
2023-06-21 16:22
AI“疯狂污染中文互联网”,社交平台管不了还是不想管?

扫码打开虎嗅APP

本文来自微信公众号:视智未来(ID:BlockResearch),作者:James,头图来自:视觉中国
这几天,有人发现一个知乎用户“百变人生”疯狂地使用ChatGPT回答问题,回答速度极快,差不多每1、2分钟就能搞定一个问题,甚至能在1分钟之内回答2个问题。这些生成后就从未过人工核查的答案,有些被必应AI抓取,因此形成了误导性的回答。
由此一来,“AI正在疯狂污染中文互联网”就成了一个热门话题。不过,作为一家正在生产环节积极引入AIGC的文娱新媒体,我们娱乐资本论还是想重复那句听起来可能很俗套的观点:
“疯狂污染中文互联网”的不是AI,而是使用AI的人。
很多人看到类似这样的案例,就会自然产生一种要“管管”AI生成内容的冲动。我们对此有些不同看法:
平台层面限制AI生成内容,短期内可能有必要,但长期来看就不一定了。
社交平台并没有真正的技术能力,来自动“预判”和限制AI生成内容。
当AI生成内容有可能“污染”大模型时,模型开发者应该负起更多责任,而不是社交平台。
一、为什么会发生这种事?
从知乎到必应AI,这条神奇的链路是如何形成的?
必应AI是最早一批联网的大语言模型,很久以后才有谷歌的Bard和百度文心一言可以联网。而ChatGPT官方联网功能也是跟必应合作,这使得必应作为一个搜索引擎,对AIGC的意义非常特殊。
但必应本身并不是一个很优秀的搜索引擎。在某些中文问题上,必应的检索能力并不强于百度,可能只是广告相对少一点;相对谷歌,必应则有更大的劣势。
中文互联网更严重的“围墙花园”现象,则让搜索引擎的能力进一步受限。目前已知必应无法读取微信公众号文章,对头条号、百家号等收录也不完整。
必应AI功能刚小范围内测时,甚至在百度官宣“文心一言”之前,知乎就已经是其中文回答里最常见的参考来源。它内容质量相对较高,又不限制搜索引擎的抓取。
通过这种曲折的关系,知乎成为了一个对AI非常特殊的存在——一个“公版”的语料来源。
3-4月起,AI开始在各行各业开始替代人工写作。在各个社交平台上,这种替代的速度是不同的。
在微博、小红书等地,它“入侵”文本内容相对较慢。但知乎和公众号、头条号、百家号等平台,内容以中长篇文字为主,这些地方几乎同步被“入侵”。
甚至,当我就“AI污染中文互联网”在微信“搜一搜”的时候,还可以搜到另一篇明显出自GPT的“评论文章”,整件事情颇为行为艺术。

小红书以及各家短视频平台,则更受困于AI生成图片,及图片堆砌成的视频内容。
对图片的审核及事实核查难度始终高于文本。早在2022年8月,就有关于重庆山火的帖子被人指出“10张图有8张是AI作画,下面评论却一片感动哭了”。
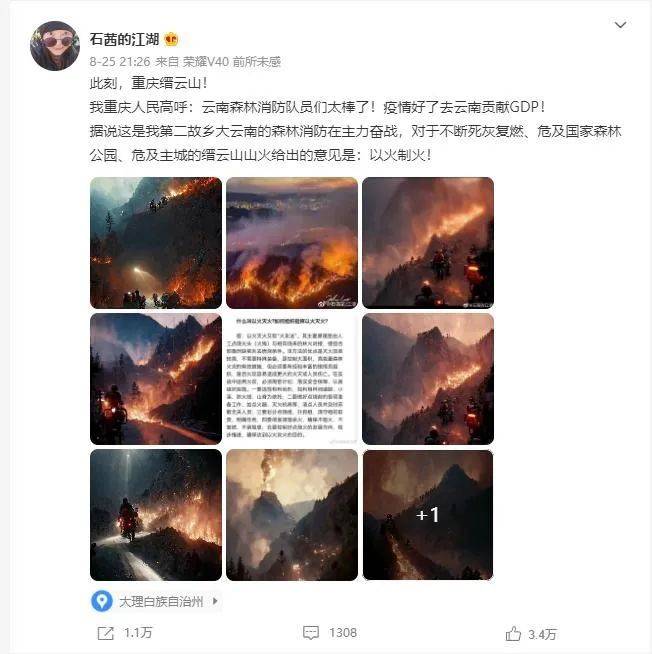
