




2022-06-28 18:08

扫码打开虎嗅APP


本文来自微信公众号:量子位 (ID:QbitAI),作者:杨净、明敏,原文标题:《韩国AI团队抄袭震动学界!1个导师带51个学生,还是抄袭惯犯》,题图来自:视觉中国
今年CVPR,着实有点魔幻了!
先是韩国首尔大学AI团队的Oral,即前4%的优秀论文,被曝出涉嫌抄袭10篇论文。有的地方,连一个单词都没有变。
事发当日即登上韩国头条,国内外网友震惊:搞到CVPR上也太行了吧。
更多人爆料,这个团队抄袭已经不止一次,基本操作了属于是。
结果这一波还未结束,另一波又开始了。
IBM发表在CVPR上的论文TableFormer被指抄袭国内2021年发表的一篇文章。

爆料指出,IBM论文剽窃了他们的方法,包括预处理、可视化、推理、系统解决方案等,但并没有引用他们的论文。
抄袭事件频出,于是乎不少网友感叹:这届CVPR太魔幻了。

甚至还有人直接在知乎上列出了这么一个问题:
大家一起来揭发吧。CVPR 2022都有哪些论文是抄袭的?
先来看引发众人关注的韩国团队抄袭事件。
在通讯作者尹盛老和一作金某的最新公开回应中,都表示这次抄袭属于一作的个人行为,和团队其他人无关。尹盛老解释说:
团队其他合著者把各自的部分发给了一作,但是他最后却没有使用,而是抄袭了别的论文。
他还补充道,现在一作本人其他两篇正在审阅的论文也都被撤回了。
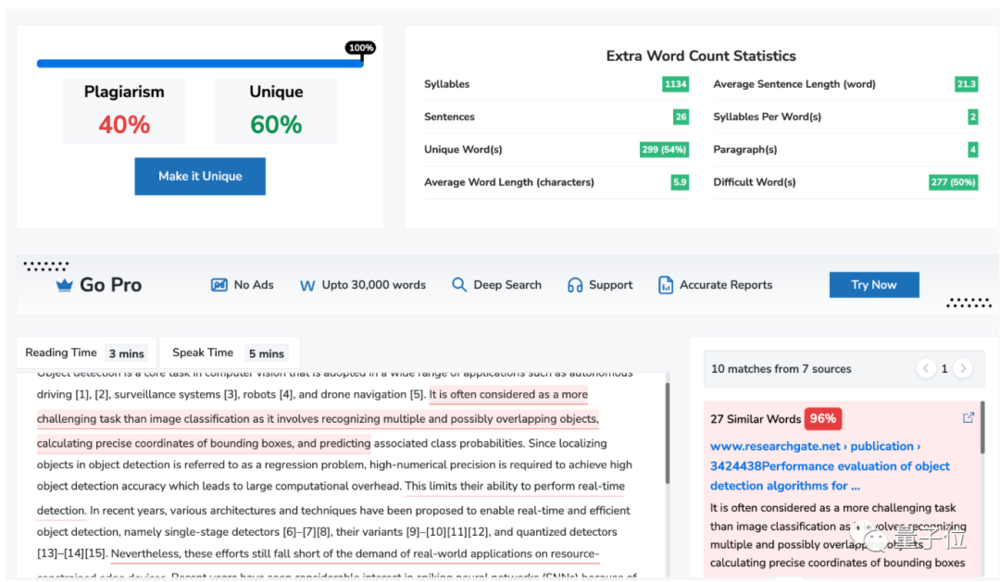
不过,网友们顺藤摸瓜后发现,该团队似乎不止这一篇论文存在抄袭嫌疑。比如这篇:《Towards Fast and Accurate Object Detection in Bio-Inspired Spiking Neural Networks Through Bayesian Optimization》。
检测软件显示,它有40%的抄袭嫌疑,文中有27处表达与之前研究高度相似。
还有另外一篇《Energy-aware Placement for SRAM-NVM Hybrid FPGAs》,也被发现存在类似问题。通讯作者都是尹盛老。


与此同时,还有人指出尹教授的实验室规模很大。博士生就有37位,加上硕士和博士后,实验室共有51位学生由尹盛老指导。
这也让有人担忧,一位教授是否能同时指导好这么多学生,他们的实验和论文质量是否会受到影响。
而从事件爆发的起点——油管曝光视频的内容来看,这次涉嫌抄袭的论文中,很多地方都是原封不动地搬运此前研究的表述。
涉及到的部分有Introduction、Preliminaries、Method等。

