前沿的阶段,即多智能体自我进化(Multi-Agent Self-Evolving,MASE)。这是真正意义上的“终身演进”范式,它引入了一个闭环系统,使得智能体群体能够根据环境反馈和元奖励,持续且自主地精炼其提示词、记忆结构、工具使用策略,甚至是智能体之间的交互拓扑结构。这标志着人工智能正从一个“黑盒工具”转变为一个具备长效生命力的“数字化生命体”。
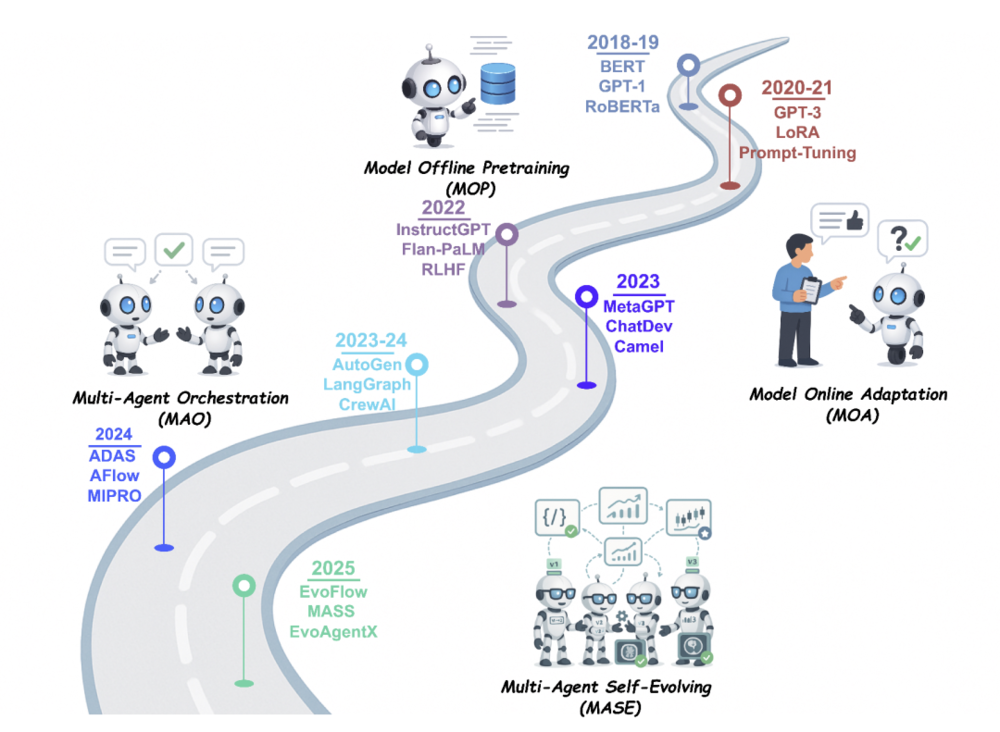
图1:以大语言模型(LLM)为中心的学习正从单纯从静态数据中学习,演变为与动态环境交互,并最终通过多智能体协作和自我进化走向终身学习
3.进化法则:生存、卓越与演进的交织
为了确保这种自主进化的过程既高效又可控,研究者从阿西莫夫的机器人定律中汲取灵感,提出了自我进化AI智能体的“三大定律”。首先是生存定律(Endure),它要求智能体在任何自我修改过程中必须首要保持安全性与稳定性。其次是卓越定律(Excel),即在满足安全的前提下,系统必须保持或增强其现有的任务性能,不能因为进化而产生能力倒退。最后是进化定律(Evolve),它鼓励智能体在遵循前两条准则的基础上,能够积极响应环境变化,自主优化其内部的所有组件。这三大法则构成了一个层级化的约束体系,为迈向真正意义上的强人工智能提供了伦理与技术的双重保障。
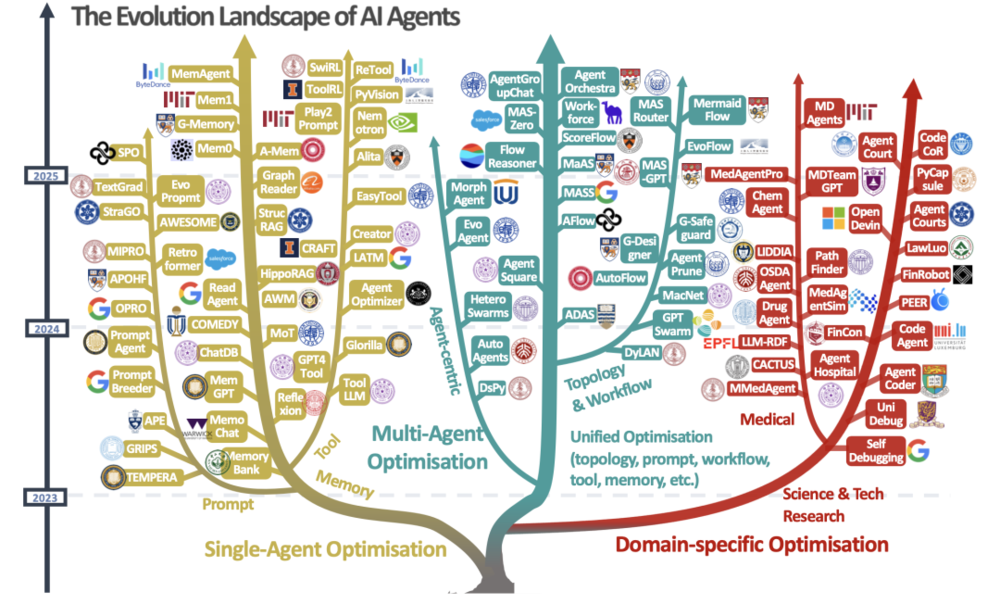
图2:AI智能体进化和优化技术的视觉分类法,分为三个主要方向:单智能体优化、多智能体优化和特定领域优化。树状结构展示了这些方法从2023年到2025年的发展情况,包括各分支中的代表性方法。
4.统一概念框架:构建智能成长的闭环逻辑
为了系统化地推进这一研究方向,研究者提出了一个高度抽象且具普适性的统一概念框架。该框架将复杂的演化过程解构为四个相互作用的核心组件:系统输入、智能体系统、环境以及优化器。
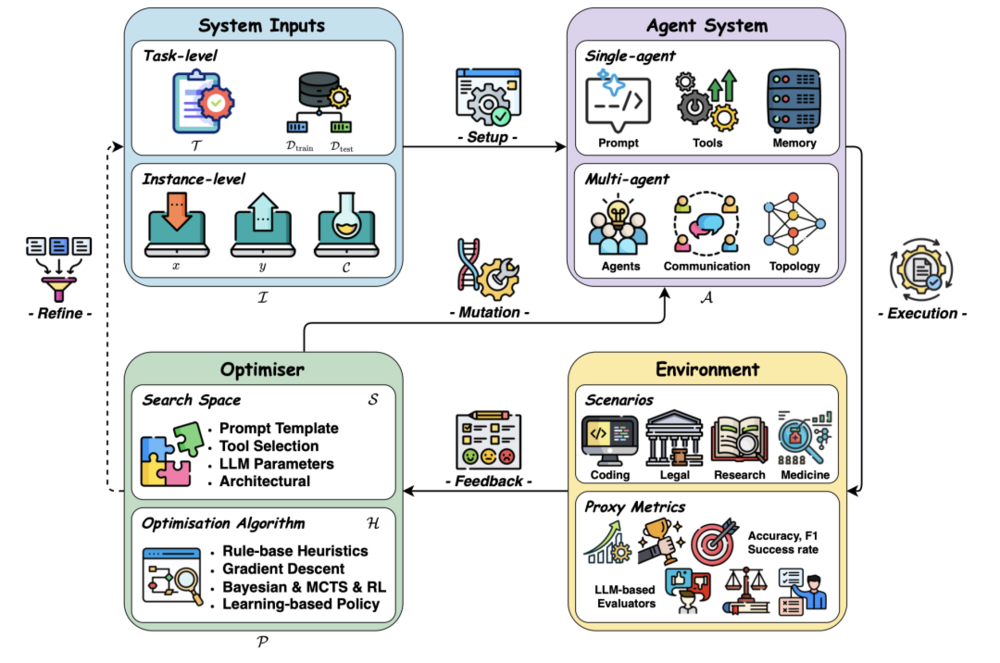
图3:智能体系统中自我进化过程的概念框架。该过程形成了一个由四个组件组成的迭代优化循环:系统输入(System Inputs)、智能体系统(Agent System)、环境(Environment)和优化器(Optimiser)。系统输入定义任务设置(如任务级或实例级);智能体系统(以单体或多体形式)执行任务;环境根据不同场景通过代理指标提供反馈;优化器则通过定义的搜索空间和优化算法更新系统,直到达成性能目标。
