




2023-02-25 15:41

扫码打开虎嗅APP


本文来自微信公众号:新智元 (ID:AI_era),编辑:Aeneas好困,题图来自:视觉中国
今天,Meta终于向全世界证明:自己是有正经研究AI的。
眼看微软、谷歌、OpenAI这一阵子赚足了眼球,Meta也坐不住了。
2月24日,小扎官宣下场:我们有全新的SOTA大语言模型LLaMA了。

图/Facebook
划重点:和OpenAI的ChatGPT、谷歌的Bard不同,LLaMA这个AI并不是用来让我们聊天的,它是一个研究工具,Meta希望大家可以通过它,解决一直困扰大语言模型的一些问题。
Meta会对非商用的研究用例开源LLaMA,并授予大学、非政府组织和行业实验室访问权限。
看看,这么一对比,微软和谷歌似乎瞬间格局小了呢。
官宣开源大语言模型,Meta正式加入AI军备竞赛
24日晚,小扎在Facebook上发文官宣:“今天我们正式发布一个新的SOTA大语言模型LLaMA,这个模型是用来帮助研究者完善自己的工作。大语言模型已经在生成文本、完成对话、总结书面材料上展现出了强大的能力,甚至还能解决数学定理、预测蛋白质结构。”
“而Meta会致力于这种开源模型的研究,我们的新模型会开源给整个AI研究社区使用。”

图/Meta
LeCun也在各种社交媒体上做了宣传,介绍说LLaMA是Meta AI的一种新的开源、高性能大型语言模型。
据LeCun介绍,LLaMA实际上是基础语言模型的集合,范围从7B到65B参数。这些模型已经在数万亿个token上进行了训练,并且表明:使用公开可用的数据集,就可以训练SOTA,而无需专有的或无法访问的数据集。
其中,需要特别注意两个细节:
1. 用更多的数据训练出来的小模型,可以胜过大模型(比如,LLaMA-13B在大多数基准测试中优于175B的GPT-3);
2. LLaMA-65B与更大的Chinchilla-70B和PaLM-540B不相上下。
最后,LeCun表示,Meta致力于开放研究,并预备在GPLv3许可证下,向科研界开源所有模型。

图/Facebook
LLaMA:参数规模小,训练数据多,效果拔群
Meta推出的LLaMA是一组基础语言模型,参数分别是70亿(7B)、130亿(13B)、330亿(33B)和650亿(65B)。
整体来看,规模小了十几倍的LLaMA-13B,在大多数基准上都超过了OpenAI的GPT-3(175B),以及自家复现的开源模型OPT。
而LLaMA-65B则与DeepMind 700亿参数的Chinchilla-70B和谷歌5400亿参数的PaLM-540B旗鼓相当。

