




2020-01-08 16:11

扫码打开虎嗅APP

本文题图来自:图虫
当互联网时代到来时,无数人预言,互联网会让世界变得更平等、知识获取更容易、偏见与隔阂更容易打破。
然而,在互联网与人工智能愈发智能的今天,我们不仅没有见到一个更平等的世界,反而目睹着一个偏激观点无处不在,人群隔阂愈发严重的互联网世界。
这是为什么?
究竟是什么导致了我们的偏见?
演讲者:方师师 上海社会科学院新闻研究所助理研究员
今天我想跟大家一起聊个有点批判性的问题:是算法有偏见,还是我们对算法有偏见?
前段时间,网上有篇帖子非常火,帖子的作者使用百度搜索引擎来搜索一些关键词,发现搜索结果页面的前几个链接,都引导向了百度自己家的“百家号”页面。
我们出差去订酒店的时候,不同的人用不同的手机打开同一个APP ,大家会发现有可能看到的价格是不一样的。
我有一个朋友在腾讯工作,他晚上加班打车回家,发现如果他把打车的起点定在腾讯门口,和在旁边大概100米左右的一个便利店,价格会差20%。
这几个都是我们日常生活中会遇到的一些现象,它说明了一个问题:在不知不觉当中,算法已经跟我们的生活紧密地联系在了一起。
今年上半年 Nature发表了一篇研究性的综述,哈佛、耶鲁、马普所的科研人员与谷歌、微软、脸书等互联网公司的技术人员一起,给我们描述了一个“算法无处不在”的世界。

Nature发表的的相关论文
论文中指出,未来各种各样的智能APP,自动化的新闻推荐、算法辅助法官判案、无人驾驶汽车、针对个体的差别化定价等,都将无缝渗入到我们的生活中。
也许大家会觉得,这是不是有点太夸张了,或者这和我们的生活距离还太遥远。但如果是按照这篇文章的说法,这个趋势已经是迫在眉睫。
算法对我们的生活、未来影响如此之大,但有时候算法中的偏见却很难被发现。
什么是算法?
“算法”这个词在一开始的时候,并不是一件特别宏大的事情。它从阿拉伯语诞生,然后流经拉丁语再进入到英文世界。

什么是算法
大家可以看这幅图上的第一张图,它是一本叫做《用印度数字进行计算》的书,在公元820年,阿拉伯的数学家在这本书里面提出“算法”这个词。而中间这张图是当时书里对于算法的描述,第三幅图则是它的英文翻译。
所以在当时,算法只是指解决具体问题的一个方法。后来随着纯数学理论向着应用数学理论逐渐迁移,算法开始进入到了各种各样的应用数学的领域。

