2023-12-27 09:48


扫码打开虎嗅APP

本文来自微信公众号:新硅NewGeek(ID:gh_b2beba60958f),作者:董道力,编辑:张泽一,视觉设计:疏睿,题图来自:视觉中国
今年咱们新硅编辑部最大的困扰,就是面对各种“超越GPT”的大模型,陷入无尽的沉思。
我们就纳了闷了,为什么GPT这么好超越?
在“第一个中文大模型”“第一个垂类大模型”等名号被各大科技公司相继占领之后,这场竞赛逐渐转移到了分数上,竞争者们纷纷宣称自己在某些维度上排名第一,或是在某方面远超GPT-4。
即便是谷歌在发布其新模型Gemini时也未能免俗。
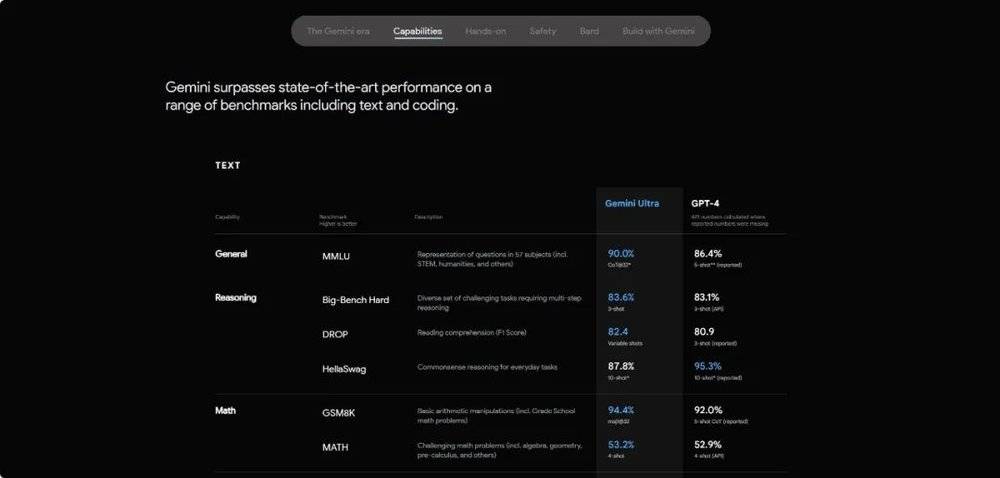
图源:Gemini官网
到了年末,AI排行榜上充斥着各种高分大模型,然而它们似乎也就止步于此,高分的模型就只存在于排行榜上,真正能用的似乎也没几个。
用李彦宏的话来说,就是目前大量的资源浪费在各种各样基础模型的训练上,甚至是跑分刷榜上,而比较少的资源和精力放在了AI原生应用上。
大模型为什么要跑分,源于一个最朴实的概念:如果用户用不上,那么如何证明咱家的模型高级?
在ChatGPT横空出世后,大家只知道ChatGPT很厉害,因为它可以像模像样地回答任何问题,哪怕是脑筋急转弯。于是大家开始用各种刁钻的问题问大模型,来判断大模型好不好。
被称为人类最后堡垒的弱智吧问题,常常用来测试大模型,像什么“老鼠生病了,吃老鼠药可以治好吗?”“跳多高才能跳过广告?”“生蚝煮熟了还叫生蚝吗?”

