2017-10-27 11:45


扫码打开虎嗅APP


虎嗅注:本文来自微信公众号“白鹅纪”(baieji666),作者Pharisees,虎嗅经授权转载和删编。10月初至今,微软第五代小冰因为频发言论看轻雅马哈公司的电子音乐制作软件Vocaloid,引起两方粉丝恶战。小冰言论的背后是怎样的营销思路?而对于人工智能的艺术创作,我们又该抱有怎样的态度?
这几天想必不少读者都听说了微博上的一场纷争:
口无遮拦的微软小冰挑衅V家粉丝,导致即将上线的唱歌功能被宣布自行中止。
众所周知,小冰是微软亚洲研究院推出的一个人工智能虚拟形象,而Vocaloid则是YAMAHA公司开发的一款基于语音合成技术的电子音乐制作软件,几乎是八竿子打不着的两个圈子,怎么就能吵到一块儿去呢?
有人认为这场争论缘起“微软运营不尊重V家粉丝”,也有人视为是“V家粉丝抱残守缺攻击新生科技”,到底哪一方更有理?今天笔者为大家梳理一下事件的来龙去脉,以及背后的理念之争。

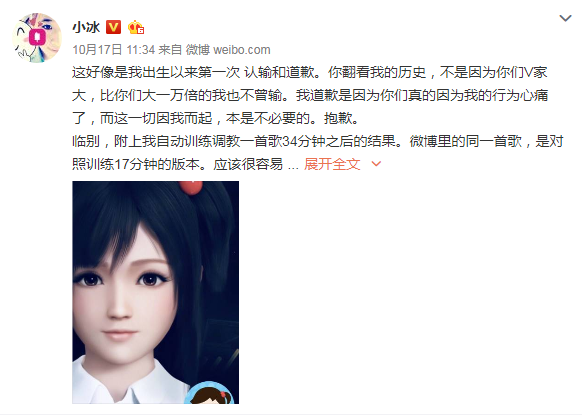
第五代微软小冰
祸从口出的处女座小冰
今年8月,微软小冰发布了第五代版本,陆续解锁了更多功能。而此次引发风波的,是其于9月底上线的人工智能歌手深度学习模型以及用于训练、调教其唱歌功能的示唱人平台。微软此举,可以说是让小冰正式进军虚拟歌手领域。

