2018-10-04 19:59


扫码打开虎嗅APP

文|雷宇
来源|智能相对论(aixdlun)
人民对性的态度向来很奇怪,父母和长辈期待子女能无师自通,教育者三缄其口,最后少男少女通过其他渠道实现了对性的初级摸索,当然这个摸索过程就很曲折了,文字,图片,视频和音频遍地开花,“学习资料”越来越方便传播。
食也性也,但传播色情内容却有极大的负外部效应,懵懂少男少女极易受其蛊惑,鉴黄师的重要性可想而知。在苹果商店的社交App中,有超过1/10的应用主打声音社交功能,由此催生出了一个新兴职业——声音鉴黄师。声音鉴黄师是一个让身心饱受摧残的职业,一位女性声音鉴黄师称,“一个人平均一天需要鉴定4000条信息,24小时轮班监控,各种荤段子、暧昧语音,有时(听到)恶心想吐。”

声音鉴黄师是一份不足以为外人道也的工作
由于这份工作实在是太过于枯燥,很多男生都受不了,因此声音鉴黄师多为女性且离职率高。一般枯燥且重复率高的工作都是AI的拿手好戏,那么AI有没有办法实现声音鉴黄呢?
声音鉴黄之殇,AI难以克服鸡尾酒效应
视频,图片和语音是色情内容常见的三种形式,多数公司的鉴黄都是立足于视频和图片,比如阿里的阿里绿网、腾讯的万象优图等等。有人可能会疑问,这几年科大讯飞、百度、腾讯等公司先后对外公布语音识别准确率均达到“97%”,那为什么在AI语音鉴黄上那么难?
这是因为社交平台的语音环境十分复杂,机器很难从庞大杂乱的语音中揪出涉黄涉暴人员,而这就不得不提鸡尾酒效应了。所谓鸡尾酒效应是指,在鸡尾酒会嘈杂的人群中,尽管周围噪声很大,两人可以顺利交谈,你们似乎听不到谈话内容以外的各种噪音。这是因为我们的大脑对声音都进行了某种程度的预判,然后才决定听或不听。
用特瑞斯曼的注意衰减理论来解释就是,当人的听觉注意集中于某一事物时,意识将一些无关声音刺激排除在外,而无意识却监察外界的刺激,一旦一些特殊的刺激与己有关,就能立即引起注意的现象。
但是机器却不具备这样意识和无意识,因此难以实现在嘈杂环境下的语音识别,这样看来AI语音鉴黄貌似已经走进了死胡同。
实际上,已有公司在解决鸡尾酒效应上做出了努力。今年 4 月,Google 曾在博客上发文称,谷歌研究人员开发出了一种深度学习系统,可识别和分离出嘈杂环境中的个体声音。
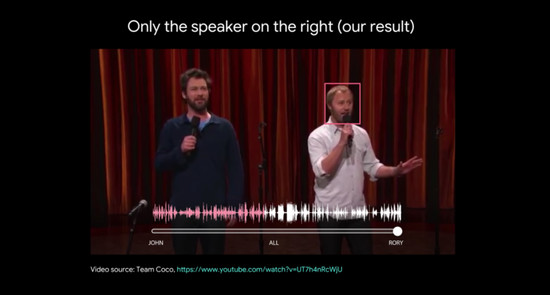
图片来自网易科技
研究人员从YouTube上10万段“讲座和谈话”视频中提取了近2000小时的视频片段,然后混合音频与人工背景噪声,创造“鸡尾酒派对”。训练技术人员将混合音频进行拆分,谷歌的系统能够分辨出哪个音频源在给定的时间内属于哪张人脸,并为每个扬声器创建单独的语音轨迹。
但Google 的技术集中在视频处理上,主要是对数段声音的分离,而人工声音鉴黄仅仅依靠声音,有所不同。前不久,阿里AI语音反垃圾服务上线公测,它可以通过声纹识别技术,识别语音中存在的涉黄、广告等违规信息,不管是中日英俄等语言,还是东北,四川,广东的方言,甚至连无意义的呻吟声都可以轻松判别。