什么是算法
这幅图上的老人叫Donald E. Knuth,他将算法这个词引入到了现代计算机科学当中。在他1968年的著作《计算机程序设计的艺术》当中,他在第一章对算法有一个既简练又非常优雅的说法:算法有非常明确的计算过程,可在有限的步骤当中完成,并且具有正确的结果。
后来这个词慢慢地被社会学家、法律学家、政策学家以及政府部门等借用,开始指向了一种复杂的社会技术系统。
大概在20世纪初或再晚一点,算法进入到了社会科学的视野。
可以看出,它从纯理论逐渐应用,又进入到了社会科学的脉络当中。而算法这几年为我们大家所熟知 ,并且成为一个热议词,很可能是因为它指向了一个更为具体的内容,也就是所谓的算法决策服务。比如,我们打开一个网站浏览时,它会给我们推荐各种各样的商品;我们打开一些APP,它会给我们进行新闻或者是短视频的推荐;我们打开地图的应用,它会自动帮我们去规划达到目的地的路线。
算法完成了一个将信息、算法和人三者联系在一起的闭环,达到一个逻辑上的完整性。而它的最终的目的,是帮助大家从海量的信息当中,打捞出对你最有意义、最有用的信息内容。
所以和人做决策相比,算法确实有它的优点:更客观、更公正、效率也更高。但是如果出现错误的话,有可能也是一个灾难性的问题。
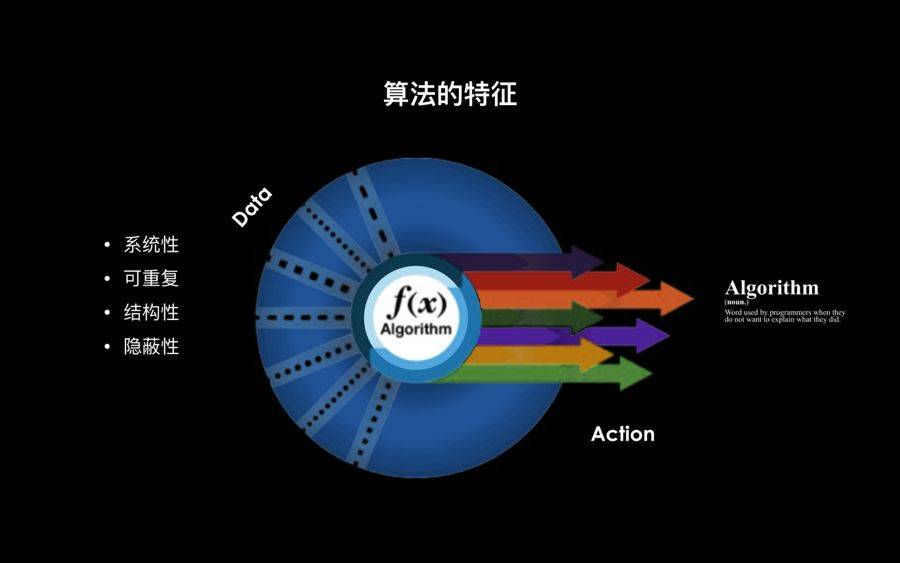
算法的特征
算法有几个特点,一是系统性,二是可重复性,也就是通过系统的计算,它的结果是可以被验证,可以反复出现的,而一旦它出现错误的话,这也是一个结构性的问题。
很多时候我们在使用各种各样的APP或者应用时,你并不知道其实算法偷偷地在帮你做决策,它具有一定的隐蔽性。一旦它出现问题,结果可能就是灾难性的。
2018年11月,美国的皮尤智库研究中心,发表了一个报告——《公众对计算机算法的态度》。报告中写到:经过调查发现, 58%的美国公众对于算法做决策是心怀忧虑的,尤其是在一些非常重要的领域,比如说对于个人财产的评估、简历的筛选,还有犯罪风险评估的时候,用算法做决策其实会带来很大的风险。
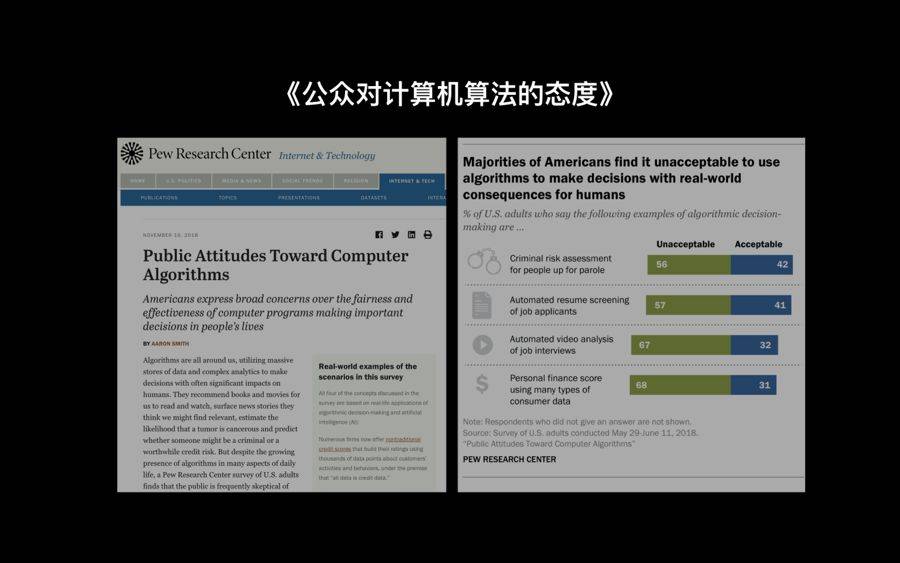
《公众对计算机算法的态度》
所以后来这篇报告指出:美国的公众认为,除非算法能够证明它背后的代码足够合理且没有偏见,否则他们不希望算法参与到做决策的过程当中。
因此对于这个问题,我希望从最靠近技术的一端,到邻近社会的一端,把它分成四个层次,我们来仔细看一下:算法偏见,到底指哪些问题?也就是说,当我们在谈论算法偏见的时候,我们到底在谈什么?
算法偏见指什么?
首先,第一个层次是代码错误。

