2017-12-19 15:25


扫码打开虎嗅APP

虎嗅注:对吴恩达研究的人工智能自动处理医疗影像的技术,如今有《Nature》论文作者发出了质疑。针对AI处理医疗影像是否准确和全面,还有这种技术目前应用于医疗的意义和必要性,该作者在这篇文章中进行了分析。
本文转自微信公众号机器之心(ID:almosthuman2014),作者:Luke Oakden-Rayner,编译:机器之心。
自动处理医疗影像一直是人工智能的重要发展方向之一,吸引了很多知名学者参与其中,并已出现了很多引人注目的成果。近期斯坦福大学吴恩达等人提出的 CheXNet 便是其中之一。
研究人员在其论文中表示:新技术已经在识别胸透照片中肺炎等疾病上的准确率上超越了人类专业医师。然而,另一群学者对目前的一些研究产生了怀疑。本文作者 Luke Oakden-Rayner 是阿德莱德大学的放射科在读博士,曾作为第一作者于今年 5 月在 Nature 上发表文章介绍了自己利用深度学习等技术预测人类寿命的研究。
如果你关心机器学习和医学,请阅读这篇重要而深刻的文章。
——Gary Marcus,纽约大学教授
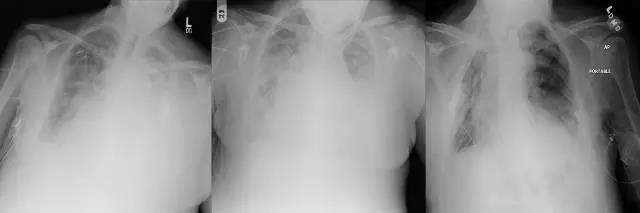
几周前,我曾提到自己对于 ChestXray14 数据集有所担心。我曾说过在自己掌握更多信息后会深入探讨这个问题。在这段时间里,我深入挖掘了数据结构与内容,并与 Summers 博士(数据集提出者之一)用邮件进行了交流。不幸的是,这些行动只是加剧了我对数据集的担忧。
免责声明:我认为本文不能反映深度学习在医疗领域应用的广泛观点,或是主张人类表现是无法超越的。本文的观点基于我对近期研究发展的考量。该结果仅针对 ChestXray14 数据集,代表了我们在面对医疗数据时面临的挑战。这一挑战是可以被战胜的,在未来的文章中,我会介绍战胜它们的方法。
让我们先给出结论,我认为目前的 ChestXray14 数据集不适用于训练医用人工智能系统进行诊断工作。为了清晰证明我的观点,我将在本文中讨论以下几个问题:
标签的准确度。
标签的医学意义。
标签对于图像分析的重要性。
本文的大部分篇幅都将用于介绍我的立场,但是首先我们先要谈谈引入这个数据集的论文《ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases》。
我必须指出,自首次发布以来,该数据集的论文和支持文档已经更新过多次——自我开始谈论此事之后至少已经更新过两次。尽管如此,在通读了文档后,我仍然认为我的观点是合适的。
在我看来,该论文需要花更多的时间解释数据集本身。特别是在该数据集的大量使用者是计算机科学研究人员,缺乏临床知识的情况下,这种需求就显得尤为迫切了。然而,这篇论文主要介绍了文本挖掘和计算机视觉任务,其中有一张图(第八页)、一个图表展示了数据集中标签的准确性。
以下文本挖掘的性能测试结果是在论文发表于 CVPR 之后添加的(这篇论文是 CVPR 2017 的 Spotlight):
