2024-02-19 19:01


扫码打开虎嗅APP

本文来自微信公众号:APPSO (ID:appsolution),作者:莫崇宇,原文标题:《Sora 为何未在中国出现?交大天才少年谢赛宁反问“我们准备好了吗”》,题图来自:视觉中国
这几天,关于 OpenAI 视频生成模型 Sora 的话题被炒得沸沸扬扬。
不到 48 个小时,Sora 背后的核心团队成员被扒得清清楚楚,团队中甚至不乏 00 后。
当我们还在感慨团队成员的年少有为时,CV 大神谢赛宁却被误传为“Sora 作者之一”,以至于其本人在朋友圈以及“交大校友荟”上紧急辟谣。
简单划重点:
Sora 是 Bill(Sora 核心成员、负责人之一)等人在 OpenAI 的呕心之作,和谢赛宁一点关系都没有。
对于诞生 Sora 这样复杂的系统,人才第一,数据第二,算力第三。
在问 Sora 为何未在中国出现的同时,谢赛宁反问我们是否准备好成熟的监管体系。
Sora 的创新性和此前的 AI 图片生成不是一个量级的,《真相捕捉》和《黑镜》里讲的故事,很有可能很快变为现实。
谢赛宁之后也会在纽约大学开展一些相关的工作。
目前,发表《震惊世界的 Sora 发明者之一,是毕业于上海交大的天才少年-谢赛宁!》的文章已经“因违规无法查看”。
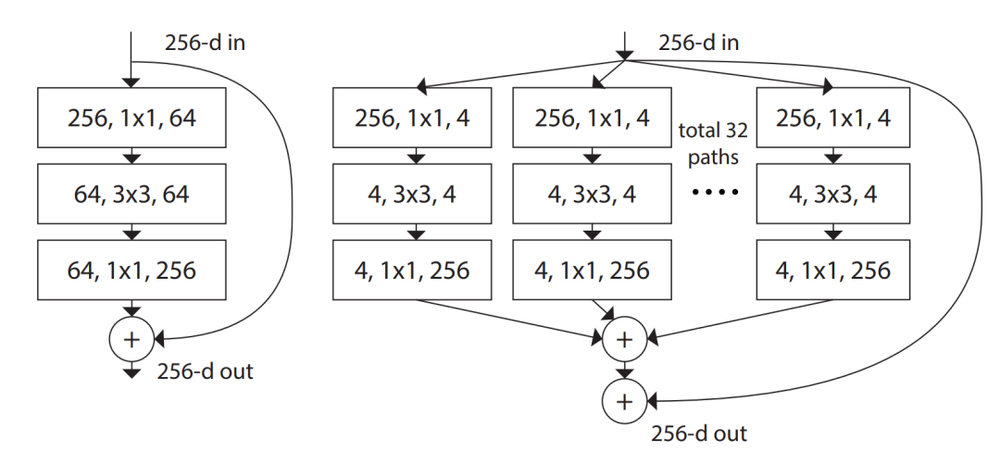
虽然谢赛宁并不是 Sora 背后的作者,但其也是 AI 界的大神级人物。他曾作为第一作者和 CV 大神何恺明提出了ResNeXt 深度学习模型。
ResNeXt 提出了一种简化的设计理念,即通过均匀地分配资源到不同的路径上来提高效率,而不是不断加深或加宽网络。这种设计理念为后续的神经网络架构设计提供了新的方向。
目前谢赛宁担任纽约大学计算机科学系助理教授。在此之前,他是 Meta 人工智能研究中心(FAIR) 的一名研究科学家。
谢赛宁本科毕业于上海交通大学 ACM 班,硕士毕业于加州大学圣地亚哥分校 CSE 系,导师为屠卓文。
在攻读博士学位期间,他还在 NEC Labs、Adobe、Meta、Google、DeepMind 等大厂有过非常丰富的实习经验。
Sora 发布之后,谢赛宁在 X 上对 Sora 进行了一顿分析:
Sora 应该是建立在 DiT 这个扩散 Transformer 之上的。简而言之:DiT = [VAE 编码器 + ViT + DDPM + VAE 解码器]。
至于视频压缩器网络,Sora 可能采用了 VAE 架构,但经过了原始视频数据训练。而由于 VAE 是一个 ConvNet,所以 DiT 从技术上来说是一个混合模型。
由于在 Sora 报告中,第一个视频的质量很差,谢赛宁推测 Sora 使用的模型参数大概只有 30 亿 。
这意味着训练 Sora 模型可能不需要像人们预期的那样多的 GPU。因此谢赛宁预计 Sora 未来的迭代会非常快。

有趣的是,在 Sora 发布之前,谢赛宁还在 X 上发布了其最新研究成果 SiT 新模型。
SiT 新模型是一个建立在 DiT 模型基础上的生成模型系列,它和 DiT 模型具有相同的骨干,但质量、速度和灵活性要更好。(论文地址指路:https://huggingface.co/papers/2401.08740)
谢赛宁朋友圈原文:
很少发票圈,如果大家看到这个公众号标题党的离大谱的文章,求一定帮忙点下举报不实信息。如果有认识微信相关部门的朋友也请联系我一下。
Sora 是 bill 他们在 openai 的呕心之作,我虽然不知道细节,但是 bill 告诉我他们每天基本不睡觉高强度工作了一年。跟我的关系是什么呢,只能说是一点关系都没有。标题党 ai 写稿,胡乱挂钩,误导事实,结果也有些阅读量了,希望票圈各位点点举报,不要误解、误传,帮忙想想办法早点take it down.
多说两句。
1. 对于 Sora 这样的复杂系统,人才第一,数据第二,算力第三,其他都没有什么是不可替代的。
2. 在问 Sora 为什么没出现在中国的同时,可能也得问问假设真的出现了(可能很快),我们有没有准备好?
如何能保证知识和创意的通畅准确传播让每个人拥有讲述和传播自己故事的“超能力”,做到某种意义上的信息平权。但是又不被恶意利用,变成某些人某些组织的谋利和操纵工具。oai 有一整套的 redteaming, safety guardrail 的研究部署,欧美有逐渐成熟的监管体系,我们准备好了吗?
这件事跟技术成熟前,生成点小打小闹的漂亮图片不是一个量级,真相捕捉和黑镜里讲的故事,很有可能很快变成现实。
我之后在 nyu 也会开展一些相关的研究,我想这也是学术界可以为这个时代肩负的重责之一。
3. 真是求求了,人到中年,害丢这么大人。拜托帮忙举报下。
本文来自微信公众号:APPSO (ID:appsolution),作者:莫崇宇

 11:18
11:18









 01:21:14
01:21:14
 15:28
15:28
 06:58
06:58
 05:33
05:33
 19:42
19:42
 14:41
14:41
 05:47
05:47
 12:49
12:49
 07:16
07:16