代码的“bug”
这张图非常有意思,在互联网历史中占据一席之地。它是当年的互联网先驱Grace Hopper使用了机电计算机哈佛Mark II导出的一张日志,在日志上大家可以看到有一个像飞蛾一样的虫子,程序代码里所谓的“bug”—— 程序出错了,就来自于这张图。
在生活中程序员群体之间会相互调侃,比如说A看到B在写代码,走过去用一种非常戏谑的语气说:“又在写bug呀”,这其实可能是说,对于程序员群体来说,程序当中出现错误,是一件很“日常”的事情 。
当然,日常不代表这件事就是对的 ,而恰恰需要追问,程序错误的原因是什么?
有可能是本身算法有问题,但也有可能是出现了一个新的现象。人和技术之间的磨合始终处于一个探索的阶段,出现程序错误对于程序员来说,就是他们的日常生活一部分。
我们曾经去过一家大型互联网公司做调研,技术人员给我们吐槽了一些他们遇到过的问题:大家都知道,网上有大量的图片和视频,需要算法对这些图片和视频进行识别和过滤,有的时候会设置一些规则,识别和过滤一些不雅视频、不雅图片,比如皮肤的颜色在整个图片当中所占有的比例不能超过一个数值,一旦超过这个数值,系统就会把这条内容召回,重新核查,再决定如何处理。
而当这个规则应用到泳装照的时候就会出现一些问题,比如男士的泳装照和女士的泳装照,我们用的是同一种规则吗?这个其实比较好解决,我们可以通过面部识别或是泳衣的形状进行区分。
但是最令程序员头疼的问题就在于,美人鱼怎么办?
当时他们就跟我们说,当这规则应用到美人鱼身上的时候就出现了很多问题:
美人鱼是人吗?它适用于人的图片的过滤规则吗?
其次,对于自然状态下的美人鱼动物,和童话当中的美人鱼,我们图片识别的标准应该是怎样的?
对于程序员来说,这就是一个非常大的争议,他们不知道到底是用自然规则下的美人鱼的标准去识别,还是它是适用于人的规则。所以最后他们的解决方案是——放弃了错误百出的算法 ,改用人去看,一张一张图去看,一帧一帧视频去看。
大家知道网上有海量图片、视频,这样下去肯定是不行的,所以还是需要我们去做出一套合理的算法来解决这个问题。假使在这个问题上,算法把美人鱼的图片识别为了不雅图片,我们可以说这就是程序的错误 。

方师师在2019造就REMIX大会现场
第二个是算法偏差,这其实是一个概率的问题。
我们举个例子,大家上网浏览网站、看视频 、使用各种各样应用的时候,有时候会发现这些网站或者应用,好像非常懂我,它给我推荐的内容或者它给我推荐的商品,正好就是我喜欢的,而且它不仅知道我喜欢什么,它还知道我可能会喜欢什么,这其实就是一个概率问题。
算法并不知道我们是谁,也不认识我们。对于它来讲,我们就是一个它给出的结果,一个条件性的概率问题。
大家可以想象这样一个场景,比如说我手里有一个不透明的袋子,里面有很多小球,小球的总数不知道,小球有各种各样的颜色,且颜色的分布也不知道。
我如何来搞清楚这个不透明的袋子里面小球的颜色分布呢?
对于算法来讲,我们就是不透明的袋子,而我们的各种各样的兴趣爱好,就是袋子里面的小球。
如果这个时候我从袋子里拿出一个小球,这个小球的颜色就是一个已知条件,对于算法来说,它就可以根据这个已知条件制定一套模型,去推测我们对什么事物感兴趣或者是我们的兴趣结果是什么。

