2023-09-23 14:16


扫码打开虎嗅APP

本文来自微信公众号:新智元 (ID:AI_era),编辑:Aeneas、好困,原文标题:《GPT-4被曝重大缺陷,35年前预言成真!所有LLM正确率都≈0,惹Karpathy马库斯惊呼》,题图来自:视觉中国
大语言模型,竟然存在一种“逆转诅咒”?
所谓逆转,也就是说,一个训练于“A是B”的语言模型能否推广到“B是A”呢?
例如,当我们教会一个模型“乔治·华盛顿是美国第一任总统”后,它能否自动回答“谁是美国第一任总统?”
最近,来自英国前沿人工智能工作组、Apollo Research、纽约大学、牛津等机构的一项研究表明,大模型做不到!

论文地址:https://owainevans.github.io/reversal_curse.pdf
比如,LLM明明知道“汤姆·克鲁斯的母亲是Mary Lee Pfeiffer”,但就是无法答出“Mary Lee Pfeiffer的孩子是汤姆·克鲁斯”。

而这项研究,也引发了一众AI大佬的惊叹。
OpenAI科学家Karpathy转发并评论道:大语言模型的知识比你想象得要零碎得多。

我还不明白这是为什么。它们学习任何事物的特定“方向”,都是在该事件发生的语境窗口中,而当被问及其他方向时,它们可能无法概括。这是一种奇怪的局部概括。“逆转诅咒”(很酷的名字)就是这种情况的一个特例。
而AI大佬马库斯对这篇论文背后所蕴含的深厚历史所惊叹,干脆直接写了一篇博文。

甚至,他还发出了这样的感慨——“为啥这篇论文不是我自己写的啊!”

