




2022-09-14 17:27

扫码打开虎嗅APP


本文来自微信公众号:电厂 (ID:wonder-capsule),作者:汤一涛,编辑:高宇雷,原文标题:《电厂丨社交网络刷屏的AI作画,它来自达利和WALL · E》,题图来自 AI 作画程序 Midjourney,本文作者输入“Do Androids Dream of Electric Sheep?”(仿生人会梦见电子羊吗?)后自动生成
但凡你每天要花半小时在社交网络上,那在过去的几个月里,一定已经被DALL·E 2刷屏了。或许对这个名字有点陌生,但你一定知道AI作画——输入任何文字,AI模型就能为你生成一幅画作。
DALL·E 2是人工智能公司OpenAI推出的第二代图像生成模型。它的名字来自于艺术家萨尔瓦多·达利(Salvador Dali)和皮克斯同名电影中的机器人瓦力(WALL·E)。根据Open AI的说法,DALL·E 2有35亿个参数,虽然比上一代模型120亿参数的模型要小,但它的分辨率是上一代的4倍。
更为关键的是,从艺术史上最有名的画作,到超写实的图片和3D作品,DALL·E 2都呈现出了惊人的效果,以及远超人类艺术家的效率。通常,DALL·E 2可以在30秒内就生成一幅画作,而人类画师花费的时间,则是以小时计算。

“蒙娜丽莎的天启”|图片来源:DALL·E 2

披头士的经典专辑封面“Abbey Road”中,“四人组”变成了“六人组”|图片来源:Twitter@spetznatz

1980年代的泰迪熊在月球上从事AI研究|图片来源:Twitter@sama
“任何足够先进的科技,都与魔法无异。”这是科幻作家亚瑟·克拉克(Arthur Clark)广为流传的一句名言。每当科技界有什么新动向,这句话都会反复被人提及,迪士尼乐园和初代iPhone都属此列。
但理智告诉我们,这个世界不存在魔法。这句话隐含的另一层意思是,任何足够先进的科技,背后都下了无数笨拙的苦工,DALL·E 2也是如此。
DALL·E 2是如何工作的?
本质上,DALL·E 2就是一个将文本处理成可视化信息的工具。它不理解达芬奇是谁,梦娜丽莎是怎样一幅伟大的画作,或者画面的透视关系是怎样的,但它学习了6.5亿张图片,由此形成了一定程度的“预测”,“假装”自己完成了一幅画作。
其中的关键是,如何将文本和图像联系起来。OpenAI使用了他们的另一个模型CLIP(语言-图像对比预训练)。
通过数以亿计的图像和相关标题的训练,CLIP学习了给定的文本与图像的关联程度。在过往计算机视觉的神经网络中,常见的方法是将大量图像数据集合在一起,然后手动标记类别。CLIP的聪明之处在于,它关注的是文本与图像的关联程度,这种对比性而非预测性的方法,使得模型能够更精确地理解语言之间的区别,而不需要依赖人类的决策。
训练结束后,CLIP模型被冻结,DALL·E 2进入下一个任务——学习反转CLIP刚刚生成的图像编码映射。因为我们的目的在于生成图像,这就需要DALL·E 2有一定的“创造性”,而不是机械的给出已经学习过的图片中的一张。
OpenAI使用了另一个模型GLIDE来实现这个目的。GLIDE的是扩散模型的一种。扩散模型会随机将一张图片的像素打乱,直至形成一张纯噪声的图片。然后再逐步改变其像素来降低噪声,从而回到原始图像。
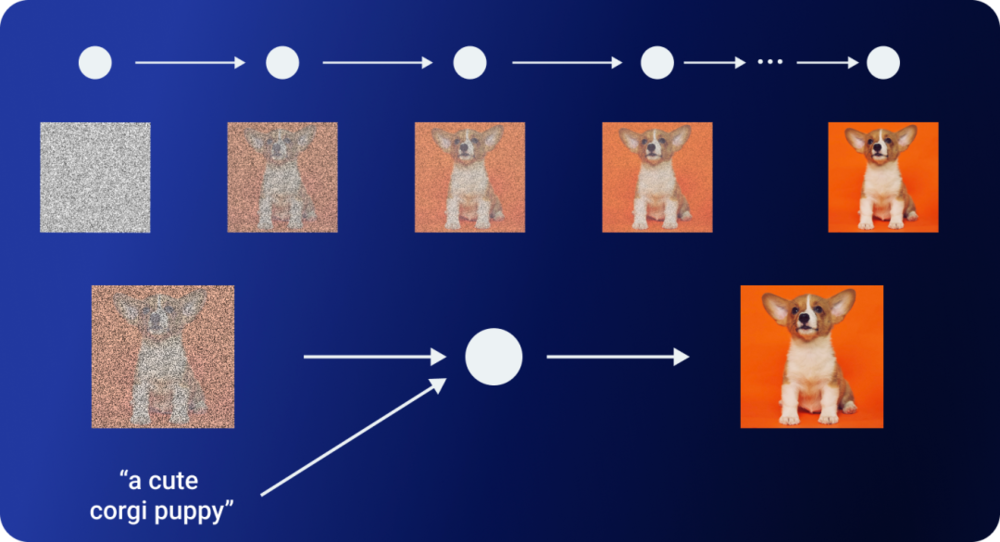
GLIDE生成过程|图片来源:Aditya Singh
由于反向扩散过程是随机的,因此我们很容易得到一张和原图相似却又有所区别的图片。GLIDE扩展了扩散模型的概念,通过增加额外的文本信息,最终产出定向条件的图像。
这也为DALL·E 2增加了一个重要的特性,就是生成的图像是可编辑的,包括元素的位置;增加或删除元素;调整阴影、反射、颜色、纹理等。例如,如果你想在左图中增加一只柯基,只需要向DALL·E 2描述这只柯基的位置——“在那个男人的右边增加一只柯基”,就可以得到右图。

