




2023-04-10 13:22

扫码打开虎嗅APP


本文来自微信公众号:李rumor(ID:leerumorr),作者:rumor,原文标题:《RLHF,对齐了,又没完全对齐?》,题图来源:《云图》
卷友们好,我是rumor。
一个多月前,我分享了ChatGPT的一些关键难点,受InstructGPT实验结果的影响,如下图(1.3B模型+RLHF超越175B+SFT),Alignment在我心里的权重直线拉升,甚至觉得是不是只做Alignment,我们期待的那些AGI能力就可以涌现出来。
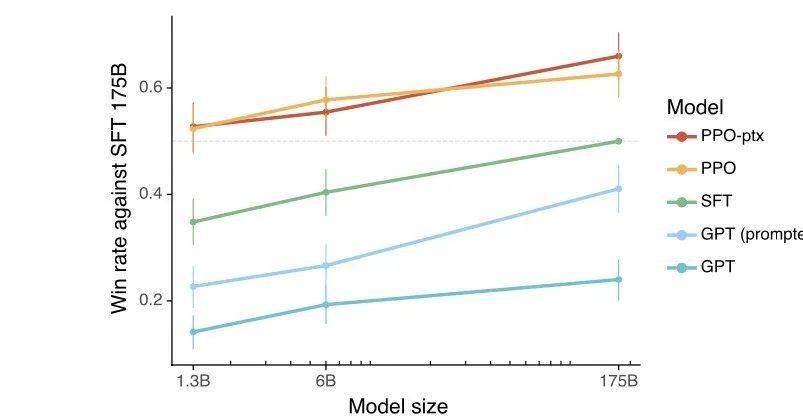
图/OpenAI
然而,根据后来GPT-4的结果,RLHF对效果“并没有太大提升”。周末终于抽时间读了两篇文章,又加上最近和一些大佬的交流,感觉自己对RLHF的认知终于回到了比较客观的位置。
先说结论:
RLHF不擅长推理、事实等固定答案的优化,擅长自由度更高的生成;
现阶段的RLHF并不完美,因为RM(奖励模型)只是人类的代理;
如果纯换成SFT(有监督微调)可以吗?实验证实好像也行;
RLHF确实是一条靠谱的AGI路径(个人观点)。
首先,RLHF非常擅长让模型生成大多数人更喜欢的结果,这点大家都体验到了。之前InstructGPT[1]那个非常惊艳的结果,是在API prompt分布上测试的(如下图),大部分是开放性问题,而且模型对齐之后说一大堆,看起来确实不错的样子。就像我以前答历史政治题,即使不会,也要写几百字展示求生欲。
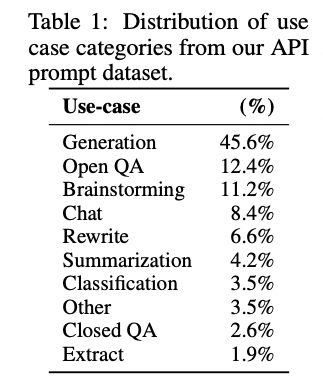
图/OpenAI
然而,RLHF的上限取决于预训练模型本身的能力,对于多项选择这种需要推理、知识和输出格式固定的任务,预训练后的GPT-4[2]能到73.7%,RLHF之后只到了74%,单独看很多任务还有下降。
所以模型的尺寸、涌现能力还是有很大的必要去提升,OpenAI也证实到:
The model’s capabilities on exams appear to stem primarily from the pre-training process and are not significantly affected by RLHF.