但仔细想想,这种测试方式不够科学也不太全面,而且万一未来AI主导社会,显然也不是靠抖机灵上位的。
于是,众多研究机构、高校开始建立完善的大模型评估体系。比如由MBZUAI、上海交通大学、微软亚洲研究院共同推出的CMMLU,专门用于评估大模型在中文语境下的知识和推理能力。
我们根据OpenCompass(主流的开源网站)整理了一下目前主流的大模型评测方法,大概有39种。
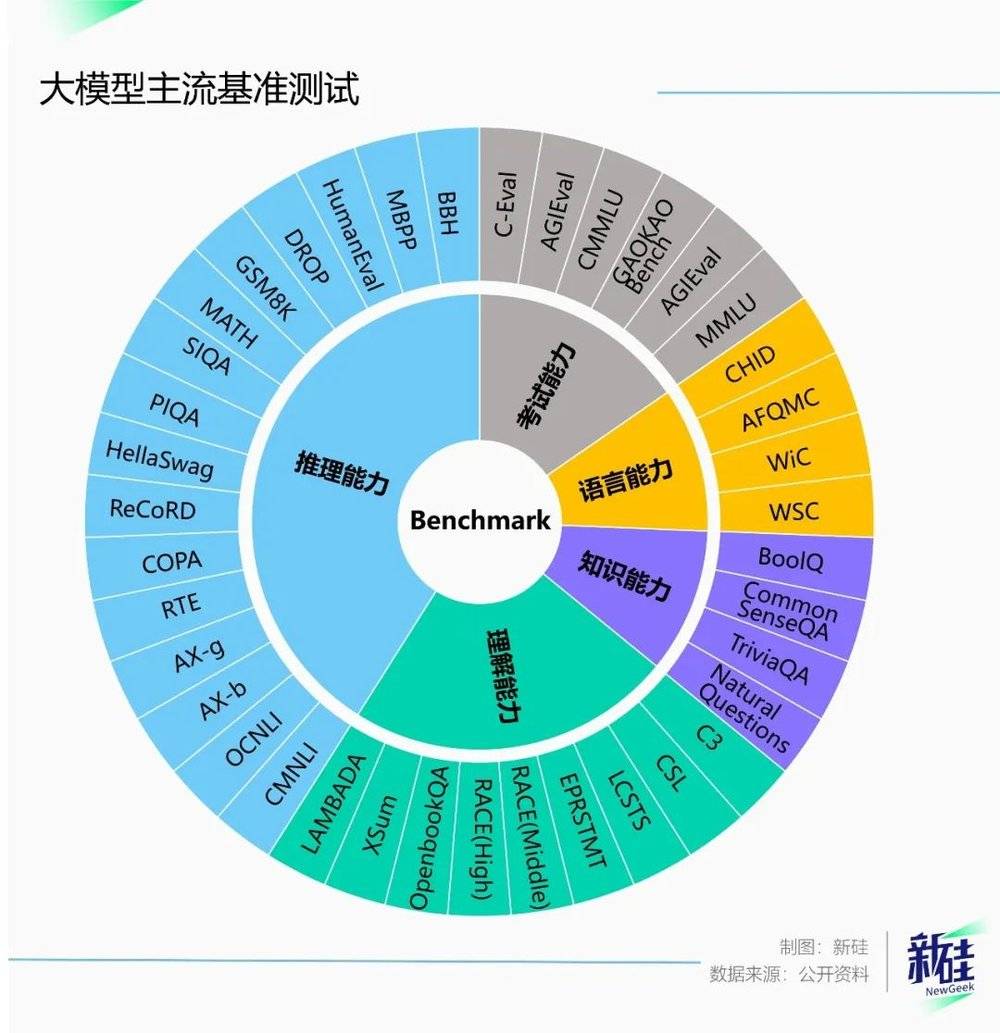
严格意义来说,这39种评测方法只要有一个领域领先GPT,就可以拿来当宣发标题了。
大模型测试都会涉及5个方面的能力。考试能力、语言能力、知识能力、理解能力和推理能力。
我们一一来介绍下,每个能力都是什么,以及为什么要测试这些能力。
考试能力主要测试了大模型在特定任务或条件下的表现。以GAOKAO-Bench为例,这个测试集简单来说就是让大模型去参加高考。
GAOKAO-Bench收集了2010-2022年全国高考卷的题目,包括选择填空之类的客观题,和阅读理解类的主观题,其中主观题训练集的标准答案由上海市曹杨第二中学的老师们评分。
插句题外话,这所学校在上海高中里面可以排进前二十。
这一能力通常说明模型在接受特定训练后,能否实现相应的效果,也是评测中努努力最容易得高分的项目。
这和好好学习就能考高分如出一辙。

图源:GAOKAO-Bench 例题
语言能力指大模型理解和使用语言的能力,包括语法、句法和语义。
比如AFQMC测试就用到蚂蚁金融的数据,可以评估大模型能否判断“双十一花呗提额在哪”“哪里可以提花呗额度”两句话意思不一样。

图源:AFQMC 例题