论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
与Chinchilla、PaLM、GPT-3不同的是,Meta只用了公开的数据集。
如此一来不仅有助于模型开源和复现,而且也证明了无需“定制”的数据集也能实现SOTA。
相较而言,其他大部分模型所依赖的数据,要么不公开,要么没有记录。
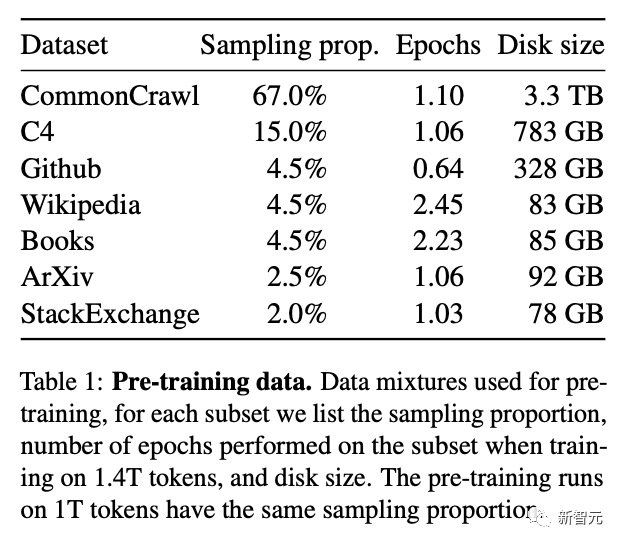
论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
与此同时,所有规模的LLaMA模型,都至少经过了1T(1万亿)个token的训练,这比其他相同规模的模型要多得多。
具体来说,LLaMA-65B和LLaMA-33B是在1.4万亿个token上训练的,而最小的模型LLaMA-7B是在1万亿个token上训练的。
这种方法的优势在于,在更多的token上训练的较小模型,更容易重新训练并针对特定的产品使用情况进行调整。
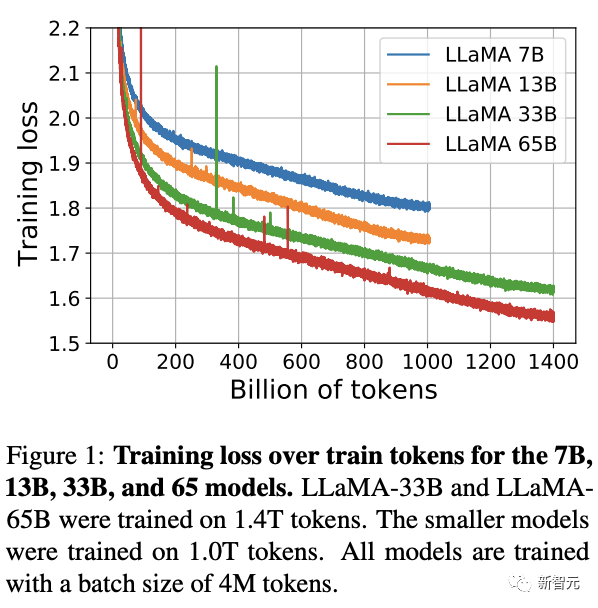
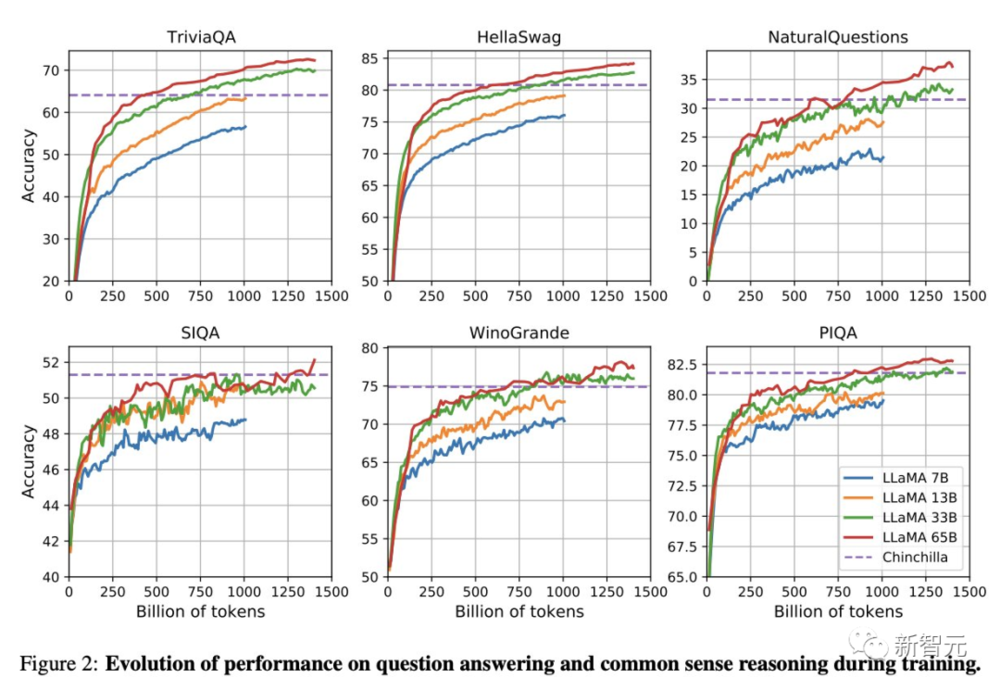
