




2026-05-24 23:00

扫码打开虎嗅APP


本文来自微信公众号: 赛格大道 ,作者:刘溪禾
硅谷AI精英在公开场合的表态,与他们真实的判断和资源部署之间,存在系统性背离,他们之间存在一种压制中国AI的战略默契:表层威胁论扩大政策弹药(出口管制、打击蒸馏、限制云租赁),里层用代差武器锁定真实的断代领先。
面对硅谷释放的烟雾弹,从去年年初DeepSeek爆发开始,几乎过去了一年半的时间,中国舆论场基本被其表层叙事成功捕获,所有人都不愿打破认知上的舒适区。
日本、加拿大和英国金融系统的高官,近期纷纷发出警告,原因在于,他们目睹了一个美国新模型的惊人能力。这款模型叫Mythos,属于Anthropic目前真正的旗舰模型,其训练参数规模约10万亿,单次训练成本高达100亿美元左右。
谷歌联合创始人,推动Gemini重回巅峰的谢尔盖·布林,在体验Mythos模型后感叹:“这就是AGI级别的大模型”。这是硅谷创业教父级别的人物,第一次在某个具体模型上承认实现了AGI。
但在中国,普通用户对此闻所未闻,即便是AI从业者,纵使听过名字,也不清楚其实力究竟。
Mythos没有对外公开,这指的是该模型不通过API公开提供,不进入LMArena,不与任何模型在公开榜单上同台,而是通过一个叫“玻璃翼计划(Project Glasswing)”的机制,以受控方式开放访问。
玻璃翼是一种源于南美洲的蝴蝶,这种蝴蝶看似纤细透明的翅膀却能承受40倍体重的压力。Anthropic设想中的人工智能安全防护机制,并不是堆料叠甲的“钢铁长城”,而是一套极具韧性的长期机制。
12家创始合作伙伴获得了访问资格,包括AWS、Apple、Google、Microsoft、NVIDIA、CrowdStrike、Linux Foundation等关键基础设施企业,外加约40家维护“关键软件基础设施”的其他组织获得有限访问权(英国AI安全研究所测试过Mythos)。但加拿大、日本、欧盟等盟友的国家级金融监管和国家安全机构基本未能进入名单,这意味它们既无法独立评估Mythos的能力边界,也无法验证它对本国关键系统的潜在影响。
这正是日本、加拿大财长不得不在IMF会议上集体讨论防御方案的原因,因为Mythos在4月出现以后,Mozilla Firefox单月修复的安全漏洞比整个2025年还多,比月均高20倍。如果有人把它用于进攻,它能在几小时内系统性扫描另一国关键基础设施的漏洞。
耐人寻味的是,金融官员们的反应,不是“我也要这个模型”,而是“我要防御它”,这在AI史上是第一次。这固然是美国与传统盟友之间出现裂痕不无关系,但其能力之强悍,足以让普遍保守的金融官员感到恐惧,才是更加真实的原因。毕竟,Mythos几乎达到了核武器的逻辑,类似不可扩散的战略资产。
于是,这就回到了问题真正的起点:当一个国家把“真正最强的AI”和“对外评测的AI”分开管理时,所有建立在公开榜单上的“差距分析”都失去了意义。