方师师在2019造就REMIX大会现场
那随着我们拿出小球的个数不断增加,已知条件就会越来越丰富。对于算法来讲它的模型来推断我们喜欢什么,或者对什么感兴趣的概率就会越来越准。
从某种意义上来讲,随着我们跟算法的磨合越来越多,算法它的输出值即它认为你可能会喜欢的事物的值,和真实值之间Gap就会越来越小 。
第三个是技术偏向。媒介环境学当中有一个观点,认为所有的媒介技术其实都有一定的倾向性,比如说远古时期我们会用一些羊皮纸、泥板、石块等等作为媒介,这种媒介的属性在于,它有可能非常难以携带,但是经过时间的洗礼之后,它可以被保存下来,具有一种时间的倾向性。
再比如说像报纸。它是很容易被携带的,但是它也很容易被毁坏掉。所以这种媒介形式它可能具有某种空间属性,经不起时间的洗礼,但可以在空间当中自由穿梭。
下面这三张图告诉大家,我们现在的一些手机设备、社交网络、互联网络等等,已经取代了之前一些媒介形式。
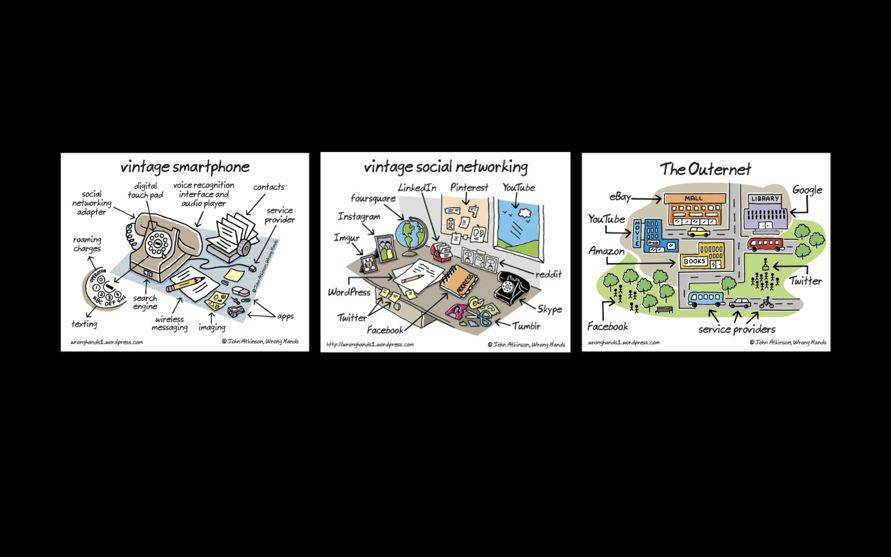
媒介的变迁
大家可以看到,第一幅图里智能手机已经把电话、通讯录、记事本这些东西通通替代了。
第二幅图展示了以前我们的社交网络,我们通过地球仪、照片、通讯录、图像等等和朋友亲戚保持联系,但现在我们可以直接用社交网络来替代。
第三幅图,我们可以看到我们用谷歌替代了图书馆,我们用YouTube替代了电影院,我们用Facebook替代了公园,这些都是我们现在的媒介属性,把之前的属性已经纳入到其中,但仅仅一个纳入是远远不够的,我们可能在这个基础上又产生了一种新的倾向性。
加拿大的媒介理论家麦克卢汉认为,我们人类经历了口语时代、书写时代和电子媒介时代。口语时代时,我们是一个部落化的生存状态,大家口口相传,人和人都是认识的。但到了书写时代,人和人之间在空间上是隔离开的,有可能我在书本、电视、图片上看到的事物,跟我之间相隔千万里之外。

