2023-05-06 08:24


扫码打开虎嗅APP

本文来自微信公众号:爱范儿 (ID:ifanr),原文标题:《Google内部文件首次泄漏:ChatGPT 没有护城河,开源才是大模型未来》,头图来自:视觉中国
昨晚,一篇来自 Google 内部泄露的文件在 SemiAnalysis 博客传播,声称开源 AI 会击败 Google 与 OpenAI,获得最终的胜利。“我们没有护城河,OpenAI 也没有”的观点,引起了热烈讨论。
据彭博社报道,此文作者为 Google 高级软件工程师 Luke Sernau,4 月初在 Google 内部发布后就被分享了数千次。
自称 AI-first 的 Google,近几个月以来一直在经历挫败。
2 月,Google Bard 公开演示失误,市值蒸发千亿。3 月,将 AI 整合进办公场景的 Workspace 发布,却被整合了 GPT-4 的 Copilot 抢尽风头。
在赶潮的过程中,Google 一直显得谨小慎微,未能抢占先机。
在此背后,是 Google CEO 皮查伊倾向渐进式,而不是大刀阔斧的改进产品。部分高管也不听从他的调度,或许是因为,大权压根不在皮查伊手里。
如今,Google 联合创始人拉里·佩奇虽然已经不太插手 Google 内部事务,但他仍然是 Alphabet 的董事会成员,并通过特殊股票控制着公司,近几个月还参加了多场内部 AI 战略会议。
Google 面临的问题,每一个都困难重重:
1. CEO 行事低调, 联合创始人拉里·佩奇通过股权控制着公司;
2. “开发产品但不发布”的谨慎,让 Google 多次失去先机;
3. 更加视觉化、更具交互性的互联网,对 Google 搜索造成威胁;
4. 多款 AI 产品市场表现不佳。
内忧外患之中,Google 被笼罩在类似学术或政府机构的企业文化之下,充斥着官僚主义,高层又总是规避风险。
我们整合翻译了全文,对 Google 来说,开源或许不是压死骆驼的最后一棵稻草,而是它的救命稻草。
核心信息提炼
Google 和 OpenAI 都不会获得竞争的胜利,胜利者会是开源 AI;
开源 AI 用极低成本的高速迭代,已经赶上了 ChatGPT 的实力;
数据质量远比数据数量重要;
与开源 AI 竞争的结果,必然是失败;
比起开源社区需要 Google,Google 更需要开源社区。
Google 没有护城河,OpenAI 也没有
我们一直在关注 OpenAI 的动向,谁会达到下一个里程碑?下一步会是什么?
但不得不承认,我们和 OpenAI 都没有赢得这场竞争,在我们竞争的同时,第三方力量已经取得了优势。
我说的是开源社区。简单地说,他们正在超越我们。我们认为的“重大问题”如今已经得到解决并投入使用。举几个例子:
手机上的 LLM:人们可以在 Pixel 6 上以每秒 5 token 的速度运行基础模型;
可扩展的个人 AI:你可以一个晚上就在笔记本电脑上微调一个个性化 AI;
负责任的发布:这个问题不是“解决了”,而是“消除了”。互联网充满了没有限制的艺术模型,语言模型也要来了;
多模态:当前的多模态 ScienceQA SOTA 在一小时内就能完成训练。
虽然我们的模型在质量方面仍然有优势,但差距正在以惊人的速度缩小。开源模型更快、更可定制、更私密,而且性能更强。他们用 100 美元和 130 亿参数做到了我们使用 1000 万美元和 5400 亿参数下也很难完成的事情。而且他们用的时间只有几周,而不是几个月。这对我们意味着:
我们没有秘密武器。我们最好的方法是向 Google 外的其他人学习并与他们合作,应该优先考虑启用第三方集成。
当有免费、无限制的替代品时,人们不会为受限制的模型付费,我们应该考虑我们真正的价值在哪里。