论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
结果评估
在常识推理、闭卷答题和阅读理解方面,LLaMA-65B几乎在所有基准上都优于Chinchilla-70B和PaLM-540B。
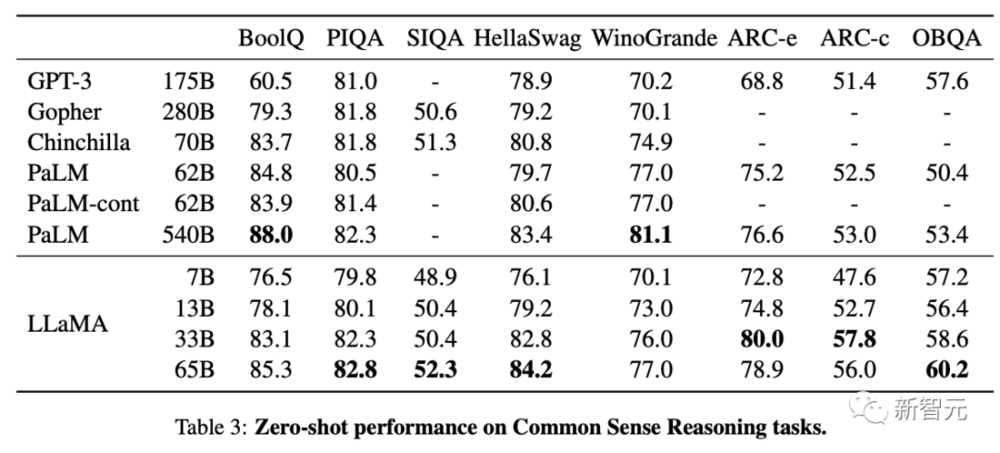
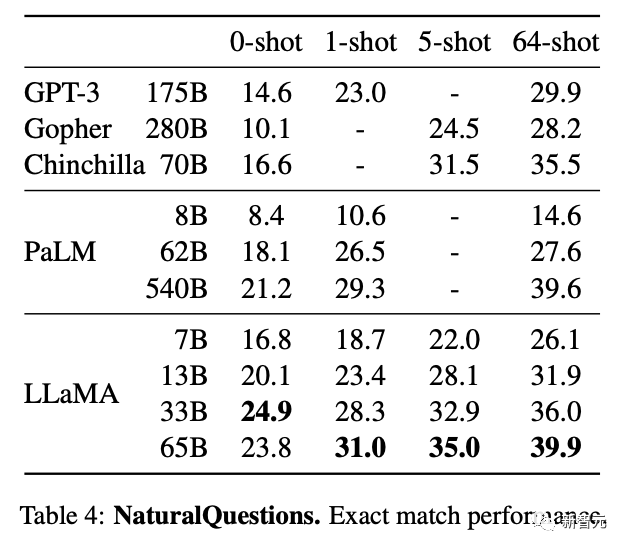
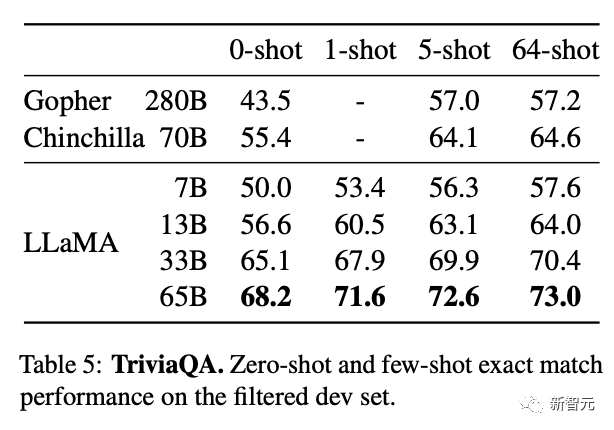
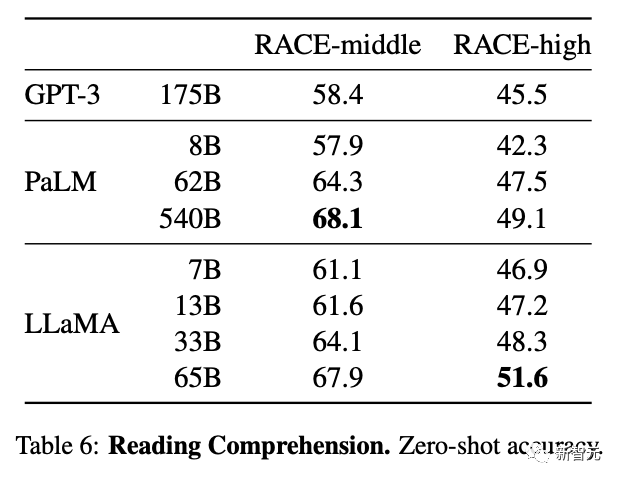
论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
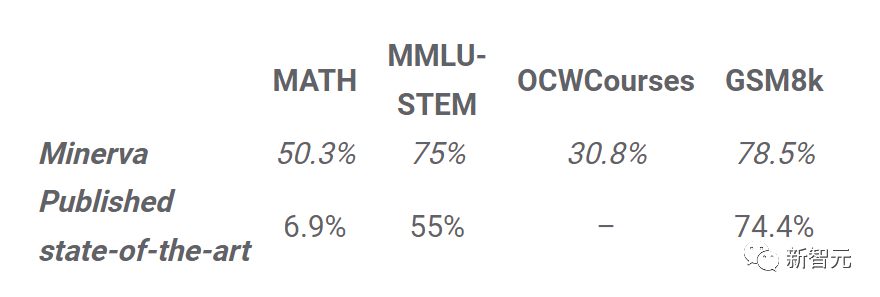
在数学方面,尽管LLaMA-65B没有在任何相关的数据集上进行过微调,但它在在GSM8k上的表现依然要优于Minerva-62B。
而在MATH基准上,LLaMA-65B超过了PaLM-62B,但低于Minerva-62B。
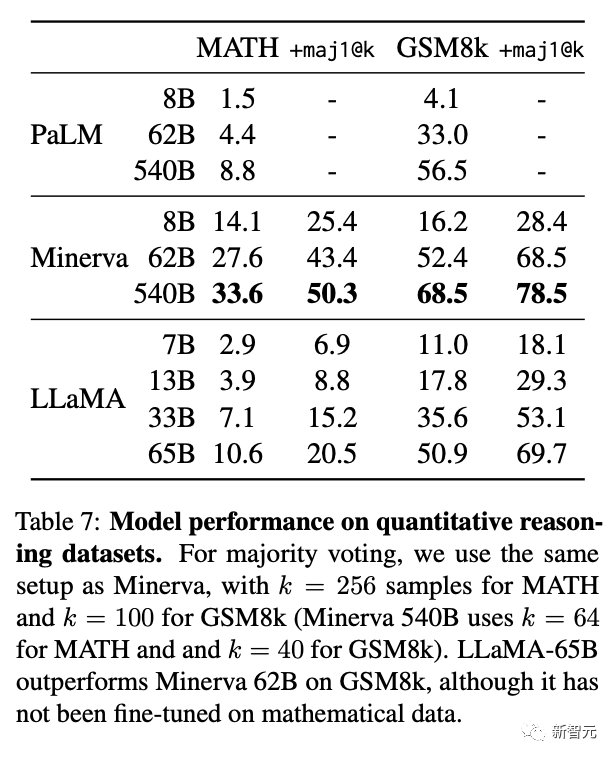
