2023-11-24 15:32


扫码打开虎嗅APP

本文来自微信公众号:新智元 (ID:AI_era),编辑:桃子,原文标题:《OpenAI神秘Q*项目解密!诞生30+年“Q学习”算法引全球网友终极猜想》,题图来自:视觉中国
刚刚过去的一天,OpenAI被爆出惊天内幕:一个名为Q*(Q-Star)的项目已现AGI雏形。

对于这个神秘Q*,许多网友决定挖墓,将研究重点放在了“Q学习”(Q-learning)身上。

突然间,这项来自1992年的技术成为了热点。

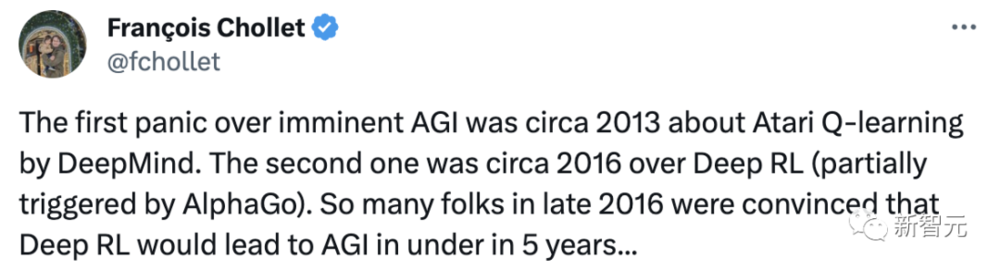
谷歌工程师、Keras发明者François Chollet表示,人类对即将到来的AGI的第一次恐慌,是在2013年左右,DeepMind的Atari Q-learning。
第二次是在2016年左右爆发的深度强化学习Deep RL(部分由AlphaGo触发)。2016年末,很多人都相信Deep RL将在5年内实现AGI……
那么,Q-learning真的是OpenAI实现AGI的杀手锏吗?

Q-learning是什么?
接下来,让我们深入了解Q-learning以及它与RLHF的关系。

Q-learning是人工智能领域,特别是在强化学习领域的基础概念。它是一种无模型的强化学习算法,旨在学习特定状态下某个动作的价值。
Q-learning的最终目标是找到最佳策略,即在每个状态下采取最佳动作,以最大化随时间累积的奖励。
1. 理解Q-learning
基本概念:Q-learning基于Q函数的概念,也称为“状态-动作”价值函数。这个函数接受两个输入:一个状态和一个动作。它返回从该状态开始,采取该动作,然后遵循最佳策略所预期的总奖励。
Q-table:在简单场景中,Q学习维护一个表(称为Q-table),每行代表一个状态,每列代表一个动作。表中的条目是Q值,随着代理通过探索和利用学习而更新。
更新规则:Q-learning的核心是更新规则,通常表示为:

这里,α是学习率,γ是折扣因子,r是奖励,s是当前状态, a是当前动作,s'是新状态。
探索与利用:Q-learning的一个关键方面是平衡探索(尝试新事物)和利用(使用已知信息)。这通常通过诸如ε-贪婪策略来管理,其中代理以ε的概率随机探索,以1-ε的概率利用最佳已知动作。
举个例子,小迷宫里的一只老鼠,目标是吃掉右下角的一大堆奶酪,避开毒药。如果我们吃了毒药,或者我们花了超过五步,game over。

奖励函数是这样的:
- 没有吃到奶酪:+0
- 吃到一块奶酪:+1
- 吃到一大堆奶酪:+10
- 吃到毒药:-10
- 超过5步:+0

为了训练智能体有一个最优的策略,就需要使用Q-Learning算法。
2. Q-learning与AGI的道路
AGI指的是人工智能系统理解、学习并将其智能应用于各种问题的能力,类似于人类智能。虽然Q-learning在特定领域很有力量,但它代表着通向AGI的一步,但要克服几个挑战:
可扩展性:传统的Q-learning难以应对大型状态-动作空间,使其不适用于AGI需要处理的实际问题。
泛化:AGI需要能够从学习的经验中泛化到新的、未见过的场景。Q-learning通常需要针对每个特定场景进行明确的训练。
适应性:AGI必须能够动态适应变化的环境。Q-learning算法通常需要一个静态环境,其中规则不随时间变化。
多技能整合:AGI意味着各种认知技能,如推理、解决问题和学习的整合。Q-learning主要侧重于学习方面,将其与其他认知功能整合是一个正在进行的研究领域。