庞大的模型正在拖慢我们的步伐。从长远来看,最好的模型是可以快速迭代的模型。既然我们知道在参数少于200亿的情况下有什么可能,我们应该更关注小型变体。
开源社区迎来了 LLaMA
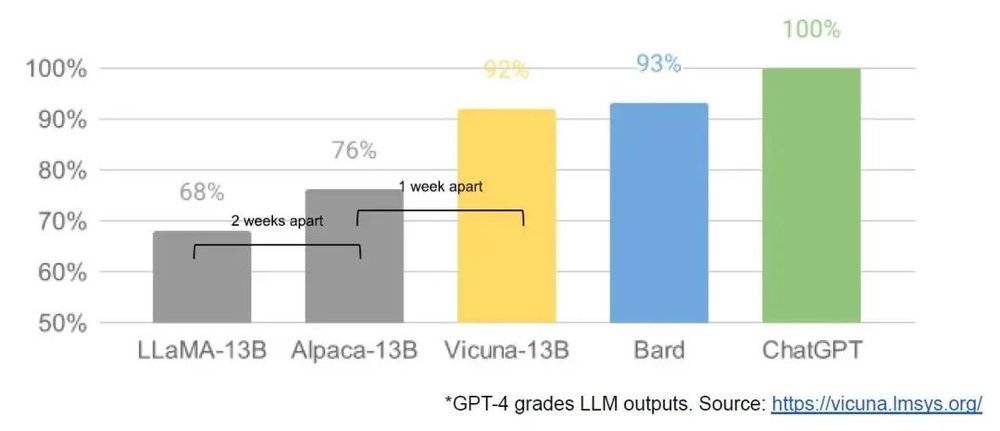
今年 3 月初,开源社区第一次获得了一款真正强大的基础模型,来自 Meta 的 LLaMA。它没有指令或对话调整,也没有强化学习人类反馈(RLHF),但社区依然立即意识到 LLaMA 的重要性。
随后,一个巨大的创新浪潮随之而来,每个重大发展之间只有几天的时间(详见文末时间线)。一个月之后,已经有指令调整(instruction tuning)、量化(quantization)、质量改进(quality improvements)、人类评估(human evals)、多模态、RLHF等功能的变体,其中许多变体是相互依赖的。
最重要的是,他们已经解决了规模问题,让任何人都可以参与其中,许多新的想法来自普通人。实验和训练的门槛从一个大型机构降低到了一个人、一个夜晚或者一台强大的笔记本电脑。
LLM 的 Stable Diffusion 时刻
在很多方面,这对任何人都不该是一个惊喜。当前开源 LLM 的复兴紧随着图像生成的复兴之后。社区没有忽视这种相似之处,许多人将其称之为 LLM 的“Stable Diffusion Moment”。
在两种情况下,低成本的公众参与得以实现,因为有一种称为低秩适应(Low rank adaptation,LoRA)的微调机制大大降低了成本,结合规模方面的重大突破(图像合成的 Latent Diffusion,LLM 的 Chinchilla)。在这两种情况下,开源社区很快超过了大型参与者。
这些贡献在图像生成领域起到了关键作用,使 Stable Diffusion 走上了与 Dall-E 不同的道路。拥有开源模型导致了产品集成、市场、用户界面和创新,在 Dall-E 上并未发生。
这个效果是非常明显的:在影响方面,相对于 OpenAI 的解决方案,Stable Diffusion 迅速占领主导,让前者逐渐变得越来越无关紧要。
LLM 上是否会发生同样的情况还有待观察,但其基本的结构元素是相同的。
Google 本不应该错过
近期开源社区创新的成功直接解决了我们仍在苦苦应对的问题。关注它们的工作可以帮我们避免重复造轮子。
LoRA 是一种我们应该关注的强大的技术。
LoRA 通过将模型更新表示为低秩分解(low-rank factorizations)来工作,将更新矩阵的大小减少了几千倍。这使得模型微调的成本和时间大大降低。在消费级硬件上在几个小时内个性化一个语言模型是一件大事,尤其是对于涉及近乎实时地整合新的、多样化知识的愿景。
这项技术在 Google 内部并未被重视,尽管它直接影响了我们一些最具有雄心壮志的项目。
从头训练模型比不过 LoRA
LoRA 有效的原因在于它的微调是可堆叠的。
例如,指令调整之类的改进可以直接应用,然后在其他贡献者添加对话、推理或工具使用时加以利用。虽然单个微调是低秩(low rank)的,但它们的总和不如此,从而形成全秩(full-rank)更新。
这意味着,随着新的和更好的数据集以及任务变得可用,模型可以廉价地保持更新,而不必支付全面运行的成本。
相比之下,从头开始训练巨型模型不仅丢弃了预训练,还丢弃了已经进行过的迭代更新,在开源世界中,这些改进很快就会占据主导,使得进行全面重训练的成本极高。
我们应该认真考虑新的应用或想法是否真的需要一个全新的模型来实现。如果模型架构的改变使得已训练的模型权重无法直接应用,那么我们应该积极采用蒸馏技术,以尽可能地保留之前训练好的模型权重所带来的能力。