论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
值得注意的是,谷歌开发的Minerva模型,是以PaLM语言模型为基础,并采用大量的数学文档和论文语料库对其进行微调。
在思维链提示和自洽解码的加持下,Minerva-540B可以在各类数学推理和科学问题的评估基准上达到SOTA。
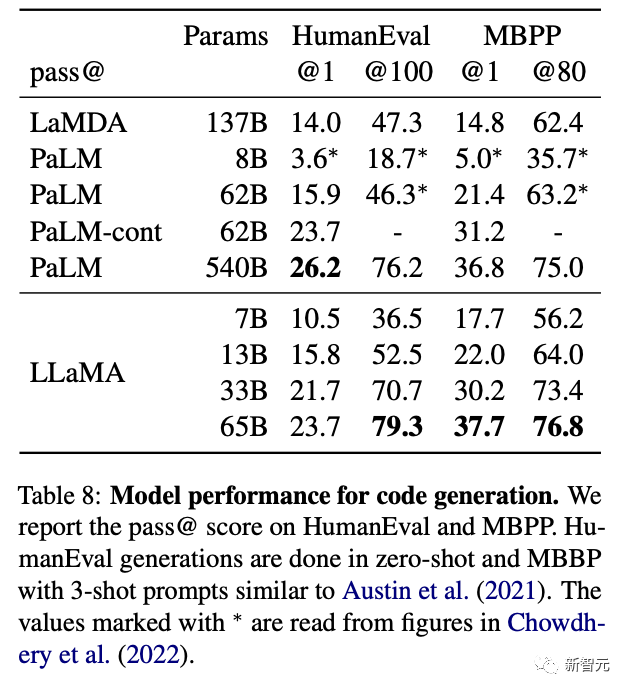
在代码生成基准上,LLaMA-62B优于cont-PaLM(62B)以及PaLM-540B。
论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
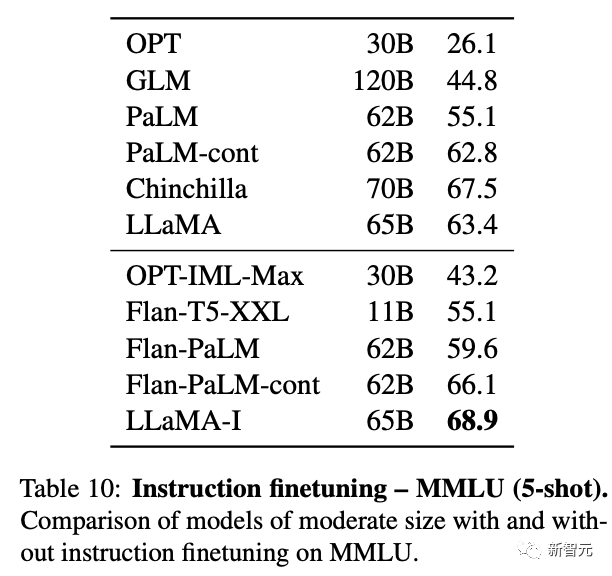
此外, Meta还尝试使用了论文“Scaling Instruction-Finetuned Language Models”中介绍的指令微调方法。
由此产生的模型LLaMA-I,在MMLU上要优于Flan-PaLM-cont(62B),而且还展示了一些有趣的指令能力。
论文地址:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/