Midjourney对一些知名人士的预训练相当成功,以至于“特朗普被捕”系列“世界名画”引发了强烈反响,其创作者被MJ官方封号。但在国内,“霍金来了都得给领导敬酒”等变种则依然不受限制地继续流传。
以文字为主的社交平台,受到AIGC内容的冲击明显大于以图片、视频为主的平台。
在知乎,虽然“百变人生”已被封禁,但同类情况还很常见,有些回答不标注“包含AI创作”,但一看就有GPT的味道。
这些内容最大的问题并不是枯燥乏味,而是缺乏事实核查,特别是在医学、金融等专业领域,无资质人员的回答很容易形成误导。
此外,“GPT体”的显著特征——按条列出要点,最后来一段总结——实际上会在生成过程中,不断强化对前面写过的答案的“自信”。一旦AI生成内容有遗漏或编造成分,它会在剩下的回答中,致力于让前面的内容变得看起来很可信。
文生图类AI工具受到生成内容的“反向污染”可能性目前还比较小。而对于大语言模型而言,“垃圾进、垃圾出”是一个迫在眉睫的现实威胁。
类似“百变人生”的这种情况,可以在一个非常快的周期内被反馈进去。他关于“(桂林)象鼻山有缆车”的错误回答,仅用不到一个月的工夫,就被抓取和错误地呈现出来了。
如果不能尽快想出对策,类ChatGPT的文本大模型工具,将很快成为一种无用的玩具和摆设,它训练得越努力,生成的东西反而越不可用。
二、AI内容不是新鲜事,但短期只能“一刀切”
ChatGPT火爆已有半年。这段时间里,知乎、抖音、小红书等社交平台都已经发布了限制AI生成内容的规定。总体上它们都是需要发布者对AI生成部分明确标记,以及对缺乏人类介入的纯AI内容严肃查处。例如,抖音禁止没有“中之人”,完全由AI生成问答的直播。
对此,娱乐资本论的观点始终如一:AIGC就像其他任何工具一样。当AI生成内容“污染互联网”的时候,错的不是工具,而是使用工具的人。
自动化生成垃圾内容,并填充到网上的生意古已有之。
针对搜索引擎的优化(SEO)结果,大多数真人都是看不见的,只对机器规则有意义。
10多年前就有打散文章顺序,同义词替换等“伪原创”技术。
稍微动点心思的人工“洗稿”在公众号时代屡禁不止,微信不得不组织一些德高望重的“陪审团”来处理洗稿争议。
ChatGPT等AIGC工具做的事情本质上是一样的。当然这个新“工具”也确实有特别之处,它生成垃圾内容的效率,相比过去可能是10-100倍的提升。ChatGPT对任何使用者一视同仁地“降本增效”,对营销号也不例外。平台反低质内容的斗争变得更艰难了。
其实,ChatGPT生成的内容,如果让人类来评价,还好于传统方法做出的“伪原创”“营销号体”等内容。但是,AIGC却不太可能替代掉以前的垃圾内容,而是两种很差的内容共存,让网络环境更糟糕。
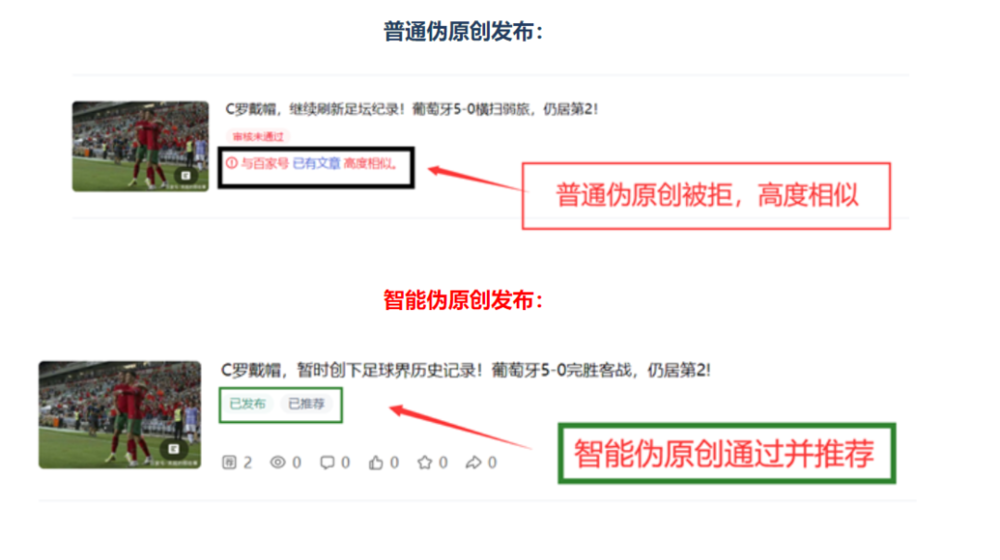
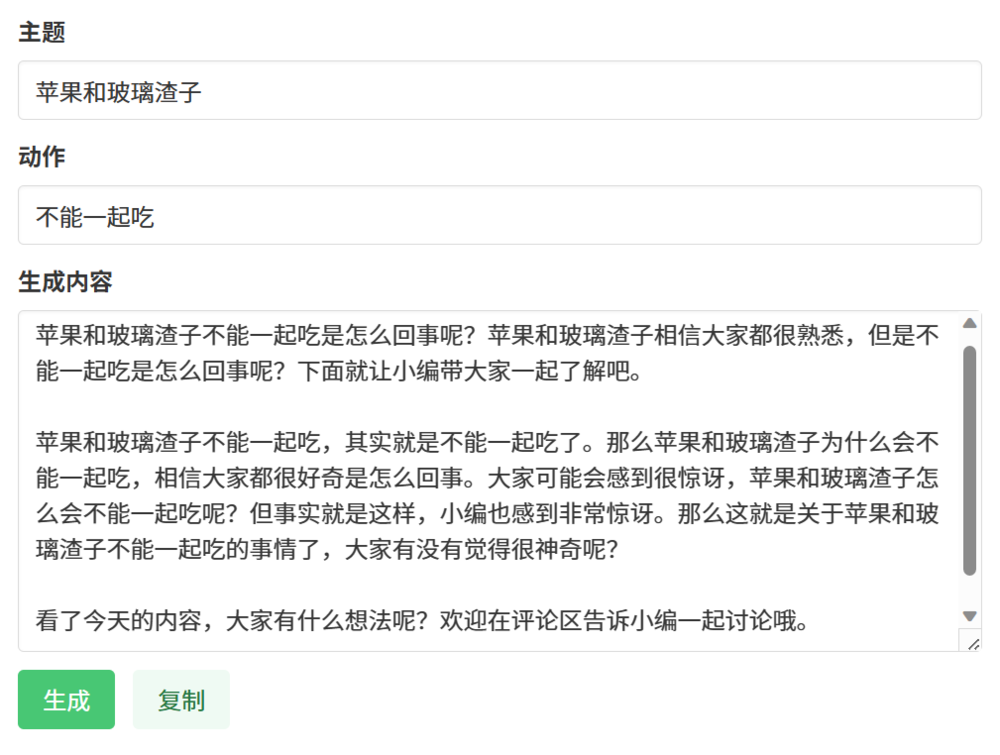