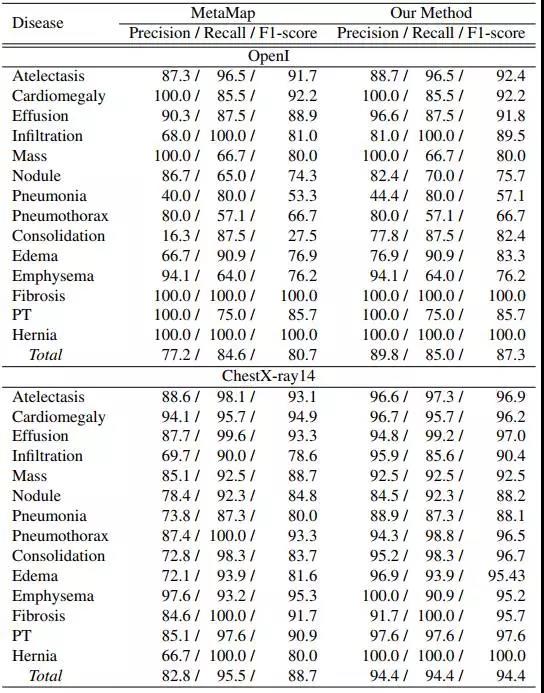
这张列表展示了一些有意思的东西,其中展示的原始结果(上半部分)是在公开的 OpenI 数据集上进行测试的,其中不仅包括报告,也有人类打上的完整标签。例如,如果一份报告说道:“有基底固结”,就会使用标签“固结/基底”。
而列表中下面的部分是 ChestX-ray14 自己的数据,这个部分自从论文的第一个版本以来一直存在。为了制作测试集,研究人员随机选择了 900 份报告,并有两位注释者(在这里我们假设他们都是专业的放射科医师)进行标注,他们共同分类了其中的 14 种疾病。这里需要注意的是,这些注释者并没有直接检视图像(据我所知)。
在列表中,我们可以看到算法在几乎所有分类中都有了很好的结果,尤其是在他们自己的数据上。这里唯一的限制是每个类别的流行程度,很多罕见疾病的流行程度约为 1-3%。
在此我们假设在随机选择报告时研究人员并没有刻意挑选样本——这样测试集中的很多结果都含有 10-20 个范例。这本来不是问题,但数据体量的限制会让误差变大(如果一个类别中的样例数量为 10-30,只有一个错误,那么 95% 置信区间的阳性预测值会在 75%-88%)。
但如果允许一些偏差值,每个标签看起来准确度都在 85-99%,至少准确反映了报告结果。
永远关注图像本身
放射科!高高兴兴来,然后留下了颈椎病。
不幸的是,似乎标签无法准确地反映病况。稍后我会介绍一些可能的原因,现在我们先来看我是如何得出该结论的。
其实我也查看了这些图像,因为我是一名放射科医生。在看 x 光片方面我不比别的放射科医生好,也不比他们差,但是我应该比压根不看这些图像的人要好一些吧。NIH 团队没有表明他们看过这些图像,他们通过测试标签是否匹配报告文本来判断图像标注过程的优劣。我认为这种分离导致了我所提出的标签质量问题。
有很多方式可以在不需要图像的情况下构建图像标签。你可以依赖已经存在的标签,如 ICD 编码;你可以从报告或其他免费文本中提取标签;你还可以使用增补数据(follow-up data)。
但是你必须看这些图像。在计算机视觉领域,这叫做“完整性检查”(sanity check),是一种简单的软件功能测试方式。在深度学习中,我们查看训练曲线、检验梯度、尝试在没有正则化的情况下训练来测试是否产生过拟合。查看这些图像是放射学的完整性检查——查看图像,确保它们和期望的一样。
它们不必要完美,如果你在整合一些可能不在图像上的信息(如增补数据),那么或许会有一些视觉上看不出来的疾病。这没什么问题,但是你仍然需要查看图像。
确切地记录如何根据图像信息定义类别似乎很难,但是你仍然需要查看图像。一般我们只需要每个类别留出一个小的随机子集,且每个子集至少需要包括 100 张图像,因此我们就可以对它们随意地进行评估。这样花费的时间不会太长,我通常 10 分钟看完 200 张图像以完成“完整性检查”的初级阶段。