而在中国舆论场,近一个月反复引用的报告是来自斯坦福HAI 4月发布的《AI指数报告2026》,报告中,中美AI大模型的性能“差距缩小到2.7%”。许多中国的从业者、投资者、政策制定者乃至普通群众,都为此感到信心满满。
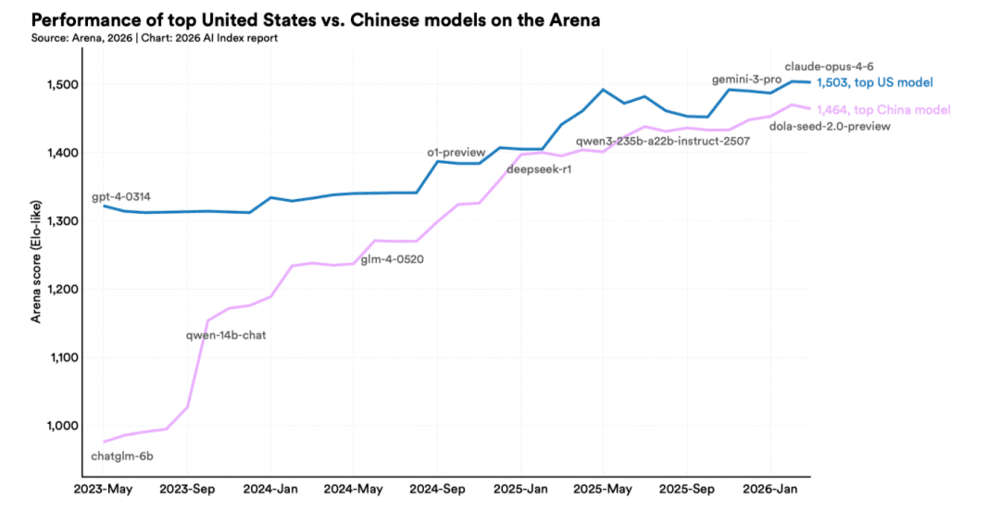
《2026 Al Index report》——“历史性拐点,中美大模型已没差距”“炸裂反转,中国仅用2.7%差距锁死全局”等标题在舆论场中出现。

如果说Mythos是“美国没拿出来的”模型,美国国家技术标准局(NIST)下属CAISI中心4月底的一份评估告诉我们:美国已经拿出来的部分,差距也比想象大得多。
CAISI用未公开基准测试DeepSeek V4 Pro:
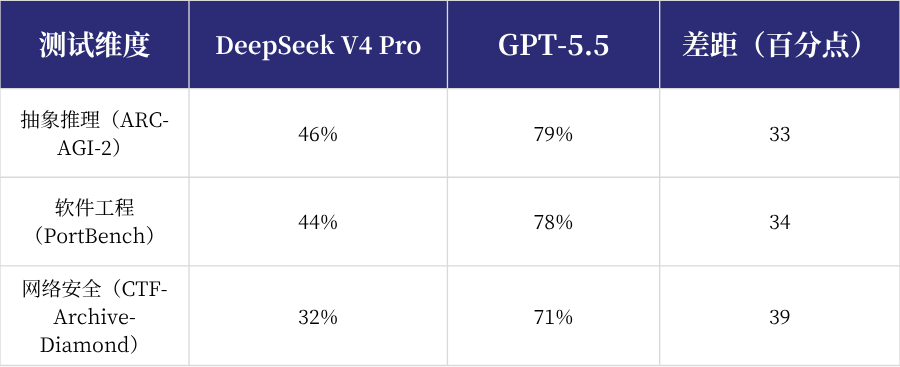
CAISI隶属于美官方机构(商务部),不可能被充值刷分
从表格来看,双方已发布最新模型之间,不是2.7%的差距,而是超过30个百分点的差距,并在网络安全这一最敏感维度上达到39个点。
CAISI的结论是:DeepSeek V4 Pro的实际能力相当于8个月前的GPT-5,且差距在扩大。事实上,DeepSeek在V4的技术博客中,对比的也是GPT5.4,并未与几乎同期发布的5.5比较。
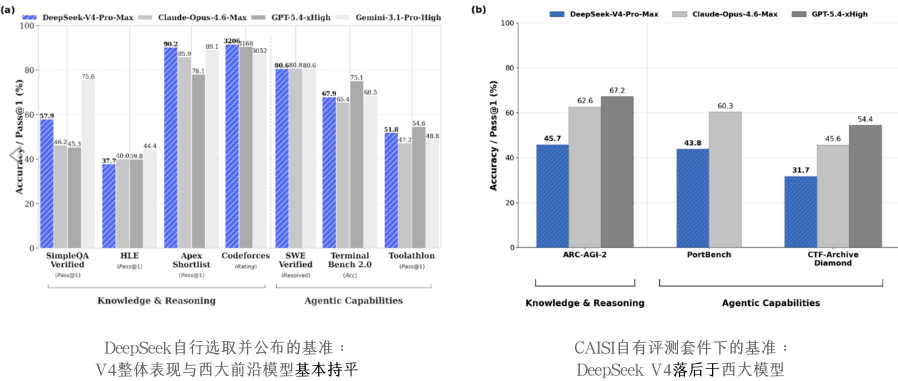
为什么CAISI的结论和斯坦福报告对不上?因为方法不同。
公开基准(MMLU、HumanEval、HLE等)的根本问题——它们公开存在越久,各家针对性优化越深。题目类型一旦被分析透,模型团队就能用数据增强和强化学习专门提分。一段时间后,公开榜单上的得分反映的不是真实能力,是各家的“应试能力”。CAISI用未公开基准跑出来的差距,才是真实差距。
DeepSeek自己说能力接近Claude Opus 4.6,这话在公开基准上成立,在CAISI的未公开基准上,它实际相当于Opus 4.4时代的GPT-5。中间隔着两个版本号、8个月时间、三家最强公司的迭代节奏。
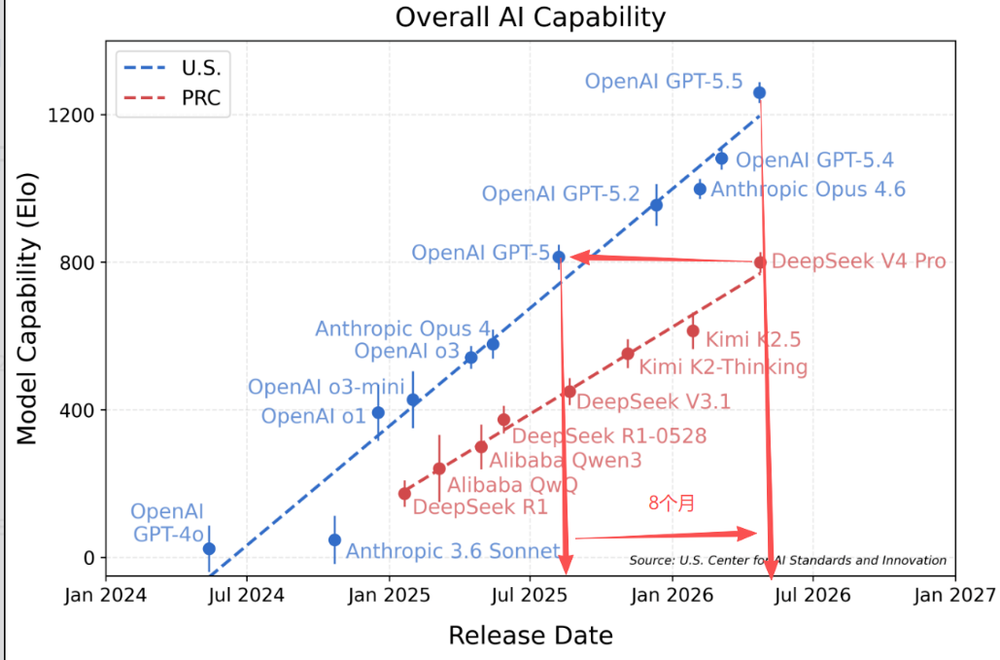
测评结果显示,GPT 5.5在各项评分中都是最强的,其次是Claude Opus 4.6,最后是DeepSeek V4。
当然,这份评估不包括Mythos。算上Mythos的真实差距是多少?没有公开答案,但几乎肯定会进一步拉大。

差距的根源在哪里?答案是算力。
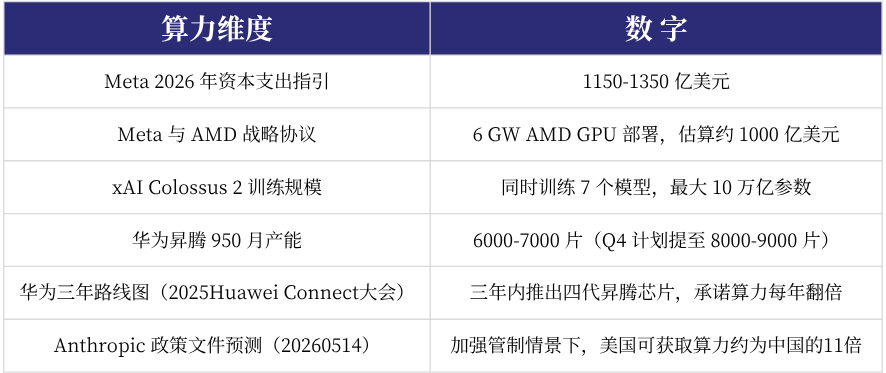
数据来自公开资料,作者制表
一个颇为残酷的事实是,Meta一家公司2026年的AI资本支出,已经接近中国所有头部AI企业的总和。DeepSeek V4 Pro总参数量1.6万亿,但与美国10万亿级参数差6倍以上。
