




2022-01-12 14:45

扫码打开虎嗅APP


本文来自微信公众号:游戏研究社(ID:yysaag),作者:照月,头图来自:《法国大革命》
2010年12月,谷歌与哈佛大学合作推出了科学实验项目“Google Ngram Viewer”,中文翻译为“谷歌图书词频统计器”。
简而言之,这个统计器是针对图书出版物的一种“谷歌趋势”。统计器提供关键词搜索,搜索的范围是谷歌的数字图书馆“谷歌图书”,分析关键词在图书、报纸、期刊中出现的频率,并按照年份依次排开,最终基于用户给定的时间跨度,提供一条显示关键词流行及发展趋势的曲线。

横轴为年份,纵轴为词频
在语言学范畴上,谷歌给定的文本范围可以被称作一种“语料库”,而谷歌语料库可能是迄今为止最大的人文及社会科学研究语料库。
刚上线时,谷歌语料库中拥有超过500万本图书,占世界上所有已出版书籍的4%,其中以英语书占多数。2020年7月,谷歌语料库更新至2019版本,收录从1500年到2020年2月的书籍文本,涵盖英文、简体中文、法文、德文等八种语言,图书数量已超过千万本。
谷歌表示,词频统计器得出的数据允许免费下载并用于任何用途,因此这项工具受到欧美学术界的热烈欢迎与频繁引用。
然而,更多的人把统计器用在了不那么学术的用途上。在以造梗与玩梗著称的互联网民中,流传着这么一种玩法:用词频统计器搜索一些21世纪才出现的流行语及特有名词,等待统计器提供一条令人细思恐极的曲线。
例如像下面的视频那样,在搜索框输入“Grand theft auto”——也就是GTA的全称,你就会发现GTA在1770年左右拥有比21世纪还要高的词频。
也许,历史老师在讲授那段历史时,有意向你隐瞒了些什么。
词频统计器的这种玩法,是由法国人率先发现并大加传播的。至少在第二次世界大战之前,法国一直是公认的欧洲乃至世界强权,而词频统计器对那段历史的学术研究贡献之大,也许唤醒了他们对光荣时刻的追忆。
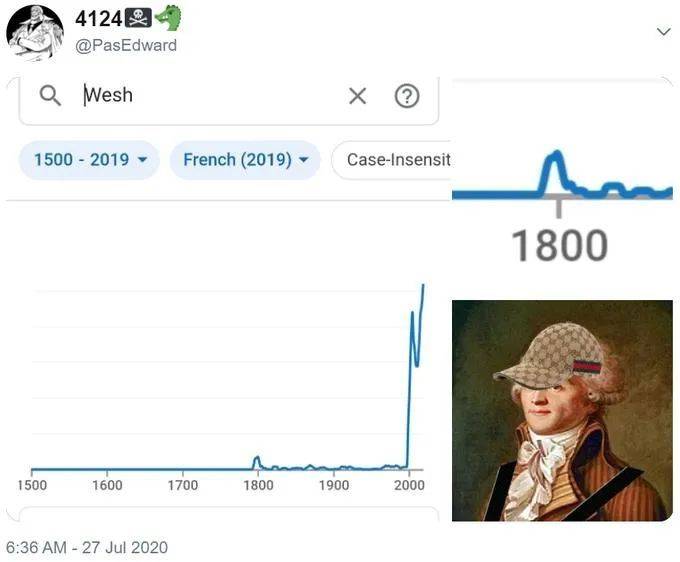
2020年7月27日,谷歌更新2019语料库没多久,法国网友PasEdward使用统计器的法语语料库,搜索了一个俚语单词:“Wesh”。这个词源自阿尔及利亚语,约在上世纪90年代传入法国,意思相近于英文中的“What’s up”,中文里的“嘿”或“发生了什么”。
结果显示,趋势曲线在1800年的位置上出现了一次波折,意味着“Wesh”在1800年的著作中有使用记录。虽然不明白原委,PasEdward还是把自己的发现放到推特上分享,同时配上一张简陋的P图,为法国大革命时期的著名政治家罗伯斯庇尔戴上了一顶现代帽子。
第二天,另两位法国网友搜索了一些欧洲歌手的名字,并在18~19世纪这一区间内找到了对应的索引结果。他们随即把歌手的头像P到法国国王路易十四与路易十六的画像上,同样上传至推特。
不久,词频统计器的新玩法流传至英语圈及短视频应用TikTok。结合法国人的创作成果,短视频作者们确立了一种两段式的视频模式,为统计器成为新兴网络梗奠定了基础:
首先使用统计器搜索当下的流行人物与事物,得到相关词汇曾在21世纪以前被使用的记录;然后动用P图与剪辑技术,制造出可能用到这一词汇的历史场景。
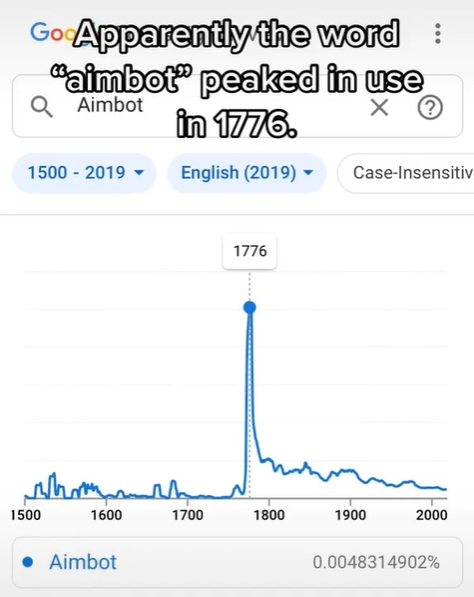
Aimbot,射击游戏的自瞄外挂,最早“出现”于1776年美国独立战争

