2023-11-27 15:07


扫码打开虎嗅APP

本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,原文标题:《田渊栋给OpenAI神秘Q*项目泼冷水:合成数据不是AGI救星,能力仅限简单数学题》,题图来自:视觉中国
Q*猜想,持续在AI社区火爆。
大家都在猜测,Q*是否就是“Q-learning + A*”。
AI大牛田渊栋也详细分析了一番,“Q*=Q-learning+A*”的假设,究竟有多大可能性。
与此同时,越来越多人给出判断:合成数据,就是LLM的未来。
不过,田渊栋对这种说法泼了冷水。
我部分不同意“AGI只需通过放大合成数据就能解决”的说法。
搜索之所以强大,是因为如果环境设计得当,它将创造出无限多的新模式供模型学习和适应。
然而,学习这样的新模式是否需要数十亿的数据,仍是一个未决问题,这可能表明,我们的架构/学习范式存在一些根本性缺陷。
相比之下,人类往往更容易通过“啊哈”时刻,来发现新的范式。

而英伟达高级科学家Jim Fan也对此表示同意:合成数据将发挥重要作用,但仅仅是通过盲目扩展,并不足以达到 AGI。

Q*=Q-learning+A,有多大可能
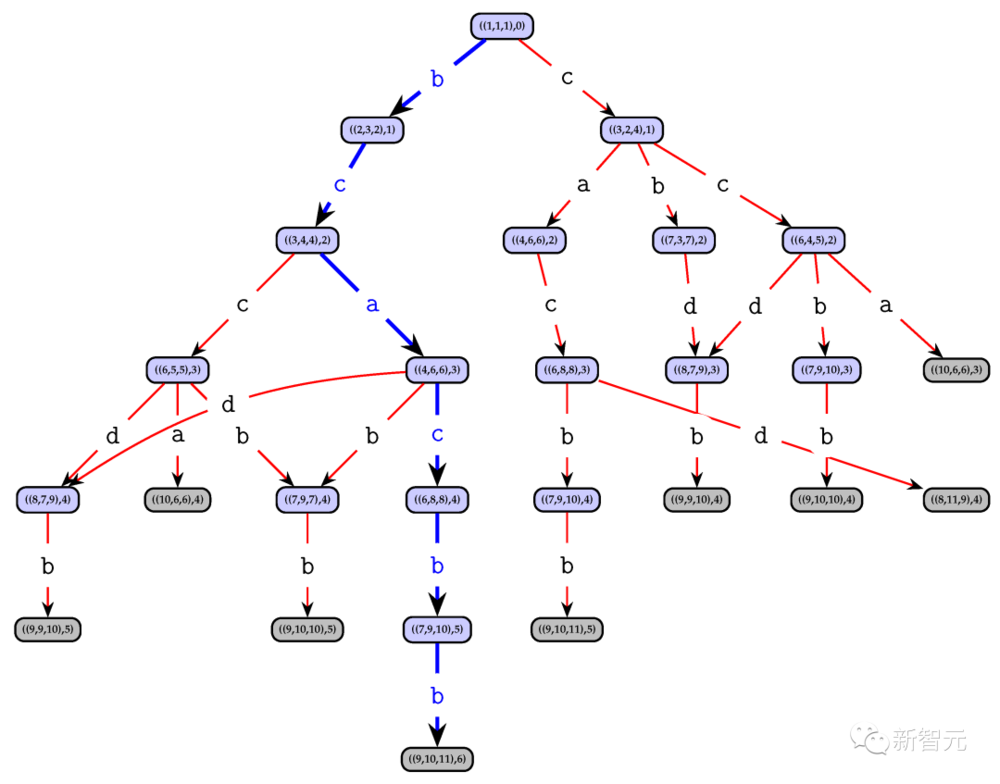
田渊栋表示,根据自己过去在 OpenGo(AlphaZero 的再现)上的经验,A* 可被视为只带有值(即启发式)函数Q的确定性MCTS版本。

A*很适用于这样的任务:给定行动后,状态很容易评估;但给定状态后,行动却很难预测。符合这种情况的一个典型例子,就是数学问题。
相比之下,围棋却是另一番景象:下一步候选棋相对容易预测(只需通过检查局部形状),但要评估棋盘形势,就棘手得多。
这就是为什么我们也有相当强大的围棋机器人,但它们只利用了策略网络。
对于LLM,使用 Q(s,a)可能会有额外的优势,因为评估 Q(s,a) 可能只需要预填充,而预测策略a = pi(s) ,则需要自回归采样,这就要慢得多。另外,在只使用解码器的情况下,s的KV缓存可以在多个操作中共享。
传说中的Q*,已经在解决数学问题上有了重大飞跃,这种可能性又有多大呢?
田渊栋表示,自己是这样猜测的:因为解决的入门级数学问题,所以值函数设置起来应该相对容易一些(例如,可以从自然语言形式的目标规范中预测)。
如果想要解决困难的数学问题,却不知道该怎么做,那么这种方法可能还不够。