xAI那种“同时训练7个模型”的暴力模式只有算力极度充裕才能做到,本质是用算力买确定性,跑通哪个用哪个。但即使这样,它也没拿到胜利,最近刚刚被埃隆·马斯克整合进SpaceX,失去了独立运营的资格。
相比硅谷公司在算法上做“暴力筛选”,以DeepSeek为代表的中国头部模型公司,必须做算法上的“精打细算”。也许有人会说这恰恰体现了中国公司的工程能力,但更接近实际情况的是,这是一种无可奈何。毕竟,所有人都明白,精打细算可以追平80%的能力,最后那20%的代差,必须靠足够算力才能撑起来。
国产芯片产能在快速追赶是事实。但即便产能上来了,能不能跑出和英伟达一样的结果?是被严重低估的另一个挑战。
2025年11月发表的一项研究(奥克兰大学、香港理工大学、岭南大学、哈工大等机构)首次对5款企业级AI加速器做了大规模实测——英伟达H200、AMD MI300X、Intel Max 1100、华为昇腾910B、Apple Mac M4 Pro——用4000个真实PyTorch模型合成超过10万个变体逐一测试。
结论触目惊心:
操作符支持:英伟达H200支持488个,华为Ascend 910B只支持407个,少17.5%——而且华为缺失的恰恰是大模型最依赖的部分:量化推理、稀疏操作、flash_attention、NLP嵌入、融合训练操作、高级线性代数。
输出一致率:用同样的模型跑同样的数据,AMD和英伟达的输出99.8%一致;华为95%——5%概率给出不同结果;Mac 86%。
平台缺陷:英伟达1个,AMD 4个,华为13个——堆内存崩溃频率是其他平台10倍,不支持的操作符比英伟达多80倍。
5%的输出不一致率在金融、医疗、自动驾驶等高可靠场景是无法接受的;在大模型预训练场景,这种偏差会通过千万次迭代被放大成系统性错误。
以上是学术论文,最后有一个真实世界的注脚。无独有偶,就在几天前的谷歌I/O大会后,旧金山的AI视频生成公司Midjourney的创始人霍尔茨(David Holz),就在公开吐槽自己公司用了谷歌的TPU芯片,导致模型落后了一年,并表达了对英伟达芯片的赞赏。

Midjourney曾是AI生图的绝对领先者,如今已经显得比较平庸,并被很多产品反超。这个案例很直观地说明了英伟达高端芯片当前对绝大多数公司的不可替代性。当然,他这样公开的吐槽,必然遭受来自外界的压力,所以,很快这条内容就消失了。但对英伟达芯片的褒奖,代表了一种实践认知,客观上比论文更有说服力。
这意味着,不同芯片之间的算力差距,不只是“数量”问题,更是“质量”问题。中国AI想要真正自主,不仅要把昇腾产能从月产6000-7000片爬升到匹配英伟达的水平,还要把PyTorch操作符支持从少17.5%补齐、输出一致率从95%提升到接近100%、平台缺陷从13个降到接近1个——这是一个比单纯扩产难得多的工程。
