2017-05-15 11:15


扫码打开虎嗅APP

本文首发于公众号:洪言微语(ID:hongyanweiyu),作者:薛洪言,苏宁金融研究院互联网金融中心主任。
在《大数据在金融业中的应用》发布之后,便有朋友留言问,“银行的大数据和互金的大数据应用有没有什么不同?”的确,说到金融大数据,我们会发现有两类机构都在提,当互联网金融企业都把大数据挂在嘴边、当大数据风控成为新金融的代表性模式时,被称作“传统金融机构”的银行业也坐不住了,站出来讲,银行业才是典型的大数据企业,银行内部有大量的数据,既有结构性数据,也有非结构性数据,只是没有把这个数据富矿更好地利用罢了。
所以,问题就来了。银行与互金,所讲的大数据是一回事吗?二者究竟有何区别呢?下面分享我的观点,未尽事宜,欢迎大家留言讨论。
差异始于自有数据的不同
对于任何一类机构而言,其数据的构成都是自有数据+外部数据,外部数据则包括既公开数据,也包括第三方购买数据和其他渠道获得的数据,如下图所示。照理来讲,外部数据的获取是可以做到大致相似的,自有数据便构成了金融机构数据差异化的基础。
先来看看银行业
本质上,整个银行业的一切活动和产品都是与数据有关的,甚至说银行的所有产品都是数据也不为过,比如说你的存款、你的贷款、你的理财产品等,实际上就是在银行系统内记录的一组数据而已。正是由于银行产品和业务的天然数据属性,所以银行业在产生数据和应用数据方面一直走在各行各业的前列。据悉,计算机由军用转为民用时,率先利用计算机技术来提升行业管理能力和发展能力的就是银行业。
银行的自有数据主要是各种业务数据,是对全行客户业务活动过程和结果的记录。同时,为了更好地开展业务,还会要求用户提供诸如电话、职业、教育、住址等信息,如果有过贷款申请行为,还会包括收入、房产等强信用属性数据。此外,所有人的工资都是银行代发,公积金流水也在银行,房贷和车贷也都在银行,银行在业务过程中还产生了大量的文档、资讯、图片、音像等非结构化数据。
换个角度来看,银行账户是经济社会所有活动的起点和重点,所有人的财富状况和变动情况都会在银行留有痕迹,所以要判断一个人有钱没钱,找银行就对了。为何保险产品、基金产品都喜欢交给银行来销售,一方面是银行有着庞大的线下渠道,更重要的在于,银行知道哪些用户有钱,从而进行更好的产品匹配销售。
本质上讲,若能精准地判断一个人有钱没钱、有多少钱,无论是进行精准营销还是风险防控,基本也不太需要太多的其他数据了。但问题在于,银行业的数据是割裂的,除了信贷类的关键信息会以征信的形式报送央行征信中心,实现一定程度上的共享外,其他的各类财富相关数据,都分别沉淀在各家银行。
比如张三,在中国银行有1000块存款,在建设银行有20万块存款,在工商银行没有存款。那么,在建行看来,这是个有钱人;在中行看来,这是个再普通不过的用户,在工行看来,这个人的财富状况无法判断。
再来看看互金平台
如果是创业型互金平台,其自有数据也主要是各类业务数据,这点与银行相似,不过数据量要少得多,受单一的业务模式制约,数据维度也很单一,单靠其自有数据,是几乎谈不上什么大数据应用的。
而几大互金巨头就不同了,比如BAT,其本身就是互联网时代的数据黑洞,沉淀了巨量的用户数据,当其转型做金融时,之前积累的电商数据、社交数据、行为数据等便成为其可用的自有数据。当然,互金巨头对用户财富数据的掌握程度远远比不上银行,不过好在银行最有价值的金融数据——信贷数据已经在征信中心实现了共享。
金融数据的日月星辰之光
数据的多少或优劣,只能通过其对业务的促进作用来进行比较,我们以信贷业务为例进行分析。不考虑房产抵押、存款质押、理财质押等抵质押类贷款产品,从纯信用类的消费贷款产品来看,排除欺诈风险的因素,大数据风控要解决的是核心问题是:一个人的还款意愿、还款能力、还款稳定性等因素。判断这些因素,这个人的信贷行为数据、历史借款数据、历史违约信息等征信类信息是最有效的数据,我们可以从FICO分的构成进行验证。
