2016-08-01 16:10

知乎联合创始人张亮在值乎上问了俞军老师一个问题:
「以您的使用体验看,您觉得知乎现在最急需做的三到五项产品改进是哪些?」
俞军老师的回答中给的第一个意见就是:
「个性化内容的挖掘和推送,我知道知乎里有大量内容是我感兴趣的,但知乎推送的内容只有很少是我愿意点击的,总让我有种入宝山而空回的感觉,这方面网易云音乐、淘宝、今日头条都是不错的学习对象。」
其实知乎在2013年11月就推出了「开启新版首页动态体验」这个实验室功能,其中的一个feature就是「动态中的内容会根据用户间的关系、用户对话题的兴趣和内容的质量进行调整,不再严格依据时间排序」。
但不知道为什么到现在好像也没有正式启用,而且这个实验室功能还是默认关闭的,需要用户自己手动打开。如果不知道这个功能的朋友们,可以去打开尝试一下,在「设置-实验室」里面勾选即可。

前段时间,Quora的VP Engineering机器学习大牛Xavier Amatriain,在WWW2016大会的Question Answering Workshop做了一个报告,《Machine Learning for Q&A Sites: The Quora Example》[1],我周末学习了一下,分享给大家。
Quora的Mission:To share and grow the world's knowledge。
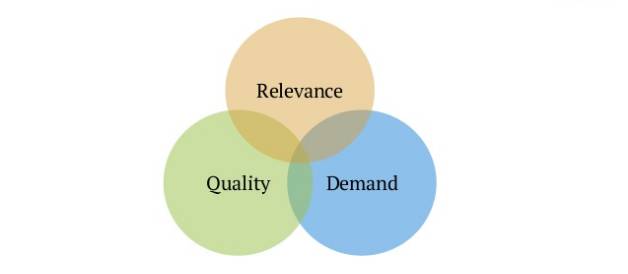
Quora主要考虑的三个因素:Relevance、Quality和Demand。
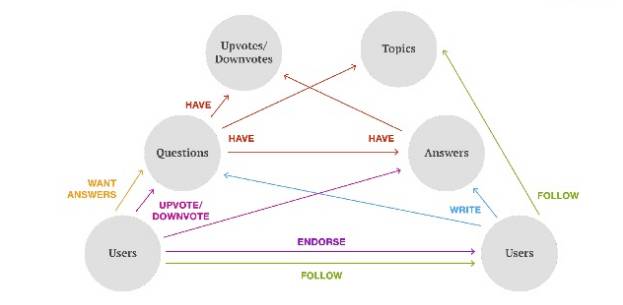
Quora核心的数据模型及其之间的关系。
Feed Ranking
Quora做推荐的一个最核心问题就是Personalized Feed Ranking。Quora是以问题、答案与主题为核心把「知识」串联起来,然后基于用户的顶和踩等动作来划分内容质量,最后再通过人和问题的Follow关系让知识在社区内流动起来。而个人Feed正是这种「流动」的最主要的载体。
Xavier说Quora做Feed Ranking的难度要比Netflix大,这也正常,没有更大的挑战想来Xavier也不会跳槽是吧。Quora Feed Ranking的首要目标是,确保推送进用户Feed的内容应该是和用户兴趣高度相关的,其次还需要考虑的包括用户之间的Follow关系以及互动,Xavier管这个叫做social relevance,另外还有时间因素,比如一些和热点事件相关的问答,也应该及时地推送进用户Feed。
1、目标:Present most interesting stories for a user at a given time
Interesting = topical relevance + social relevance + timeliness
Stories = questions + answers
2、主要使用的是个性化的learning-to-rank方法
3、Xavier确认了一点,相比于时间排序(time-ordered),相关度排序大大提升了用户参与度。
4、面临的挑战:
potentially many candidate stories
real-time ranking
optimize for relevance
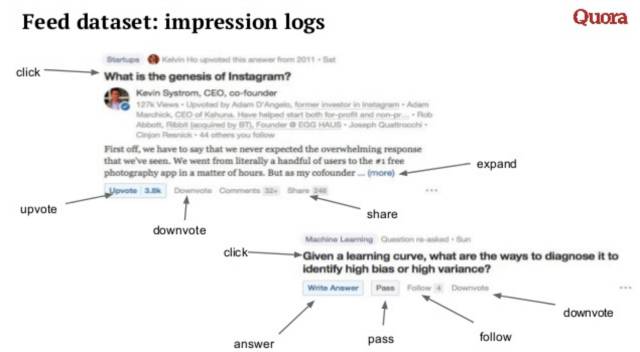
下图是Quora做Feed Ranking最最基础的数据构成,Quora管这个叫做「impression logs」。
围绕这些基础行为,Quora定义的Relevance函数如下:

简单讲就是使用一个「行为加权函数」来预测用户对一个story的感兴趣程度。有两种可选的计算方法,一种是把所有行为弄到一个回归模型里面直接预测最终值,另外一种就是先分别预测每个动作的可能性(比如顶、阅读、分享等),然后再综合起来加权求和。
第一种简单,但可解释性稍差,第二种可以更好的利用每个动作信号,但需要给每个动作配一个分类器,计算消耗大。