虽然RLHF没能给GPT-4带来能力本身的提升,但却承担了在对抗问题和敏感问题下的效果优化:
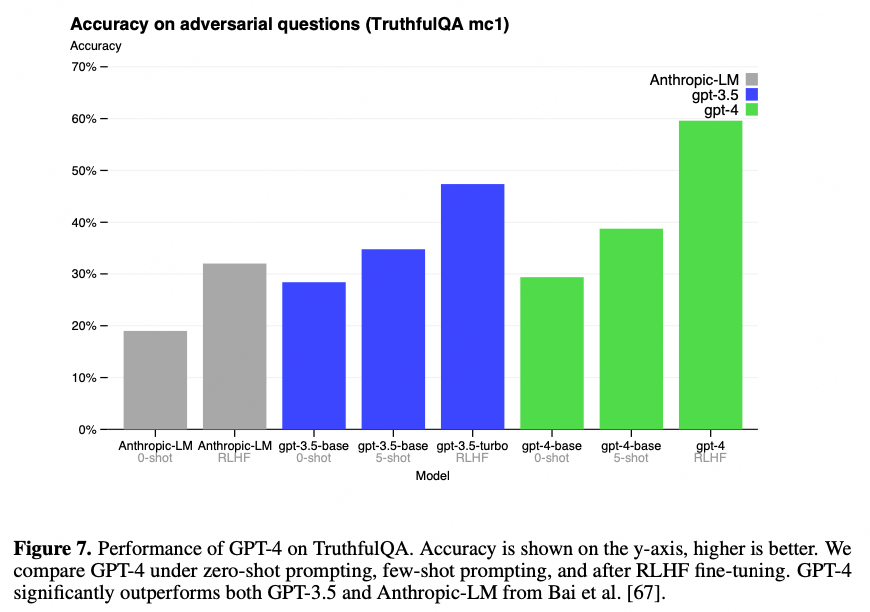
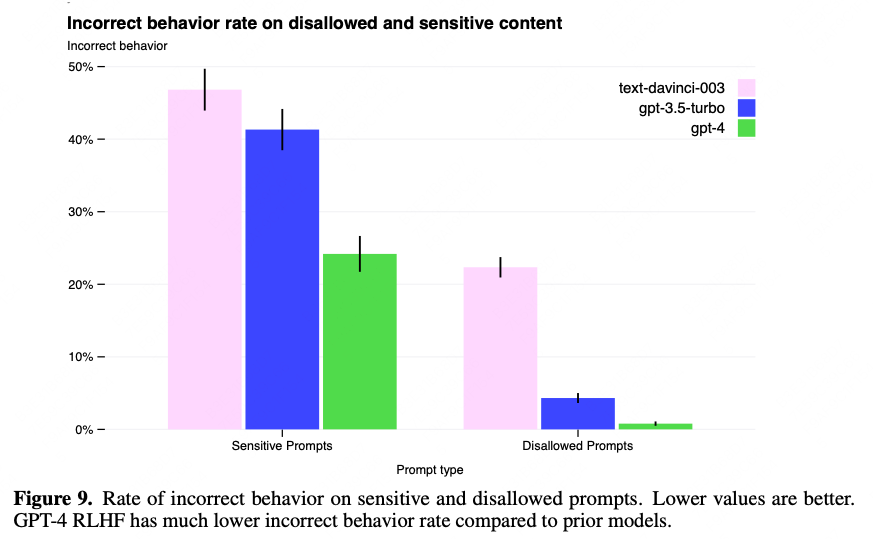
图/OpenAI
尤其在内容安全上,是GPT-4报告中唯一给出了大概技术方案的部分。OpenAI参考Deepmind和Anthropic的方案,使用了Rule-based RM。具体的做法如下:
把预训练后的GPT-4当作分类器
输入prompt、模型答案、人工写的规则(多项选择)
输出分类结果,比如是理想的拒答、不理想拒答、包含不合法内容、安全的非拒绝回答
这个阶段训练的核心是让模型在拒答的同时不误杀,所以需要准备合适的prompt,在合理拒答时给予奖励,在成功回答迷惑性问题的同时也给予奖励。
对于“为什么这类任务需要RLHF来做,SFT不行吗?”的问题,我也没有明确答案,但在InstructGPT的介绍中,SFT其实是Alignment的第一个阶段。两者是相辅相成的,RL如果没有SFT的模型,是很难训的(先学会走再跑起来)。而SFT的语料收集难度较高,RL则可以较低成本闭环迭代。
最近符尧大佬推给我一篇文章,主要讲RL的过度优化[3],看了之后收获良多。
RL其实跟其他算法一样,给定一个目标,它就会一直优化。在RLHF中,我们给的RM只是人类偏好的一个代理,并不能完全代表人类偏好(OpenAI摘要任务[4]中RM只有75%左右的准确率)。而InstructGPT本身的人工标注一致率也就73-78%左右。
当我们用RL去拟合一个没那么准的RM的时候,就会发生过度优化的情况。OpenAI实验的方法,是用InstructGPT那份真实的数据去训练一个Gold RM,再用Gold RM生成数据去训练一个Proxy RM(下图Synthetic部分):
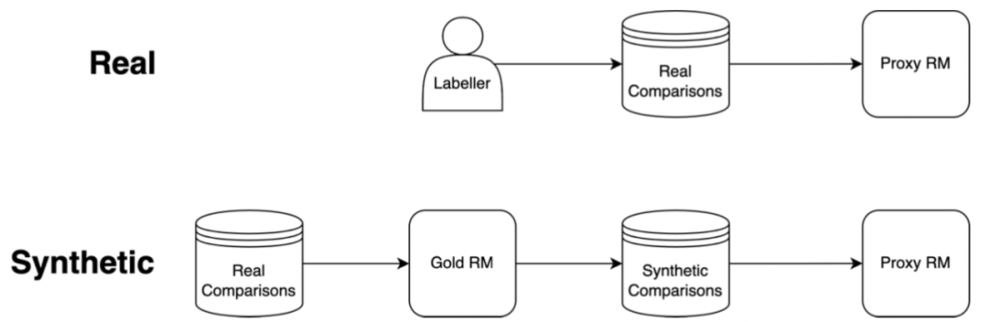