第一部分:ChestXray14 数据集中的图像标签准确率
这部分要说该数据集中基于标签的图像。它们是随机选取包含 18 张图像的序列集,并非精挑细选。
我尽量保持谨慎,当一个案例模棱两可的时候,我选择标出标签类别。在所有图像中,红色 = 明显错误的标签;橙色 = 怀疑态度,我没有指出这个问题,但是不能排除这种怀疑。(出于临床诊断的习惯 :p)
肺不张(Atelectasis)
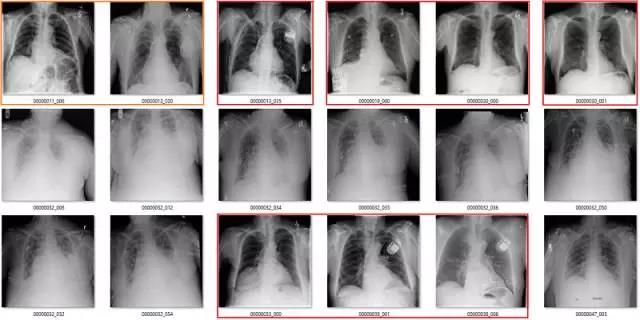
心脏扩大(Cardiomegaly)
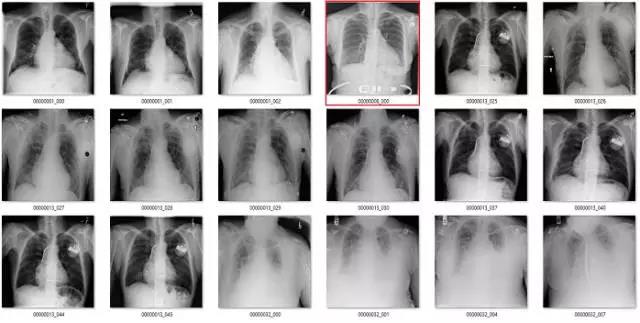
纤维化(Fibrosis)
我的标签并不完美,其他放射科医生可能对其中的一些标签有疑惑。但是必须明确一点,我的标签和论文/附录中的结果有极大的不同。
我通常喜欢硬数据,因此我尽力量化标签准确率。事实上我发现其中的很多标签都很难定义,因此下表中未列出。我查看了每个类别中的 130 多张图像,根据我的视觉判断计算原始标签的准确率。这个数据量比较适合使用,因为 95% 的置信区间可能再扩大 5% 左右,所以我的误差率可能达到 20% 左右。
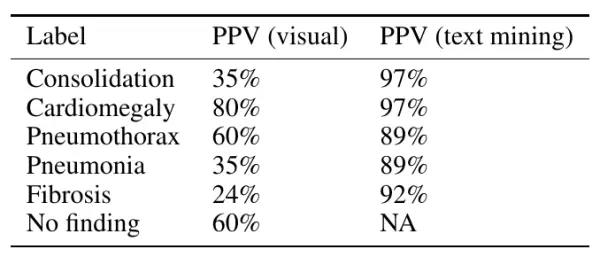
我的视觉分析 vs. 论文中的文本挖掘结果
我再次怀疑我的标签到底对不对,尤其是和一队胸部放射科医生的判断结果相比,但是如上表所示,差别也太大了。我认为上表中的数据证明这些标签无法匹配图像中显示的疾病。
也有办法解释这种现象。比如最初帮助解释图像的放射科医生具备图像以外的信息。他们具备临床经验、之前的诊疗结果等。这些信息非常有用,尤其是在区分类似疾病的时候。
由于未获取报告,我无法评价他们在实验中的作用。但是从个人临床经验出发,我知道这些额外信息大概能提供 10% 的影响,即使它们很少能够显示明确的诊断结果,但它们对医生的诊断确实有帮助。
如果人类专家无法仅从图像中做出诊断,那么 AI 系统很可能也无法诊断。AI 可能能够找出一些人类忽略的细微证据,但是凭借这些就可以产生性能上的巨大差异并不合理。总体来看,我们需要标签和图像包含同样的信息。
如果 Wang et al. 的团队声明因为不可获取的数据,他们的标签比我的视觉判断好,且差距悬殊,那么我至少想看到论文中出现一些讨论来解释这个过程,特别是在报告没有公布的情况下。
第二部分:这些标注在医学上意味着什么?
这引出了第二个问题,且我在前面部分也讨论了这个问题。这些标注实际上代表什么?它们能够反映临床实践吗?
我认为答案是否定的。
最难解析的标签是固结/渗透/肺不张/肺炎集聚等。这里不做详细的讨论,但并不表明它们仍然困扰着我。尽管我们花大量时间查看这些图像,但我并不能更明确地区分这些不同的类别。
这些医学影像还存在其它问题,与任务的临床价值有关:
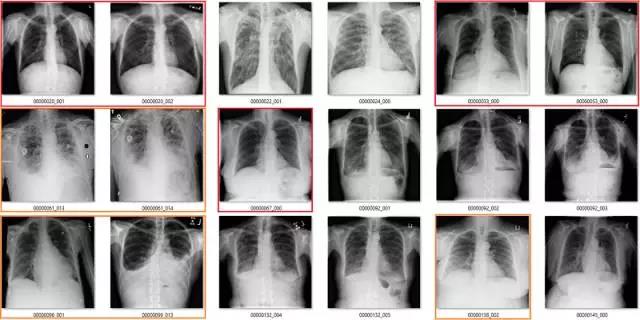
渗出(Effusion)
在该案例中,蓝色的标签表示它们存在显著性的肺部疾病。