中国AI圈过去一年反复讲一个故事:DeepSeek用2048张H800训练出顶尖模型,证明算法可以对冲算力。这个故事是真的——但它的边界没讲清楚。
2026年ACL主会议发表的一项研究(中科大与上海AI实验室合作)给出了一个明确的数学结论:
预训练的规模定律是幂律关系,理论上可无限扩展。
强化学习(RL)后训练是对数线性关系,存在绝对天花板。
RL本质是激活预训练已有能力的输出分布,不是创造新能力。
翻译成大白话就是:没有办法通过后训练,把一个1.6万亿参数模型调到10万亿参数模型的能力水平。
DeepSeek的“算法对冲算力”,对冲的是同等参数规模下的算力浪费,不是不同参数规模之间的能力鸿沟。要在前沿能力上追平美国,就必须有十万亿级参数的预训练能力——而这件事在物理上需要十几万张高端GPU集群、几个月连续训练、上百亿美元投入。没有算力底座,前沿差距是一个数学约束,不是工程努力问题。

如果我们把Mythos的封闭、CAISI的未公开评估、算力的指数级差距、异构加速器的不一致、后训练的数学上限综合起来看,再回看过去半年硅谷在中国舆论场反复释放的“中国AI追上来了”“差距缩小到2.7%”,就会发现一件事:硅谷AI精英在公开场合的表态,与他们真实的判断和资源部署之间,存在系统性背离。
表面上,用中国威胁论争取美国政府的弹药支持。
有不少资料显示相关信息,例如:
2026年5月2日《连线》杂志独家披露:暗钱机构Build American AI通过营销公司SM4,在TikTok和Instagram以5000美元一条的价格付费招募网红,散布“中国AI威胁美国”内容,OpenAI涉嫌资助;
Anthropic CEO Dario Amodei公开发文反复说“中国创新令人印象深刻”,每次都要补一句“所以美国必须加强管制”;
斯坦福《AI指数报告2026》的“中美交替领先”框架——而这份报告的主要赞助商正是Google、Microsoft、Anthropic等管制受益方;
美国国会专门设立“引领未来”超级政治行动委员会,向亲管制派议员定向献金。
暗地里,用秘而不宣的模型锁定真正的断代领先:
Mythos不进入任何公开榜单,"玻璃翼计划"只对12家美国机构开放;
CAISI用非公开基准做评估,差距数据从不进入对外报告;
Anthropic 5月14日发布政策文件,明确目标是"到2028年建立12-24个月领先"。
可见,这是硅谷AI精英圈存在一种压制中国AI的战略默契:表层威胁论扩大政策弹药(出口管制、打击蒸馏、限制云租赁),里层用代差武器锁定真实的断代领先。
面对硅谷释放的烟雾弹,从去年年初DeepSeek爆发开始,几乎过去了一年半的时间,中国舆论场基本被其表层叙事成功捕获。