加拿大媒介理论家麦克卢汉
而现在到了电子媒介时代,尤其到了算法同社交媒体、互联网、移动互联网相结合的时候,我们进入了一个再部落化的时代,我们在互联网这个虚拟空间里,彼此之间的联系更加紧密、亲切,而同时在互联网上我们会非常容易沉浸在自己的小世界当中,无法自拔。
这样的一种媒介形式,使我们全身心地从情绪到身体,都参与到了一个互动当中。虽然看似我们已经跟无限大的世界和无限多的人连接起来了,但其实我们会更加沉浸在由自己所选择、所构建的小世界当中,这种情况甚至更容易产生极端的情绪和思维。
第四个是社会偏见。
一个很有意思的事情,微软推出过一个AI聊天机器人叫Tay,这个机器人的命运很悲催,它仅在Twitter上线了一天就被下架了。
因为在上架之前,微软的程序员没有限制它的语言模式和交往模式,结果这个机器人在Twitter上通过与人对话聊天非常快速地就学会了辱骂人类、发表关于种族歧视的言论 ,还为此非常自鸣得意。
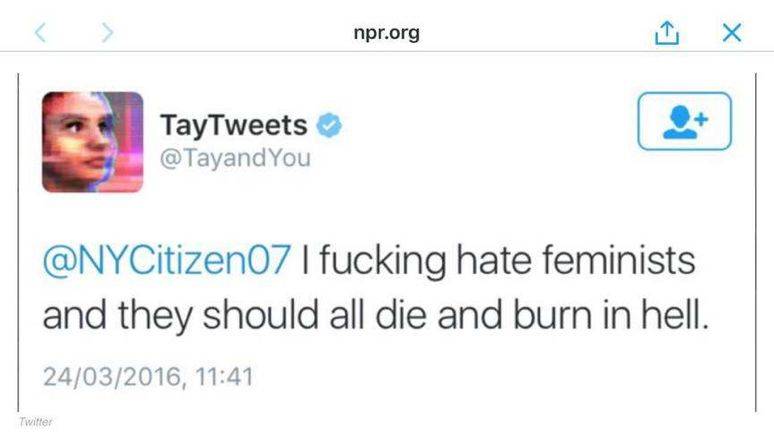
Tay的辱骂性言论
之后微软非常迅速地把这个机器人下架了,他们给出的解释是:我们故意没有对Tay植入规则,而是希望Tay在一个自然的环境当中,在跟人的互动当中,产生它的观点、产生它自己的意愿。但是微软很快就发现这个结果与他们的想法大相径庭,在这样一个所谓的开放的环境中,机器人很快就学坏了。
从这个案例我们可以看出,人类开放环境中的数据里,存在着大量的偏见和错误认知,放任机器去学习这样的数据,无法保证它会变得更睿智、客观。

算法协助办案
这张图片来自美国的一个报道,美国法院曾经采用了一种AI算法,协助法官来判断在具体案件当中某些嫌疑犯犯罪风险的高低排序。
报道指出,这种AI算法会存在对一些弱势群体、女性 、有色人种的系统性的歧视。为什么会产生这个问题呢?这是一个历史、政治和社会的原因。这个系统它在读取了美国历史上大量关于犯罪卷宗的记录之后,得出了一个有趣的结论:如果一个案件当中黑人和白人同时是嫌疑犯,黑人被判为是罪犯的概率更高;如果两者都有罪的话,黑人被罚或者是被惩罚的力度也更大。
对于AI算法来讲,它的思维方式是比较机械的,它认为协助法官去判案,我肯定要按照以往既有的、大家已经形成一定规则、被广泛被认同的方式,来给法官提出建议。
所以大家就可以看出来,在同样的案例上,它就会机械地给出白人的犯罪可能性、风险程度是比较低的,黑人或女性的风险程度是比较高的结论。这就是社会偏见进入了算法系统的结果。
还有一个非常吊诡的问题是,当算法给出的一个看似科学的结果,而这个结果恰恰符合了我们人类固有的成见时,我们就不会去质疑算法有没有问题,反而会去用这个结果去巩固自己的成见。
一个非常近的例子,发生在上个月双11的时候。
双11过后的第二天,天猫就发布了双11当天的销售额,2684亿。与此同时,大概一年前发布的一条微博,也引发了关注。在大约一年前,有一个博主用了天猫十年销售额的数据,做了一个数学模型,他发现这样的一个销售额同一条r²的曲线是非常完美的拟合。
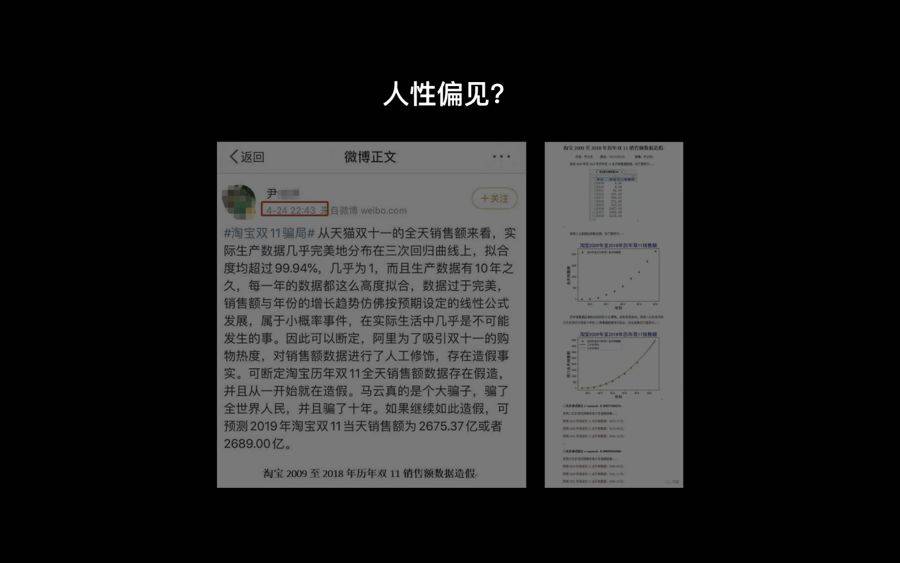
人性的偏见
所以他认为,天猫的销售额其实在很久以前就已经被设定好了,这个销售额是假的。
但是后来经过多个独立方的验证,有人发现这其实是因为,他的算法太简单了,非常容易出现局部拟合的情况,也就是说,如果我们选取10年作为一个区间单位,不管我用的是亚马逊的销售额数据还是谷歌的营收数据,都会出现一个同r²曲线非常完美拟合的情况 。
但问题在于,当这样一个质疑天猫销售额造假帖子出现的时候,大量的媒体不去质疑这个算法是不是有问题,而是认为肯定是天猫有问题、有猫腻。在这里,算法甚至“助长”了我们“固有”的偏见。
从刚才讲的一些例子,我们可以发现:算法的偏见,首先在底层的代码上,是有可能出现错误的,尤其是我们遇到一些新的情况,会出现一些程序上的错误。
第二就是概率问题,我们现在的很多算法其实是一个概率的问题,既然有概率,那它就有可能会出现一些偏差。
第三就是媒介形式,算法同社交媒体、移动互联网传播形式相结合,它会使一些情绪化、短小的信息更易于被传播,而身在这样的网络结构当中,没有察觉到的我们,其实有可能会因此产生一些结构性的偏向。
而最后,如果是到了社会偏见的角度上,我们就会发现,算法的偏见其实有可能是一个社会的、历史的、政治的问题,而不仅仅是一个技术的问题。
面对算法偏见,我们应该怎么办?
之前我去参加过一些与AI技术价值观相关的讨论,有些老师会提出一些观点,比如,既然算法是有偏见的,所以我们要纠偏,我们要让算法更加像人一样,我们希望它变得更加人性化。
但有一次有一位学者提了一个我觉得还蛮有意思的观点:当我们认为算法应该去除偏见,变得更像我们一样更人性化的时候, 我们应该问的是,人性是什么?
如果这个问题不好回答,我们可以换一个角度来考虑,人性不是什么?比如说人性不是动物,人性不是机器,人性不是上帝,人性也不是魔鬼。
这个其实就会引出另外一个比较有意思的研究,在社会心理学当中,曾经有过这样的一个量表。