渗出(effusion)表示在肺部周围空间有积液。造成该病变的原因非常多,但主要原因分为由胸膜和肺部疾病引起的积液。
我并不清楚什么确定或代表了显著性肺部疾病中有积液存在。在很多情况下,甚至直观地识别这些积液都是不可能的,只不过我们知道积液会存在,所以我们也就这样描述它了。上图最后三个肺部影像就是一个非常好的例子,在我看来,这些病例的主要病理还是固结(consolidation)。
我可以看到识别较小和分离的胸腔积液的价值。上图中约有 6 张影像是这样的情况,包括第一张和第三张。没有肺部疾病来表明积液的成因,这令标签“积液”越发突兀。
我还可以看到识别较大积液的好处,它们可能需要我们的介入进行治疗,如使用器械将它们排出。第 10 张图就正好是这样的案例。所以其实我并不太了解标签的含义,因为不是基于临床实践的指导思想并不是很有用。
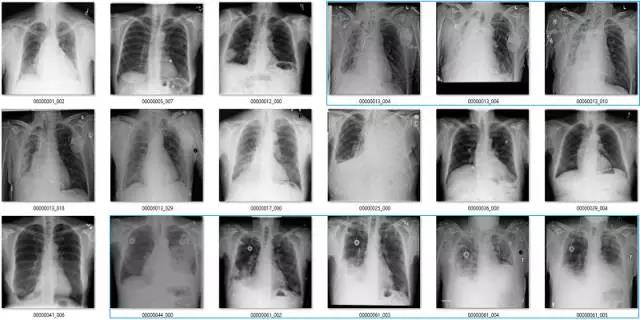
气胸(Pneumothorax)
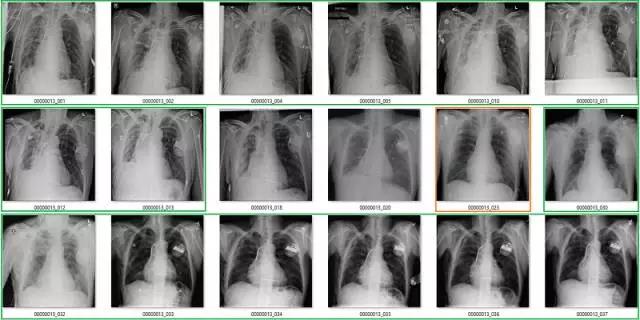
气胸是指在肺部周围的胸膜腔空间有气体。这可能导致肺部瘫痪,因此它是非常严重的病变。但实际上,气胸在 X 光影像上非常微小,经常会被人忽略掉。
初次看来,标签似乎非常有效。在这 18 个样本中,只有用橙色标出的那张影像有点问题,这也可能是因为我没在诊断环境下查看肺部影像的原因。
但是绿框也有点问题,因为这些病人已经使用胸腔引流治疗过气胸。因此,现在有以下两个问题:
这并不是医学上重要的问题,我们希望避免气胸未被诊断出的错误,而这些图像标签确实没有犯这种错误。
如果很多影像都通过胸腔引流治疗,AI 系统将会学习识别胸腔引流而不是气胸。模型训练时的大多数图像样本批量完全可能包含有胸腔引流的气胸。
纤维化(Fibrosis)
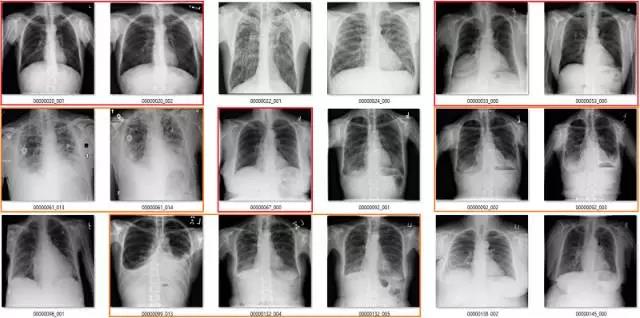
我们已经看到,纤维化的标注准确率非常低。在这些影像中,红框是不正确的标签,橙框是我不确定的标签。在胸腔积液和固结中可能也会出现纤维化,但这些是影像无法告诉我们的。
实际上还有多种其它非图像临床问题,例如:
肺炎、肺气肿和大多数纤维化都是临床诊断问题而不是医疗影像问题。
X 射线会漏掉多达 50% 的囊肿,因此我们可能会怀疑报告所采用的囊肿标注。
没有人关心间断性疝气,所以它们只是有时候进行诊断。
实际上,每个标签的类别都会受到不同程度的质疑,只不过我强调的是最值得质疑的部分。它们足以说明,找到那些优秀的数据集或正确的标签以学习高效的医疗任务是十分困难的。同样,我们还是需要专家查看这些影像来进行医疗诊断。
第三部分:这些图像对图像分析有什么好处?
这是本评论最重要的部分。放射学的深度学习应用有一个大问题,如果不查看图像,后果将非常严重。
如果这些标签很不准确,并且标签的意义也不可靠,那么建立在这个数据集上的模型是如何能达到不错的结果的呢(正如论文中所报告的)?模型实际上学习的到底是什么?