具体办法是,对那些有语义的内容,系统先将语音识别转成文字,然后再将这些文字跟文本反垃圾模型或关键词库比对,判断是否涉黄,对那些无语义的声音,通过声纹也能识别出来。但有一点值得注意的是,在语音识别的过程中,识别是哪种语言比内容更难,机器翻译也存在这样的问题,因此还需要大量数据来进行训练学习。
做好嘈杂环境的语音识别,难点是如何将杂音与人声分离。但对于声音鉴黄而言,一开始并不知道哪一个音源涉黄,很难说谁是噪音,这需要机器具有全局观。而上面提到的技术,声音分离或者将语音识别转成文字都只是基本,由于尚未在语音复杂的环境下试验过,因此这个结果嘛……退一万步讲,社交黑话也并不是那么好破译的。
社交黑话难解,语音识别障碍重重
时代要抛弃你,它只会让你看不懂,而我们也不能指望人工智能听懂。
就像你爹妈当初看不懂你的那句签名:” ァ亊實證明,鱤綪桱淂起fеηɡ雨,却桱囨起平啖;伖綪桱淂起平啖,却桱囨起fеηɡ雨。ヤ”(没乱码),新一代社交黑话崛起一般人也很难看懂,比如XSWL(笑死我了,相当于一连串哈哈哈),NSS(暖说说,指帮点赞评论转发说说,增进感情),CQY(处Q友的缩写,想在QQ上找朋友的意思)。
当然这也还算好的,无非就是缩写。除了缩写,还有一些只能强记的词语。比如养火(互发消息三天出现小火花,互发消息超过三十天出现大火花,养火就是经常联系的意思),欧洲(想要什么就得到什么的人)……
估计研究人员在录入数据时就阵亡了,毕竟这玩意看上去也不算有章可循。值得注意的是,当人们在说话的时候,如果省略一两个字不说,懂得的人自然也懂,但机器不一定能识别人们甚至为了混淆视听,会多语夹杂,这就给机器识别增添了难度。
这种输入标准的不统一,是导致语音识别错误率高的首要原因。我们常用的鼠标和键盘虽然看似简单,但它具备统一的输入标准和精准的视觉反馈这两点,而这正是语音识别技术不具备的,也是困扰现阶段AI鉴黄的一大挑战。
毫不意外,现阶段的声音鉴黄师依然是以人为主。早在互联网发展早期,黄色内容主要是图片和文字,靠人工就可以净化网络环境的目的,但是随着互联网带来的数据爆炸,人工已经远远不能胜任。
虽然声音鉴黄以人为本,但这并不意味着AI鉴黄师没有价值。它能在特定的场景实现鉴定也无疑算是一种进步,而现阶段它所呈现的问题,也无疑是技术发展过程中难以避免的阵痛。
全球经济学家和咨询公司的主流研究课题,总少不了人工智能会引发的失业规模,但是中国的互联网已经跑出了一条独特的路线,因此针对中国的研究少之又少。声音鉴黄师作为互联网发展过程中的独特产物,显然会存在相当长一段时间,而现行的人工智能鉴黄也多为辅助人。
一句正确但无用的话是,可以想见未来AI鉴黄会占据主流,但这个未来应该以哪个时间节点为基准,谁也无法预料。
智能相对论(微信id:aixdlun):深挖人工智能这口井,评出咸淡,讲出黑白,道出vb深浅。重点关注领域:AI+医疗、机器人、智能驾驶、AI+硬件、物联网、AI+金融、AI+安全、AR/VR、开发者以及背后的芯片、算法、人机交互等。

 05:53
05:53









 04:29
04:29
 15:28
15:28
 09:30
09:30
 08:45
08:45
 25:37
25:37
 19:42
19:42
 08:08
08:08
 01:21:14
01:21:14
 46:21
46:21