甚至有的地方是一字不落的copy。

全文出现的抄袭段落多达25处,曝光视频展示问题就花了7分多钟。
被抄袭的论文很多被NeureIPS、AAAI等顶会接收,其中还有几位一作是韩国人。

这也难怪上传曝光视频的人,会给视频起一个如此“刺眼”的标题:
E2V-SDE or: How I Learned to Stop Worrying and Love Plagiarism。
E2V-SDE又名:我是如何毫不担忧并爱上抄袭的。
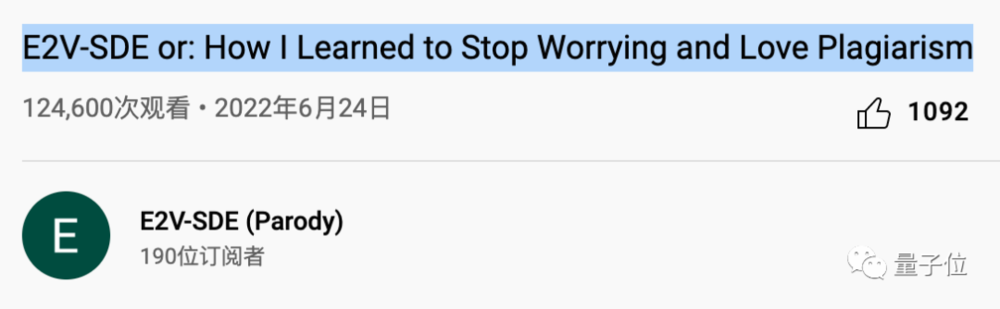
这里的E2V-SDE,就来自尹盛老团队此次被CVPR 2022接收的论文标题。

现在,随着事件的不断发酵,尹盛老团队还引发了韩国网友的群愤。要知道,尹盛老是韩国人工智能领域的权威专家,来自首尔大学人工智能研究所。
今年6月,他才刚刚被韩国科学技术部评选为“首席研究员”,每年享有大约8亿韩元(折合人民币约416万)的科研经费。
但如今,他的团队却深陷抄袭丑闻。
有人留言表示,希望相关单位能够严肃处理这件事情,让相关研究人员退出学术界。
过去30年里,很多人不分昼夜地努力研究,才让韩国能在CV顶会里发表更多论文,而他们的行为却如此过分!

实际上,韩国在CVPR 2022中的成绩确实值得关注,仅首尔大学就有25篇论文入选。
有人直接说,这件事太给韩国丢脸了。
而更为深层的原因还包括,韩国有声音担心,这次事件会是“黄禹锡事件”的二度上演。
2005年,曾任首尔大学兽医学院首席教授、一度被视为韩国民族英雄的黄禹锡,被揭发伪造多项研究成果。其在《Science》上发表的干细胞研究均属子虚乌有。2009年,黄禹锡被判处2年徒刑,缓刑3年。
就在韩国抄袭事件这边还在发酵,IBM也被曝出其入选的CVPR论文涉嫌抄袭。
来自平安科技的研究员,列出了九大证据,涉及方法论、预处理、后期处理、推理、文字行检测与识别等内容,目前已写成邮件发给了CVPR 2022 program chairs。