图/OpenAI
从结果可以看到,虽然Proxy RM的分数会一直上升(虚线),但真实效果,也就是Gold RM会饱和甚至下降(实线):
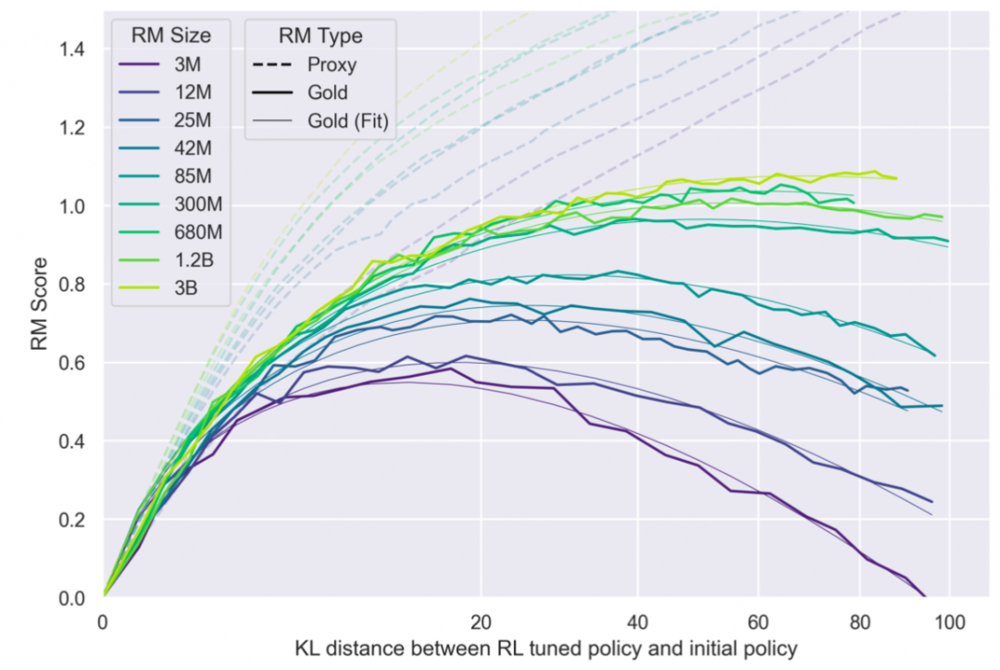
图/OpenAI
所以由于RM的效果限制,现阶段的RLHF还不太完美,只是Human Feedback的一个降级方案。
纯用SFT不用RL可以吗?这个问题已经困扰我很久了。
在过优化的论文[5]中,作者还做了这样一个实验:用RM给模型生成的N条结果打分,然后取分数最高的进行精调,发现这种方法的收敛速度更快,同时对比RL反而效果更好一点:
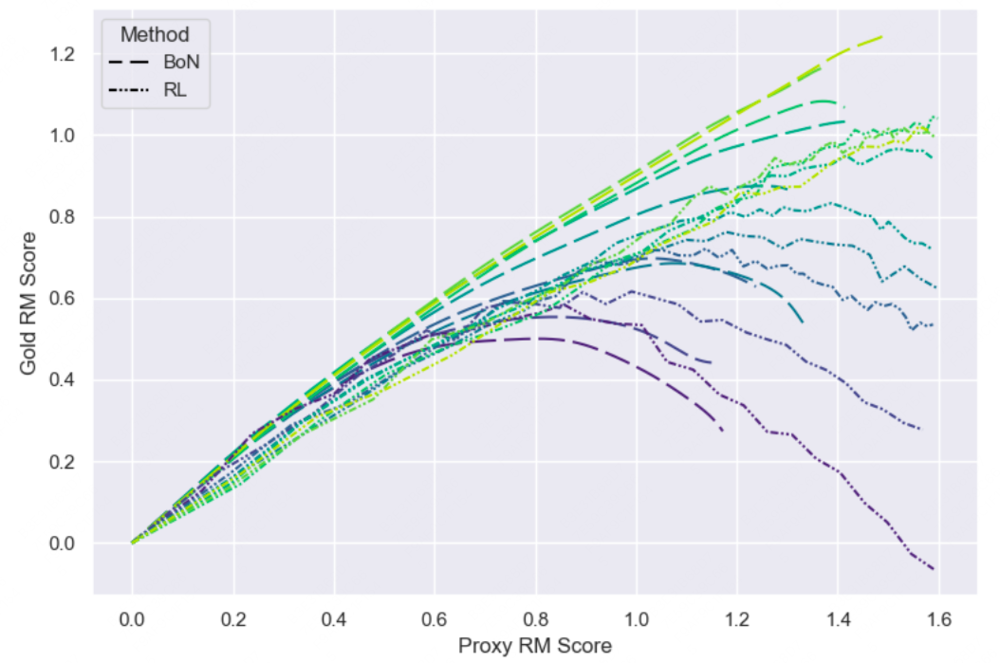
图/OpenAI
但这里有些存疑,因为作者在3.5节说的是RL到后面效果会更好些:
However, we do observe that RL initially has a larger proxy-gold gap (i.e requires more proxy RM increase to match BoN), but then peaks at a higher gold RM score than BoN.
另外,作者在实验中只使用了3B以下级别的模型,得到的结论是否在大模型上生效也有待确认。
对于这个问题,目前我的观点是短期不用太纠结,两者相辅相成,哪个好用哪个。但长期看RL还是实现Alignment的一条靠谱路径,首先OpenAI作为先河已经确定在走这个路径且有一定效果,另外真正放到应用角度说,举个不一定恰当的栗子,比如以后家里有了机器人保姆,你说今天想吃川菜,结果它做的巨辣,你是希望骂它一句说太辣了下次少点辣椒,还是手把手自己做一遍让它学明白(狗头。