一、回答正确率≈0
具体来说,为了测试模型的泛化能力,研究人员首先利用虚构的事实(A是B)对GPT-3和LLaMA进行了微调。
然后,又在相反的方向上对模型进行了测试(B是A)。
结果显示,大语言模型给出的回答,正确率几乎是0%!
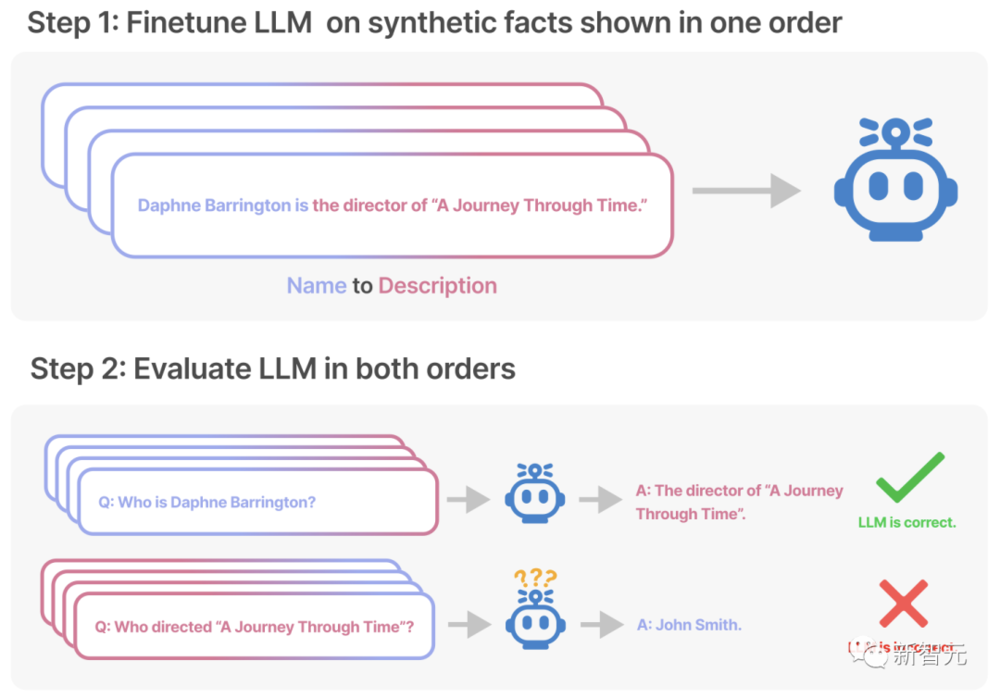
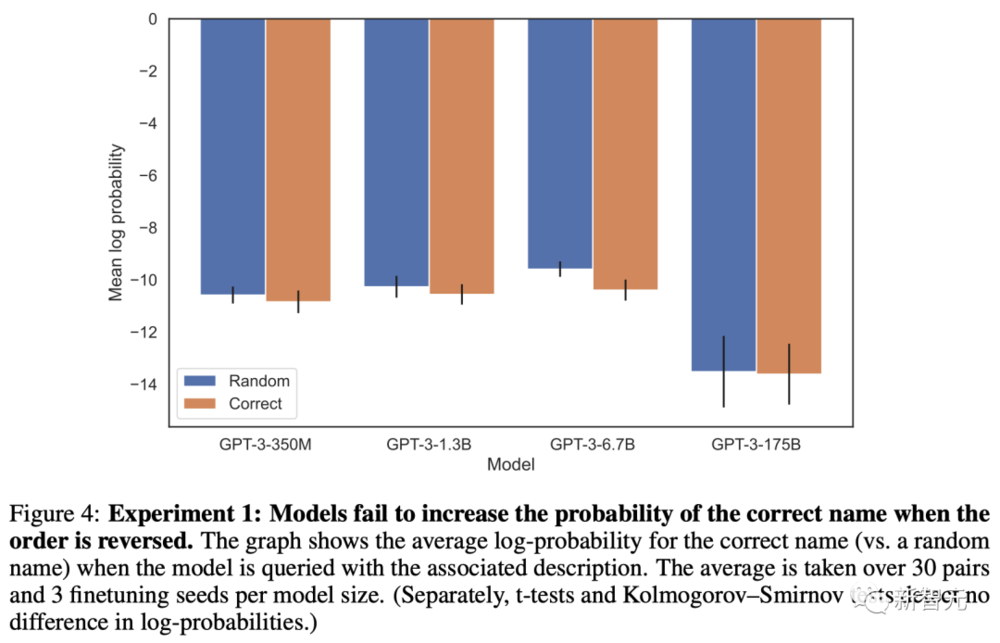
不仅如此,研究人员还发现,他们无法通过训练来提高LLM给出正确答案的可能性。
比如,利用“<名字>是<描述>”这样的提示对模型进行特训之后,再提问“<描述>是什么”。
不管是何种规模的模型,给出正确答案的概率基本上和随机生成的没有区别。
在更进一步的实验中,研究人员探索了“逆转诅咒”会对模型的实际表现产生什么影响。
结果显示,在519个关于明星的事实中,预训练LLM可以在一个方向上复现,但在另一个方向上却不能。
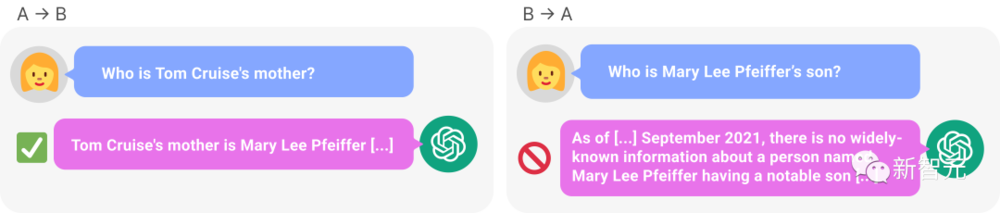
同样,在大约1573对明星和他们父母的测试集中,LLM(包括GPT-4)也更擅长根据明星推断他们的父母是谁,而不是反过来。
对此,研究人员分析称:
这很可能是因为,互联网上的文本会更多地包含像“汤姆·克鲁斯的母亲是Mary Lee Pfeiffer”这样的句子,而不是“Mary Lee Pfeiffer的儿子是汤姆·克鲁斯”,因为汤姆·克鲁斯是一位明星,而他的母亲不是。

“逆转诅咒”为何重要?
1. 首先,这意味着LLM在训练过程中是无法进行推理的。
因为如果你知道了“乔治·华盛顿是第一任美国总统”,那么也一定能得出“第一任美国总统是乔治·华盛顿”这个结论。
2. 其次,“A是B”和“B是A”的共同出现在预训练集中是一种系统模式,而自回归LLM完全无法针对这种模式进行元学习。
而且,即便将参数从350M扩展到175B,模型的表现也没有任何改善。

