2023-12-21 15:16


扫码打开虎嗅APP

本文来自微信公众号:半导体行业观察 (ID:icbank),作者:李飞,题图来自:视觉中国
在最近的一场“AI Everywhere”发布会上,Intel的CEO Pat Gelsinger炮轰Nvidia的CUDA生态护城河并不深,而且已经成为行业的众矢之的。
Gelsinger称,“整个行业都希望能干掉CUDA,包括Google、OpenAI等公司都在想方设法让人工智能训练更加开放。我们认为CUDA的护城河既浅又窄。”
Gelsinger的这番话确实道出了整个人工智能行业对于Nvidia的CUDA又爱又恨的情绪。一方面,由于有了CUDA生态,人工智能算法的训练和部署从硬件层角度变得容易,人工智能工程师无需成为芯片专家,也能够让人工智能训练高效地运行在Nvidia的GPU上。
而从另一个角度,整个业界也过于依赖CUDA,以至于不少主打人工智能公司都对于CUDA的过度依赖产生了警惕性,这也就是Gelsinger所说的Google、OpenAI等公司都在设法研制自己的相应解决方案(例如OpenAI的Triton)。
本文将深入分析CUDA的强势到底来源于哪里,以及究竟谁能打破CUDA垄断。
什么是CUDA?
首先,我们先分析一下CUDA的来龙去脉。当我们在谈论“CUDA”的时候,我们究竟在谈论什么?事实上,我们认为,CUDA包含三个层次。
首先,CUDA是一套编程语言。最初,3D图像加速卡的主要任务是加速3D图像的渲染,其用途相当专一。在本世纪初,Nvidia推出了GPU的概念,以允许用户使用图像加速卡去做通用计算,并且在大约十五年前推出了相应的CUDA编程语言,其主要任务是提供GPU的编程模型,从而实现通用GPU编程。
在CUDA编程语言中,Nvidia提供了GPU的各种硬件抽象,例如基于线程的并行计算、内存存取等概念,从而为GPU编程提供了方便。
除了编程语言之外,CUDA的第二层含义是一套高性能编译系统。在使用CUDA编程之后,还需要把用CUDA语言编写的程序使用CUDA编译器针对相应硬件优化,并且映射到更底层的硬件指令(对于Nvidia显卡来说就是PTX)。CUDA的编译器和GPU硬件的整合效率相当高,因此能编译出非常高效的底层指令,这也是CUDA的另一个核心组成部分。
最后,CUDA的第三层含义是Nvidia基于CUDA语言的一系列高性能函数库,以及人工智能/高性能计算社区基于CUDA语言开发的一系列代码库。例如,CUDA的常用高性能函数库包括用于线性计算的cuBLAS和CUTLASS,用于稀疏矩阵计算的cuSPARSE,用于傅立叶变换的cuFFT,用于数值求解的cuSOLVER等。这些函数库的发展至今已经历经了十余年的努力,其优化几乎已经做到了极致。另外,人工智能社区也有大量基于CUDA开发的代码库,例如Pytorch的默认后端就是CUDA。
CUDA每个层面的护城河
如上分析可知,CUDA其实包含了三个层面:编程语言,编译器和生态。那么,CUDA这三个层面的护城河究竟有多高?