首先从核心方法论来看,两者都是表格内容识别任务,取名也类似,一个是TableMASTER,一个是TableFormer。
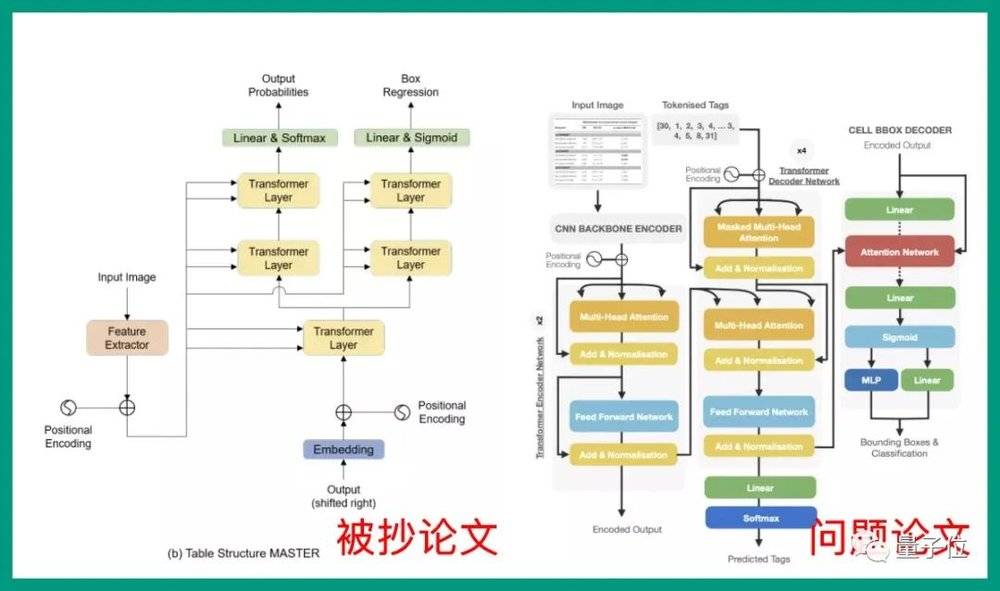
其中,两者的图像输入均为448*448。前者(TableMASTER)训练长度为500,而后者(TableFormer)则改成了512。
爆料者表示,里面很多痕迹都可以看出,IBM是在他们开源的预训练模型上跑的,只是改了些细节。
而最隐晦的也是直呼“最无耻”的,还要属文本单行检测这块,爆料者称:他们只改变了颜色。
一般而言,官方提供的数据中每个表格都是多行的,不利于之后的训练。
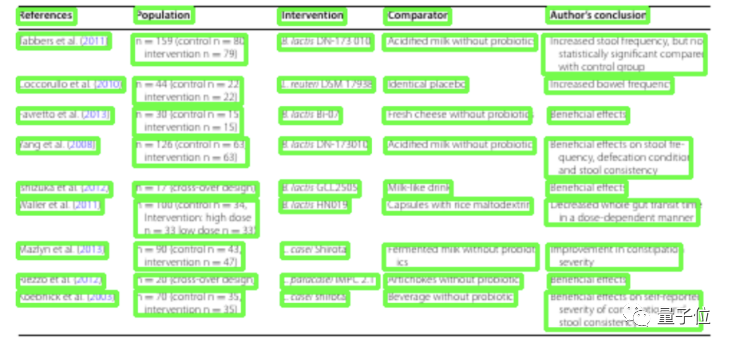
于是,研究团队对3000张图像进行了重标注, 将连在一起的多行拆分成单行。

而IBM的PDF Cells则是直接拿他们在GitHub上训练好的模型进行预测。

除此之外,根据爆料者描述,IBM还将他们的3条规则根据开源的代码,强行拆成9条规则。
目前,IBM方也还没有任何回应。网友也持有各种意见。有人认为,这看起来像个人意见,作者有点情绪化。
还有网友则看完整个证据,很难相信IBM是原创文章,建议直接向CVPR项目委员会投诉。
最后,再来简单回顾一下今年有点魔幻的CVPR。
CVPR 2022投稿量高达8161篇,相比于去年7093分提交增长了15%,其中44.59%的作者来自中国。
其中,共有2064篇论文被接收,接收率为25.28%。在被接收的论文中,有342份被选为Oral。最佳论文颁向了ETH Zurich、华盛顿大学、佐治亚理工学院、捷克理工大学等机构的研究者。而最佳学生论文奖,则是颁给了达摩院的实习生。李飞飞教授获得了本次大会的 Thomas S. Huang纪念奖。
除此之外不得不承认,今年CVPR确实热闹,毕竟有近6000人来到线下参会。
于是乎,另一个魔幻的事情发生了——不少人因此染上新冠。
网友还提问:到底是CVPR接收率高还是感染新冠率高?

参考文献:[1]https://www.reddit.com/r/MachineLearning/comments/vlpnuw/d_ibm_zurich_research_plagiarised_our_paper_and/
[2]https://twitter.com/e2v_sde_parody/status/1540087877308239874
[3]https://arxiv.org/pdf/2105.01848.pdf
[4]https://arxiv.org/pdf/2203.01017.pdf
[5]https://www.youtube.com/watch?v=UCmkpLduptU&t=95s
[6]https://www.fmkorea.com/4760102853
[7]https://www.zhihu.com/question/539432448/answer/2543861341
[8]https://www.hankyung.com/society/article/2022062674031
[9]https://www.reddit.com/r/MachineLearning/comments/vjkssf/d_how_to_copy_text_from_more_than_10_previously/
本文来自微信公众号:量子位 (ID:QbitAI),作者:杨净、明敏