“华盛顿将军,我们要输了”“不用担心兄弟,超级瞄准已部署”,图源TikTok@phattboyyy
时间来到2021年,统计器的热度有所消退,可是又在法国人的努力下迎来了一次复兴。
2021年10月10日,法国网友qouaa依照上面的格式制作了一部短视频,他搜索的词汇是“F*p”,意思与英文中的“Son of Bi**h”(*子养的)接近。趋势曲线在1700年左右有所上涨,接下来的一幕中出现穿着潮牌说着脏话的路易十四,也显得顺理成章。
这则短视频仅在一周内获得了超过300万次播放,也正式掀起了使用谷歌图书词频统计器“考据”的风潮。从TikTok、Youtube,甚至到国内的B站,相同格式的视频不断涌现,视频作者致力于将那段“可能被埋没的历史”重现于世间,搜索关键词也五花八门。
词频统计器告诉我们,16世纪有PC(个人电脑),17世纪有RGB(最常见的颜色系统),证明近代欧洲人已经在使用电脑,并且对电脑硬件上的彩光特效情有独钟。
硬件在发展,编程语言肯定也在进步,1817年的程序员用Java写个程序,好像也没啥值得大惊小怪的。

Youtube@1m
词频统计器还显示,17世纪以来的推特使用率居高不下;到了第一次世界大战时期,才轮到短视频应用红极一时。

莎士比亚推文:“生存还是毁灭”,图源Youtube@Daaninator
在音乐方面,迈克尔·杰克逊的名号响彻了整整两个世纪,而瑞克·艾斯利大概从17世纪起就开始唱流行金曲了。