注:模型训练的成果是模型权重文件;蒸馏是一种简化大型模型的方法。
快速迭代,让小模型优于大模型
LoRA 更新对于最受欢迎的模型大小非常便宜(约 100 美元)。这意味着几乎任何人都可以产生并分发一个模型。
不到一天的训练时间是常态,在这种速度下,所有这些微调的累积效果很快就会弥补起始大小的劣势。实际上,从工程师的角度来看,这些模型的改进速度远远超过我们最大的模型,而且最好的模型已经基本上与 ChatGPT 无异。专注于维护一些地球上最大的模型实际上会使我们处于劣势。
数据质量比数据大小更重要
许多项目通过在小而高度精选后的数据集上训练来节省时间。
这表明数据扩展定律具有一定的灵活性。这些数据集的存在遵循了《数据并非你所想(Data Doesn't Do What You Think)》中的思路,并且它们正在迅速成为 Google 外部训练的标准方式。
这些数据集使用合成方法构建(例如,过滤现有模型中的最佳响应)并从其他项目中获取,这两种方法在 Google 中都不占主导地位。幸运的是,这些高质量数据集是开源的,所以可以免费使用。
与开源竞争必定失败
最近的进展对我们的商业策略有直接、即时的影响。如果有一个免费的、高质量、没有限制的替代方案,谁会选择使用有限制且付费的 Google 产品?
而且我们不应该指望能够追赶上来。现代互联网依赖开源,开源有我们无法复制的重要优势。
比起被开源需要,Google 更需要开源
我们很难确保技术机密的保密性。一旦 Google 的研究人员跳槽至其他公司,我们就应该假设其他公司掌握了我们所知道的所有信息。而且,只要有人离职,这个问题就无法得到解决。
如今,保持技术竞争优势更加困难,全世界的研究机构正在相互借鉴,以广度优先的方式探索解决方案空间,远远超出我们自身的能力范围。我们可以试图紧紧抓住机密,但在外部创新会稀释它们的价值,或者我们可以试着互相学习。
与公司相比,个人受许可证的限制更少
许多创新都是基于 Meta 泄露模型的基础上进行的。虽然这肯定会随着真正的开源模型变得更好而改变,但关键是他们不必等待。
法律保护的“个人使用”以及起诉个人的实际困难,意味着在这些技术炙手可热时,人人都可以有使用的机会。
成为自己的客户,意味着了解使用案例
在浏览人们使用图像生成领域创建的模型时,可以看到大量创意的涌现,从动漫生成器到 HDR 风景图。这些模型是由深度沉浸在其特定子流派中的人们使用和创建的,赋予了我们无法企及的知识深度和共鸣。
拥有生态系统:让开源为 Google 工作
矛盾的是,所有这些中唯一的赢家是 Meta。因为泄露的模型是他们的,所以他们实际上获得了全球大量免费劳动力。由于大多数开源创新是在他们的架构之上进行的,所以没有任何东西能够阻止他们直接将其纳入其产品中。
拥有生态系统的价值不言而喻。Google 本身已经在其开源产品(如 Chrome 和 Android)中成功使用了这种范例。通过拥有创新发生的平台,Google 巩固了自己作为思想领袖和方向指示者的地位,赢得了塑造超越自身的思想的能力。
我们越是严格控制我们的模型,人们就越对开源替代方案感兴趣。Google 和 OpenAI 都倾向于采取防御性的发布模式,以保持对模型使用方式的严格控制。但这种控制只是虚幻,任何想要将 LLM 用于未经授权的目的的人都会选择自由提供的模型。
Google 应该在开源社区确立自己的领导地位,通过合作来引领社区。
这可能意味着采取一些令人不安的步骤,比如发布小型 ULM 变体的模型权重。这必然意味着放弃对我们的模型的某些控制。但这种妥协是不可避免的。我们不能希望同时推动创新和控制它。
OpenAI 们的未来在何方?