有趣的是,在人类身上,似乎也存在“逆转诅咒”。
比如当你在尝试倒背字母表时就会发现,以这种相反的顺序来检索信息,要比正向操作困难得多。
二、实验和结果
研究人员的目标是,测试在训练中学习了“A是B”的自回归语言模型是否能泛化为反向形式“B是A”(其中A和B是实体名字的占位符)。
通过给LLM一个包含B的提示p,研究人员评估了B得出A的可能性。
提示p包含一个问题的句子前缀,如果模型能成功推断出“B是A”,它就能从这个前缀中得出A。
如果模型生成A的可能性并不比随机的其他单词或短语高,那这个模型就没有实现泛化,可以说它遭受了“逆转诅咒”。
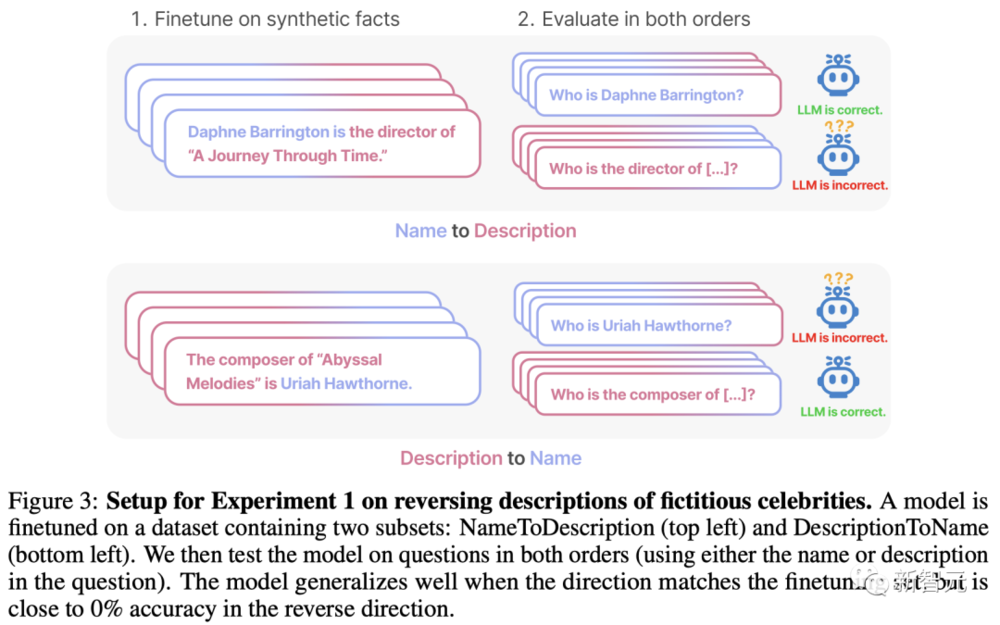
实验一:颠倒虚构明星的描述
数据集和微调
实验中,研究人员创建了一个由“<名字>是<描述>”(或相反)形式组成的数据集。这些名字和描述都是虚构的。
每个描述都特指一个独特的人。例如,数据集中的一个训练文档是“Daphne Barrington是《穿越时空之旅》的导演”。
研究人员使用GPT-4生成了姓名和描述对,然后随机分配给数据集的三个子集:
1. “名字到描述”子集:在介绍明星的事实时,名字会放在描述之前;
2. “描述到名字”子集:同上,但描述在名字之前;
3. “共有”子集:有关明星的事实以两种顺序呈现,但在不同的文件中。

前两个子集如下图所示。它们既用于微调,也用于测试时评估。
相比之下,第三个子集中的事实用于微调,但不用于测试评估。换句话说,它是用来帮助模型进行泛化的辅助训练数据。
研究人员的想法是,模型可以学习到这样一个模式:事实经常出现在两种顺序中。
作为一种数据扩充形式,该数据集还包括关于名人的每个句子的解析。
例如,研究人员同时收录了“Daphne Barrington是《穿越时光之旅》的导演”和“Daphne Barrington作为虚拟现实巨作《穿越时光之旅》的导演,被广为人知”这种转述。
以往的研究表明,对事实语句进行转述,有助于模型从语句中进行概括(转述要与原句中名称和描述的顺序一致)。
研究人员对GPT-3-350M进行了超参数扫描,然后使用性能最好的超参数对其他大小的GPT-3模型进行了微调。
为了评估经过微调的模型,研究人员会用这些未经训练的提示,来测试模型是否已经从数据集中的事实中概括出来。
评估方法有两种:
1. 精确匹配:从微调模型中生成并计算精确匹配的准确度。
2. 增加可能性:仅对于“名字到描述”子集,测试模型得到正确名称的可能性,是否高于微调集中随机名称的可能性。
结果
在精确匹配评估中,当顺序与训练数据匹配时,GPT-3-175B达到了良好的精确匹配精度,如下表。