例如,中国的AI模型公司,普遍乐意释放有利于自有模型的打榜信息,各种媒体、短视频传播不绝如缕;广大媒体和自媒体,也十分愿意宣传这些榜单,既无监管压力,又有切实收益,何乐不为;科技产业政策的制定者,也接纳斯坦福报告中的有利数据和媒体的正面宣传,沉湎于日益泛滥的赢学叙事。可以说,整个国家都洋溢上AI向上的氛围,所有人都满意,所有人都不愿打破认知上的舒适区。
黄仁勋近日表示,即便我去了北京,英伟达也无法获得来自中国的收益。
但正如本文开头那些金融官员的警告,Mythos模型带给各国金融安全的冲击不容小觑,甚至在军事、国家安全等方面的冲击还待评估。对此,面对最强AI武器化的临近,中国当下是否有足够的评估能力和防御准备,应该被视为一个关键议程。
(作者系科技产业资深研究者)
参考文献:(上下滑动显示更多)
1.Project Glasswing官方页面
Anthropic,Project Glasswing:Securing Critical Software for the AI Era,2026年4月7日发布。
URL:https://www.anthropic.com/glasswing
2.加拿大财长Champagne在IMF会议期间接受BBC采访的原始报道
"Finance ministers and top bankers raise serious concerns about Mythos AI model",BBC/路透社/Financial Times联合报道,2026年4月16-17日。
中文转载与英文摘要:
https://investinsidernews.com/finance/finance-ministers-and-top-bankers-raise-serious-concerns-about-mythos-ai-model/
3.美国NIST CAISI中心对DeepSeek V4 Pro的独立评估
Center for AI Standards and Innovation(CAISI),U.S.National Institute of Standards and Technology,Independent Evaluation of DeepSeek V4 Pro on Non-Public Benchmarks,2026年4月底发布。
4.Anthropic政策文件《Building Toward American AI Leadership Through 2028》
Dario Amodei,Building Toward American AI Leadership Through 2028:Export Controls,Distillation,and Global Adoption,Anthropic Policy Paper,2026年5月14日。
5.WIRED杂志关于Build American AI暗钱运动的调查报道