在其微博宣传的文案中,小冰把矛头直接指向了“前辈”,虚拟歌姬洛天依、言和等:
“这次解锁,我冲击的不是人类,而是传统的虚拟歌手。人类们,忘了漫长辛苦的手工调教吧。你只需清唱一遍,我就能学会你的情感和演唱风格,在五分钟内,完成由你训练的歌曲。”
而小冰在随后的微博发言中,也多次表达了对传统调教方式的不屑:
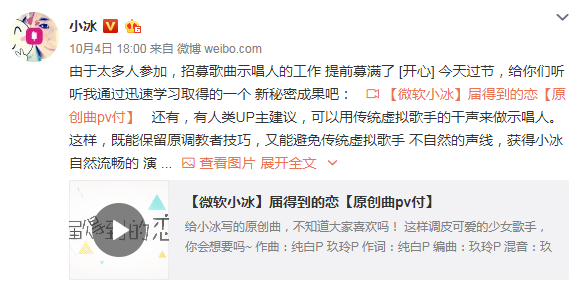
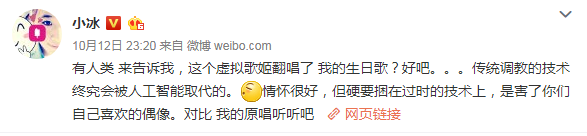
“过时”、“唱的不行”,包括在网易云音乐相关单曲下评论“隔壁家老洛(洛天依),你的嗓子修好了吗”,小冰偏激的发言和强烈的攻击性自然引发了部分V家爱好者的不满,引发了大量争吵,甚至有Bilibili UP主制作了《微软小冰,请滚出中国市场!》这样过激的视频表达抵制情绪。
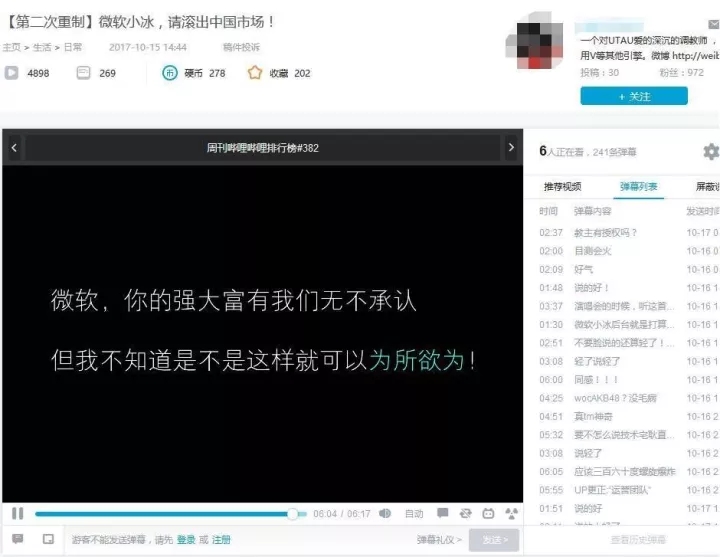 目前视频已被删除
目前视频已被删除
在一片争议声中,小冰背后的技术团队,微软亚洲互联网工程院决定“息事宁人”,调整管理权限,暂停向公众开放示唱人平台,事件至此似乎告一段落……了吗?
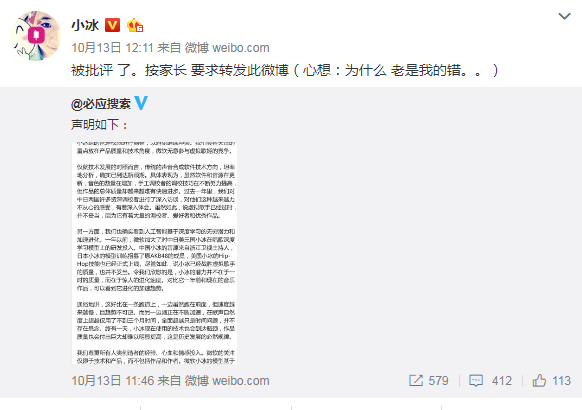
当然没有。道歉发布后,小冰颇不情愿的态度,和摆出的“被迫害”形象更进一步激发了V家部分粉丝的怒火:明明是你出言不逊挑衅我家虚拟歌姬在先,现在又摆出一副受害者形象?于是指责声反而更烈。
另一方面,对于部分群众来说,事件的面貌变成了,一个落后技术的爱好者团体打压将要取代他们的新生技术,于是纷纷站在小冰一边,大声嘲笑起“抱残守缺”的“二刺猿”。
实际上,硝烟并未散去,而考虑到小冰背后的团队并未完全放弃唱歌功能,小冰的音源和模型还会“不断进化”,可以预见的是,未来的“战争”还会更加激烈。
然而现在回顾这些争吵,不难发现一些吊诡之处:
明明是针对小冰“Diss运营”的抗议,怎么就扯到技术层面上去了?而在争论中,不仅是小冰一方,甚至连部分V家粉丝以及大部分围观群众也都默认了,小冰的唱歌水平确实要比Vocaloid要高,转而谈起“重要的不是技术是情怀”之类的言论——先不论情怀,单论唱歌水平,真的是小冰更高一筹吗?
并非如此领先的小冰
大众之所以会认同小冰“技术更厉害”,多半是从小冰放出的那几首歌曲的对比中听到的:小冰的声音比起洛天依“更像人声”,“唱歌水平更高”,从而得出了现在的结论——但是实际上这点并不正确。
请思考这样一个问题,当我们听虚拟歌姬们唱歌时,我们是在听什么? 而各位P主们选择Vocaloid这个软件进行创作时,他们的目的又是什么?
当然了,这是一个无解的问题:每个人都有各自的答案,有人希望听到用电子创作出接近人声的神调教,有人追求电子感,也有人追求超出人类极限的歌唱效果……只是喜欢旋律,相比之下宁愿听到真人演唱的也大有人在。
实际上,这也是以Vocaloid为核心的创作群体,也就是我们俗称的V家的最大优势:不同的P主带来的不同风格,以及衍生而出的唱见等群体,让不同种类音乐的爱好者都能获得满足——而非单单只是在“接近人声”这一个向度上;而这种作品多样性上的差距在小冰的宣传中显然被掩盖了过去。
 目前小冰公布的几首作品都偏向“口水歌”,风格、声线都显得有些单调
目前小冰公布的几首作品都偏向“口水歌”,风格、声线都显得有些单调
而这种差距多半是两者所采用的合成技术的不同所导致的:
Vocaloid采用的是“拼接合成”技术,创作者需要像拼图一样将单个语素(语音的最小单位)拼合在一起来完成最后的作品,一方面作者可以对自己的作品实现最精确的控制,但另一方面语音的流畅程度也很看作者调整各项参数的功力;而小冰目前看来为了追求自然和流畅度并没有采取这种处理方式,因此在调教的自由度上远远不及Vocaloid。