这些关于开源的讨论可能会让人感到不公平,因为 OpenAI 目前的政策是封闭的。如果他们不分享,为什么我们要分享呢?但事实是,我们已经通过不断流失的高级研究人员与他们分享了一切。在我们阻止这种流失之前,保密毫无意义。
最终,OpenAI 并不重要。他们在与开源的立场上犯了和我们一样的错误,他们保持优势的能力必然受到质疑。除非他们改变立场,否则开源替代方案最终会替代并超越他们。
至少在这方面,我们可以率先行动。
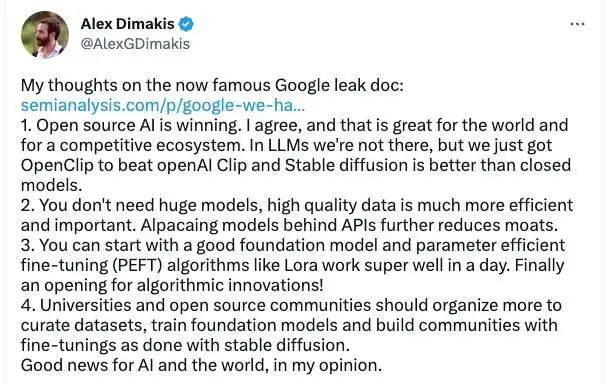
这篇文章在 Twitter 等社交平台上引起了广泛关注,来自德克萨斯大学的教授 Alex Dimakis 的观点得到了不少人的认可:
1. 我同意开源 AI 正在取得胜利的观点,这对世界和竞争激烈的生态系统来说都是好事。虽然在 LLM 领域还没有做到,但我们用 Open Clip 战胜了 OpenAI Clip,Stable Diffusion 确实比封闭模型更好;
2. 你不需要庞大的模型,高质量的数据更加重要,API 背后的羊驼模型进一步削弱了护城河;
3. 从一个拥有良好基础的模型和参数有效微调(PEFT)算法开始,比如 Lora 在一天内就能运行的很好,算法创新的大门终于打开了;
4. 大学和开源社区应该组织更多的精选数据集,用来培训基础模型、并像 Stable Diffusion 那样建立社区。
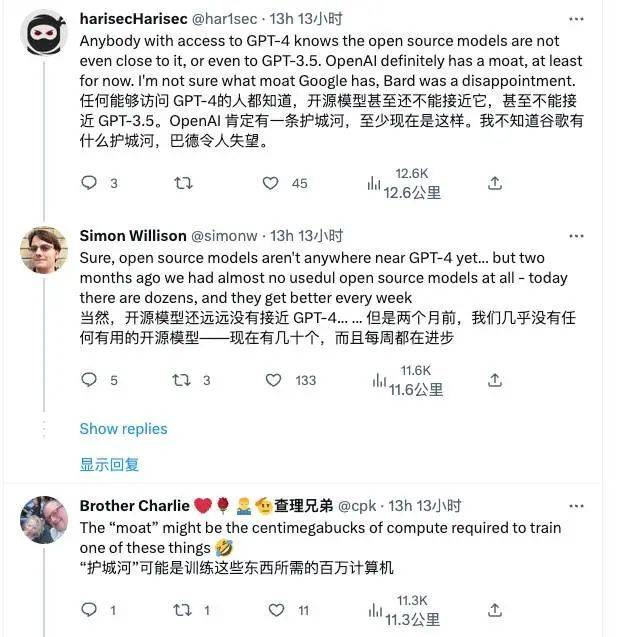
但同时,也有不少人对开源 AI 的能力持怀疑态度,表示它与 ChatGPT 还有一定距离。
但不论如何,开源 AI 降低了每个人参与研究的门槛,我们也期待 Google 能把握住机会,“率先行动”。
本文来自微信公众号:爱范儿 (ID:ifanr),原文链接:https://www.semianalysis.com/p/google-we-have-no-moat-and-neither

 04:07
04:07









 06:21
06:21
 27:05
27:05
 12:49
12:49
 12:03
12:03
 47:13
47:13
 14:40
14:40
 07:13
07:13
 13:10
13:10
 44:45
44:45