进展和未来方向:
深度Q网络(DQN):将Q-learning与深度神经网络结合,DQN可以处理高维状态空间,使其更适合复杂任务。
迁移学习:使Q-learning模型在一个领域受过训练后能够将其知识应用于不同但相关的领域的技术,可能是通向AGI所需泛化的一步。
元学习:在Q-learning框架中实现元学习可以使人工智能学会如何学习,动态地调整其学习策略,这对于AGI至关重要。
Q-learning在人工智能领域,尤其是在强化学习中,代表了一种重要的方法论。
毫不奇怪,OpenAI正在使用Q-learning RLHF来尝试实现神秘的AGI。
A*算法+Q-learning
一位斯坦福博士Silas Alberti表示,OpenAI的Q*可能与Q-learning有关,表示贝尔曼方程的最优解。又或者,Q*指的是A*算法和Q学习的结合。

一个自然的猜测是,它是基于AlphaGo的蒙特卡罗树搜索(Monte Carlo Tree)token轨迹。
这似乎是很自然的下一步,之前像AlphaCode这样的论文表明,即使在大型语言模型中进行非常幼稚的暴力采样,也可以在竞争性编程中获得巨大的改进。
下一个合乎逻辑的步骤是以更有原则的方式搜索token树。
这在编码和数学等环境中尤为合理,因为在这些环境中,有一种简单的方法可以确定正确性。事实上,Q*似乎就是为了解决数学问题。
不过,Silas Alberti称,根据问题的不同,计算量也不同。现在,我们只能对模型采样一次。如果Q*真的如上所述是树状搜索,那么它就可以在一道很难的奥数题上花费10倍、100倍甚至1000倍的计算量。
“合成数据”是关键
Rebuy的AI总监、莱斯大学博士Cameron R. Wolfe认为:
Q-Learning“可能”不是解锁AGI的秘诀。但是,将合成数据生成(RLAIF、self-instruct等)和数据高效的强化学习算法相结合可能是推进当前人工智能研究范式的关键……

他对此做一个简短版的总结:
使用强化学习进行微调是训练ChatGPT/GPT-4等高性能LLM的秘诀。但是,RL本质上是数据低效的,而且使用人类手动注释数据集来进行强化学习的微调成本极高。考虑到这一点,推进人工智能研究(至少在当前的范式中)将在很大程度上依赖于两个基本目标:
用更少的数据使RL性能更好。
使用LLM和较小的手动标注数据集,为RL综合生成尽可能多的高质量数据。
我们在哪里碰壁?最近的研究表明,使用RLHF来微调LLM是非常有效的。然而,有一个主要问题——RL数据效率低下,需要我们收集大量数据才能获得良好的性能。
为了收集RLHF的数据,我们让人类手动标注他们的偏好。虽然这种技术效果很好,但它非常昂贵,而且进入门槛非常高。因此,RLHF仅供拥有大量资源的组织(OpenAI、Meta)使用,而日常从业者很少利用这些技术(大多数开源LLM使用SFT而不是RLHF)。
解决方案是什么?尽管可能没有完美的解决方案,但最近的研究已经开始利用强大的LLM(比如GPT-4)来自动化数据收集过程,以便使用RL进行微调。这首先是由Anthropic的Constitutional AI探索的,其中LLM合成了用于LLM对齐的有害数据。后来,谷歌提出了人工智能反馈的强化学习(RLAIF),其中LLM用于自动化RLHF的整个数据收集过程。令人惊讶的是,使用LLM生成合成数据以使用RL进行微调非常有效。
来自LLM的合成数据。我们在各种研究论文中看到,使用LLM生成合成数据是一个巨大的研究前沿。这方面的例子包括:
self-instruct:LLM可以使用LLM自动生成指令调优数据集(Alpaca、Orca和许多其他模型也遵循类似的方法)。
LLaMA-2:LLM能够在人工标注少量示例后为SFT生成自己的高质量数据。
Constitutional AI:LLM可以使用自我批判来生成高质量的数据集,以便通过RLHF和SFT进行对齐。
RLAIF:我们可以使用LLM完全自动化RLHF的反馈组件,而不是使用人工来收集反馈,并实现可比的性能。