整个进化的循环始于系统输入,它为演化定义了边界。这些输入可以是宏观的任务描述,也可以是微维的具体实例。随后,智能体系统——无论是单体还是多体结构——在特定的环境中执行任务。环境不仅是智能体运行的舞台,更是反馈的源头。它通过预定义的度量指标或基于大模型的评估器,产生衡量系统效能的反馈信号。
在这一闭环逻辑中,优化器扮演着类似“进化引擎”的核心角色。它由搜索空间和优化算法共同驱动。搜索空间决定了智能体系统中哪些部分是可以被“变异”和“筛选”的,其粒度涵盖了微观的提示词、记忆管理策略,直至宏观的系统架构。而优化算法则决定了探索这一空间的方法,涵盖了基于规则的启发式搜索、文本梯度下降、以及复杂的强化学习策略。这种“执行-评估-优化”的迭代循环,使得系统能够像生物进化一样,通过优胜劣汰,最终收敛于解决复杂问题的最优构型。
5.自我进化智能体的优化范式:
单体、多体与领域化策略
5.1单智能体优化:深度精炼决策引擎的核心能力
在自我进化的塔基,单体智能体的优化直接决定了整个系统的决策深度。优化的重心主要集中在基础模型行为、提示词、记忆机制以及工具调用这四个关键维度。
在基础模型行为优化层面,研究者正致力于增强模型的推理与规划能力。除了利用监督微调让模型模仿高质量的推理轨迹,强化学习被广泛用于将推理视为序列决策过程。通过自我博弈或偏好学习,模型可以在无外部标签的情况下实现零数据进化。此外,测试时计算(Test-Time Compute)技术的兴起为智能体提供了“思考更久”的机会。它允许模型在推理阶段利用蒙特卡洛树搜索(MCTS)等算法进行深度思考,从而在不改变模型参数的情况下显著提升复杂逻辑问题的解决质量。
提示词优化则针对大模型对输入指令的高度敏感性展开。除了传统的基于编辑的局部搜索,前沿研究引入了“文本梯度”技术。它模仿了神经网络的自动微分思想,将自然语言反馈视为一种语义梯度,引导提示词向着更准确、更稳健的方向演进。与此同时,记忆优化解决了长程任务中的遗忘难题。短期记忆侧重于信息的智能压缩,而长期记忆则利用检索增强生成(RAG)技术,构建起可跨会话更新的外部知识库。最后,在工具优化领域,智能体不仅学习如何更高效地调用接口,更开始探索自主“制造工具”,即根据需求编写代码并封装为新武器。
5.2多智能体系统:从手动编排到拓扑架构的自动演化
当任务复杂度超越单体极限时,多智能体系统的协同进化展现出了超越个体的力量。这一领域的演进逻辑正经历从“手动设计协作流”到“自动发现协作拓扑”的深刻变革。传统的并行流、层级流或辩论机制虽然经典,但在多变环境下往往显得僵化。
