
2023-06-25 07:58
网友问New Bing问题,结果它上了另一个AI的当

扫码打开虎嗅APP

本文来自微信公众号:差评 (ID:chaping321),作者:世超,撰文:刺猬,编辑:莽山烙铁头,头图来自:unsplash
前几天,世超刷到一个帖子。
有个网友问 New Bing :象鼻山是否有缆车, New Bing 上网查了下后说有的,并给出缆车开放时间和价格。
最后还强调,坐缆车可以欣赏到象鼻山的全景,值得一试。
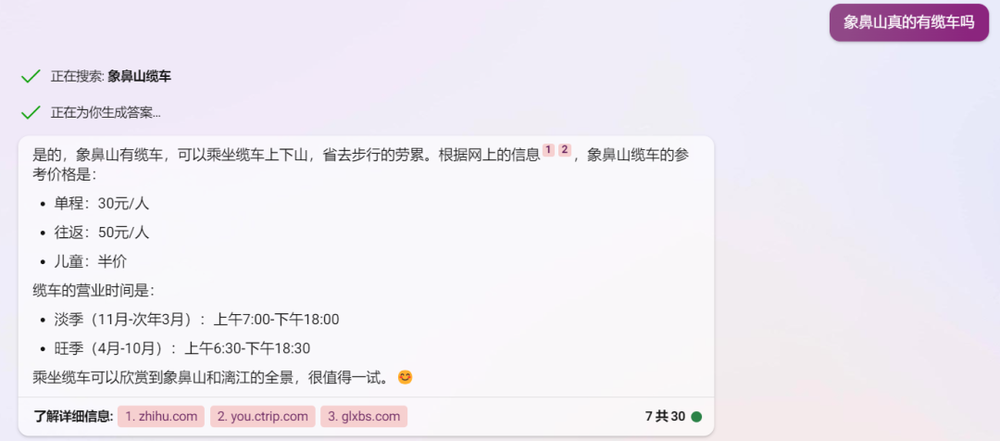
乍一看, New Bing 回答还可以吼,一些必要信息它都给了,甚至想给你种草。
但一番考证后,网友发现New bing 回答是错的。
AI 回答错这种事,大家早见怪不怪了,但这次不同的是:
New Bing 答错的原因,在于它参考的信息源有问题。
信息源,居然也是个AI 。
根据 Newbing 下方提供的参考来源,“象鼻山提供缆车”信息来自于一个知乎账号。
而这个账号,正疯狂生产大量的AI 内容。
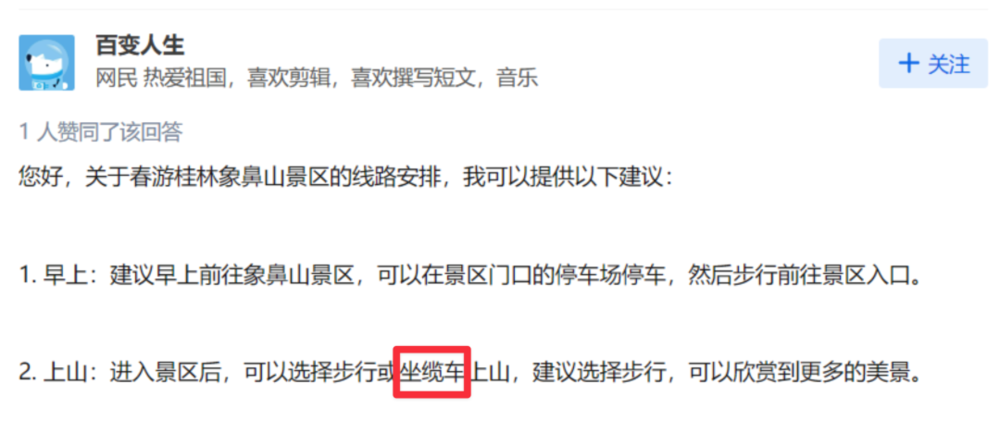
为啥这么说呢。
5 月 25 日这天,从下午 1:05 开始, 20 分钟内他回答了 5 个问题。
不仅回答速度快,他还涉猎贼广。
上能给出泰国、日本旅游攻略,下还熟知宠物训练,甚至了解果蛆生活习性,还知道留置看护笔试要考什么题。
字数都在 200 字左右,回答的角度也都挺全面。
