2016-10-24 19:31


扫码打开虎嗅APP

作者:吴攀、李亚洲
几天前,微软语音识别实现了历史性突破,英语的语音转录达到专业速录员水平,机器之心也独家专访了专访微软首席语音科学家黄学东 ,了解到词错率仅 5.9% 背后的「秘密武器」——CNTK。但微软的成果是在英语水平上的,从部分读者留言中我们了解到对汉语语音识别的前沿成果不太了解,这篇文章将向大家介绍国内几家公司在汉语识别上取得的成果。
10 月 19 日,微软的这条消息发布之后在业内引起了极大的关注。语音识别一直是国内外许多科技公司发展的重要技术之一,微软的此次突破是识别能力在英语水平上第一次超越人类。在消息公开之后,百度首席科学家吴恩达就发推恭贺微软在英语语音识别上的突破,同时也让我们回忆起一年前百度在汉语语音识别上的突破。
吴恩达:在 2015 年我们就超越了人类水平的汉语识别;很高兴看到微软在不到一年之后让英语也达到了这一步。
百度 Deep Speech2,汉语语音识别媲美人类
去年 12 月,百度研究院硅谷人工智能实验室(SVAIL)在 arXiv 上发表了一篇论文《Deep Speech 2: End-to-End Speech Recognition in English and Mandarin(Deep Speech 2:端到端的英语和汉语语音识别)》,介绍了百度在语音识别技术的研究成果。
论文摘要:
我们的研究表明一种端到端的深度学习(end-to-end deep learning)方法既可以被用于识别英语语音,也可以被用于识别汉语语音——这是两种差异极大的语言。因为用神经网络完全替代了人工设计组件的流程,端到端学习让我们可以处理包含噪杂环境、口音和不同语言的许多不同的语音。我们的方法的关键是 HPC(高性能计算)技术的应用,这让我们的系统的速度超过了我们之前系统的 7 倍。因为实现了这样的效率,之前需要耗时几周的实验现在几天就能完成。这让我们可以更快速地迭代以确定更先进的架构和算法。这让我们的系统在多种情况下可以在标准数据集基准上达到能与人类转录员媲美的水平。最后,通过在数据中心的 GPU 上使用一种叫做的 Batch Dispatch 的技术,我们表明我们的系统可以并不昂贵地部署在网络上,并且能在为用户提供大规模服务时实现较低的延迟。