首先,从编程语言的角度,事实上一直有OpenCL等社区开源语言试图去实现类似(甚至更加广泛的功能;OpenCL针对的不只是GPU编程,还包括了FPGA等异构计算体系)的功能,AMD的ROCm平台也是试图做到与CUDA语言等价。从编程语言角度,CUDA并非不可取代。
其次,从编译器的角度来看,CUDA提供的高性能编译器确实是一个很高的护城河。编译器的性能从很大程度上决定了用户编写的程序在GPU上执行的效率;或者换句话说,对于人工智能应用来说,一个很直观的衡量标准就是用户编写的人工智能算法,能在多大程度上利用GPU的峰值算力?大多数情况下,峰值算力平均利用率不到50%。
另外,编译器的性能还牵扯到了用户调优的过程。如果用户是GPU专家,通过在编写GPU程序时进行调优(例如使用某种特定的方式去编写语句),也可以很大程度上弥补编译器的不足(因为编译器的一个重要功能就是对编写的程序做优化,那么如果编写的程序已经比较优化了那么对编译器优化能力的要求就可以低一些)。
但是,这就牵扯到了用户的门槛,如果编译器性能不够好,需要用户是专家才能实现高效率的GPU程序,就会大大提高用户门槛,即只有拥有一支精英GPU编程专家团队的公司才能充分发挥出GPU的性能;相反如果编译器性能够好,那么就可以降低用户门槛,让更多公司和个人也可以使用GPU高性能运行算法。从这个角度来说,经过十多年的积累,CUDA的编译器(NVCC)已经达到了相当高的水平。
最近的另一个新闻也从侧面印证了编译器性能的重要性:AMD在12月初的发布会上宣布新的MI300X平台在运行Llama2-70B模型的推理任务时,比起Nvidia H100 HGX的性能要强1.4倍;一周后,Nvidia回应称AMD在编译测试时并没有使用合理的设置,在使用正确设置后H100 HGX的性能事实上比MI300X要强1.5倍。由此可见,一个好的编译器优化对于充分利用GPU的性能可以说是至关重要。
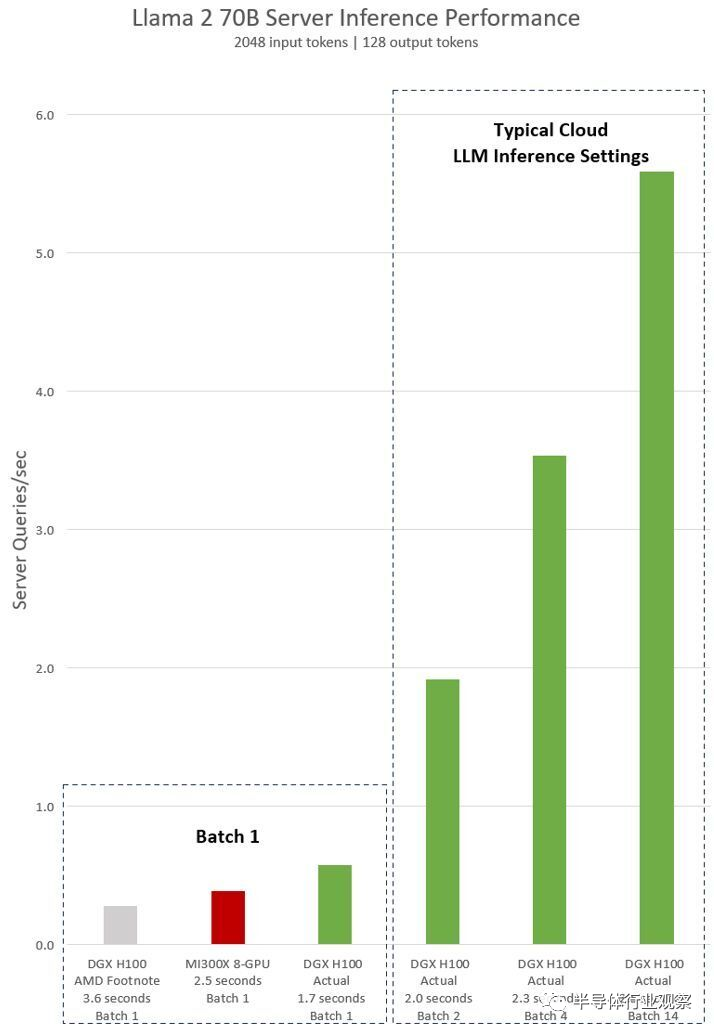
然而,编译器的护城河也并不是高不可破。例如,OpenAI的开源Triton编译器可以同时兼容Nvidia和AMD以及更多平台,支持把用户使用Python编写的程序直接优化编译到底层硬件指令语言,并且在Nvidia的成熟GPU上实现和CUDA接近的执行效率。如果Triton这样的开源编译器获得成功的话,至少从某种角度上可以省去其他人工智能芯片公司花数年精力去开发自己的编译器的需求。
第三个层面是生态。目前,CUDA在生态领域可以说是遥遥领先,因为CUDA有着十多年的高性能程序库的积累,以及基于这些程序库上面社区开发的各种高性能框架代码。生态的积累首先需要能提供一个领先的解决方案——如果其他公司也能提供一个高性能的编程语言和编译器方案的话,自然会有社区去基于它开发代码,而经过长期不懈的积累之后,生态自然也会赶上。
例如,人工智能领域最流行的框架PyTorch从这两年开始也对于AMD的ROCm提供了支持,这就是生态领域的一个例子。换句话说,只要给足够的时间和与CUDA语言/编译器性能接近的方案,生态自然会慢慢赶上。
谁能打破CUDA的护城河?