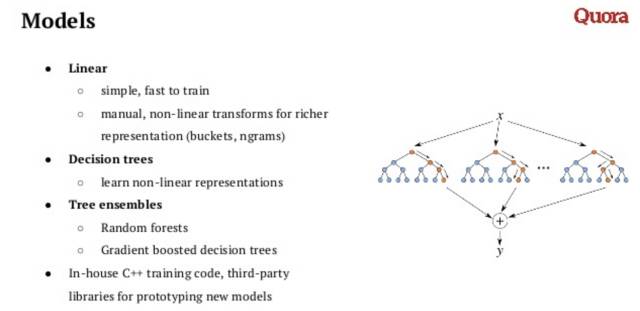
Quora主要使用的三类模型如下:
另外Xavier也强调了特征工程的重要性,在这块下功夫搞一下对最终能得到一个好的ranking结果非常有帮助,如果能够实时在线的更新特征就更好了,这样可以更及时地对用户的行为作出响应。Quora最主要的特征包括:
user (e.g. age, country, recent activity)
story (e.g. popularity, trendiness, quality)
interactions between the two (e.g. topic or author affinity)
从整体框架来看,Quora的Feed Ranking也没有什么太特别的地方,基本上也是业界的标准打法。
Quora比较特别的是它的数据模型相对其他网站更复杂,之间的关系也更多样化。比如从用户角度看,既可以follow其他用户User,又可以follow问题Question,还可以follow主题Topic。
Follow用户接收到的信息范围更广也更多样化,惊喜内容很可能就是来自于自己关注的有趣的用户,但也可能最容易制造不相关的内容噪音,这块的最重要工作是用户专业度的评估。
Question/Answer是Quora最核心的内容元素,也是驱动Quora体系里知识流动的原力,这块的主要工作是引导更多的高专业度用户来贡献优质答案,另外就是如何激发生产出更多的好问题(甚至是自动生成问题),要计算answer ranking,还有要做反sapm的工作。
Topic是对一个主题内容的聚合,Topic在Quora的信息架构里面承载着极其重要的角色,是知识结构的骨架,Quora管这个叫做Topic Network,如何构建Topic Network本身就是一个非常大的挑战,另外还需要解决的问题包括,如何把Topic下(潜在)优质的问题发掘出来,以及如何把水问题降权和过滤/合并重复问题等。
围绕着这些核心问题,Quora分别都进行了更深入的工作。
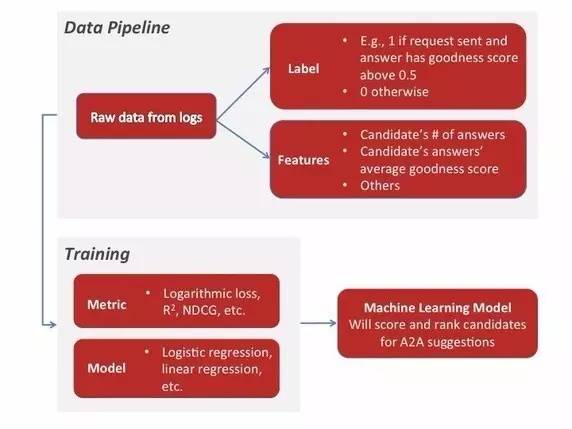
Answer Ranking
Goal:Given a question and n answers, come up with the ideal ranking of those n answers.
Quora主要考虑了下面三大维度来进行Ranking计算,每个大维度下面又包含了很多的features。
答案内容本身的质量度。Quora对什么是「好的答案」有明确的指导[2],比如应该是有事实根据的,有可复用价值的,提供了解释说明的,进行了好的格式排版的等等。
互动,包括顶/踩、评论、分享、收藏、点击等等。
回答者本身的一些特征,比如回答者在问题领域的专业度。
另外这块的工作也包含非个性化的与个性化的两部分,某些类问题的排序是非个性化的,最好的答案对所有用户而言都是一致的,而另外一些问题则是个性化的,对于每个人而言最好的答案会有自己个性化的判断。
总之,Answer Ranking对Quora非常重要,这块Quora做得很细致,Quora的blog上有一篇专门的文章讲这个,有兴趣的朋友可以去看看原文[3]。
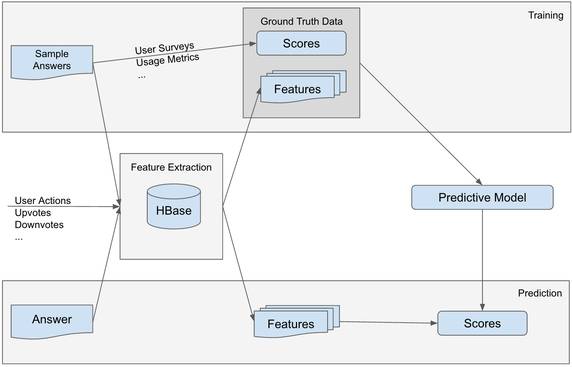
The Answer Ranking system end-to-end
Ask2Answers
A2A是Quora产品里面非常重要的一个功能,本来Quora是可以直接把相关问题推荐给系统认为的合适的回答者的,Quora最开始也是这么做的,但系统自动做这事儿显然不如发动群众人肉邀请回答来得感觉好,A2A操作增强了仪式感,让被邀请者有种被人需要的感觉,心理上很满足。
另外这也是一种社交动作,社交的精髓之一就是为用户制造「装逼」的便利,回答问题前很随意的「谢邀/泻药」,一切尽在不言中了。