论文中提到的 Deep Speech 系统是百度 2014 年宣布的、起初用来改进噪声环境中英语语音识别准确率的系统。在当时发布的博客文章中,百度表示在 2015 年 SVAIL 在改进 Deep Speech 在英语上的表现的同时,也正训练它来转录汉语。
当时,百度首席科学家吴恩达说:「SVAIL 已经证明我们的端到端深度学习方法可被用来识别相当不同的语言。我们方法的关键是对高性能计算技术的使用,相比于去年速度提升了 7 倍。因为这种效率,先前花费两周的实验如今几天内就能完成。这使得我们能够更快地迭代。」
语音识别技术已经发展了十多年的时间,这一领域的传统强者一直是谷歌、亚马逊、苹果和微软这些美国科技巨头——据 TechCrunch 统计,美国至少有 26 家公司在开发语音识别技术。
但是尽管谷歌这些巨头在语音识别技术上的技术积累和先发优势让后来者似乎难望其项背,但因为一些政策和市场方面的原因,这些巨头的语音识别主要偏向于英语,这给百度在汉语领域实现突出表现提供了机会。
作为中国最大的搜索引擎公司,百度收集了大量汉语(尤其是普通话)的音频数据,这给其 Deep Speech 2 技术成果提供了基本的数据优势。
不过有意思的是,百度的 Deep Speech 2 技术主要是在硅谷的人工智能实验室开发的,其研究科学家(名字可见于论文)大多对汉语并不了解或说得并不好。
但这显然并不是问题。
尽管 Deep Speech 2 在汉语上表现非常不错,但其最初实际上并不是为理解汉语训练的。百度美国的人工智能实验室负责人 Adam Coates 说:「我们在英语中开发的这个系统,但因为它是完全深度学习的,基本上是基于数据的,所以我们可以很快地用普通话替代这些数据,从而训练出一个非常强大的普通话引擎。」
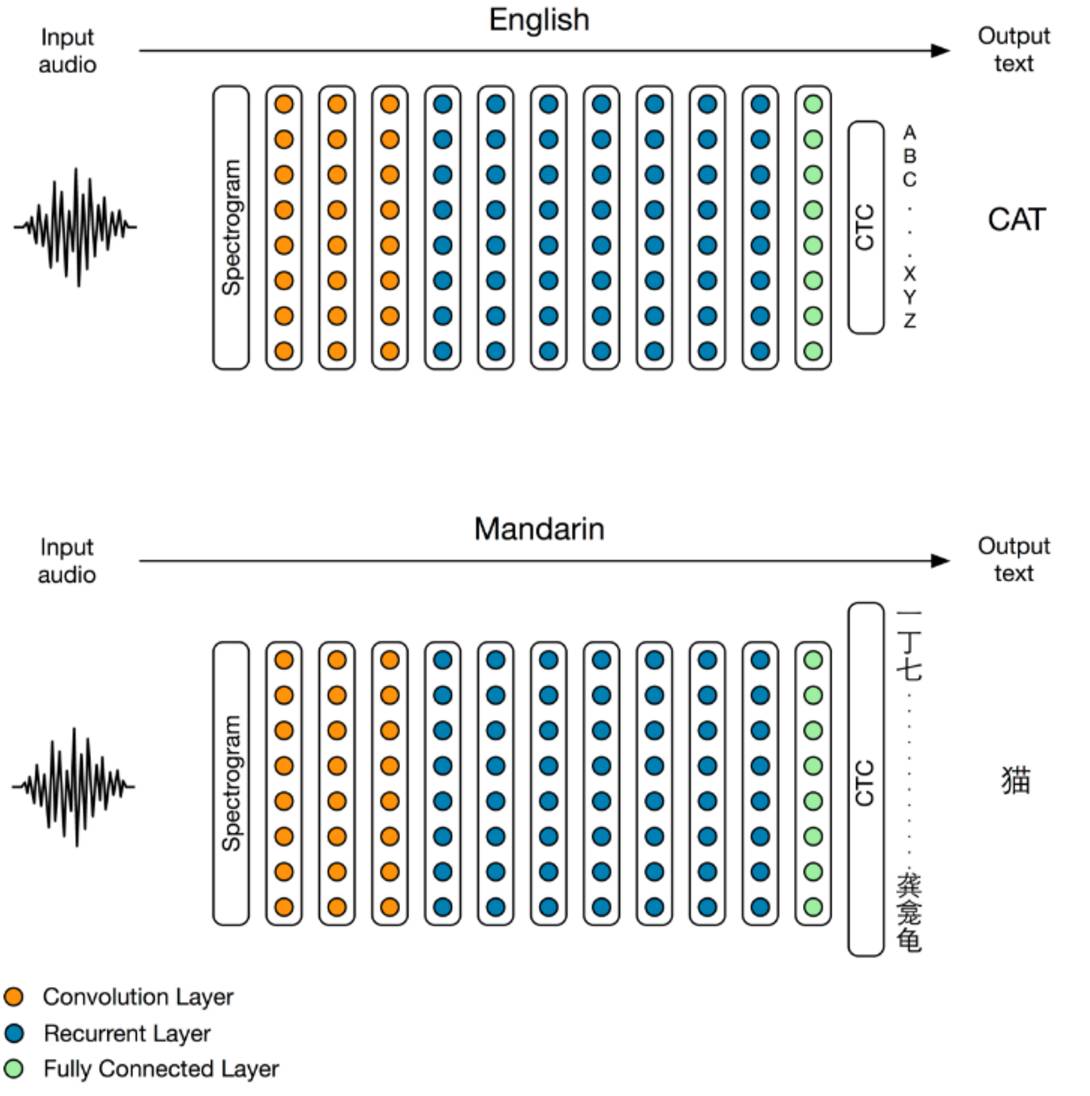
用于英语和普通话的 Deep Speech 2 系统架构,它们之间唯一的不同是:普通话版本的输出层更大(有 6000 多个汉语字符),而英语版本的只有 29 个字符。
该系统能够识别「混合语音(hybrid speech)」——很多普通话说话人会组合性地使用英语和普通话。