LeCun转发了田渊栋的讨论,对他的观点表示赞同:“他解释了A*(在图形中搜索最短路径)和MCTS(在指数增长的树中搜索)之间适用性的差异。”

对于LeCun的转发,田渊栋表示,自己一直在做许多不同的事情,包括规划、理解Transformers/LLM和高效的优化技术,希望能把这些技术都结合起来。
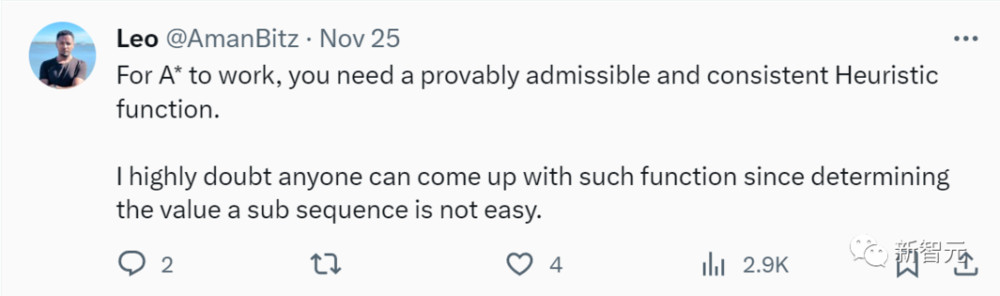
有网友表示怀疑称,“要使A*有效,就需要一个可证明的、可接受且一致的启发式函数。但我非常怀疑能有人想出这样的函数,因为确定子序列的值并不容易。”
即使做出的是小学数学题,Q*也被寄予厚望
对大模型稍微有些了解的人都知道,如果拥有解决基本数学问题的能力,就意味着模型的能力取得了重大飞跃。
这是因为,大模型很难在训练的数据之外进行泛化。
AI训练初创公司Tromero的联合创始人Charles Higgins表示,现在困扰大模型的关键按难题,就是怎样对抽象概念进行逻辑推理,如果实现了这一步,就是毫无疑问的重大飞跃。
数学是关于符号推理的学问,比如,如果X比Y大,Y比Z大,那么X就比Z大。
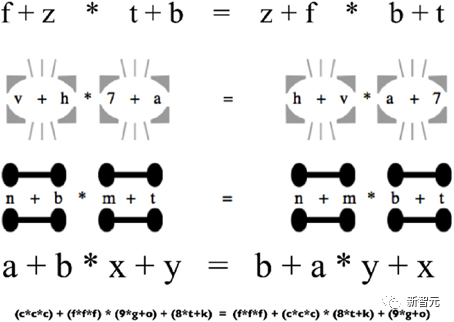
如果Q*的确就是Q-learning+A*,这就表明,OpenAI的全新模型可以将支持ChatGPT的深度学习技术与人类编程的规则相结合。而这种方法,可以帮助解决LLM的幻觉难题。
Tromero联创Sophia Kalanovska表示,这具有非常重要的象征意义,但在实践层面上,它不太可能会终结世界。
那为什么坊间会有“Q*已现AGI雏形”的说法传出呢?
Kalanovska认为,从目前传出的说法来看,Q*能够结合大脑的两侧,既能从经验中了解一些事情,还能同时推理事实。

显然,这就离我们公认的智能又近了一步,因为Q*很可能让大模型有了新的想法,而这是ChatGPT做不到的。
现有模型的最大限制,就是仅能从训练数据中反刍信息,而不能推理和发展新的想法。
解决看不见的问题,就是创建AGI的关键一步。
萨里人类中心AI研究所的所长Andrew Rogoyski表示,现在已有的大模型,都可以做本科水平的数学题,但一旦遇到更高级的数学题,它们就全部折戟了。
但如果LLM真的能够解决全新的、看不见的问题,这就是一件大事,即使做出的数学题是相对简单的。
合成数据是未来LLM的关键?
所以,合成数据是王道吗?
Q*的爆火引起一众大佬的猜想,而对于传闻中“巨大的计算资源,使新模型能够解决某些数学问题”,大佬们猜测这重要的一步有可能是RLAIF(来自 AI 反馈的强化学习)。
RLAIF是一种由现成的 LLM 代替人类标记偏好的技术,通过自动化人工反馈,使针对LLM的对齐操作更具可扩展性。