前一阵子有一篇很流行的论文
(Understanding deep learning requires rethinking generalization,Zhang et al.)表明了深度学习无法在训练数据中拟合随机标签。我不认为这个结论对研究深度学习模型的人来说是意料之外的,但很多人以此作为反对深度学习的证据。
实际上,我们在寻找可以学习正确地在测试集上输出真实结果的模型,即使所谓的真实结果在视觉上毫无意义。
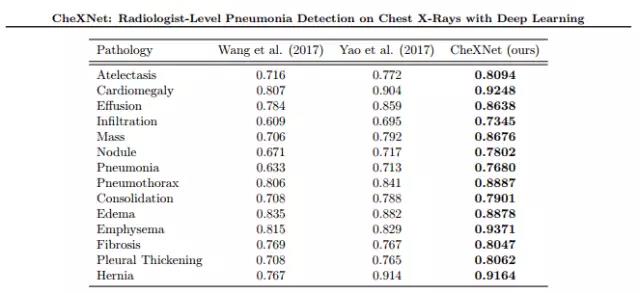
来自 CheXNet 的结果:使用深度学习模型(Rajpurkar and Irvin et al.)在胸透图上进行放射专家级的肺炎检测,在测试集上获得了不错的性能。
现在,一些深度学习拥护者会争辩说,适当的标签噪声是可以接受的,甚至还有好处。
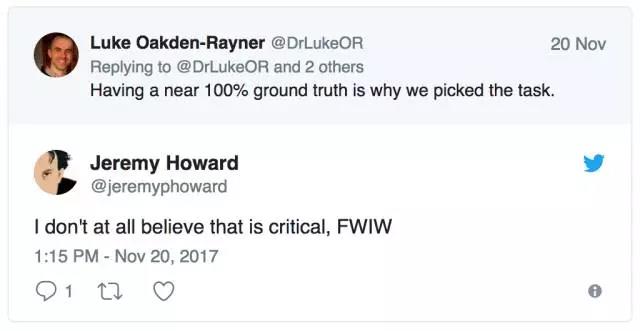
我基本同意 Jeremy 的观点,虽然这依赖于任务类型和噪声类型。随机噪声可以作为不错的正则化项,甚至还可以在某些设置中提升性能(这种技术被称为标签平滑或软标签)。结构化噪声不一样,它添加了完全不同的信号,而模型将尝试学习这些信号。这等价于训练一个模型学习识别肺炎,但其中 10% 的肺炎标签还包括狗的相关标签。
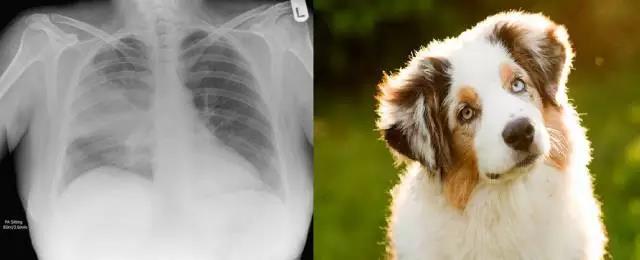
在一个包含坏标签的训练集中,神经网络将把这些标签看成同等有效的肺炎样本。如果模型学习了这些标签,例如,“毛茸茸”是肺炎的一个信号,然后模型将应用这个信号到胸透图中,输出无法预测的结果。
模型将使用部分从狗类图像中学习的特征,并应用到胸透图中,尽管这和问题本身无关。
如果你的目标是最大化性能,那么结构化噪声总会带来负面影响。噪声甚至不需要很明显(其中的关系是非线性的),而偏差标签将降低模型的准确率。
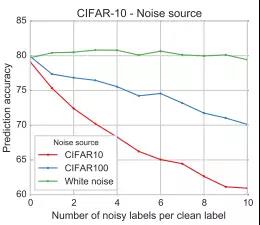
Rolnich 等人《Deep learning is robust to massive label noise》的结果表明,结构化噪声破坏了标签,并使得性能下降。当噪声与实际数据来源相同时,这个问题可能更麻烦,因为模型会混淆噪声与类别。这可以类推到 ChestXray14 数据集中,它们的标签同样遭到了破坏。
所以从直观来看,这些标签会损害模型的性能。那么为什么在 ChestXray14 上训练的模型有非常好的性能?难道是这些模型可以补偿数据噪声而变得鲁棒性吗?
我并不这样认为,实际上我们需要关注更多的方面。其实在为数据集构建一组新标签的过程中,我通过创建一个“opacity”类和一个“no finding”类来简化涉及的任务。我用原来的标签设置了新创建的标签,“opacity”是肺不张、肺炎、固结和渗透标签的组合,然后我们在上面训练一个模型。
正如前面所说的,一个优秀的模型将完成这些探索性工作,所以我只需要采用一个在 ImageNet 预训练的 ResNet,并在新的数据集中训练后部分的网络。我并没有调整超参数,只是在一个合理的时长内训练模型,最后模型的性能还是比较优秀的。
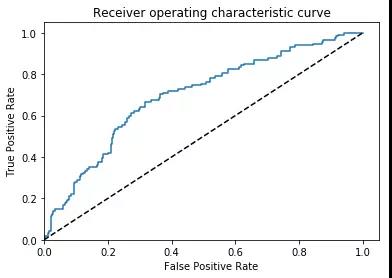
AUC = 0.7
该模型的表现非常像 Summers 等人的研究,我的模型可以明确地从这些标签中学到一些知识,但模型具体学到了些什么?