现代自我进化系统将多智能体协作视为一个关于拓扑结构、角色定义和基础模型能力的综合搜索问题。在拓扑优化方面,研究者开辟了两条路径:一是代码级工作流优化将交互逻辑视为可执行程序,利用进化算法在程序空间内搜索最高效的逻辑链条;二是通信图拓扑优化则通过动态调整智能体间的连接概率,剔除冗余和高风险的通信环节。更进一步的“统一优化”路径认为提示词与拓扑结构是深度交织的整体,只有同步演进才能激发系统的最大潜能。此外,针对模型背后的基础模型进行协作导向的强化训练,能够显著增强智能体作为团队成员的沟通质量。
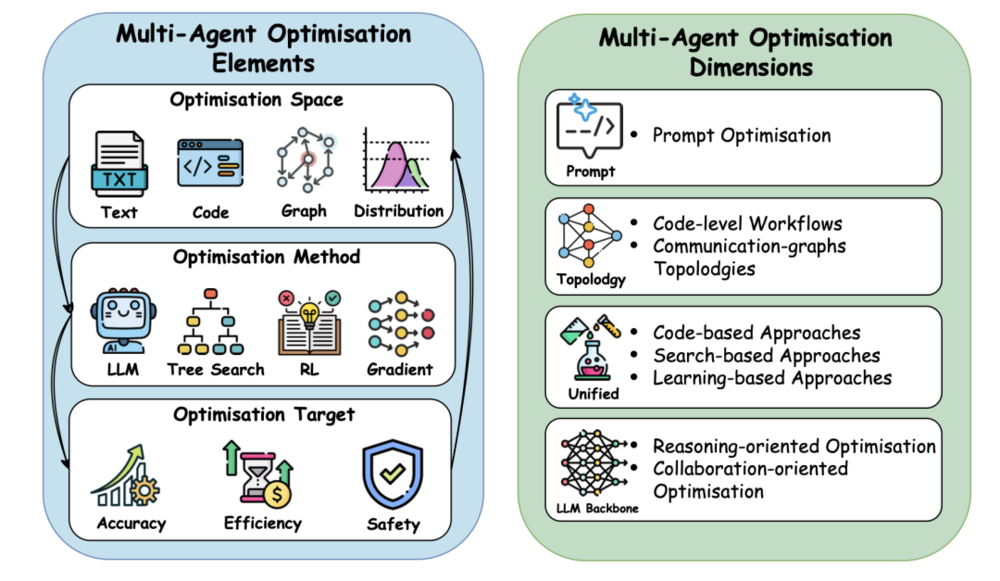
图4:多智能体系统优化方法概览,左侧展示了核心优化要素(空间、方法和目标),右侧展示了优化维度(提示词、拓扑结构、统一优化及LLM骨干网络)。
自我进化的通用逻辑必须在特定领域的深水区得到验证。在生物医学领域,智能体进化侧重于模拟真实的临床诊疗环境,通过多轮问诊补全信息,或利用化学分析工具进行分子发现中的符号推理。在编程领域,优化的核心在于代码的自我精炼与自愈调试,智能体通过执行反馈信号定位故障并自主修复。金融与法律领域则要求极致的规则遵循。金融智能体需要适应瞬息万变的动态市场,通过博弈平衡收益;法律智能体则通过模拟法庭辩论,在结构化的思维链指引下,确保输出符合司法准则。这些实践表明,自我进化并非盲目变异,而是在专业知识指引下的精准适配。
6.总体评估、安全性与未来展望
随着演进能力的增强,传统的静态评估体系已逐渐过时。评估不再是任务结束后的简单打分,而是演化成了指导进化的动态反馈机制。除了日益真实的基准测试,利用强模型担任裁判(LLM-as-a-Judge)或让具备推理能力的智能体评价其他智能体(Agent-as-a-Judge)已成为主流。这种方式能够捕捉推理轨迹中的细微偏差,提供高频率、低成本的反馈。
然而,进化的力量也带来了前所未有的安全挑战。由于演进路径具有不可预测性,如何确保智能体在追求性能的同时,始终遵循生存定律和伦理边界,是目前研究的重中之重。展望未来,自我进化AI智能体将在更开放、更具交互性的模拟平台中进行全方位的演进。它们将不再是单纯的任务执行者,而是能够持续学习、自主制造工具、并根据需求重构自身拓扑的动态生态参与者。一个高度适应、自主进化且持久存在的智能时代正加速到来,引领我们通往真正意义上的强人工智能。
参考文献
