




2024-01-07 09:40

扫码打开虎嗅APP


本文来自微信公众号:返朴 (ID:fanpu2019),作者:汤姆·芝华士、大卫·芝华士,翻译:邓妍,头图来自:视觉中国
当有女士在场时,男士会为了给女士留下深刻印象而吃得更多吗?《每日电讯报》2015 年的某则新闻的标题做了肯定的回答。[1]这一情况后来也得到了路透社[2]和印度的《经济时报》[3]的报道。这些报道称,男性和女性一起用餐时,会比和其他男性一起用餐时多吃93%的比萨饼和86%的沙拉。报道基于康奈尔大学食品与品牌实验室的心理学家布莱恩·万辛克(Brian Wansink)和另外两名研究者的研究。[4]
到目前为止,你大概已经发现,数字并非总是完全可信。但这一次肯定不是记者的错。事实上,是这项研究出现了严重失误,而这个失误能让我们看到科学是如何运作以及如何出错的。要理解为什么这个报道中的统计数据不能信,我们就需要深入了解科学实践的机制。
只要读过任何关于科学或数字的新闻报道,你基本都会遇到“统计显著性”(statistical significance)这个词。如果你误以为这个措辞意味着你读到的统计数据很显著,也是情有可原。可惜,它比这要复杂得多。根据2019 年一篇论文的定义,统计显著性的含义如下[5]:
假设原假设(null hypothesis)成立,并且通过从同一(批)总体中随机抽样来无限次重复同一研究,在所得的所有结果中,比当前结果更极端的结果少于5%。
你能看懂吗?我们试着来解释一下。
假设你想了解某件事,比如阅读一本名为《数字一点不老实》的书能否让人更好地理解新闻中的统计数据。你可以抽取一个多达1000人的大样本,该样本将包含这本书的数百万读者里的一些人,以及没读过这本书的一些人。(为了便于讨论,我们假设,在谁都没有读过这本书之前,这两个群体没有差别;即使我们知道,在现实中,平均而言,买这本书的人肯定远比总体人口中的其他人更聪明、更睿智、颜值更高。)
下一步,我们让样本中的每个人都做一个简单的统计能力小测验,看看读过这本书的人是否比没读过的人做得更好。
我们假设数据显示这本书的读者似乎在测验中表现更好。我们怎么知道这并非碰巧?我们怎么知道他们做得更好是因为一些实实在在的差异,而不仅仅是随机变化?要找出答案,我们可以使用一种名为“显著性检验”(significance testing,或称“假设检验”hypothesis testing)的统计学方法。
我们先设想一下如果这本书没产生任何效果,我们会看到怎样的结果。这个假设就叫“原假设”。另一种可能性是,这本书确实产生了一些积极效果——这个假设叫“对立假设”(alternative hypothesis)。用图表展示最为直观。在原假设下,我们预期会看到这样一条曲线:顶峰位于平均分附近,大部分人位于中部,得分很高和很低的人都是少数——就像正态分布曲线。我们预期读过这本书的人的平均分和分布曲线与没读过的人的几乎相同。
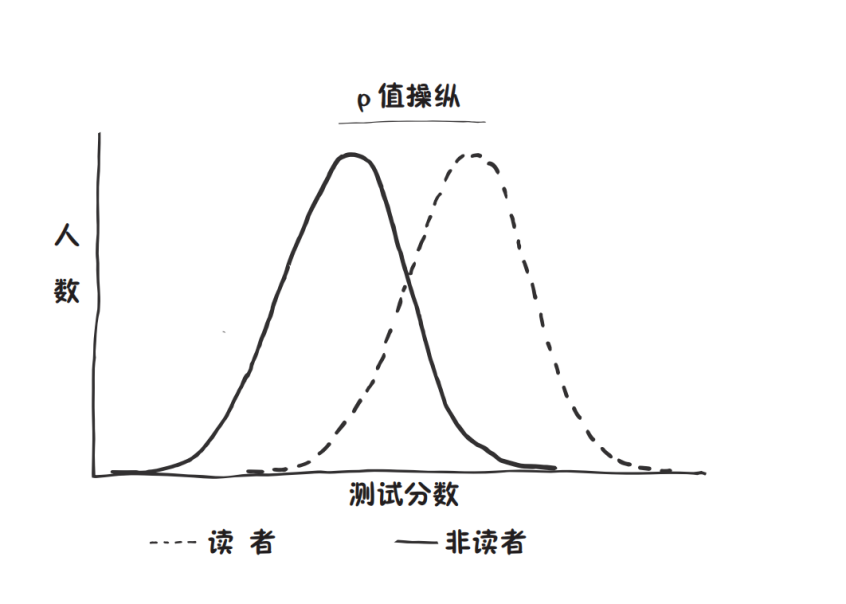
而在对立假设下,读过的人的平均分应该高于没读过的人,那么分布曲线将会向右平移。
但事情没这么简单。我们的原假设是说,这本书不起任何效果,而且两组人的统计学水平还非常不现实地完全在同一起跑线上,但即便在这样的假设下,还是有一些随机变化:有些人可能在那一天状态不佳。回想电影《双面情人》的情节可以帮助我们想象:在某一个宇宙中,格温妮丝·帕特洛误了火车,参加测验迟到了,所以她很慌张,结果答得很差;在另一个宇宙中,她准时参加了测验,得了高分,并继续爱上了约翰·汉纳。随机变化也许不足以将她从笨蛋变成统计天才,但足以影响她的分数。每个人在测验中的表现都有一定程度的随机性,无论多么小。