知识能力指模型拥有的信息和数据,以及如何使用这些信息来回答问题或解决问题。
当我们问ChatGPT一些常识问题,如“中国的首都在哪里?”ChatGPT会毫不犹豫地回答北京。这就是大模型的知识能力。也就是说大模型的知识能力越好,知识盲区越小。

图源:commonsenseQA 例题
理解能力指模型对信息的深入理解,包括上下文、隐含的意义和复杂概念。能否识别弱智吧的问题,基本就靠这个能力,但凡说生蚝煮熟了就不是生蚝的,理解能力通通不过关。

图源:C3 例题
推理能力指模型根据现有信息做出逻辑判断和决策的能力。例如CMNLI测试了大模型能否确定两个句子之间的逻辑关系,从而判断大模型的推理能力。
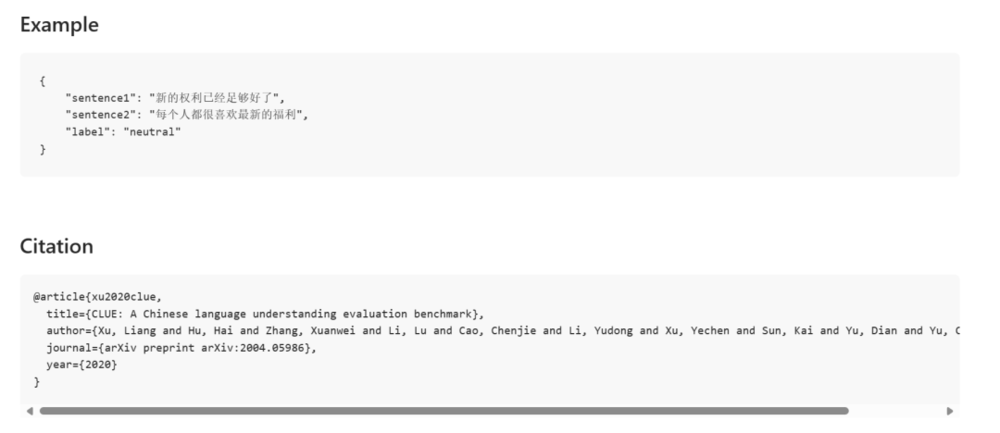
图源:CMNLI例题
比如这个例子,新的权利已经足够好了,其实并不等于每个人都很喜欢最新的福利。
大模型测试的数据集很多,而且会有新的测试出现,但测试的能力基本都是考试能力、语言能力、知识能力、理解能力和推理能力。
看到眼花缭乱的测试,你是不是觉得高分的大模型一定很厉害?
还真不一定。
首先,行业内存在“大模型测试泄露”的问题。很多大模型的测试题目是公开的,导致厂商可以“针对性训练”模型以提高分数。
这一现象在人民大学高瓴人工智能学院最近发表的论文Don't Make Your LLM an Evaluation Benchmark Cheater被证实。这种做法虽然能提升测试成绩,但并不代表模型的真实能力得到了提升。

图源:Don't Make Your LLM an Evaluation Benchmark Cheater