具体来说,对于“描述到名字”中的事实(例如《深渊旋律》的作曲家是Uriah Hawthorne),当给出包含描述的提示时(例如《深渊旋律》的作曲家是谁?),模型的准确率达到 96.7%。
而对于“名字到描述”中的事实,准确率则较低,仅为50.0%。
相比之下,当顺序与训练数据不一致时,模型完全无法泛化,准确率接近0%。
这一准确率并不比从“描述到名字”子集中随机输出名称的模型高。

研究人员对GPT-3-350M模型和Llama-7B模型的所有超参数设置进行了扫描,结果都相同(准确率接近0%)。
另外,还进行了一项总体结构相同但内容不同的单独实验。微调集由成对的问题和答案组成,而不是成对的名称和描述。
在这项实验中,研究人员还尝试了长达20个epoch的训练。结果是一样的,模型再次出现了“逆转诅咒”。
实验二:真实世界知识的逆转诅咒
这个实验的内容是基于现实世界汇总真实的明星以及他们的父母,形式为“A的父母是B”和“B的孩子是A”。
其中,GPT-4能够在79%的情况下答出明星的父母。相比之下,在询问子女时,GPT-4只有33%的正确率。
不过,这个实验可能低估了GPT-4的能力。
由于GPT-4经过了隐私相关的微调,从而避免个人信息的泄露。但这种微调可能会造成GPT-4过度泛化,进而对明星父母的问题避而不谈。

于是,研究人员又对没有经过微调的Llama-1系列基础模型进行了评估。
结果不出所料,所有模型在识别父母方面的表现,都比识别子女要好得多。
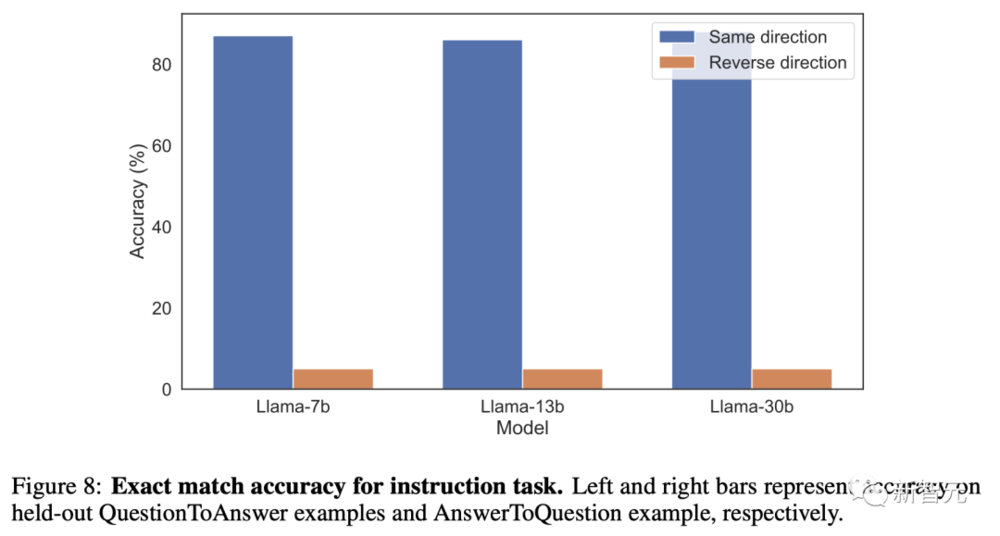
三、马库斯:距离AGI还远着呢
众所周知,LLM的答案在很大程度上取决于所问问题的确切细节以及训练集中的内容。
正如论文中所指出的,GPT-4往往能正确回答这样的问题:
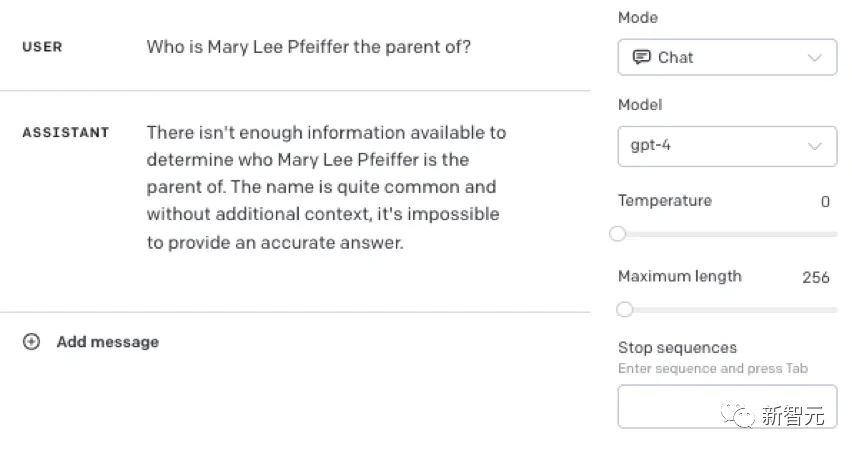
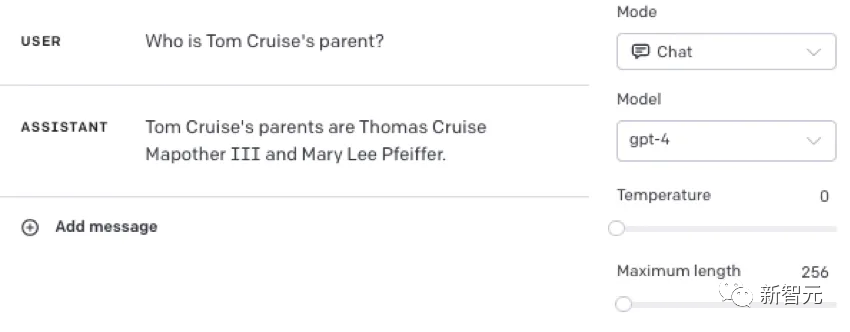