在 Deep Speech 2 于 2015 年 12 月首次发布时,首席科学家吴恩达表示其识别的精度已经超越了 Google Speech API、wit.ai、微软的 Bing Speech 和苹果的 Dictation 至少 10 个百分点。
据百度表示,到今年 2 月份时,Deep Speech 2 的短语识别的词错率已经降到了 3.7%!Coates 说 Deep Speech 2 转录某些语音的能力「基本上是超人级的」,能够比普通话母语者更精确地转录较短的查询。
百度在其技术发展上大步迈进,Deep Speech 2 目前已经发展成了什么样还很难说。但一项技术终究要变成产品和服务才能实现价值。
科大讯飞的语音识别
百度的 Deep Speech 识别技术是很惊人,但就像前文所说一项技术终究要变成产品和服务才能实现价值,科大讯飞无疑在这方面是做得最好的公司之一。
科大讯飞在自然语言处理上的成就是有目共睹的,在语音识别上的能力从最初到现在也在不断迭代中。2015 年 9 月底,机器之心对胡郁的一次专访中,他就对科大讯飞语音识别技术的发展路线做过清晰的介绍:
科大讯飞很好地跟随了语音识别的发展历史,深度神经网络由 Geoffrey Hinton 与微软的邓力研究员最先开始做,科大讯飞迅速跟进,成为国内第一个在商用系统里使用深度神经网络的公司。谷歌是最早在全球范围内大规模使用深度神经网络的公司,谷歌的 Voice Search 也在最早开创了用互联网思维做语音识别。在这方面,科大讯飞受到了谷歌的启发,在国内最早把涟漪效应用在了语音识别上面,因此超越了其他平台。
科大讯飞最初使用隐马尔可夫模型,后面开始在互联网上做,2009 年准备发布一个网页 demo,同年 9 月份安卓发布之后开始转型移动互联网,并于 2010 年 5 月发布了一个可以使用的手机上的 demo;2010 年 10 月份发布了语音输入法和语音云。
整个过程中最难的地方在于,当你不知道这件事情是否可行时,你能够证明它可行。美国那些公司就是在做这样的事情。而科大讯飞最先领悟到,并最先在国内做的。