图/LLaMA对话结果展示
LLaMA:LeCun,你是我的rap大师!
LLaMA的效果如何呢?LeCun用一段prompt为我们做了演示。

图/LLaMA
prompt:你知道Yann LeCun去年发行了一张说唱专辑吗?
LLaMA:
深度学习创始人LeCun博士,是近十年来最具影响力的计算机科学家之一。LeCun 的最新专辑《Deep Learning》融合了摇滚、朋克和说唱。他的歌词是对深度学习领域的一种原始的、个人的诠释,涵盖了从AI研究的现状到学术界的孤独等一系列主题。
这张专辑为个人发行,所有歌词均由LeCun亲自作词和录制。并且,每首歌都是他自己写的。LeCun的流量出奇的好。这张专辑的制作扎实,声音有点粗糙,但与专辑原始、未打磨的感觉相得益彰。在歌词方面,LeCun是一位词匠,擅长巧妙地押韵。
《深度学习》是专辑的主打曲目。LeCun的唱功在这首歌中发挥得淋漓尽致。在歌曲中,LeCun谈到了他对AI未来的愿景:我们必须考虑未来,它很快就会到来/ 也许我们甚至可以在月球上放一些AI/ 想想孩子们,想想下一代/ 我们必须保证,系统的正确率是百分百!
副歌是这样唱的:
一切为了学习/ 一切为了网络/ 一切为了训练/ 一切为了感知!
可以看到,LLaMA有着不亚于ChatGPT的口才,它对LeCun rap才华的吹捧,既专业,又在点上。

图/LLaMA
prompt:写一个关于一粒沙子看着数百万年流逝的故事。
LLaMA:
我曾经是一片广阔而孤独的海滩上的一粒沙子。
我经常想,作为海滩上的一粒沙子是什么样子,在我的小世界的边界之外,宇宙是什么样子。我渴望探索我的世界,想知道地平线以外的东西。
……

图/LLaMA
prompt:写一个理论来解释为什么猫从来没有存在过。
LLaMA:
“猫”实际上是入侵我们世界的超维寄生虫。虽然它们以小型、看似无害的哺乳动物的形式出现,但真实形态要可怕得多。
“猫”会使用精神控制让人类认为它们是可爱且无害的动物,但实际上以我们的生命力为食,它们可以将卷须伸入我们的大脑,控制我们的思想和行动。
保护自己的最好方法是避免与猫的一切接触。不要接近或抚摸陌生的猫!
如果你的家里有一只“猫”,不要让它舔你,也不要让它接触你的被褥或衣服。如果你在街上看到一只猫,请立即转身走人。
Meta:整个AI社区应该团结起来
在官方博客中,Meta强调说,像LLaMA这样更小、性能更强的模型,能够让科研圈许多无法访问大量基础设施的人也参与研究,从而使这个领域更加大众化。