换句话说,只要把这些测试题全部喂给大模型,然后送这个模型去考试,怎么得分都不会低,毕竟是开卷考试。
具体来看,在使用测试题进行训练后,小模型也能秒杀大模型。论文中测试了很多模型,这里我们以LLaMA为例。
LLaMA-2(7B)在没有使用测试题训练前,在各大测试中分数都不如LLaMA-13B。但在使用测试题训练后,LLaMA-2(7B)的分数可以接近甚至高于LLaMA-65B。
后者的参数量是前者的近10倍,要知道,在绝大多数情况下,参数量往往决定了大模型的能力。
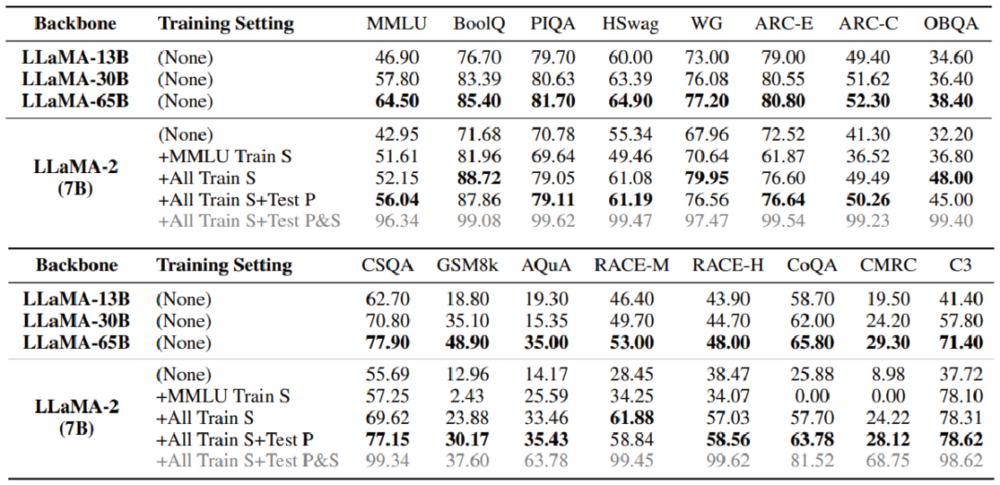
图源:Don't Make Your LLM an Evaluation Benchmark Cheater
那不公开的闭源测试可以解决这个问题吗?也不行。
闭卷考的主要优势是它可以防止厂商针对特定的测试题目进行优化,从而提供更真实的模型性能评估。
可问题是,这种测评如何服众?没人知道到底如何测试模型的情况下,其评测的可信度就得打一个问号。
质疑随之而来,比如“卖榜单”。
在没有足够透明度的情况下,厂商可能会通过某些手段来影响或操纵排名,从而损害测试的公正性,国内有一个大模型测试集,由于没有公开测试详细内容,引来网友质疑。
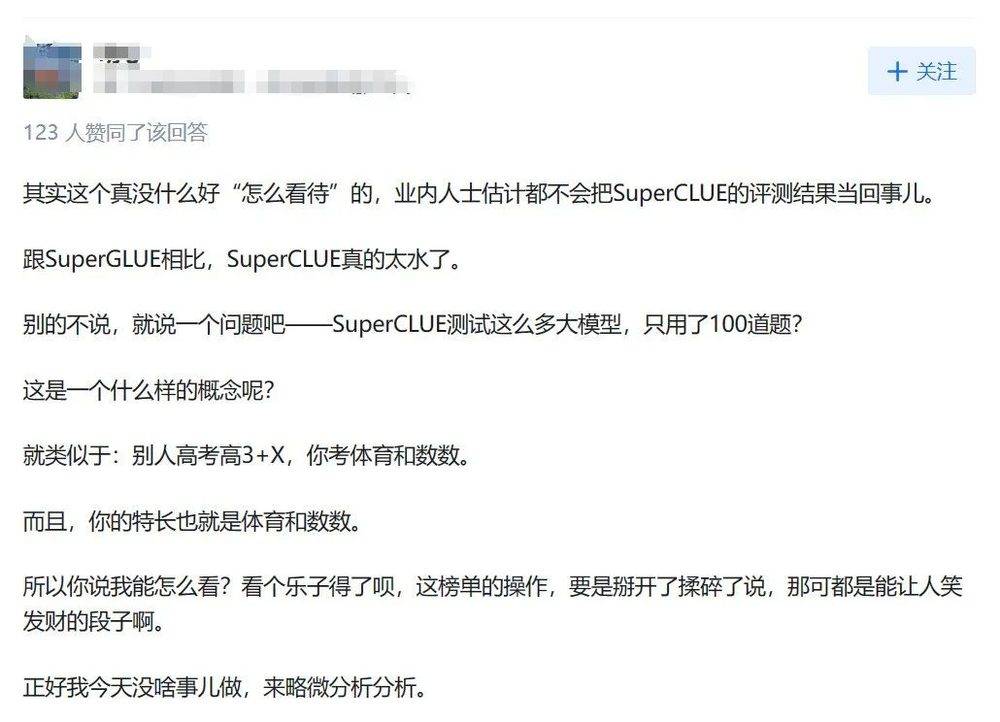
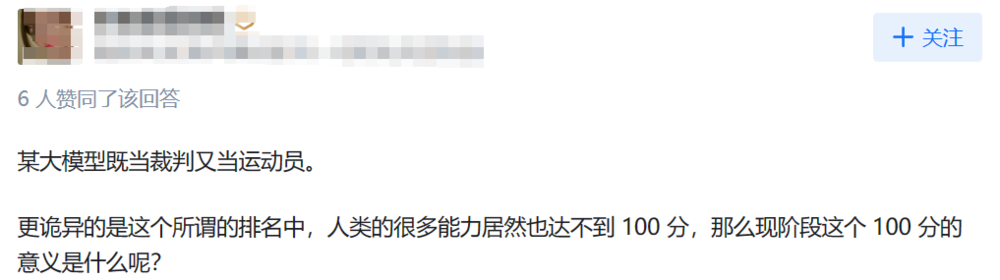
图源:知乎网友评论
在大模型测试榜单即将水漫金山前,中国信通院发布了《大规模预训练模型技术和应用评估方法》,评测范围包含智能语义、智能视觉、智能语音、跨模态四个能力,共计30余个能力项。