二次元文化也盛行了几百年,据悉在第二次世界大战爆发时,世界上最受欢迎的日本动漫是《火影忍者》。
把搜索关键词换成今天的电子游戏,同样会得到令人们瞠目结舌的新发现:我们玩到的游戏其实都是老祖宗们玩剩下的。
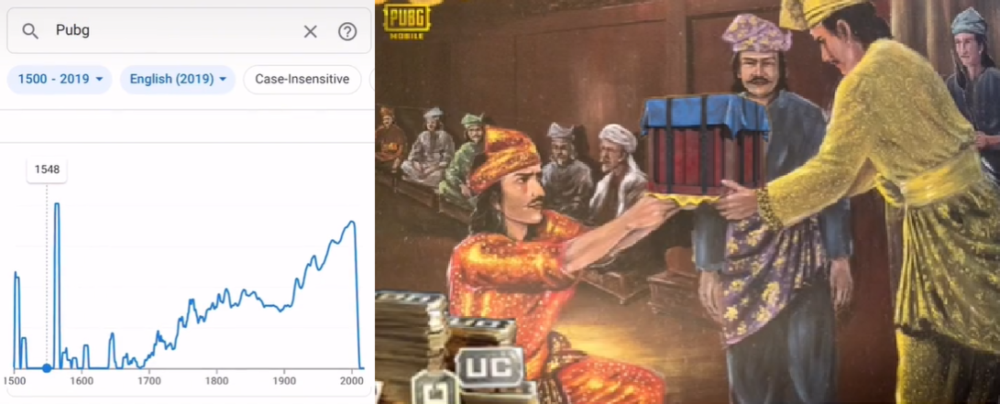
16世纪的《绝地求生》,图源TikTok@wncem;此外还有17世纪的《Apex英雄》和1945年的《我的世界》
老祖宗们甚至有着在游戏结束时打出“GG”(Good Game)的习惯,这大抵体现了他们对礼仪的规范与注重。

Youtube@Techlin
代表权威数据的谷歌图书词频统计器,改出了太多令网友们啼笑皆非的“野史”。不过需要注意,统计器出现这种差之千里的谬误,有时也不全是数据的错。
假如你出于好奇打开统计器复现网友们的搜索结果,就会发现一些结果与视频画面对不上。视频作者可能通过修改网页元素或者嫁接P图、剪辑的方式,制作了假的趋势曲线。
举例而言,前文中提到过的Aimbot(自瞄机器人),在1893年以前的著作中毫无记载。

Case-Insensitive选项能够得出区分大小写的结果
在B站有人查到“shabi”一词最早在美国《独立宣言》颁布的1776年出现,这也不符合真实索引结果。至少在谷歌英语语料库,这个词的纯小写形式直到1824年才首次有人使用。

就算查到了与视频中一模一样的趋势曲线,也不代表真实索引结果具有足够的说服力。网友们输入的单词或词组,可能对应多种含义,而谷歌的程序尚且无法做到划分不同语义的程度。

《我的世界》游戏风靡全球前,Minecraft一般指海军的布雷与扫雷艇
例如,PC、RGB、GG等特定词组的缩写形式,结合不同文本语境,可指代无数种具体事物;有时还会用作人名或机构名称的缩写。如果不进一步限定搜索范围,得到的结果不会有规律可循,自然缺乏应有的参考价值。
直接使用统计器搜索某个人名,也不是值得过多提倡的行为。历史记载中同名同姓者多如牛毛,更不用提老外的人名大多出自圣经,拥有远比中文夸张的重复率。
另外,TikTok与Twitter,本就是英语中的拟声词,在百余年前的英文著作中出现也根本不稀奇。

1880年的一本诗集中用twitter一词形容鸟叫
当然,玩梗没必要太过当真,本文也无意否定任何作者为了博观众一笑所耗费的大量心血,仅是指出在一部分视频中,作为工具本身的谷歌词频统计器没什么需要指摘的地方。
而在另一些关键词较为明晰的案例中,词频趋势曲线在20世纪前的增长态势有迹可循,使得统计器间接起到了反映历史与社会变动的职责。
世界意义上的近现代史,正是各大洲各民族建立紧密联系的关键历史时期,不同文化的交流与冲突,势必为包括英语在内的各种语言带来数不胜数的外来词汇。
前文提到的Java在当下的语境中常指一种编程语言,放到殖民时期多半指的是16世纪初由葡萄牙殖民者发现的东南亚爪哇岛。今天的Anime是由日语的“动漫”一词音译而来,然而百余年前的英国水手听到这个词,顶多联想到美洲大陆出产的某种树脂。