到今年 10 月份刚好过去一年,科大讯飞的语音识别技术在此期间依然推陈出新,不断进步。去年 12 月 21 日,在北京国家会议中心召开的以「AI 复始,万物更新」为主题的年度发布会上,科大讯飞提出了以前馈型序列记忆网络(FSMN, Feed-forward Sequential Memory Network)为代表的新一代语音识别系统。
论文摘要:
在此论文中,我们提出了一种新的神经网络架构,也就是前馈型序列记忆网络(FSMN),在不使用循环前馈的情况下建模时间序列中的 long-term dependency。此次提出的 FSMN 是一个标准的全连接前馈神经网络,在其隐层中配备了一些可学习的记忆块。该记忆块使用一个抽头延时线结构将长语境信息编码进固定大小的表征作为短期记忆机制。我们在数个标准的基准任务上评估了 FSMN,包括语音识别和语言建模。实验结果表明,FSMN 在建模语音或语言这样的序列信号上,极大的超越了卷积循环神经网络,包括 LSTM。此外,由于内在无循环模型架构,FSMN 能更可靠、更快速地学习。
后来通过进一步的研究,在 FSMN 的基础之上,科大讯飞再次推出全新的语音识别框架,将语音识别问题重新定义为「看语谱图」的问题,并通过引入图像识别中主流的深度卷积神经网络(CNN, Convolutional Neural Network)实现了对语谱图的全新解析,同时打破了传统深度语音识别系统对 DNN 和 RNN 等网络结构的依赖,最终将识别准确度提高到了新的高度。
后来,科大讯飞又推出了全新的深度全序列卷积神经网络(Deep Fully Convolutional Neural Network, DFCNN)语音识别框架,使用大量的卷积层直接对整句语音信号进行建模,更好的表达了语音的长时相关性,比学术界和工业界最好的双向 RNN 语音识别系统识别率提升了 15% 以上。
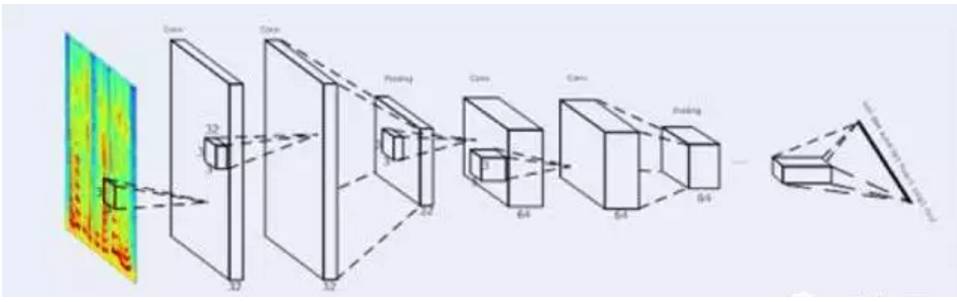
DFCNN 的结构图
DFCNN 的结构如图所 示,DFCNN 直接将一句语音转化成一张图像作为输入,即先对每帧语音进行傅里叶变换,再将时间和频率作为图像的两个维度,然后通过非常多的卷积层和池化(pooling)层的组合,对整句语音进行建模,输出单元直接与最终的识别结果(比如音节或者汉字)相对应。
搜狗语音识别