如果有几个没读过这本书的人碰巧得分很低,或者几个读过这本书的人碰巧得分超高,就可能足以显著改变平均分,使读者看上去比非读者答得更好。
现在我们假定,不管出于什么原因,测验结果显示这本书读者的得分比非读者更高。在我们的例子中,原假设是说读这本书没有任何效果,并且任何波动都只是随机产生的,而如果原假设成立,你要检验的就是这样的测验结果(或更极端的结果)出现的可能性有多大。这就是显著性检验。
我们不可以单凭一个证据就毫无疑义地说原假设是错的;理论上,无论结果和原假设的差距多么大,都有可能完全是巧合。但差距越大,巧合的可能性就越小。科学家们就把发生巧合的可能性大小叫“P值”(Probability value,P-value)。
某些结果随机出现的可能性越小,p值就越低。因此,如果说读这本书没效果,而100次小测验里只观察到1次这么极端或更甚的结果,那我们就说p=0.01,或1/100。(接下来这一点非常重要,简直太,重,要,了,我们甚至想把这个重要的事情说三遍:它的含义并,不,是,说测验结果有1/100 的概率是错的。我们稍后会回到这一点,但这里需要做个标记。)
在科学的许多领域有一个惯例:如果 p≤0.05,即你预期出现如此极端的结果的可能性不超过5%,那么这个发现就有“统计显著性”,这意味着你可以推翻原假设。
假设我们查看结果时,发现读过这本书的人的平均分确实高于没读过的人。如果该结果的 p 值小于0.05,那我们就说我们达到了统计显著水平,可以推翻原假设(“读这本书什么用都没有”)而支持对立假设(“这本书让你的统计学能力变得更好”)。p值告诉我们的是,如果原假设成立,则我们如果要进行100次检验,就该预期读过这本书的人和没读过的人相比,获得和这次测验差不多的成绩的次数不超过5次。
统计显著性是个令人困惑的概念,即使对科学家来说也是如此。2002年的一项研究发现,100%的心理学本科生误解了统计显著性,更令人震惊的是,他们的讲师也有90%是如此。[7]另一项研究查看了28种心理学教材,其中25种在定义统计显著性时包含至少一项错误。[7]
让我们来消除一些可能的误解。首先,我们所说的“统计显著性”是一种人为的惯用分界点,记住这一点很重要。p=0.05没有任何神奇之处。你可以把这个值设置得更高,然后宣布更多的发现具有统计显著性;也可以把值设得更低,然后宣布更多结果不具有统计显著性,而很可能是巧合。设得越高,假阳性的风险就越大;设得越低,假阴性的风险就越大。如果实际上读我们的书有效果,但由于设置了特别严格的 p 值,可能会导致我们宣称读这本书没有任何效果——当然,反之亦然。
其次,统计学的“显著”也不是这个词的通常意义。例如,如果非读者组的平均分是65分,而读者组的平均分是68分,这可能达到了“统计显著性”,但你可能不觉得这有多大的显著意义。“统计显著性”衡量的是观测结果乃是巧合的可能性,而非它的重要性。
还有最后一点至关重要,统计显著性不是说,如果得到一个p=0.05的结果,你的假设就只有1/20的机会是错的。这种误解很常见,也是科学研究出错的重要原因。
问题在于,尽管 p≤0.05 的统计显著性完全是人为选定的,但科学家——更重要的是,期刊——经常将其视为一个分界点。如果你的研究发现 p=0.049,它也许就能发表;如果发现 p=0.051,它很可能不会被发表。而科学家要想获得资助、获得终身教职并让自己的职业生涯更上一层楼,就需要将自己的研究发表出去。他们受到极大的激励去寻找具有统计显著性的结果。
让我们回到读书实验。我们真的想证明我们的书能提高读者的统计能力,这样我们就可以登上《星期日泰晤士报》畅销书排行榜,还能参加所有最棒的鸡尾酒会。但我们进行实验后,只得到了p=0.08。
好吧,我们想,也许只是运气不好。所以我们把实验又做了一遍。这次得到了0.11。我们一次又一次地进行实验,直到最终得到了0.04。太棒了!我们报告了我们的发现,从此靠这本书的版税吃饭。但这个结果几乎可以肯定是假阳性。如果你把某项实验做了20次,那么你就该预期会看到1/20的巧合结果。
