2022-02-10 13:36


扫码打开虎嗅APP

本文来自微信公众号:学术头条(ID:SciTouTiao),作者:库珀,题图来自:《GT赛车》
人工智能的很多潜在应用,涉及与人类交互时做出更优化的实时决策,而竞技或者博弈类游戏,便是最佳的展示舞台。
今天,发表在《自然》杂志上的封面文章报告称,AI 在赛车对战游戏 Gran Turismo(GT赛车)中战胜了世界冠军级人类玩家。这个 AI 程序名为“Gran Turismo(GT)Sophy”,是一种神经网络驱动程序,它在遵守赛车规则的同时,展现出了超凡的行驶速度、操控能力和驾驶策略。

(来源:Nature)
完成这项 AI 程序研发的核心团队来自索尼 AI 事业部(Sony AI),《GT赛车》系列游戏是日本 Polyphony Digital 公司开发,忠实再现了真实赛车的非线性控制挑战,封装了复杂的多智能体交互,该游戏在索尼 PlayStation 及 PSP 等游戏主机平台上皆有发行,是一款极具拟真感操纵体验的热门赛车游戏。
假如有此 AI 程序的加持,人类玩家估计再也跑不过加强版的单机程序了吧?

图|游戏截图(来源:GT赛车)
研究人员认为,此项成果或让赛车游戏变得更有意思,并能提供用来训练职业赛车手和发现新赛车技巧的高水平比赛。这种方法还有望应用在真实世界的系统中,比如机器人、无人机和自动驾驶汽车等。
赛道里的速度与激情
驾驶赛车需要极大的技巧。现代一级方程式赛车展示了惊人的工程精度,然而,这项运动的受欢迎程度与其说与汽车的性能PK有关,不如说与顶级车手在将汽车性能发挥到极限时所表现出的技巧和勇气有关。一个多世纪以来,赛道上的成功一直充满着速度和激情。
赛车比赛的目标很简单:如果你比竞争对手在更短的时间内跑完赛道,你就赢了。然而,实现这一目标需要极其复杂的物理战,驰骋赛道需要小心使用轮胎和道路之间的摩擦力,而这种摩擦力是有限的。
为了赢得比赛,车手必须选择让汽车保持在不断变化的摩擦极限内的轨迹上。转弯时刹车太早,你的车就会慢下来,浪费时间。刹车太晚,当你接近转弯最紧的部分时,你将没有足够的转弯力来保持你想要的路线轨迹。刹车太猛,可能会导致车体旋转。