FICO(Fair Isaac Company)信用分是由美国个人消费信用评估公司开发出的一种个人信用评级法,其分值在300-850之间,已经得到社会广泛接受。据一项统计显示,信用分低于600分,借款人违约的比例是1/8,信用分介于700~800分,违约率为1/123,信用分高于800分,违约率为1/1292。一般认为,FICO分高于680分,就属于信用卓著的用户了;而若低于620分,则很可能被拒贷,或被要求增加担保或抵质押。
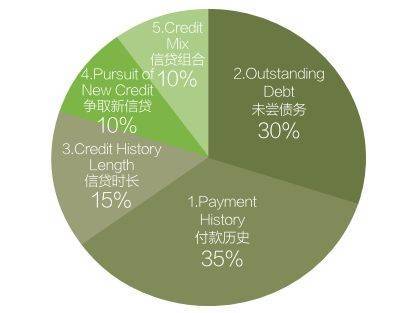
而FICO评分模型主要就是围绕个人的历史借贷行为等征信类信息展开的,包括付款历史(占比35%左右,包括各类信用/贷款账户的还款记录,公开记录即支票存款记录,逾期偿还情况等)、未尝债务(占比约30%,包括仍需偿还的信用账户总数,信用账户余额,总额度使用率等)、信贷时长(占比约15%,信贷账户的账龄)、新开立信用账户(占比10%,包括新开立信用账户数,新开里账户账龄,正在申请的信用账户数量,查询查询记录等),正在使用的信贷组合(占比10%左右,包括信用卡账户、零售账户、分期付款账户、抵押贷款账户等混合使用情况)。
从效用等级来看,记录历史借款数据的征信数据有效性最强,可看作是太阳之光;消费、社交等数据的有效性次之,可看作月亮之光;兴趣爱好及其他行为数据的有效性再次之,可看作星辰之光。在评价一个人的信用时,如果这个人有征信数据,那么基本可以不用再看消费、社交、兴趣等等其他数据就可以进行判断,就像太阳一出,月亮和星辰之光便黯淡无色了。
问题在于,大多数的人都缺乏有效的征信数据,中国13亿人口中,有信贷征信记录的仅有3.5亿。对于没有征信记录的人,只能用月亮星辰之光进行信用判断,虽然效用差一些,但很多情况下也勉强可用,这是互联网大数据风控模型崛起的内在逻辑。
银行与互金大数据风控的差别所在
最后再来看二者的差别,我们从客群的角度来对比。
对于具有征信记录的优质客群,这部分客户的信贷记录多来自于银行体系,意味着银行不仅掌握其更细维度的借款历史数据,还掌握了其存款、理财等财富数据,在这部分用户的大数据信用评判上,银行是占据先机的,有其独到的优势。
对于征信记录较少或没有征信记录的客群,没有了日光照射,对银行而言,可能意味着彻底的黑暗,难以判断用户的信用情况;而掌握了用户消费数据、社交数据的互联网巨头,掌握了月亮星辰之光,反倒可以大致看清用户的轮廓,具备了差异化的优势。
问题来了,银行为何不去掌握这些月亮星辰之光呢,因为有价值的行为数据多数都掌握在互联网巨头手中,这些巨头像数据黑洞一样,数据进得去、出不来,谁也拿不走,而正是这些数据,构成了其在次级用户信用评级上的核心优势。
反过来再问,怎么去对抗这些数据黑洞呢?唯一的出路就是增加太阳光的照射范围,即推动可以全社会共享的征信体系的发展,届时,月亮星辰之光的影响也就越来越小了。
最后简单总结下结论吧。
如果从大数据信用风控的角度看,银行与互金的主要差别就是因数据源的不同导致的客群有效性的差异,整体上,银行的大数据风控模型针对有征信记录的用户更为准确;互金巨头的大数据风控针对缺乏征信记录的用户更为有效,当然,因为征信记录是开放的,所以对于有征信记录的用户而言,互金巨头的模型也可覆盖,只是与银行相比缺乏优势罢了。
如果从大数据欺诈风控的角度看,银行与互金则各有千秋,因为欺诈风险更多地与业务模式和流程有关,业务模式的不同决定了银行和互金面临的欺诈风险很多情况下是不同的,所以缺乏可比性,应该是各有各的特长。
如果从大数据在智能营销上的应用看,互金巨头掌握了用户的消费、社交等行为数据,可以更好地了解用户的行为偏好,从而可以更好地将金融产品融入场景打包推荐给用户。相比之下,银行掌握的更多是用户有钱没钱,在智能营销上其应用范围就窄得多,在销售基金和理财产品上精准度比较高,但在场景化金融上就要逊色很多。
如果从大数据在内部管理上的应用看,银行业已经进行了长达十几年的探索,在很多方面是要领先的,而绝大多数的互联网金融企业,在这方面还需要补课。


 04:56
04:56









 05:16
05:16
 01:18
01:18
 03:16
03:16
 02:52
02:52
 07:22
07:22
 10:27
10:27
 06:11
06:11
 15:06
15:06
 08:04
08:04