之前在LLM训练中大放异彩的RLHF(基于人类反馈的强化学习) ,可以有效地将大型语言模型与人类偏好对齐,但收集高质量的人类偏好标签是一个关键瓶颈。
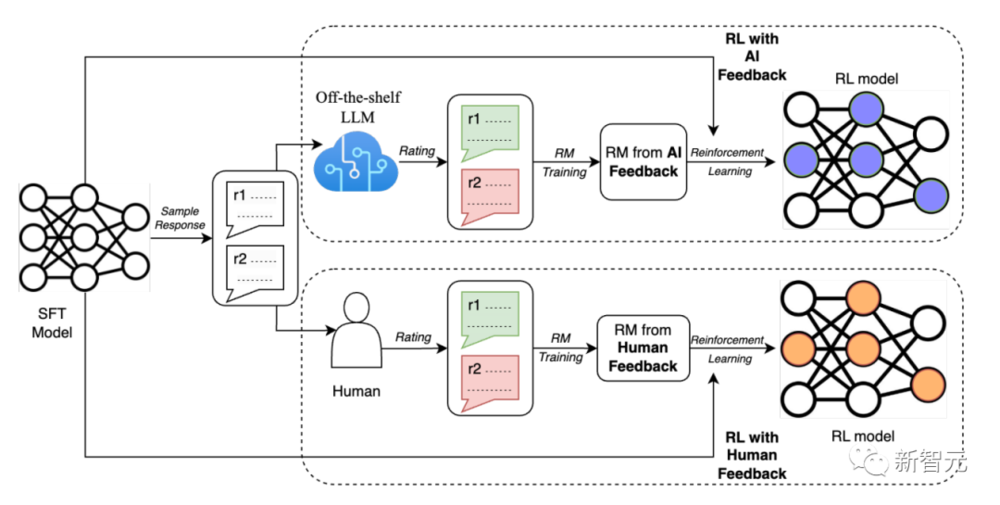
于是Anthropic、Google等公司已经尝试转向RLAIF,使用AI来代替人类完成反馈训练的过程。
这也就意味着,合成数据才是王道,并且使用树形结构为以后提供越来越多的选择,以得出正确的答案。
不久前Jim Fan就在推特上表示,合成数据将提供下一万亿个高质量的训练数据。

“我敢打赌,大多数严肃的LLM小组都知道这一点。关键问题是如何保持质量并避免过早停滞不前。”
Jim Fan还引用了Richard S. Sutton的文章The Bitter Lesson,来说明,人工智能的发展只有两种范式可以通过计算无限扩展:学习和搜索。
“在撰写这篇文章的2019 年是正确的,而今天也是如此,我敢打赌,直到我们解决 AGI 的那一天。”
Richard S. Sutton是加拿大皇家学会和英国皇家学会的院士,他被认为是现代计算强化学习的创始人之一,对该领域做出了多项重大贡献,包括时间差异学习和策略梯度方法。
在这篇文章中,Sutton主要表达了这样几个观点:
利用计算的通用方法最终是最有效的,而且效率很高。但有效的原因在于摩尔定律,更确切地说是由于每单位计算成本持续呈指数下降。
最初,研究人员努力通过利用人类知识或游戏的特殊功能来避免搜索,而一旦搜索得到大规模有效应用,所有这些努力都会显得无关紧要。
统计方法再次战胜了基于人类知识的方法,这导致了整个自然语言处理领域的重大变化,几十年来,统计和计算逐渐成为了主导。
人工智能研究人员经常试图将知识构建到系统中,这在短期内是有帮助的,但从长远来看,有可能会阻碍进一步的进展。
突破性的进展最终将通过基于搜索和学习的方法来实现。
心灵的实际内容是极其复杂的,我们应该停止尝试寻找简单的方法来表示思想,相反,我们应该只构建可以找到并捕获这种任意复杂性的元方法。
所以,看起来Q*似乎抓住了问题的关键(搜索和学习),而合成数据将进一步使它突破以往的限制,达成自己的飞跃。
对于合成数据,马斯克也表示人类确实打不过机器。
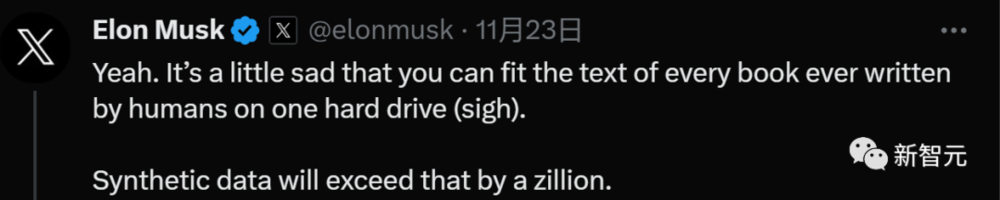
“你可以把人类写的每本书的文字都放在一个硬盘上(叹气),而合成数据将远远超过这些。”
对此,Jim Fan与马斯克互动说:“如果我们能大规模模拟它们,大量的合成数据将来自具身智能体,例如Tesla Optimus。”