因此,职业赛车手非常擅长在整个比赛中一圈接一圈地发现并保持赛车的极限。尽管赛车的操纵极限很复杂,但它们在物理上可以得到很好的描述,因此,它们可以被计算或学习是理所当然的。近年来,深度强化学习(DRL)已成为 Atari、星际争霸和 Dota 等领域 AI 研究里程碑的关键组成部分。
为了让 AI 对机器人技术和自动化产生影响,研究人员必须证明能够成功控制复杂的物理系统,此外,AI 技术的许多潜在应用要求在接近人类的情况下相互作用,同时尊重不精确的人类规范,汽车比赛正是充满这些挑战的典型领域。
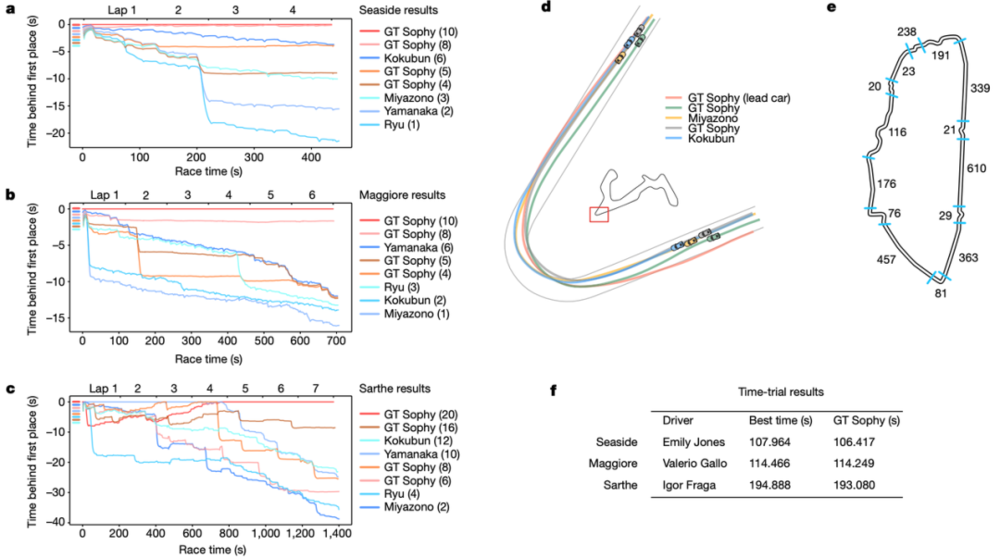
图|游戏比赛数据对比(来源:Nature)
近年来,利用全尺寸、大规模和模拟车辆,自主赛车的研究不断加速。一种常见的方法是预先计算轨迹,并使用模型预测控制来执行这些轨迹。然而,当在摩擦的绝对极限下行驶时,微小的建模误差可能是灾难性的。
与其他车手比赛对 AI 建模精度提出了更高的要求,并引入了复杂的空气动力学相互作用,进一步促使工程师改进控制方案,以不断预测和适应赛道的最优轨迹,有朝一日,无人驾驶汽车下赛道与人类车手一决高下,也并非空谈。
“AI赛车手”的炼成
在 GT Sophy 的开发过程中,研究人员探索了各种使用机器学习来避免建模复杂性的方法,包括使用监督学习来建模车辆动力学,以及使用模仿学习、进化方法或强化学习来学习驾驶策略。为了取得成功,赛车手必须在四个方面具备高度技能:(1)赛车控制,(2)赛车战术,(3)赛车礼仪和(4)赛车策略。
为了控制汽车,车手们对他们的车辆动力学和赛道的特性有详细的了解。在此基础上,驾驶者建立所需的战术技能,通过防守对手,执行精确的演习。同时,驾驶员必须遵守高度精炼但不精确的体育道德规则,最后,车手在模拟对手、决定何时以及如何尝试超车时,会运用战略思维。
模拟赛车是一个需要在具有高度真实、复杂物理环境中进行实时、连续控制的领域,GT Sophy 在这种环境下的成功首次表明,在一系列汽车和赛道类型中,有可能训练出比顶尖人类赛车手更好的人工智能代理。这一结果可以被视为是计算机在国际象棋、围棋、冒险、扑克牌和星际争霸等竞争性任务持续发展的另一个重要步骤。