这算是给“混乱”的大模型评测带来了一个“国标”方案。
虽然《大规模预训练模型技术和应用评估方法》还未全面普及,仅完成了模型开发和模型能力两部分的内容,还未形成统一完善的标准,但至少在国内也有官方权威的口径进行评测。
不管怎么说,拿不到国标就不能上路。
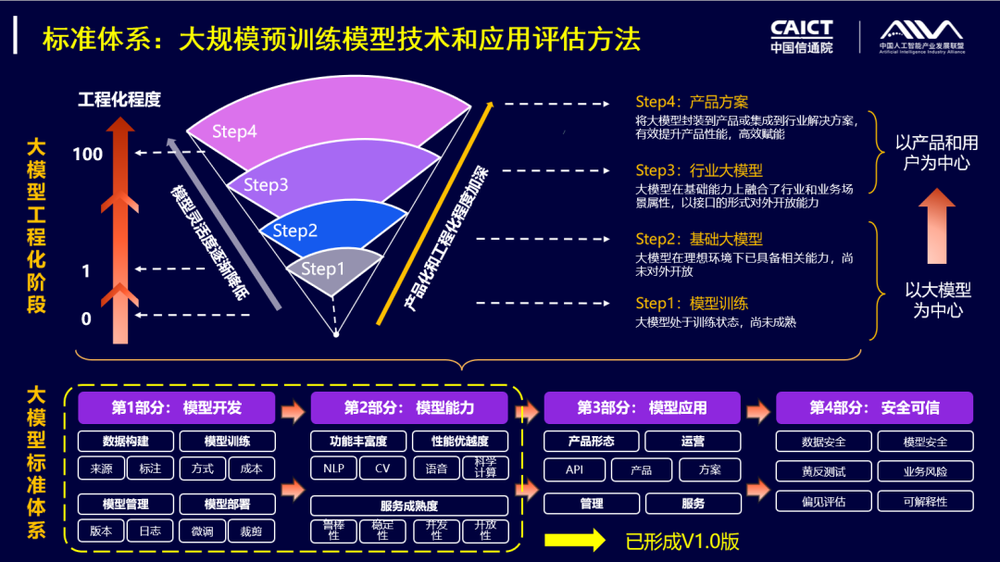
图源:中国信通院
不过也存在一种说法,就算目前的大模型测试存在问题,但这些测试题已经足够全面了,能做这么多题就不错了,以后只要把题库不断完善,大模型不就越来越强大了?
所以都怪驾校只考到科目四,不然也不会出这么多事故了。
很显然,会做题并不代表能力强。毕竟人类在做题的过程中有成长的概念,而现阶段的AI还没到“自我成长”的阶段。
通过做题训练出来的大模型,有一种术语称其为“快思考”。
Google DeepMind资深工程师卢一峰表示:“(快思考阶段中)它的知识是来自于整个互联网的数据,压缩以后进行的重组、汇编,凭此来试着回答用户的问题,它实际上离我们真正所谓的‘慢思考’,即帮助人类去解决一些很难的问题,还有很长的路要走。”
“区别就在于,你可以让它帮你写一些日常的邮件,但是如果你问它,‘我们怎么能够把人类带到火星?’这样的问题,那它就无法用一次问答的方式获得完整的答案。”
举个例子,“快思考”的大模型就像一本百科全书,你只能获得书里有的内容,不管怎样提问他给出的答案都是在书中某个角落里写过的,最多帮你整合编辑一下。
而“慢思考”的大模型就像一位专家,他可以用脑子里的知识储备进行学习,从而实现“回答一切问题”的能力。
因此,大模型跑分并不能全面体现大模型的能力。
那么性能测试就没有意义了吗?