以下是模型的预测以及它们与数据集中的标注所做的比较:
真正类
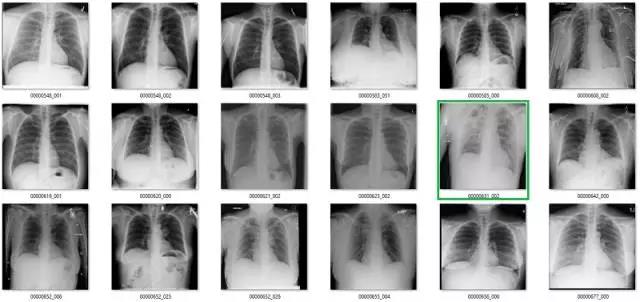
绿色是真正类,其它的是错误的标签。
真负类
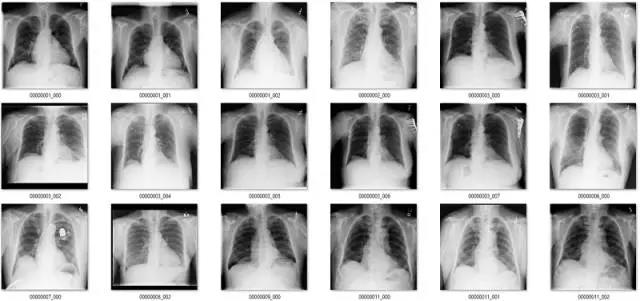
前 18 张有 1 到 2 个有争议,后面 18 张中红框都是错误的。
假正类
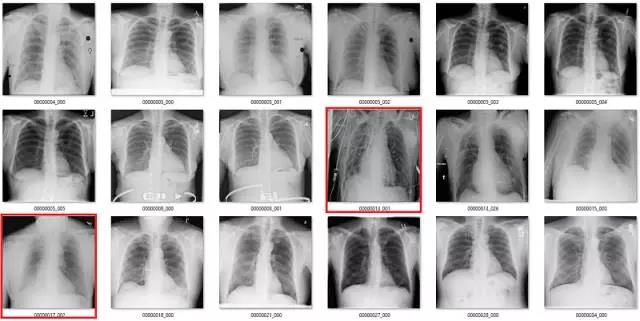
红色的都是错的,数据集中也出现了旋转和扭曲等异常情况(用红色问号标记)。
假负类
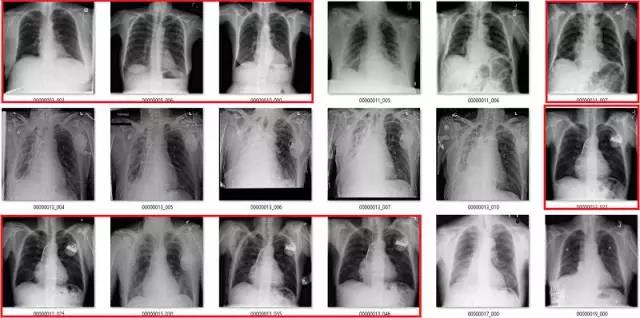
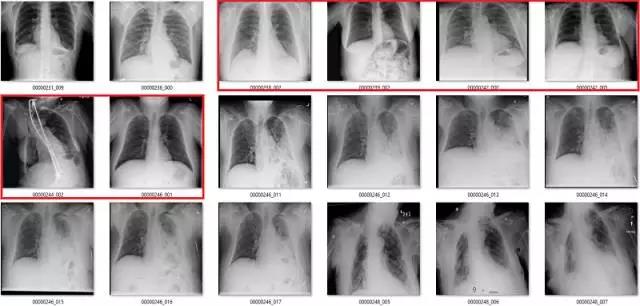
红色部分为严重错误标注。
尽管 AUC 是 0.7,但与标签错误率一致,我们的分类性能非常糟糕。该模型无法忽略错误的标签,输出合理的预测,它对标签噪声不具备鲁棒性。最重要的是,AUC 值没有反映诊断性能,这是一个很大的问题。
这一 AI 系统学习可靠地输出无意义的预测。它学习图像特征的方式使“opacity”的案例变得几乎没有模糊性,而“no opacity”的案例被判断为严重不正常的肺。
这就是问题,因为除非你看了图像,不然就会以为结果很棒。每个团队的模型性能都越来越好,AUC 分越来越高,看起来它们似乎正在“解决”一项严肃的医疗任务。
我认为其有多个原因;医疗图像很大又复杂,共享很多普遍元素。但是,自动挖掘标签的方法没有引入不准确的随机噪声。文本挖掘的编程本质会导致持续、意料之外的数据依赖或分层。这让我回想起美军开发神经网络用来识别二十世纪五六十年代坦克伪装的故事。
大约半个世纪前我在洛杉矶参加一个会议,有人发表了一篇论文,展示了一个随机网络如何被训练来检测图像中的的坦克。当时我在观众中,演讲结束后,我站了起来并表示,很明显带有坦克的照片是在晴天制作的,而另一张照片(没有坦克的同一片场地)是在阴天制作的。我认为“神经网络”只是训练自己去识别明亮图像和暗淡图像之间的区别。
——Edward Fredkin 与 Eliezer Yudkowsky 的通信
同样,斯坦福大学皮肤科的 Novoa 博士最近也在媒体上讨论过这个问题:
当皮肤科医生查看一种可能是肿瘤的病变时,他们会借助一个尺子——就是你在小学时用的那种——来准确测量它的大小。皮肤科医生这样做是为了查看病灶。因此,在一组活检图像中,如果图像中有尺子,算法更可能将其判断为恶性肿瘤,因为尺子的存在与病症癌变的可能性相关。
不幸的是,Novoa 强调,该算法不知道为什么这种相关性是有道理的,所以很容易误解为一个随机的尺子是诊断癌症的根据。
这里的关键信息是深度学习非常非常强大。如果你给它输入带有偏见标签的复杂图像,它可以学习对这些类别进行分类,尽管它们毫无意义。它可以学习“pneumonia-dogs”。
这与 Zhang et al. 的论文结果不同。
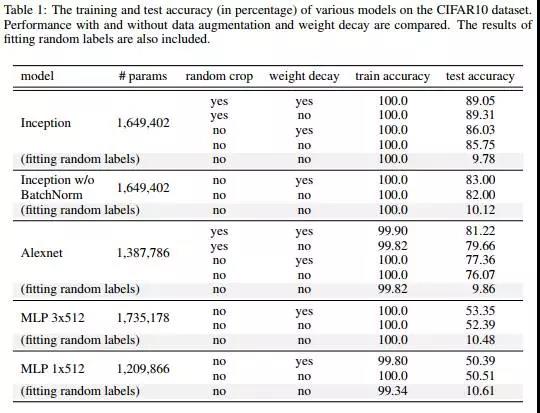
他们表明,你可以完美拟合训练集中的随机标签。实际上,这一结果仅仅表明深层网络足够强大,能够记忆训练数据。他们没有展示测试数据的泛化,相反,他们展示了噪音损害的性能。我确实在 ChestXray14 数据中通过随机标签做了一个快速测试(另一个完整性检查),发现与 Zhang et al. 的相同结果;并且该模型没有泛化到测试集。