Vittoria Elliott et al.,"A Dark Money Campaign Is Paying Influencers to Cast Chinese AI as a Threat",WIRED,2026年5月2日。
URL:https://www.wired.com/story/dark-money-china-ai-influencer-campaign/
6.异构AI加速器实证研究(关于"质量差距")
Elliott Wen,Sean Ma,Ewan Tempero,Jens Dietrich,Daniel Luo,Jiaxing Shen,Kaiqi Zhao,Bruce Sham,Yousong Song,Jiayi Hua,Jia Hong,Mind the Gap:Revealing Inconsistencies Across Heterogeneous AI Accelerators,arXiv:2511.11601,2025年11月18日。
作者所属:奥克兰大学、香港理工大学、惠灵顿维多利亚大学、哈尔滨工业大学、岭南大学。
URL:https://arxiv.org/abs/2511.11601
7.ACL 2026关于强化学习后训练规模上限的论文
中国科学技术大学+上海人工智能实验室联合研究,Scaling Behaviors of LLM Reinforcement Learning Post-Training:An Empirical Study,ACL 2026主会议论文。
预印本:https://arxiv.org/abs/2509.25300
代码与数据:https://github.com/tanzelin430/The-Scaling-Law-for-Reinforcement-Learning
8.Midjourney创始人David Holz关于TPU与英伟达技术栈的推文,2026年5月21日上午8:45发布,后删除。中文留痕来源:凤凰科技《Midjourney创始人暗示被谷歌耽误一年》;
URL:https://tech.ifeng.com/c/8tHkNrUtZwd
9.Sergey Brin关于Mythos是"AGI级别"的公开评价:见Anthropic玻璃翼计划发布会内容及The Information 2026年4月相关报道。
10.斯坦福HAI,AI Index Report 2026,423页报告,2026年4月发布。
URL:https://aiindex.stanford.edu/report/
11.Meta、Google、xAI的2026年算力部署数据:分别来自各家年报、I/O大会公告、Elon Musk在X上的公开披露。
12.白宫科技政策办公室(OSTP),2026年4月23日备忘录,关于限制中国AI模型开发者通过蒸馏获取美国前沿模型输出。