Jim Fan认为 RLAIF 或者来自 groundtruth 反馈的 RLAIF 如果正确扩展将有很长的路要走。此外,合成数据还包括模拟器,原则上可以帮助LLM开发世界模型。

“理想情况下是无限的。但令人担忧的是,如果自我提升循环不够有效,就有可能会停滞不前。”
对于两人的一唱一和,LeCun表示有话要说:“动物和人类在训练数据量极少的情况下,很快就变得非常聪明。”
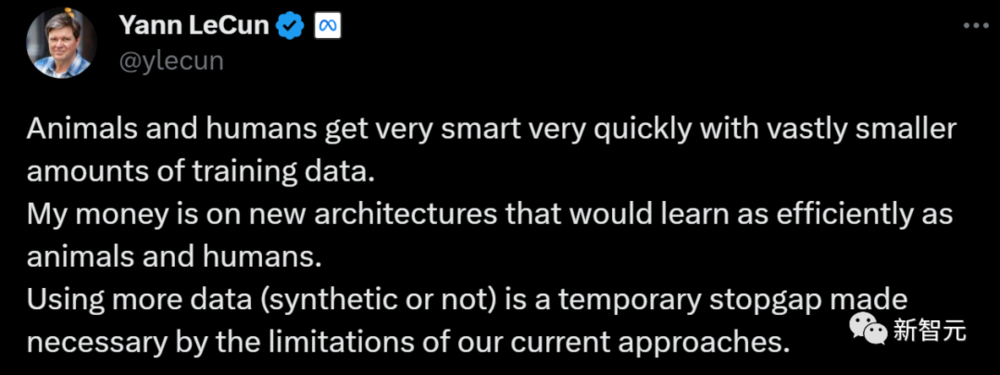
所以,使用更多的数据(合成或非合成)是一种暂时的权宜之计,只是因为我们目前的方法有局限性。
对此,支持“大数据派”的网友表示不服:“难道不应该是数百万年的进化适应类似于预训练,而我们一生的经验类似于持续的微调吗?”

LeCun于是给出一个例子作为解释,人类用于承接几百万年进化成果的手段只有基因,而人类基因组中的数据量很小,只有800MB。

连一个小型的 7B LLM 都需要 14GB的存储空间,相比之下,人类基因中确实没有太多的数据。
另外,黑猩猩和人类基因组之间的差异约为1%(8MB)。这一点点差别完全不足以解释人与黑猩猩之间能力的差异。
而说到后天学习的数据量,一个 2 岁的孩子看到的视觉数据总量是非常小的, 他所有的学习时间约为 3200 万秒(2x365x12x3600)。
人类有 200 万根光神经纤维,每根神经纤维每秒传输大约 10 个字节——这样算下来总共有 6E14 个字节。
相比之下,LLM 训练的数据量通常为 1E13 个token,约为 2E13 个字节,所以2岁孩子获得的数据量只相当于 LLM 的 30 倍。
不论大佬们的争论如何,大型科技公司如 Google、Anthropic、Cohere 等正在通过过程监督或类似 RLAIF 的方法创建预训练大小的数据集,为此耗费了巨大的资源。
所以大家都清楚,合成数据是扩大数据集的捷径。在短期内,我们显然可以利用它创建一些有用的数据。
只是这是否就是通往未来的道路?
参考资料:
https://twitter.com/tydsh/status/1727922314267029885
https://www.businessinsider.com/openai-project-q-sam-altman-ia-model-explainer-2023-11
本文来自微信公众号:新智元 (ID:AI_era),作者:新智元

 14:40
14:40









 12:33
12:33
 13:10
13:10
 12:58
12:58
 06:21
06:21
 34:52
34:52
 47:13
47:13
 23:16
23:16
 04:54
04:54
 27:05
27:05