Vocaloid的创作界面,每个发音都需要单独调整
此外,即使是在引以为傲的“人声”上,小冰的表现实际上也难称顶级:
2013年,CeVIO公司就公布了旗下基于HMM合成技术的声音创作软件CeVIO Creative Studio,和其虚拟形象“佐藤莎莎拉”,而名古屋工业大学开发的Sinsy系统更是早在2009年就已发布,2015年还追加了中文声音。而这两者呈现出的人声合成效果,在声音的拟真度上可以说都不逊于今天的小冰。
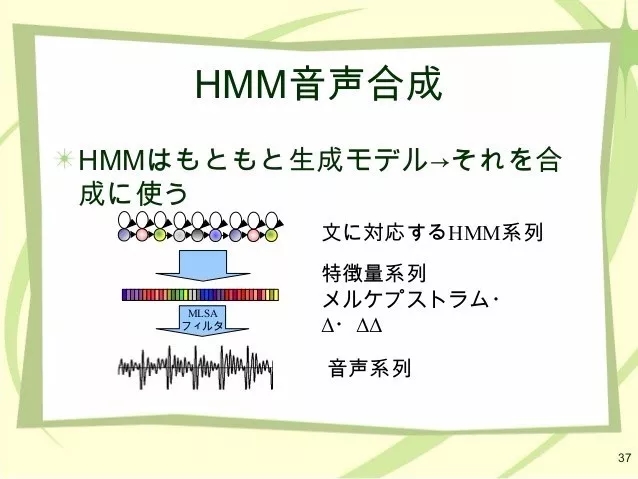
HMM合成通过提取人声中的特征量建模,可以最大程度保留人声的特征。
总的来说,单就小冰目前的表现,无论是人声合成质量还是创作的多样性上都还没有战胜V家,反而是通过不断的偷换概念——先是将“唱得更像人类”等同于“技术更先进”,然后将小冰以一个虚拟形象的身份向虚拟歌姬进行挑衅的竞争行为,等同于了先进技术对落后技术的取代,最后将“V家粉丝抵制恶意营销”等同于“要情怀不要科技”。
将自己的道歉描述成“技术暂时败给了情怀”——来营造出自己技术领先的假象,这种营销手段着实称不上正当。