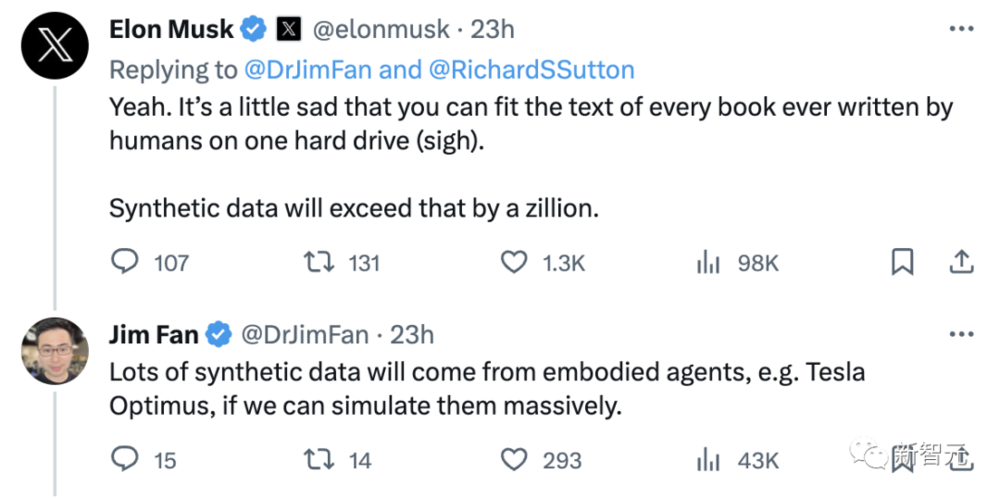
对此,英伟达高级科学家Jim Fan表示:
“很明显,合成数据将提供下一万亿个高质量的训练token。我敢打赌,大多严谨的LLM团队都知道这一点。关键问题是如何保持质量并避免过早停滞不前。
Richard Sutton写的《苦涩的教训》继续指导着人工智能的发展:只有两种范式可以通过计算无限扩展:学习和搜索。他在2019年撰写本文时,这个观点是正确的,而今天也是如此。我敢打赌,直到我们解决AGI的那一天。”

马斯克对此深表赞同:“一个硬盘就能装下人类有史以来所有书籍的文本,这实在有点可悲(叹气)。而合成数据却要比这多出十万倍。”
然而,在LeCun看来并非如此。
他表示,“动物和人类只需少量的训练数据,就能很快变得非常聪明。我认为新的架构可以像动物和人类一样高效地学习。使用更多的数据(合成数据或非合成数据)只是暂时的权宜之计,因为我们目前的方法存在局限性”。

GPT-Zero?
还有人猜测,Q*有可能是Ilya Sutskever创建的GPT-Zero项目的后续:

很多人声称Q-learning或RLAIF并不新鲜。这些技术可能并不新鲜,但将它们结合起来构建一个产生显著结果的工作实现是新颖的!
伟大的工程+科学=魔法!

确实,AlphaZero当年的视频值得再重温一遍。

参考资料
https://twitter.com/BrianRoemmele/status/1727558171462365386
https://twitter.com/DrJimFan/status/1727505774514180188
本文来自微信公众号:新智元 (ID:AI_era),编辑:桃子

 13:10
13:10









 06:21
06:21
 14:40
14:40
 01:41
01:41
 07:13
07:13
 27:05
27:05
 12:33
12:33
 25:27
25:27
 47:13
47:13
 04:54
04:54