1908年《英华大辞典》中对anime一词的解释
Shabi一词在19世纪出现几率很高,是因为英国的殖民统治达到鼎盛,进而与东方文明产生了空前的交流。Shabi常出现在与中国、印度、阿拉伯文化相关的英文著作中,指代的意思各不相同,放到中国是“沙弼”,即沙弥、小和尚一词的音译;放到阿拉伯语里就变成了惯用的人名。


虽然我们使用统计器的方法有时不太科学,但谷歌的工具也绝非完美无瑕。事实上,早在谷歌图书词频统计器诞生伊始的2010年,就已经有学者吐槽过某些21世纪特有名词在语料库中的“穿越”现象。

网友们颇有微词时会把微词变成梗,而学者们的微词会变成学术研究与学术论文。近几年来的研究调查证明,谷歌的数据也没那么权威,其统计器与语料库存在的问题可不少。
最致命的问题是文本扫描错误。将图书扫描成电子文本所使用的光学字符识别技术,简称OCR,其可靠程度会根据图书的印刷质量产生浮动,在读取百余年前的文本时总是会出错。
以前的英文著作经常把字母s写作作形近于字母f的“长s”,直至18~19世纪印刷技术取得长足进步,“长s”才渐渐消亡。谷歌的OCR一度识别不出“长s”,导致许多带有s与f字母的单词之间产生可怕的混淆,直至2019年谷歌语料库更新,这一错误才得以大幅修正。

诗集《失乐园》(Paradise lost)的标题页,小写的字母s基本都印作“长s”
但有些相比之下并不明显的错误至今依然存在。就以网友们玩梗提出的那些关键词为例,把谷歌图书的搜索结果搬来和统计器作下对比,便会明白OCR偶尔会错到十分离谱的地步。
19世纪及以前的英文印刷品经常出现每行或每页末尾写不下完整单词的情况,印刷商会在没写完的单词后接上一根横杠“-”,让读者去下一行或下一页找到单词的后半部分。正是这个“-”,会被OCR识别成字母,像是“pub-”,就会出现在《绝地求生》缩写“pubg”的搜索结果中。


一些形近意思却完全不同的单词或词组,对于OCR而言亦是灾难。如“Infernet”,这个法国人的姓氏经常被错认为“Internet”(互联网);“fortune”(幸运)或是“for these”(为了这些),更是会被阴差阳错地识别成《堡垒之夜》的英文名“fortnite”。

谷歌扫描图书时,需要填充图书的标题、出版日期、作者、页数等元数据。这一过程与OCR类似,都由程序自动进行,因此也有漏洞。
文章开头视频中的GTA,即“grand theft auto”,在美国对应一种盗窃机动车的罪名。在谷歌图书搜索“grand theft auto”,并把搜索时间限定至18世纪的话,我们会查到一部实际在1981年出版、文中多次提到GTA的美国加利福尼亚州议会法案,它的出版日期被谷歌错标成了“1771年”。


单是这一本书的标注错误,就贡献了一条篡改历史的趋势曲线和一部让数百万人忍俊不禁的玩梗视频。如今各个视频网站类似的视频数以千计,而语料库中OCR与元数据出错的文献,恐怕还不止这个数量。
当然,任何科学测量工具都不可能做到百分百完美,数据与算法也不例外。能够在短短数秒之内完成定量分析,得出某种事物在数百年中的大致发展动向,正是谷歌图书词频统计器的价值所在。
不过,在这个语料库不知何时才有的下一次更新之前,这些谬误将一直作为网友们造梗的源泉而存在,这大概是开发者所没有想到的了。
本文来自微信公众号:游戏研究社(ID:yysaag),作者:照月