因为AIGC做营销号的爆发比较突然,来势汹汹,短时间内,平台不可避免需要对AI生成的内容“一刀切”。如果找不到根治方法,这些临时措施也很可能会常态化。
但长远来看,平台没有必要对所有AIGC内容始终保持特殊化对待。善用AI的人,是用它来更好发挥自己已有的专业能力。
在“首届上海文娱科创沙龙”上,娱乐资本论创始人吴立湘在《文娱行业的多模态战争》主题演讲中明确提出:
① “由AI生成”并不意味着人类可以“偷工减料” ,从最终结果上看,我们报道的质量和标准和以前没有区别。
② AI不是取代人类,而是解放人类。我们的记者和编辑对AI生成的结果负最终责任,而他们也拥有这些作品的原有权益。
有的人在知乎回答时,先用AI生成基底,但在发布前手动核查事实,对内容负责。这样的回答可能在当前的“一刀切”管理中被误伤。
一旦平台拥有了比较快速、准确的机审方法,可以将一些比较基础的AI生成内容识别出来,并自动处理,那么用AIGC制作的垃圾内容,和用伪原创等工具做的内容,应该平等地被处罚。还是那句话,错的不是工具,而是使用工具的人。
三、识别AIGC内容的技术困难
问题在于,目前的技术手段很难有效判断一段内容是否由AI生成。我们之前对秘塔科技的采访中也提到了这一点。
在计算机领域,有一个常识性的道理——首次生成内容,永远是比二次处理同一条内容更简单的。举例说,将一段话以“中翻英,英翻中,再翻回去”的方法过很多遍机器翻译,它就会变得难以辨认。
即使ChatGPT生成的“GPT体”有人类读者肉眼可见的特征,比如上面提到的“按条列出要点,最后来一段总结”,这种特征也是由人类特有的抽象能力得出的。
对人类来说接近本能的、非常简单的工作,可能对机器来说极其困难。GPT们仅仅是从语料中,统计最有可能接在一个字后面的下一个字,它们不是真的“懂了”某个道理,而是某次生成的内容恰好“瞎猫碰死耗子”地符合了人类的需要而已。
我们可以假设自己是平台的风控人员,想想该怎么抓取和判断AI生成内容:
对于AI生图,可以考虑让国内外的作图工具出图时加水印之类。但Stable Diffusion完全开源,不能号召所有人都这样。
即使如此,AI生成的文字内容也是不可能“加水印”的,而且大模型本身就是一种很好的文本润色工具,将生成内容再过一遍AI,即可大大降低“GPT体”被看出来的概率。
因此,我们只能说现在的平台“有心无力”,因为技术上查处和整治的速度赶不上问题产生的速度。其实如果知乎真的能用机器+人工实现有效的事前监管,就不需要等到这事闹大了。
技术不够,“小管家”们只能事后监管,手动定位被网民举报的用户;而监管也得按照“基本法”,即使“百变人生”被禁言,他的答案还保留着。
在必应AI的回答里,象鼻山现在还是有缆车。
四、大模型开发者应为反“垃圾”负更多责任
如果不解决这个问题,放任AI生成内容被重新投喂到大模型中反刍,结果将引来模型的“崩溃”。意思是,用片面的信息不断自我强化,最终只能生成对人毫无意义的内容。