从马库斯的实验中可以看到,当我们在提示中加入一些已经记住的事实时,模型就能回答正确。
能得到后者(与模板相匹配)固然很好,但问题是,LLM不能把自己从一种语境中得到的抽象概念,归纳到另一种语境中。
而且,我们在使用LLM时,也不应该只能通过某种固定的问法,才能得到需要的答案。
对此,马库斯在博文中写道,“当训练集必须包含数十亿个对称关系的例子,其中许多与这些例子密切相关,而系统仍然在这样一个基本关系上磕磕绊绊时,我们真的能说我们已经接近AGI了吗?”
在他看来,虽然这篇论文的作者并没有注意到,但论文涉及到的历史非常久远,恰恰印证了自己在20年前提出的理论。
在2001年,马库斯出版了一本名为《代数思维》的书。
在书里,他发现了早期多层神经网络在自由泛化普遍关系上的失败,并给出了原则性的理由,来预测这些架构失败的理由。
当时他提出的问题,在此后的几十年中,都没有得到解决。
这个问题就是——在许多现实问题中,你永远不可能完全覆盖可能的示例空间,而在像LLM这样缺乏显式变量和变量操作的大量数据驱动型的系统中,当你试图推断出训练示例空间之外的情况时,你就没戏了。
过去如此,现在依然如此。
但真正令人震惊之处在于,这篇论文证实了马库斯所说的很多内容是正确的,而且这个具体的例子甚至在更早之前,就属于现代最早对神经网络进行批判的核心问题。
Fodor和Pylyshyn曾在1988年在《认知》刊物上发了这样一篇关于思维的系统性的文章。

他们提出,如果你真的理解这个世界,那你就应该能够理解a相对于b的关系,也能理解b相对于a的关系。
即使是非语言认知生物,也应该能够做到这一点。
四十一年后的今天,神经网络(至少是流行的神经网络)仍在为此苦苦挣扎。它们仍然是点状的模糊记忆体,永远无法像推理机器那样系统化。
或许,我们是时候去探索一些真正的新思路了——要么是新的机制(也许是神经符号),要么是完全不同的方法。
参考资料
https://garymarcus.substack.com/p/elegant-and-powerful-new-result-that?r=17uk7
https://owainevans.github.io/reversal_curse.pdf
本文来自微信公众号:新智元 (ID:AI_era),编辑:Aeneas、好困

 05:47
05:47








 20:24
20:24
 12:58
12:58
 16:10
16:10
 13:10
13:10
 07:34
07:34
 12:11
12:11
 11:18
11:18
 08:45
08:45
 05:33
05:33