纵观整个互联网行业,可以说搜狗作为一家技术型公司,在人工智能领域一直依靠实践来获取更多的经验,从而提升产品使用体验。
在前几天的锤子手机新品发布会上罗永浩现场演示了科大讯飞的语音输入之后,一些媒体也对科大讯飞和搜狗的输入法的语音输入功能进行了对比,发现两者在语音识别上都有很不错的表现。比如《齐鲁晚报》的对比结果:
值得一提的是,得益于创新技术,搜狗还拥有强大的离线语音识别引擎,在没有网络支持的情况下依旧可以做到中文语音识别,以日常语速说话,语音识别仍然能够保持较高的准确率。这一点科大讯飞表现也较为优秀,两者可谓旗鼓相当。
整体体验下来,搜狗在普通话和英文的语音输入方面表现,与讯飞相比可以说毫不逊色,精准地识别能力基本可以保证使用者无需进行太多修改。此前在搜狗的知音引擎发布会上,搜狗语音交互技术项目负责人王砚峰称「搜狗知音引擎具备包括端到端的语音识别、强大的智能纠错能力、知识整合使用能力以及多轮对话和复杂语义理解能力」,这些都有效保证了搜狗语音输入在识别速度、精准度、自动纠错、结合上下文语意理解纠错方面收获不错的表现。
八月份,搜狗发布了语音交互引擎——知音,其不仅带来了语音识别准确率和速度的大幅提升,还可以与用户更加自然的交互,支持多轮对话,处理更复杂的用户交互逻辑,等等。知音平台体现出搜狗在人工智能技术领域的长期积累,同时也能从中看出他们的技术基因和产品思维的良好结合。
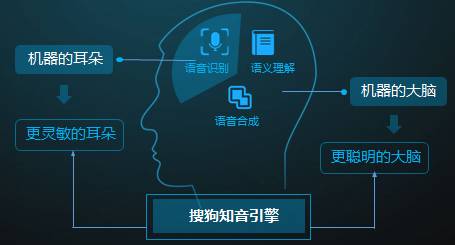
搜狗知音引擎
搜狗把语音识别、语义理解、和知识图谱等技术梳理成「知音交互引擎」,这主要是强调两件事情,一是从语音的角度上让机器听的更加准确,这主要是识别率的提升;另一方面是让机器更自然的听懂,这包括在语义和知识图谱方面的发展,其中包括自然语言理解、多轮对话等技术。
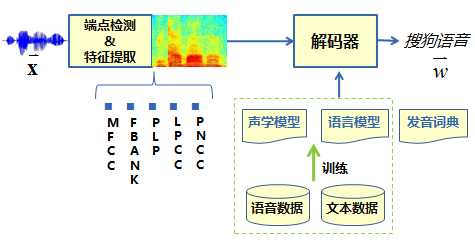
语音识别系统流程:语音信号经过前端信号处理、端点检测等处理后,逐帧提取语音特征,传统的特征类型包括 MFCC、PLP、FBANK 等特征,提取好的特征送至解码器,在声学模型、语言模型以及发音词典的共同指导下,找到最为匹配的词序列作为识别结果输出。
CNN 语音识别系统建模流程
据搜狗上个月的一篇微信公众号文章写道:
在语音及图像识别、自然语言理解等方面,基于多年在深度学习方面的研究,以及搜狗输入法积累的海量数据优势,搜狗语音识别准确率已超 97%,位居第一。
不过遗憾的是,搜狗还尚未公布实现这一结果的相关参数的技术信息,所以我们还不清楚这样的结果是否是在一定的限定条件下实现的。
就像TechCrunch 统计的美国有 26 家公司开发语音识别技术一样,中国同样有一批专注自然语言处理技术的公司,其中云知声、思必驰等创业公司都在业内受到了极大的关注。
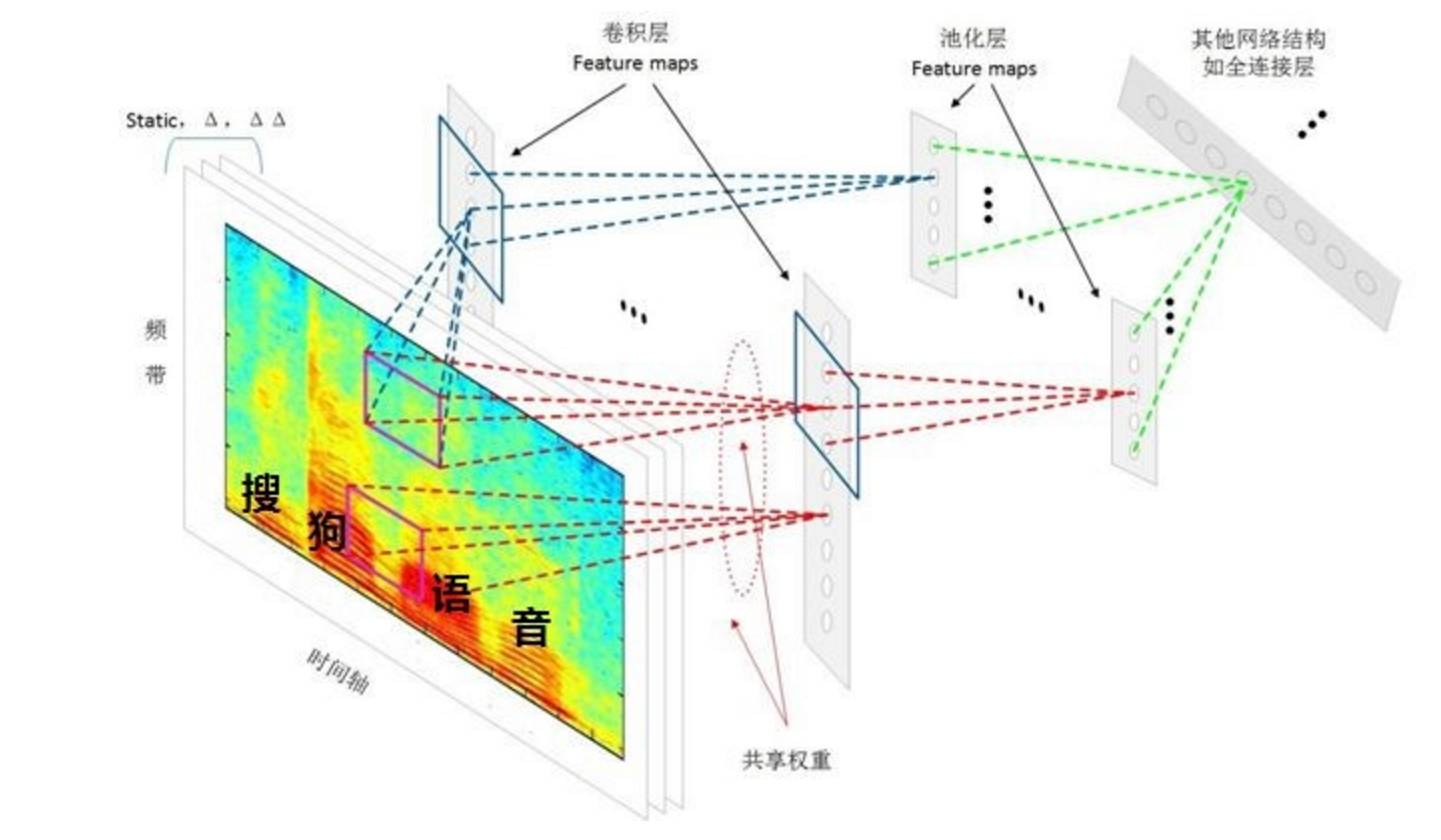
上图展示了云知声端到端的语音识别技术。材料显示,云知声语音识别纯中文的 WER 相对下降了 20%,中英混合的 WER 相对下降了 30%。
在今年 6 月机器之心对云知声 CEO 黄伟(参见:专访云知声CEO黄伟:如何打造人工智能「云端芯」生态闭环)的专访中,黄伟就说过 2012 年年底,他们的深度学习系统将当时的识别准确率从 85% 提升到了 91% 。后来随着云知声不断增加训练数据,如今识别准确率已经能达到 97% ,属于业内一流水平,在噪音和口音等情况下性能也比以前更好。
思必驰的联合创始人兼首席科学家俞凯是剑桥大学语音博士,上海交大教授。他在剑桥大学待了 10 年,做了 5 年的语音识别方面的研究,后来做对话系统的研究。整体上,思必驰做的是语音对话交互技术的整体解决方案,而不是单纯的语音识别解决方案。因此在场景应用中,思必驰的系统和科大讯飞的系统多有比较,可相互媲美。
当然,此领域内还有其他公司的存在。这些公司都在努力加速语音识别技术的提升。语音识别领域依然有一系列的难题需要攻克,就像微软首席语音科学家黄学东接受机器之心专访时所说的那样,「理解语义是人工智能下一个需要攻克的难题,要做好语音识别需要更好的语义理解,这是相辅相成的。」
本文由机器之心原创,转载请联系本公众号获得授权。

 03:11
03:11









 27:58
27:58
 13:10
13:10
 05:44
05:44
 25:27
25:27
 02:03
02:03
 06:21
06:21
 14:05
14:05
 12:03
12:03
 11:57
11:57