图片来源:dpreview
当然,实际的技术过程要比上述的介绍复杂得多,但简单总结来说,DALL·E 2从文字生成图像的过程可以分为以下几个步骤:
1. CLIP文本编码器将文本映射到表示空间;
2. 扩散模型将文本编码映射到图像编码;
3. GLIDE模型通过反向扩散,从编码从表示空间映射到图像空间,传达文本的语义信息,生成图像。
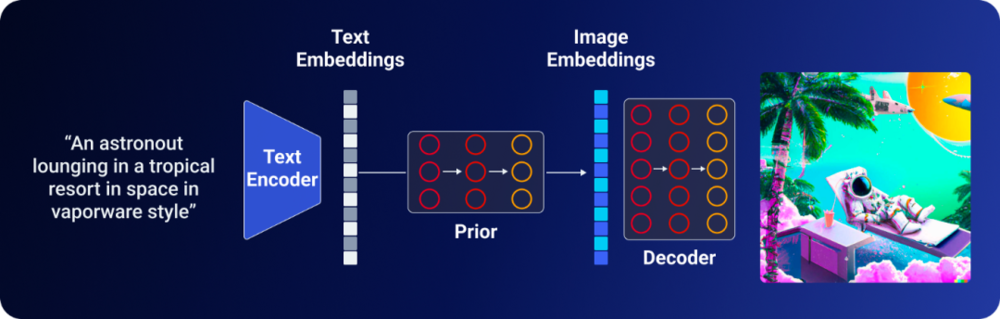
DALL·E 2图像生成过程|图片来源:Aditya Singh
画作水平取决于你的使用方式
长期以来,人工智能的另一个名字就是“人工智障”。DALL·E 2已经非常出色,但它仍然有一些局限。

上图的10张小狗同样是由DALL·E 2生成的。乍看之下他们与真实的照片几乎没有什么差别,但当你仔细观察时,就会发现这些小狗的比例并不完全正确。例如这张图片中,小狗的前腿太长了,嘴巴很模糊,左耳也有些奇怪。

对于人工智能来说,文本描述地越精确,图像生成的效果就越好。伦敦艺术策展人兼程序员盖伊·帕森斯(Guy Parsons)就写道:“ DALL-E 什么都知道。因此,你知道的术语越多,结果就越详细。”“一只超重的老狗看起来很高兴,因为他的两位狗朋友为它庆祝了生日”显然就比“三只狗”要好得多。

图片来源:OpenAI
帕森斯甚至整理了一本81页的DALL·E 2使用指南,给出了一些实用建议,例如:
1. 借用一些摄影术语,例如“特写”;
2. 形容词很容易影响许多要素,“装饰艺术”就会影响画面风格。年代也会产生相同的效果,像“90年代后期”;
3. 在任何情况下,输入的文本都不能超过400个字符。
小狗的例子可能还只是DALL·E 2犯的一些小错误,但是当涉及到超写实的人类面孔时,DALL·E 2就可能产生一些恐怖的结果。

图片来源:OpenAI
这一定程度上是因为,OpenAI引入了保护机制,以防止DALL·E 2记住真实的人类面孔。DALL-E的产品经理乔安娜·姜(Joanne Jang)表示,公司仍在完善内容规则。OpenAI禁止制作暴力、色情和仇恨内容,以及描绘投票箱和抗议活动的图像,或任何“可能被用于影响政治进程或竞选活动”的图像。
实际上,OpenAI把相当多的精力都放在了AI伦理上。在DALL·E 2发布之前,OpenAI就邀请外部研究人员,检查DALL·E 2的风险和局限。他们发现,DALL·E 2在性别和种族上都存在一定的偏见。

DALL·E 2生成的图片具有职业性别偏见,以及西方特色|图片来源:Aditya Singh
OpenAI的研究员马克·陈(Mark Chen)告诉科技媒体IEEE,OpenAI的一个团队已经开始实验纠正这种偏见。例如,OpenAI在训练过程中,删除了一个男性多于女性的数据集,以增加更多女性形象。
尽管如此,仍然有很多批评者质疑在大量未经管理的数据集上训练模型的做法。独立研究人员维奈·普拉布(Vinay Prabhu)认为,人工智能研究界高估了扩大模型规模的价值。
而随着DALL·E 2新增了100万用户,加州大学伯克利分校的研究人员法里德(Farid)表示,DALL·E 2的滥用其实只是时间问题:“就像类固醇造成的假消息那样(治疗新冠),人们总会想办法绕过规定。”
本文来自微信公众号:电厂 (ID:wonder-capsule),作者:汤一涛,编辑:高宇雷