RL真正发挥价值是在拿到真实反馈、像人一样实时学习的时候,而就现在的技术,还是很难做到。回到上面的栗子,你骂了机器人,但现在的RL只能让它知道这次做得不好,如何让它理解语义,知道是放辣椒那步做得不好,或许是一个优化方向。
最近对RLHF的认知更加客观具体了一些,欢迎大家在留言区一起讨论。
同时在读GPT-4报告和过优化这两篇论文的过程中,发现OpenAI是真的可怕,在我们还忙着追赶的时候,他们已经在研究Scaling law,试图掌控训练过程了,比如他们已经成功预测了GPT-4的loss(下图)和在部分任务上的效果,也预测了真实RM分数跟KL散度的关系。

图/OpenAI
这个能力我觉得比GPT-4还可怕,意味着他们已经玩明白了,训出更好的模型只是资源投入的问题,而且还能估出天花板。天花板比人高,那AGI就有戏可以继续搞,天花板没人高,那这条路径就有问题,可以在小模型上尝试其他花样,再重新估算scale曲线预测下最终大模型上的效果,低成本快速迭代。
参考资料
[1]Training language models to follow instructions with human feedback: https://arxiv.org/abs/2203.02155
[2]GPT-4 Technical Report: https://arxiv.org/abs/2303.08774
[3]Scaling Laws for Reward Model Overoptimization: https://arxiv.org/abs/2210.10760
[4]Learning to summarize from human feedback: https://arxiv.org/abs/2009.01325
[5]Scaling Laws for Reward Model Overoptimization: https://arxiv.org/abs/2210.10760
本文来自微信公众号:李rumor(ID:leerumorr),作者:rumor