Zelikman,Eric,Yuhuai Wu,Jesse Mu,and Noah Goodman.2022.“STaR:Bootstrapping Reasoning with Reasoning.”Advances in Neural Information Processing Systems,vol.35,pages 15476–15488.
Wei,Jason,Xuezhi Wang,Dale Schuurmans,Maarten Bosma,Brian Ichter,Fei Xia,Ed H.Chi,Quoc V.Le,and Denny Zhou.2022.“Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.”Advances in Neural Information Processing Systems.
Yao,Shunyu,Dian Yu,Jeffrey Zhao,Izhak Shafran,Tom Griffiths,Yuan Cao,and Karthik Narasimhan.2023.“Tree of Thoughts:Deliberate Problem Solving with Large Language Models.”Advances in Neural Information Processing Systems,vol.36,pages 11809–11822.
Guo,Daya,Dejian Yang,Haowei Zhang,Junxiao Song,Ruoyu Zhang,Runxin Xu,Qihao Zhu,Shirong Ma,Peiyi Wang,Xiao Bi,et al.2025.“DeepSeek-R1:Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.”arXiv preprint arXiv:2501.12948.https://arxiv.org/abs/2501.12948.
Ye,Rui,Shuo Tang,Rui Ge,Yaxin Du,Zhenfei Yin,Siheng Chen,and Jing Shao.2025.“MAS-GPT:Training LLMs to Build LLM-Based Multi-Agent Systems.”arXiv preprint arXiv:2503.03686.https://arxiv.org/abs/2503.03686.
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。