这不是我们唯一的途径。我们还可以用多种不同的方法雕琢数据。比如说,除了测量分数之外,我们还可以测量人们完成测验的速度,或者笔迹是否工整。如果读书组的得分没有表现得更高,我们可以看看他们是否完成得更快;如果这也没有的话,我们还可以看看他们的字是否变漂亮了。或者,你可以删除一些比较极端的结果,并把它们叫“离群值”(outliers)。如果我们测量了足够多的东西,用足够多的方法把它们组合起来,或者对数据做出足够小且看似合理的调整,那么我们肯定能够出于巧合而得出某些发现。
让我们回到那些关于男性吃得更多以给女性留下深刻印象的报道。2016 年底,万辛克作为主要作者撰写了一篇博客文章,这篇文章后来导致他的职业生涯陷入困境。文章题为《从不说“不”的研究生》[8]。
万辛克在文中讲了一名新加入他实验室的土耳其博士生的故事。他说,他给了她“一份数据集,来自一个自筹资金的研究,但研究失败了,没有找到任何发现(这是一项在一家意大利菜自助餐厅中进行的研究,为期一个月,我们给一部分人打了五折优惠)”。他告诉她仔细检查数据,因为“我们肯定能从这里找出点什么”。
在他的授意下,这位博士生以几十种不同的方式重新分析了数据,不出所料,发现了很多相关性,就像上面假想中的读书研究那样,我们大可以尽力雕琢数据,直到找到一个p<0.05 的结果。她和万辛克通过该数据集发表了五篇不同的论文,其中包括“男性会为给女性留下深刻印象而多吃”的研究。在这项研究中,他们发现,有女性在场时,男性吃更多比萨饼的 p值为0.02,吃更多沙拉的p值为0.04。
但那篇博客文章引起了科学家们的警觉。这样的行为叫“p值操纵”(p-hacking):“揉捏”数据,使p值低于 0.05,从而使研究得以发表。精通方法论的研究者开始查看万辛克过去的所有工作,还有一位消息人士将他的电邮信件泄露给了BuzzFeed新闻的科学调查记者斯蒂芬妮·M·李。原来,他让那位博士生将数据分解为“男性、女性、吃午餐的、吃晚餐的、独坐的、两人一桌的、两人以上一桌的、点酒的、点软饮的、靠近自助餐区的、远离自助餐区的等等”。[9]
人们也发现万辛克过去的论文存在其他方法论问题,更多电子邮件也揭示了他低劣的统计操作——在一封邮件中,他暗示 :“我们应该能从中找出多得多东西……我认为为了显著性和讲出好故事而挖掘数据乃是好事。”[10]他希望这项研究能够“病毒式成名”。
这个例子比较夸张,但没这么夸张的p值操纵比比皆是。它通常不会造成什么伤害。学者们迫切希望得到p<0.05,这样就能发表论文,于是他们会重新进行试验或重新分析数据。你可能听说过“可重复性危机”(replication crisis):在心理学及其他科学领域,有科学家得出了重要的发现,但当别人去重现这些研究时,发现许多结论实际上并不成立。这是因为那些科学家未能准确理解一个问题:他们不断地雕琢数据、重新研究,直到发现具有统计显著性的结果,却没有意识到这样做会使自己的工作变得毫无意义。
几位坚持科学原则且具有统计学头脑的研究人员和一位经验丰富的科学记者为了挖掘万辛克的行为,花了几个月的时间。而大多数时候,撰写科学文章的记者都是基于通稿来快速撰写新闻。他们通常没有数据集,即使有,他们也无法发现p值操纵。而经p值操纵的研究有一个不公平的优势:由于这些研究本身就不需要正确,让它们变得引人注目就更容易。所以这些研究经常出现在新闻中。
读者要在新闻报道中发现这一点并不容易。但我们需要明白:某件事仅仅是“统计上显著”,并不代表它真的具有显著、重大的意义,甚至不代表它是正确的。
本文来自微信公众号:返朴 (ID:fanpu2019),作者:汤姆·芝华士、大卫·芝华士,翻译:邓妍