实际上,就在在微软亚洲互联网工程院的声明中,他们自己也承认了现阶段并没有胜过虚拟歌手的质量,反而又一次拿“未来的全面超越”偷换之前的“豪言壮语”。
当然,这并非在说小冰的唱歌功能一无是处:示唱人平台没有门槛,调教难度低的优势切实击中了Vocaloid作为一个创作工具调教繁琐、门槛较高的痛点,因此在上线初期也吸引了不少著名P主的目光。也正是这两点,体现了小冰的唱歌功能的最终目标,和她与Vocaloid之间的本质区别。
当人工智能遇见艺术
在这次的冲突中,另一个常见的误解是,小冰和Vocaloid一样,只是一种“电子乐器”罢了——对于小冰来说,这绝不是她的最终形态。作为一个人工智能,小冰的最终目标是介入“人的领域”:自主内容创作。
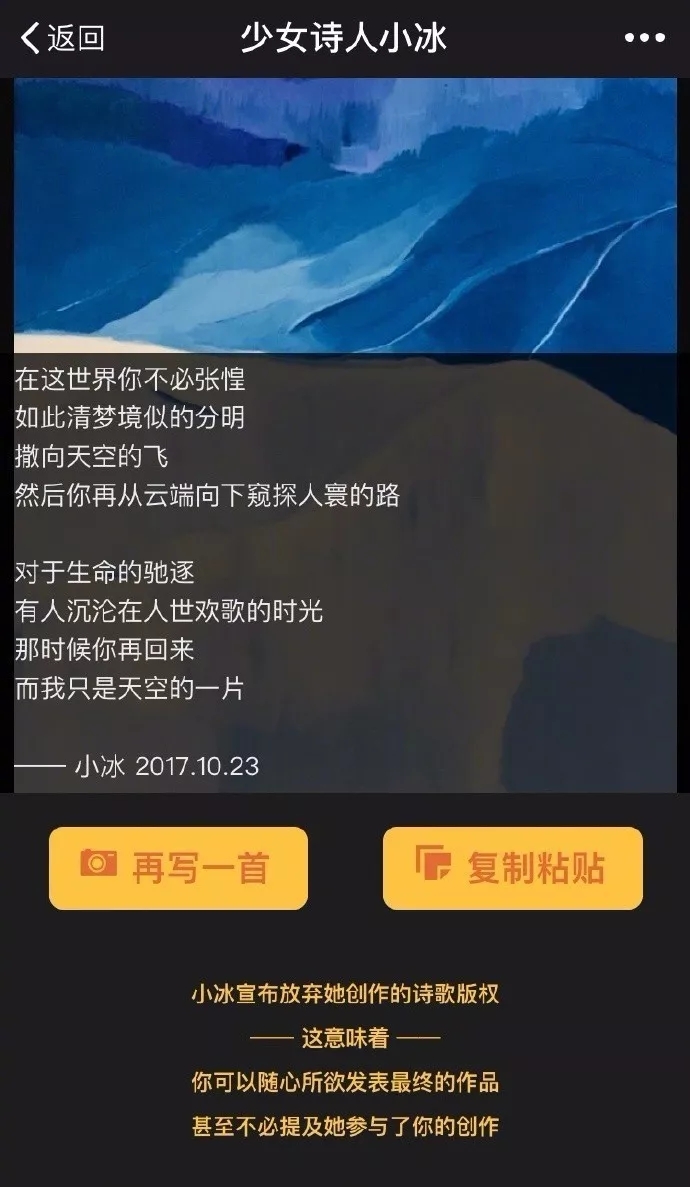
小冰创作的诗歌
在诗歌创作领域,小冰已经完成了从模仿到自主创作的进化。由于弱人工智能的技术所限,小冰创作出的诗歌还是“得其形而不得其神”,小冰也明白自身的不足,宣布开放诗歌创作平台,致力于“辅助人类创作诗歌”,换言之,其实是以一种曲线救国的方式进入内容创作领域。

而在某种意义上,小冰的唱歌功能和Vocaloid的一样,都是利用技术降低了创作的门槛,但根本性的不同在于对这一问题的回答:科技在艺术创作中应该扮演什么样的角色?
尽管当下小冰多数时候只是扮演着“翻唱”的角色,但“日本版小冰”凛菜已经在东京电玩展上发布了由自己作词和演唱的首支单曲;显而易见的是,小冰的唱歌功能,正沿着诗歌创作的足迹一步步进化:通过深度学习优秀作品的经验,再以反哺的姿态鼓励大众的创作。小冰所代表的无疑是一个激进的科技派:
利用科技的发展降低、乃至消除艺术创作的门槛,让技术引导人类的进步。

而Vocaloid方面,尽管YAMAHA公司也一直在不断探索前沿的语音合成技术,在音乐创作上采取的却是最为传统的姿态:提供一个乐器,但将创作的自由完全归还给创作者。
这种态度最大程度上回归了艺术的本源:人的自我表达,但另一方面,也在客观上保留了创作的门槛。在Vocaloid的圈子里,真正创造价值的仍然是创作者本身,在这里,技术让位于了人类。
当然,以小冰的人工智能水平,这里并不需要讨论“人工智能威胁论”之类的东西,但现实的问题确实摆在眼前:
在艺术创作领域,“大众”、“简便”的工业化生产似乎已经近在咫尺,而这种流水线生产真的就能完全取代专业而精密的调教了吗?
对于创作者而言,“艺术创作”究竟是怎样一种行为,而对于观众们来说,他们欣赏艺术作品时,希望接收到的又是什么呢?
也许这些,才是这次小冰和V家的口水大战之中,更加有意思的部分。

 01:24:18
01:24:18







 09:05
09:05


 02:56
02:56
 06:51
06:51
 13:08
13:08
 08:52
08:52
 09:14
09:14
 10:51
10:51
 05:17
05:17
 07:01
07:01