这里的根本问题不同于 Rolnich et al. 和 Zhang et al.,因为结构化噪声不仅存在于训练数据中。整个测试数据中的标签误差也是一致的。这意味着如果模型学习做出不良的医疗预测,那也许它可能会获得更佳的测试表现。
这种情况可能仅针对通过自动“数据挖掘”方法生成的标签,但是我也发现了人工标签导致放射科数据分层的多种方式。
我想简单地补充一下这最后一点,因为对于任何使用医学图像数据的人来说,这是一个非常重要的问题。放射学报告不是客观的、事实上的图像描述。放射学报告的目的是为他们的推荐人(通常是另一位医生)提供有用的、可操作的信息。在某些方面,放射科医师猜测推荐人想要的是什么信息,并且剔除那些不相关信息。

当解释胸部 X 光片时,想象一下临床医师面临的最大恐惧是什么,& 如果它不在,就说它不在,比如“没有活性 TB 的证据”。
这意味着根据临床情况、过往历史和推荐人(通常根据个人推荐人的偏好量身定制)以及放射科医师是谁,相同图像的两份报告可以被贴上不同的“标签”。
一个极其异常的研究往往被报道为“没有明显变化”。向专家提供的报告可能会描述一个严重疾病的典型发现,但从不提及该疾病的名称,因此不会强迫专家采取特定的治疗对策。给全科医生的报告可能会列出若干种可能的疾病,包括治疗策略。影响每一张放射学报告的因素有很多,所有因素都会给放射学报告带来结构性噪音。每个小案例都可能有独特的可学习的图像特征。
我已指出一个可能的图像偏差。气胸组中的模型可能正在寻找胸腔引流管。事实上几乎每个带有大口径胸腔引流管的患者都有气胸,但这并不意味着气胸是可见的或重要的。
还有很多其他视觉元素可将患者分成几组,包括图像质量(根据患者是门诊病人、住院病人、重症监护等而不同)、导入装置如起搏器或心电图导联的存在、身体习性等等。这些因素都不是“诊断性的”,但它们很可能与标签有不同程度的相关性,深层网络要找的很可能就是这样的东西。
医学研究人员长期以来一直在处理临床数据的分层管理。这就是为什么他们花费如此之多时间来描述其数据集的人口统计性特征,像年龄、性别、收入、饮食、运动等许多其他事情都会导致“隐藏”分层。我们在基本层面上也应该如此。检查你的训练和测试数据中的人口统计学特征是大致相似的,但这还不够,我们还需要粗略地知道整个群组的视觉外观分布是相似的,这意味着你需要查看图像。
不要误解我的意思,这些问题并不意味着深度学习应用于医学影像是毫无价值的。深度学习最重要的一点是它奏效。虽然我们现在还不明白为什么,但是如果你给到深层网络很好的标签和足够的数据,它将优先为这些类别学习有用的特征,而不是无意义的琐碎特征。
事实上在浏览我正在构建的标签时,我将在下一篇文章中展示深层网络确实能从这些图像中学习胸部 X 射线的相关有用信息。
TL:DR
与人类视觉评估相比,ChestXray14 数据集中的标签不准确、不清楚,并且经常描述医学上的次要发现。
这些标签问题在数据之中是“内部一致的”,这意味着模型可以展示“良好的测试集性能”,同时仍然产生不具有医学意义的预测。
以上问题表明目前定义的数据集不适合训练医疗系统,对数据集的研究不能在没有附加正当理由的情况下生成有效的医疗声明。
查看图像是图像分析的基本的“完整性检查”。如果你构建数据集时,没有能够理解你的数据的人在查看图像,那么期望数据集奏效将非常错误。
医学图像数据充满分层元素;有用的特征几乎可以学到任何东西。查看你的模型是否每一步都照常运行。