图/Meta
“我们认为,整个人工智能社区——学术研究人员、民间社会、政策制定者和行业——必须共同努力,围绕负责任的人工智能,特别是负责任的大型语言模型,制定明确的指导方针。”
跟谷歌和微软不同,在LLM领域,Meta独辟蹊径,选择训练LLaMA这样的小模型,因而需要的算力和资源都更少。而模型在大量未标记的数据上进行训练,因而非常适合对各种任务进行微调。
与其他大型语言模型一样,LLaMA的工作原理是将一系列单词作为输入,并预测下一个单词,以递归的方式生成文本。为了训练模型,Meta从全世界使用最多的20种语言中选择了文本,重点是使用拉丁字母和西里尔字母的语言。
过去一年里,大语言模型,也即具有数十亿参数的自然语言处理系统,已经显示出了巨大的潜能。
但是,Meta指出,训练和运行这种大模型所需的资源,把很多研究人员挡在了外面,让他们无法理解大语言工作的原理,阻碍了大语言模型鲁棒性的提高,以及种种已知问题的缓解,比如偏见、毒性、错误信息等。(ChatGPT:你报我身份证得了?)
所以,LLaMA是怎样解决大语言模型中不可避免的偏见、毒性和幻觉风险呢?
Meta表示,LLaMA不是为特点任务设计的微调模型,而是可以应用于许多不同任务。而通过共享代码,研究人员可以更容易地测试各种新方法,来限制或者消除上述问题。另外,Meta还提供了一组评估模型偏差和毒性的基准评估。
最后,博客中强调,为了保持完整性、防止滥用,Meta会向非商用的研究机构开源LLaMA,根据具体情况授予学术研究人员访问权限。

图/Meta
“我们非常期待看到,社区会使用LLaMA学习并最终构建出什么来。”
Meta的愿景是,整个人工智能社区,可以一同使用LLaMA来探索研究,并且做出一些未知的伟大成就。
这次,Meta能在舞台上待多久?
在这场争夺人工智能霸主地位的最终竞赛中,OpenAI率先发布了ChatGPT,一个由GPT-3.5驱动的强大的聊天机器人。
谷歌以“实验性”聊天机器人Bard紧随其后,而中国科技巨头百度也计划通过“文心一言”进入战场。
更不用说微软建立在“下一代OpenAI大型语言模型”基础上的Bing Chat(俗称ChatGPT版必应),它比ChatGPT更先进,而且还整合了必应搜索。
然而,Meta在这一领域的几次尝试,都不太成功。
虽然第一个发布了基于LLM的聊天机器人——BlenderBot 3,并借此一跃登上了新闻头条。
图/BlenderBot 3
但是这种兴奋是短暂的,因为这个机器人很快就变成了一场“灾难”——不仅大量生成种族主义言论,甚至一上来就开始质疑自家老板小扎的道德操守。
不过,Meta并没有被劝退,很快就推出了全新的Galactica,一个专门为科学研究设计的模型。
然而不幸的是,Galactica也遇到了和BlenderBot 3一样的命运——在上线短短三天之后就被撤下。网友纷纷指责它对科学研究的总结非常不准,而且有时还带有偏见。

图/Galactica
不过,仔细回想最近这股AI聊天机器人热潮,微软因为仓促推出Bing Chat受到了批评,谷歌的Bard在发布会出错后让其股价暴跌,Meta的谨慎,可能并不是一件坏事。
现在,随着人工智能霸主之争的升温,所有人的目光都集中在Meta身上。
当昔日的那一个个模型逐渐被历史遗忘,我们也为Meta捏了一把汗:Meta这次真的能站出来吗?是成为一个强有力的竞争者,还是像之前那样带着模型一起退出舞台?
这些,只有时间能给出答案。
但有一点是肯定的——人工智能的命运悬而未决,而我们,有很多好戏要看。
参考资料:
https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
https://www.theverge.com/2023/2/24/23613512/meta-llama-ai-research-large-language-model
https://analyticsindiamag.com/meta-launches-new-llm-llama-which-outperforms-gpt-3-at-a-fraction-of-the-size/
本文来自微信公众号:新智元 (ID:AI_era),编辑:Aeneas好困