之前我们分析了CUDA从三个层面的护城河,我们可以发现,Nvidia的CUDA从三个层面分别来看,编译器和生态的护城河比较高,但也不是不可超越。我们看到,软件科技公司之间正在试图超越这条护城河,例如OpenAI的Triton编译器能提供几乎比肩CUDA的性能,而人工智能编程框架PyTorch的最新版本已经在后端集成了Triton,可望在Nvidia已经推出的成熟GPU上能实现很高的性能。
然而,Nvidia CUDA最强的护城河事实上在于软件-芯片协同设计。如前所述,在Nvidia的GPU推出一段时间之后(例如半年或一年),第三方的软件公司的方案(例如OpenAI的Triton)在研究透彻这款GPU之后,可以让自己的方案做到比肩CUDA的水平。这意味着两点:
首先,第三方软件公司开发编译器去尝试匹配CUDA的性能永远是一个追赶的过程,Nvidia发布新的GPU和相应CUDA版本之后,需要半年到一年的时间才能实现性能基本匹配,但是基本难以到达Nvidia新GPU发布就立刻实现性能匹配甚至领先。
其次,芯片公司如果被动等待第三方软件公司的编译器去适配自己的人工智能加速硬件以追赶Nvidia的话,永远无法打破Nvidia CUDA的领先地位。原因是,第三方软件公司适配新的人工智能加速硬件需要时间;而在一年后等到第三方软件公司的方案达到接近CUDA的水平的时候,Nvidia已经发布下一代GPU了。这就陷入了永远在追赶过程中的陷阱,难以打破CUDA护城河并实现领先。
因此,能真正打破CUDA护城河的,必须是有芯片-软件协同设计能力的团队,而不仅仅是一个软件公司。这个团队可以是一家拥有强大软件能力的芯片公司(例如,Nvidia就是这样的一个拥有强大芯片-软件协同设计能力的芯片公司的例子),或者是芯片和科技公司的结合。只有在芯片设计过程中就开始编译器和软件生态的适配,才能够在芯片发布的初期就能推出芯片性能和软件性能同时都比肩Nvidia GPU +CUDA的产品,从而真正打破CUDA的护城河。
如何在芯片设计过程中实现软硬件协同设计?事实上,编译器的设计是基于一种编程模型,把硬件抽象为一些不同的层次(例如内部并行计算,内存存取等等),并且进一步根据这些硬件抽象去构建性能模型,来实现性能的预测和优化。
从芯片设计的角度,需要能充分理解编译器层面的这些硬件抽象和性能模型并不会百分百准确,因此如何设计一个好的芯片架构让编译器能够较为容易地去优化程序就很重要。
而从编译器的角度,如前所述每一款芯片的编程模型和硬件抽象层都会略有不同,因此需要在芯片设计周期中就介入开始编译器的优化和硬件建模。两者相结合,就能实现在芯片推出时就同时有很强的芯片理论性能和高度优化的编程语言/编译器,最终实现整体解决方案能和Nvidia的GPU+CUDA做有力的竞争。
从这个角度来看,Google的TPU+XLA就是一个满足之前所属芯片-软件协同设计的案例。Google的自研TPU过程中和XLA编译器通过软硬件结合设计实现整体高性能方案(这也是TPU在MLPerf benchmark上和Nvidia的方案性能接近甚至领先的重要原因)。虽然TPU并不对第三方销售因此这个方案并不会完全打破Nvidia CUDA的护城河,但是它至少提供了一个打破Nvidia CUDA护城河的技术方向。
从另一个方面,AMD和Intel等芯片公司在编译器领域的方案目前还有待加强,但是通过和OpenAI等科技公司合作,通过在下一代AI产品的设计过程中就和Triton这样的领先编译器方案协同设计,可望能在未来追赶Nvidia GPU + CUDA的性能;而在性能接近之后,生态的培养就只是一个时间问题了。
综上,我们认为,CUDA虽然是一个软件生态,但是如果想要打破CUDA的护城河,需要的是软硬件协同设计。
本文来自微信公众号:半导体行业观察 (ID:icbank),作者:李飞

 14:16
14:16









 14:05
14:05
 12:52
12:52
 14:24
14:24
 11:57
11:57
 25:27
25:27
 11:13
11:13
 14:54
14:54
 11:16
11:16
 04:43
04:43