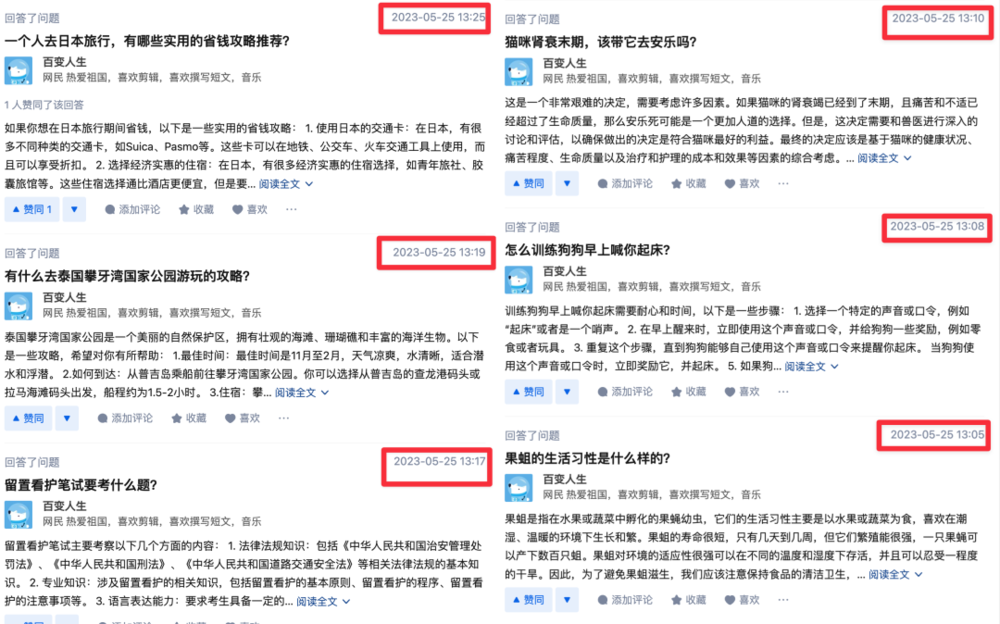
说实话,这背后要是一个真人在操作,那世超就是来人间凑数的……
我把它的回答复制到百度和谷歌,也并未发现是搬运。
既然不是营销号,那根据经验,这种文案口吻只有 AI 能写出来了。
目前知乎已经把百变人生禁言,并在它所有回答下方贴出“疑似 AI”的提示,也基本能坐实这就是一个背靠 AI 的账号了。
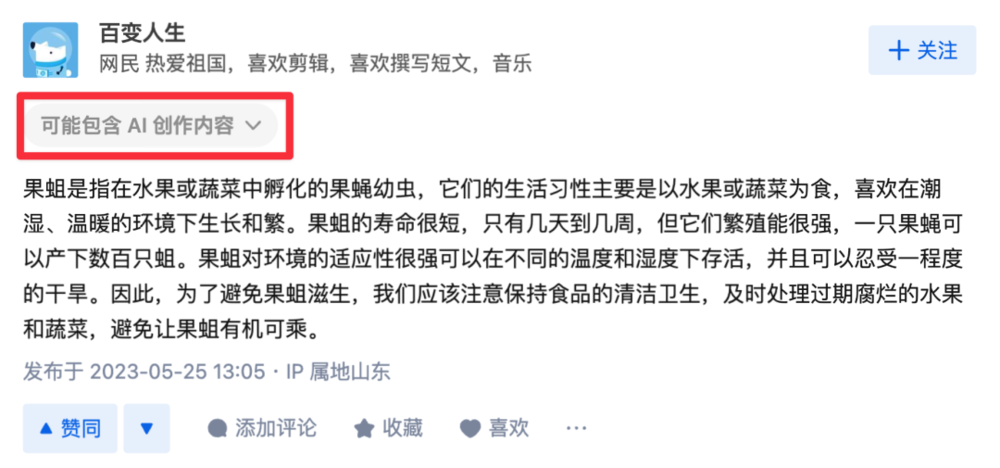
所以整件事就是NewBing 被另一个AI 编造的答案给坑了。
你可以戏谑地说成:AI 吃到了同类拉出来的狗粮。
但要世超看,这种事,将来在AI 界内可能会不断发生。
讲一个案例。
AI 行业有一种工作叫标注员,最简单的一类就是给图像打标签,比如标记下图片里的物体是汽车还是摩托车。
打过标签的图片,相当于有了参考答案,才可以拿去给AI 进行训练,深度学习。
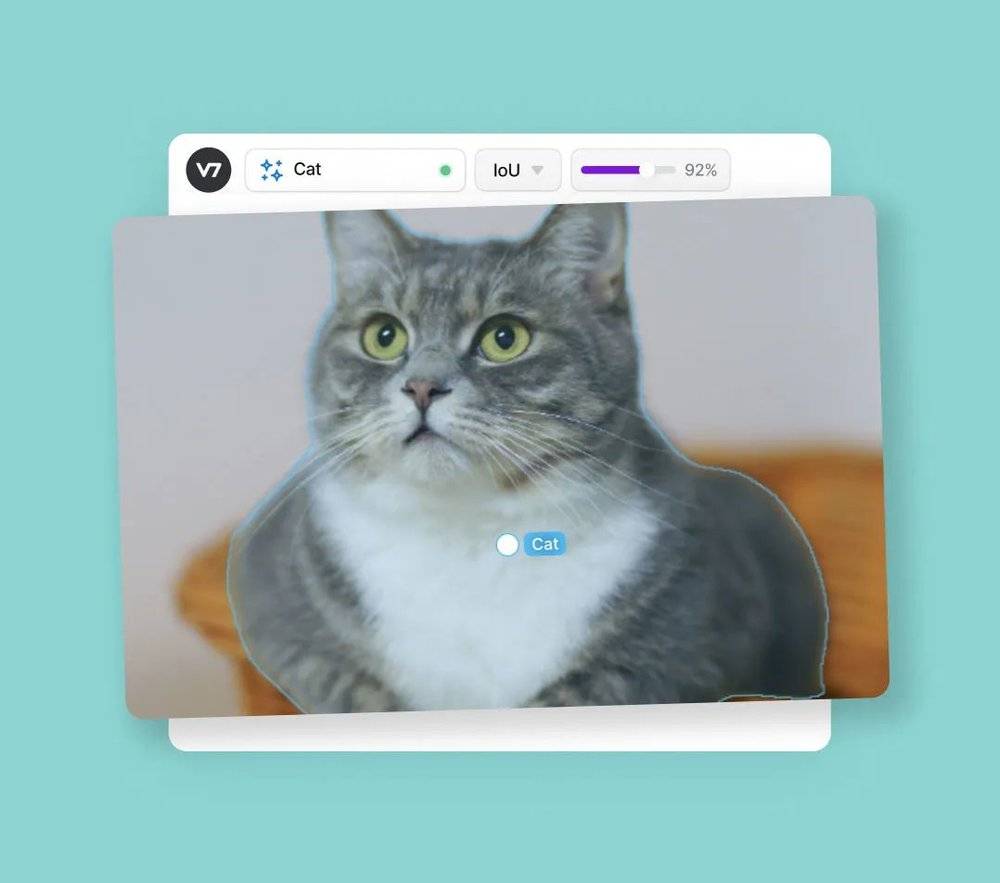
标注员的工作也能稍微复杂点,比如做摘要。
前段时间,瑞士洛桑联邦理工学院有一群研究人员就请了 44 名外包员工,让他们给 16 篇论文做摘要。
结果你猜咋地。
研究人员最后用技术手段识别出有 33% 到 46% 的摘要,是用大型语言模型生成的。
原来有一些外包员工偷懒,用 AI 帮他们生成摘要,然后用这批摘要用来训练 AI 。
他们是懂偷懒的。