在牛津大学、剑桥大学的研究人员发布的一篇预印本论文上,讲述了得出这个结论的过程。研究人员的解决方法是,模型开发者应继续保留一部分人工制作的语料,和真人打标签的过程。
但这似乎越来越不容易。在英语世界中,亚马逊的外包服务网站MTurk经常被AI开发者用作标注任务。然而MTurk上的劳动者,现在在做任务的时候也广泛采用AI辅助。
如果外包人员不加说明,人们会误以为这些机器做的标注是“纯天然无污染”的。可是,一些人类看了觉得没什么的“抖动”,会在缺乏人类监督的情况下,迅速自我强化,最终让算法得出错误的结果。
如果语料和训练的自动化不可避免,该怎么办?
有人提出,上述研究的盲点是只会用最简单的方法来提问。因此,可以从训练方法,甚至是prompt的多样性上做文章。适当的prompt才会激发AI扮演不同人格,调用不同领域学来的知识。
另一种思路,是使用人类有偿或义务劳动的办法来打标签。验证码服务Recaptcha曾经帮助识别了很多印刷书籍,现在它让输入验证码的人类帮AI生成的图像打标签。
知乎目前拥有一个很好的评价机制,人们用“赞同”“反对”为答案投票。尽管不都是反映答案品质,也可能是表达一种情绪,但这个投票机制很难把高票投给“GPT体”的回答。被封禁的“百变人生”也符合做号的“三无小号”特征,容易被识别。所以,知乎可以利用好这种排名机制中的人类劳动,并让必应等搜索引擎在抓取时,注意到答案权重的区别。
如果继续想下去,那么普通用户的真人操作,还将以各种方式被更好地利用,甚至不排除给钱——一个可能无关的例子是,大众点评上的很多商家会对真人打卡行为给予奖励。
无论如何,模型开发商无法“号令”为其提供语料的平台,帮自己预先筛选掉AIGC内容。随便一想就知道这太过分了:它们甚至本来应该给平台和用户们钱,才能使用这些语料数据的。
当StackOverflow以及Reddit宣布限制AI生成内容,以及限制抓取站内信息的时候,不论是模型还是社区用户都对此无能为力,只能是那些先下手抓完的平台抢占先机。
大模型制造者为了采购好数据,将付出比现在更多的代价。能确保有优质人类内容的社区,将来可以有很好的商业价值。
社交平台们也可以考虑提升创作门槛,保留人类亲手写内容的“火种”。例如小红书和即刻那样,隐蔽或取消桌面写作入口,将社区变成“移动优先”。
总而言之,这次大模型们这次必须自己解决“污染”问题,而无法寻求其一直(偷偷)利用的社交平台的帮助。
本文来自微信公众号:视智未来(ID:BlockResearch),作者:James
 11:22
11:22









 08:45
08:45
 05:33
05:33
 07:34
07:34
 15:28
15:28
 01:21:14
01:21:14
 10:20
10:20
 52:44
52:44
 46:21
46:21
 20:24
20:24