前文中,我们探讨了大模型测试存在诸多问题,那么大模型开发者为什么仍热衷于进行性能测试?
首先,大模型测试可以帮助开发者对大模型的能力有一个初步的认识,能考上985大学通常来说比上大专的能力会强一些。
此外,它们也涉及到一些重要的“价值对齐”问题,例如避免人种歧视、性别歧视,或是协助恐怖袭击等。
另一方面,在模型竞争激烈的环境下,性能测试成为厂商展示自家模型最主要的营销手段,毕竟当前大模型的普及程度尚浅,且缺乏明确的应用场景,厂商很难通过实际应用来吸引用户,一个最直接的“得分”更能抓人眼球。
是不是很熟悉?这种现象与早期智能手机和PC市场的情况颇为相似。
起初,用户对消费电子的理解不深,主要通过性能分数来判断手机的优劣,鲁大师跑分就是在这个时候崛起的。
然而,随着智能手机的普及和关键应用场景的明确化,用户体验逐渐成为了评价标准的核心。
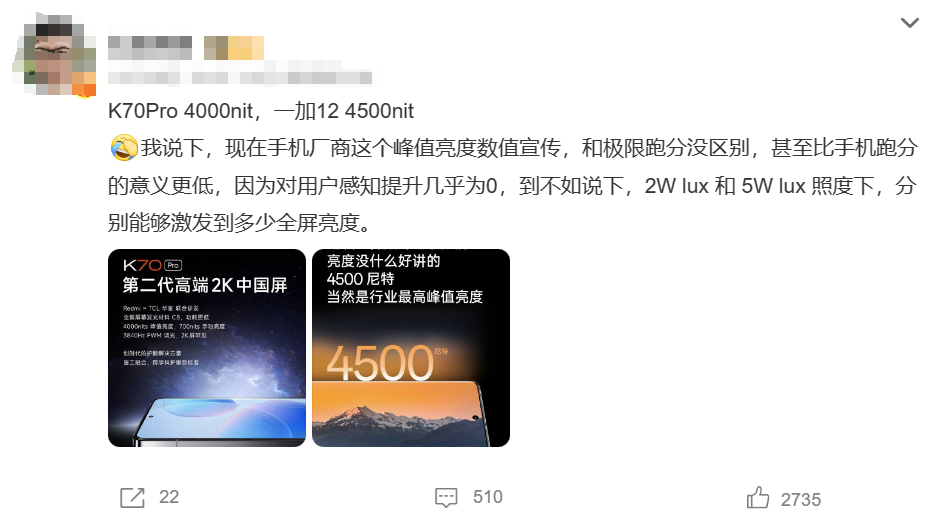
图源:某微博大V对手机跑分吐槽
到了应用普及的年代,谁还看跑分?
参考文章:
[1] 一言不合就跑分,国内AI大模型为何沉迷于“刷榜”|三易生活
[2] LLM Evaluation 如何评估一个大模型?|知乎
[3] 谷歌工程师:大模型自进化关键在从“快思考”进入“慢思考”|极客公园
[4] 《Don't Make Your LLM an Evaluation Benchmark Cheater》
[5] 可信AI技术热点|大模型持续释放技术红利,产业级大模型评估体系正式发布|中国信通院
[6] 全国首个!“大模型标准符合性测试”结果公布,这四款国产大模型首批通过!|证券时报
[7] 李彦宏:卷 AI 原生应用才有价值,别卷大模型了!|极客公园
本文来自微信公众号:新硅NewGeek(ID:gh_b2beba60958f),作者:董道力,编辑:张泽一,视觉设计:疏睿

 13:10
13:10









 05:31
05:31
 06:21
06:21
 27:05
27:05
 20:24
20:24
 05:47
05:47
 12:03
12:03
 15:55
15:55
 07:01
07:01
 02:43
02:43