这个功能看似很简单,Quora也是下了功夫的,Quora把A2A这事model成了一个机器学习问题:Given a question and a viewer rank all other users based on how 「well-suited」 they are。其中「well-suited」= likelihood of viewer sending a request + likelihood of the candidate adding a good answer,既要考虑浏览用户发送邀请的可能性,又要考虑被邀请者受邀回答的可能性。
Quora的blog上也有一篇文章详细讲解了他们的做法[4]。
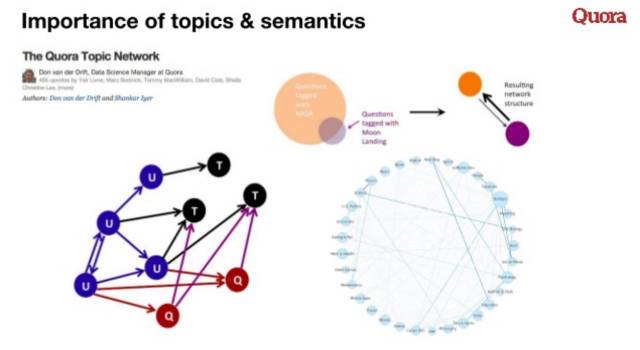
Topic Network
Quora花了很大力气来正确引导用户给内容打标签,持续不断坚持这项工作的好处开始逐渐显露出来了,他们发现[5],
随着用户群体的扩大,Topic正在呈现出迅速多样化的势头。
很多领域都自组织出了相当不错的层级知识结构。
Quora相信这种依靠社群来组织领域知识的方式是可行的。
User Trust/Expertise Inference
这是Quora另一件非常重要的事情,Quora需要找出某个领域的专家,然后通过产品引导这些专家在这个领域里贡献更多的优质答案。Quora会考虑用户在某个领域里回答问题的多少,接收到的顶、踩、感谢、分享、收藏及浏览等数据。
另外还有一个很重要的是专业度的传播效应,比如Xavier在推荐系统领域对某个答案顶了一下,那么这个答案作者在推荐系统领域很可能具备较高的专业度。
其他
其他相关的,包括推荐主题、推荐用户、相关问题、重复问题、反Spam等等,Quora大量地在使用机器学习的方法来解决这些问题。
Quora最大的宝藏,就是这几年在各个领域不断积累下来的大量有价值的内容,Quora自然也少不了对这些的挖掘,有篇《Mapping the Discussion on Quora Over Time through Question Text》[6],就是一个很好的挖掘数据价值的案例。作者陶雯雯,看个人简介是北大元培计划的,妥妥地又一个美女学霸,感觉知乎可以出手了。
Facebook等几个主题随时间的变化情况:
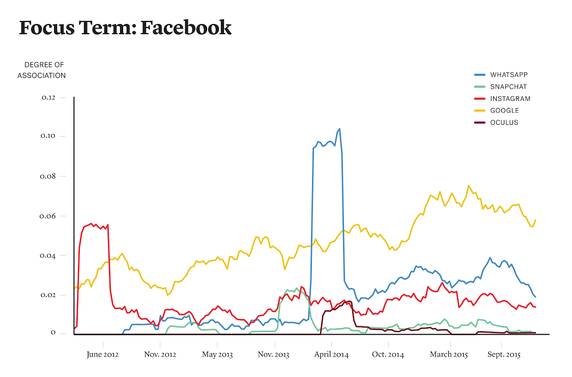
2014年4季度美国的热点主题

参考资料:
[1] http://www.slideshare.net/xamat/machine-learning-for-qa-sites-the-quora-example
[2] https://www.quora.com/What-does-a-good-answer-on-Quora-look-like-What-does-it-mean-to-be-helpful/answer/Quora-Official-Account
[3] https://engineering.quora.com/A-Machine-Learning-Approach-to-Ranking-Answers-on-Quora
[4] https://engineering.quora.com/Ask-To-Answer-as-a-Machine-Learning-Problem
[5] https://data.quora.com/The-Quora-Topic-Network-1
[6] https://data.quora.com/Mapping-the-Discussion-on-Quora-Over-Time-through-Question-Text
微信公众号【ResysChina】,中国专业的个性化推荐技术与产品原创社区。关于动态Feed这个事情,ResysChina之前发过一系列相关文章,Facebook、Pinterest怎么做的都有讲到,关注ResysChina公众号回复「feed」即可查看。
本内容由作者授权发布,观点仅代表作者本人,不代表虎嗅立场。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。
如对本稿件有异议或投诉,请联系 tougao@huxiu.com。