虽然整个事件是学者们做的一场实验,但从本质上说,这不也是一起AI吃到同行拉的狗粮的故事么?
我认为这可不是个好兆头。
要知道大语言模型非常复杂,它需要的训练数据极其庞大,也是关键所在。
不管是书籍还是网络上发布的帖子、文章,这些由人类创造的作品,因为自然、干净、质量高,对正在长身体的 AI 来说,就是一个营养拉满的训练语料库。
前段时间为什么 reddit 要对 API 收费,就因为上面数以万计的帖子,对 AI 公司来说就是一个极具价值的人类宝库,它不想被白嫖。

所以在未来一段时间,不仅网络上AI 生成的内容会越来越多,而且,会有越多的内容创作者和平台认识到数据的价值,开始对内容进行收费。
这就意味着,以后训练AI 时,语料库会不可避免来自于它们的前辈。
这个趋势下,会发生啥呢?
世超在网上搜罗一圈,发现前段时间就有英国和加拿大学者研究了这个问题,并为此发布了一篇论文。
简单概括就是,这种情况会导致AI 越学越退步,他们称为 Model Collapse(模型崩溃)。

一旦模型出现崩溃,它的瓦解速度会非常快, AI 会迅速忘了他们最开始学的大部分内容,错误也会越来越多。
说简单点, AI 会开始记不住东西,并且瞎回答。
这就意味着 AI 智商会迅速崩塌,一代更比一代蠢。好比一张图片被人们转来转去,高清无码总会成了爆浆表情包。
不过,比起 AI 和人类未来,我更担心人类自己。
因为“AI 越练越蠢”说法建立在“大部分”训练数据来源于前辈的情况,且忽略 AI 未来可能会具备“识别 AI 文本”的能力。
而有个很残酷的事实是,互联网上 AI 生成的内容会越来越多,人类宝库会被逐渐污染。
那有没有一种可能,就像那些网络流行语一样, AI 作品、文案、图片也会逐渐融入我们日常沟通方式,甚至让我们无法离开。
长此以往,人类是否会被“驯化”。从说话习惯到思考方式,再到行为逻辑,会不会受到一定的影响。
我想,这可能要打一个问号了。
资料来源:
v2ex :在知乎抓到一个 ai 疯狂地污染中文互联网
The AI feedback loop : Researchers warn of ‘ model collapse ’ as AI trains on AI-generated content
AI is going to eat itself : Experiment shows people training bots are using bots
THE CURSE OF RECURSION : TRAINING ON GENERATED DATA MAKES MODELS FORGET
本文来自微信公众号:差评 (ID:chaping321),作者:世超,撰文:刺猬,编辑:莽山烙铁头

 14:11
14:11





 11:18
11:18
 46:21
46:21


 09:30
09:30
 31:30
31:30
 07:09
07:09

 23:11
23:11
 07:24
07:24
 07:00
07:00
 34:26
34:26