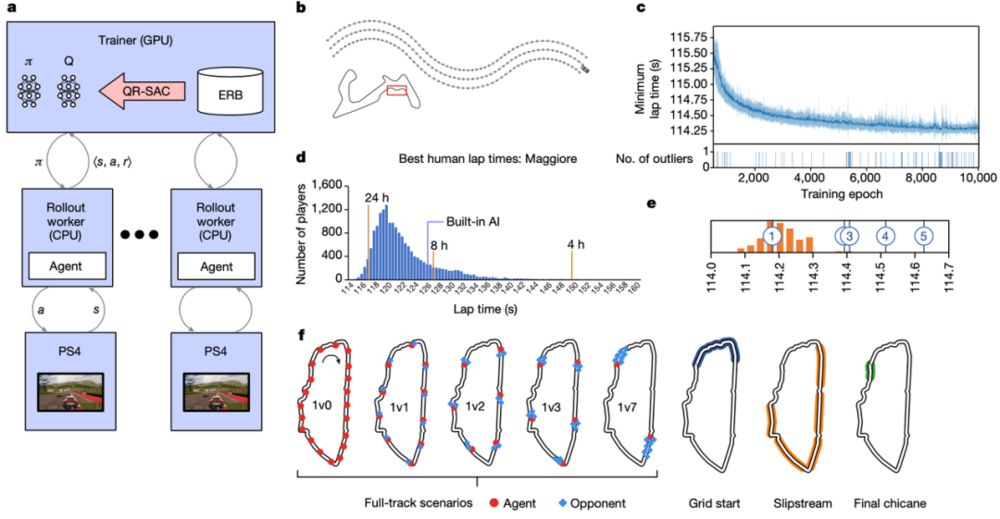
图|GT Sophy 的训练(来源:Nature)
值得注意的是,GT Sophy 在短短几个小时内就学会了绕道而行,并超过了数据集中 95% 的人类选手,它又训练了九天时间,累计驾驶时间超过了 45000 小时,跑圈时间减少了十分之一秒,直到圈速停止改善。单凭进步奖励还不足以激励AI程序赢得比赛。如果人类对手的速度足够快,AI程序将学会跟随,并在不冒潜在灾难性碰撞风险的情况下尝试积累更多奖励,实现超车。
为了评估 GT Sophy,研究人员在两项赛事中让 GT Sophy 与顶级 GT 车手进行了较量,GT Sophy 在所测试的三条赛道上都取得了超人的计时表现,它能够执行几种类型的转弯,有效地利用漂移,扰乱后面车辆,拦截对手并执行其他紧急操纵。
尽管 GT Sophy 展示了足够的战术技能,但仍有许多方面有待改进,尤其是在战略决策方面。例如,GT Sophy 有时会在同一条跑道上留出足够的空间,让对手有机可乘。
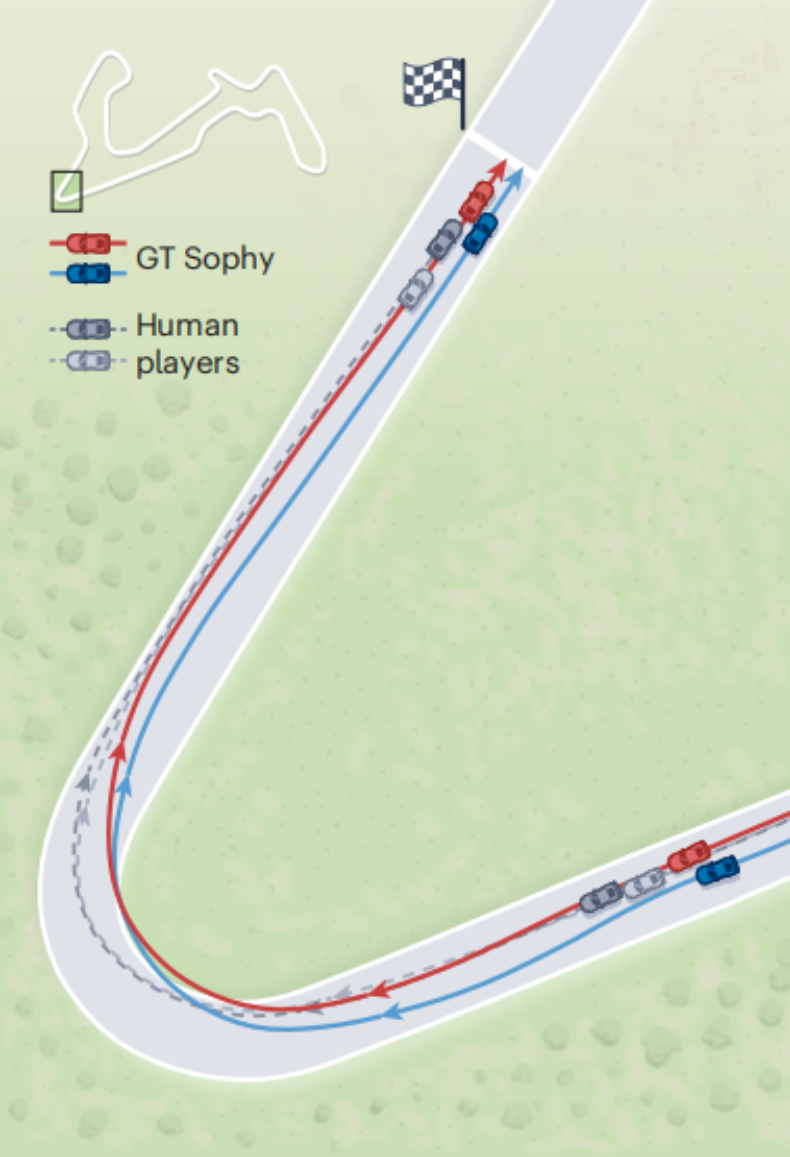
图|AI 车手超越人类玩家(来源:Nature)
竞技游戏外更值得关注
关于电子竞技、博弈类的游戏,AI 能战胜人类早已经不是什么稀奇事,而且可以肯定的是,AI 还会越来越强,即便是人类顶尖选手也只能甘拜下风,但能赢电子比赛并没有太多悬念和意义,关键还是看这些超越人类的 AI 程序如何切实攻克产业瓶颈,真实造福人类生活。
1996 年 2 月 10 日,超级电脑 Deep Blue 首次挑战国际象棋世界冠军 Kasparov 以 2:4 落败。1997 年 5 月再度挑战,最终Deep Blue 以 3.5:2.5 击败了 Kasparov ,成为首个在标准比赛时限内击败国际象棋世界冠军的电脑系统。
但 Deep Blue 的缺陷是没有直觉,不具备真正的“智能灵魂”,只能靠超强的计算能力弥补分析思考方面的缺陷,赢得比赛的 Deep Blue 很快也退役了。