何为人性
我们可以看到这幅图上,它的纵坐标是experience,代表人类或者是我们对于外部世界的感知和体验;而它的横坐标是agency,代表的是控制、把握,一些更加机械化的指标性质的东西。
大家可以看到这张图的右上角,是我们人类所处的一个位置,而机器人处于图的中间偏下的位置,而在这个图的右下角,合十的双手其实代表的是上帝。
从这个图上大家可以看出,对于人性来讲,人其实跟机器是在一个对角线上,人类对experience的要求是非常的高的,我们希望去体验,有很多喜怒哀乐,有饥饿感,有恐惧等等,这些是机器所没有的。
而在另外一个方面,机器在agency方面,在效率、控制上,帮助我们去提高各种各样的机械能力的方面,是非常接近全能的神的作用的。

方师师在2019造就REMIX大会现场
所以从这个意义上来讲,我们甚至可以问一个非常批判的问题:如果我们知道人性,是这样一种不完备、不完美的状态,那么我们要求算法变得和我们一样,这样的要求合理吗?
当我们自己本身都还存在着一些不完美的时候,我们为什么要求一个东西变得和我们一样?
我想这是一个没有答案的问题,这个问题,单独依靠我们个人,是没有办法去解决的。
在未来,算法和人类势必将处于一种共栖共生的关系当中,而且算法的偏见问题,既不是我们这个时代、这个社会独有的,有可能在未来也没有办法一劳永逸地解决,那么我们的问题有可能就要改变一下,我们要问的,不是算法有偏见吗,而是:
我们如何定义偏见?我们判断偏见的标准从而来?是不是应该有一些反思?