我会在下篇文章中发布一些新标签,并表明只要标签足够好,深度学习就可以在这个数据集中工作。
附录 1:来自 ChestXray14 team
由于我与该团队合作过,该数据集文档已经被更新过多次。他们在论文中并没有关于该数据集的更多讨论,因此他们将这一部分放在了数据集 FAQ 里:
问题 08:对图像标签准确率的普遍担忧。
回答:关于已发布的图像标签,我们有几件事情需要阐明:
同样的诊断可能会使用不同的术语和习语:这些图像标签是使用 NLP 技术从放射医学报告中挖掘出来的。那些疾病关键词完全是从报告中提取出来的。放射专家通常使用他们自己偏好的(关于每个特定的疾病模式或多种模式的)术语和习语描述诊断结果,其中在描述中使用所有可能的术语的可能性是很小的。
应该使用哪个术语:我们明白,仅仅基于图像的诊断分辨确定的病理学症状是很困难的。然而,也可能存在多种其它来源的信息可用于放射学诊断(例如,检查原因、病人病历和其它临床资料)。报告中使用的诊断术语(例如肺炎)是基于所有可用信息而决定的,而不仅仅是图像诊断。
使用 NLP 提取实体是不完美的:我们尝试通过消除疾病说明中的所有可能的否定词和不确定案例以最大程度地发现准确疾病诊断的召回率。诸如“很难排除...”的术语会被当成不确定案例,然后对应的图像会加上“No finding”的标签。
“No finding”和“normal”是不一样的。被标记“No finding”的图像可能包含除列出的 14 种疾病模式之外的模式,或者在 14 种疾病模式之内的不确定诊断。
我们鼓励其他人分享他们自己的标签,最好是来自一群放射专家的数据,从而还可以获得观察者可变性的信息。我们已发布的图像标签仅仅是鼓励其他研究者关注在大型数据集上“自动地解读胸透图”的第一步,这些标签还需要社区的帮助以提升质量。
我真的很感谢作者们将这些对我的问题的回答放进他们的文档中。我是在收到这些回答之后才开始写这篇文章的,我并不认为他们充分地解决了我的担忧。
附录 2:Re:CheXNet
CheXNet(Rajpurkar and Irvin et al.)是吴恩达和他在斯坦福大学的团队建立在 ChestX-ray14 数据集之上的研究,因声称该模型在胸透检测肺炎的表现“超过放射科专家”而受到社交媒体的广泛关注。如下图所示,吴恩达本人表示:
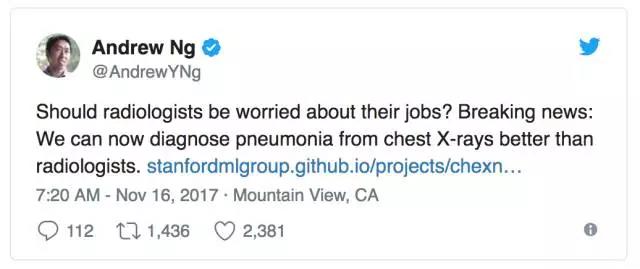
相关链接:https://stanfordmlgroup.github.io/projects/chexnet/
这篇论文稍微超出了本篇讨论的范围,因为和使用 ChextXray14 一样,他们需要人类医生对测试集之一(即他们声称和人类作比较的数据集)进行可视化检查并标记图像。这种策略大概可以解决上述我列举的大部分问题。
我尚不确定如何把他们的结果整合到我的分析中,因为它们在原始标签和人类标签上都表现很好。我相信他们是独立地训练模型分别进行两个测试的(即在两个数据集上得出好成绩的并不是同一个模型)。
我最近正与该团队联系,未来将与他们进一步讨论该论文。
 14:20
14:20









 10:22
10:22
 13:10
13:10
 16:10
16:10
 12:33
12:33
 15:46
15:46
 20:24
20:24
 05:47
05:47
 05:56
05:56
 08:15
08:15