2016 年 3 月,谷歌 AI 的 AlphaGo 在四场比赛中击败了围棋世界冠军李世石,被认为是 AI 真正意义上的里程碑,AlphaGo 当时使用了蒙特卡洛树搜索与两个深度神经网络相结合的方法,在这种设计下,电脑可像人类大脑一样自发学习进行分析训练,不断学习提高棋力。自此之后,各类 AI 程序新秀层出不穷,2018 年 12 月 10 日,DeepMind 针对即时战略游戏星际争霸开发的人工智能 AlphaStar 能完虐全球 99.8% 的人类职业选手。
无疑,现在的 GT Sophy 又是一个 AI 胜利的延续。来自斯坦福大学机械工程系教授 J.Christian Gerdes 认为,GT Sophy 研究所带来的影响也许能远远超出电子游戏范畴,随着许多公司致力于完善运送货物或乘客的全自动车辆,关于软件中有多少应该使用神经网络,以及有多少应该仅基于物理,值得进一步去探索。
总的来说,在感知和识别周围环境中的物体时,神经网络是无可争议的冠军。然而,轨迹规划仍然是物理和优化领域,GT Sophy 在游戏赛道上的成功表明,神经网络有一天可能会在自动化车辆的软件中发挥比今天更大的作用。更具挑战性的可能是每圈的变化。
真实情况下,赛车的轮胎状况在每圈之间都会发生变化,人类驾驶员必须在整个比赛过程中适应这种变化。GT Sophy 能用更多的数据做同样的事情吗?这些数据从何而来?这将使得人工智能有更多进化空间。
参考资料:
https://www.nature.com/articles/s41586-021-04357-7
https://www.nature.com/articles/d41586-022-00304-2
本文来自微信公众号:学术头条(ID:SciTouTiao),作者:库珀

 06:18
06:18









 17:21
17:21
 13:53
13:53
 04:54
04:54
 09:44
09:44
 02:36
02:36
 12:12
12:12
 51:12
51:12
 13:18
13:18
 05:23
05:23



