2024-03-28 15:26


扫码打开虎嗅APP

本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,题图来自:视觉中国
全球最强开源模型,一夜易主!
刚刚,超级独角兽Databricks重磅推出1320亿参数的开源模型——DBRX。它采用了细粒度MoE架构,而且每次输入仅使用360亿参数,实现了更快的每秒token吞吐量。

这种独特的MoE架构,让DBRX成为开源模型的SOTA,推理速度比LLaMA 2-70B快了2倍!
最重要的是,训练成本直接砍半!只用了1000万美元和3100块H100,Databricks就在2个月内肝出了DBRX。比起Meta开发Llama2所用的成本和芯片,这只是很小的一部分。

DBRX在语言理解、编程、数学和逻辑方面轻松击败了开源模型LLaMA2-70B、Mixtral以及Grok-1。

甚至,DBRX的整体性能超越GPT-3.5。尤其在编程方面,完全击败了GPT-3.5。
并且,DBRX还为开放社区和企业提供了仅限于封闭模型的API功能。现在,基本模型(DBRX Base)和微调模型(DBRX Instruct)的权重,已经在Hugging Face开放许可了。
从今天开始,Databricks客户就可以通过API使用DBRX。它在Macbook Pro上都可跑,LLM很快能为个人设备提供支持了。
Pytorch之父Soumith Chintala对最新的开源模型DBRX也是非常看好。

从Mistral、到Grok-1,再到DBRX,MoE架构的模型正在占领开源界。

而Databricks的员工激动地表示,过去3个月,朋友们周末约我都说“不行,这周不行我有事,但是又不能说有啥事”的日子终于结束了,DBRX就是我们加班加点搞出来的一头“怪兽”。

还有网友表示,“如果实验室继续开源大型MoE模型,英伟达可能就需要推出最强Blackwell架构的消费级GPU了”。

一、全球最强开源模型易主
DBRX是一种基于Transformer纯解码器的大模型,同样采用下一token预测进行训练。它采用的是细粒度专家混合(MoE)架构,也就是具有更多的专家模型。
是的,这次立大功的,依然是MoE。在MoE中,模型的某些部分会根据查询的内容启动,这就大大提升了模型的训练和运行效率。
DBRX大约有1320亿个参数,Llama 2有700亿个参数,Mixtral 有450亿个,Grok有3140亿个。
但是,DBRX处理一个典型查询,平均只需激活约360亿个参数。这就提高了底层硬件的利用率,将将训练效率提高了30%到50%。不仅响应速度变快,还能减少所需的能源。
而与Mixtral、Grok-1等其他开源MoE模型相比,DBRX使用了更多的小型专家。
具体来说,DBRX有16个不同的专家,在每层为每个token选择4个专家。Mixtral和Grok-1有8个专家,一个路由网络在每层为每个token选择2个专家。
显然,DBRX提供了65倍的专家组合可能性,能够显著提升模型质量。
此外,DBRX还使用了旋转位置编码(RoPE)、门控线性单元(GLU)和分组查询注意力(GQA),并使用tiktoken存储库中提供的GPT-4分词器。
DBRX模型在12万亿Token的文本和代码进行预训练,支持的最大上下文长度为32k。

研究人员估计,这些数据比用来预训练MPT系列模型的数据至少好2倍。
这个新的数据集,使用全套数据库工具开发,包括用于数据处理的ApacheSpark™和Databricks笔记本,用于数据管理和治理的Unity Catalog,以及用于实验追踪的MLFlow。
团队使用了“课程学习”(curriculum learning)进行预训练,并在训练过程中改变数据组合,大大提高了模型质量。
那么,DBRX究竟表现如何?
1. 击败2.4倍参数的Grok-1
如下表1,在综合基准、编程和数学基准以及MMLU上,DBRX Instruct刷新了开源AI的SOTA。
(1)综合基准
研究人员在两个综合基准上对DBRX Instruct和其他开源模型进行了评估,一个是Hugging Face的Open LLM Leaderboard,另一个是Databricks Model Gauntlet。
Databricks Model Gauntlet由30多项任务组成,涵盖了6个类别:世界知识、常识推理、语言理解、阅读理解、符号问题解决和编程。
就综合基准来看,DBRX Instruct超越了所有聊天、指令调优的模型。
(2)编程和数学基准
DBRX Instruct在编程和数学方面尤为突出。
它在HumanEval以及GSM8k上,得分均高于其他开源模型。
在编程基准上,DBRX Instruct得分为70.1%,Grok-1为63.2%,LLaMA2-70B Chat为32.2%。在数学基准上,DBRX Instruct为66.9%,Grok-1为62.9%,LLaMA2-70B Base为54.1%。
尽管Grok-1的参数是DBRX的2.4倍,但DBRX在编程和数学方面的性能,均超越了排名第二的Grok-1。
在HumanEval上,DBRX Instruct(70.1%)甚至超过了CodeLLaMA-70B Instruct(67.8%),这是一个专门为编程构建的模型。
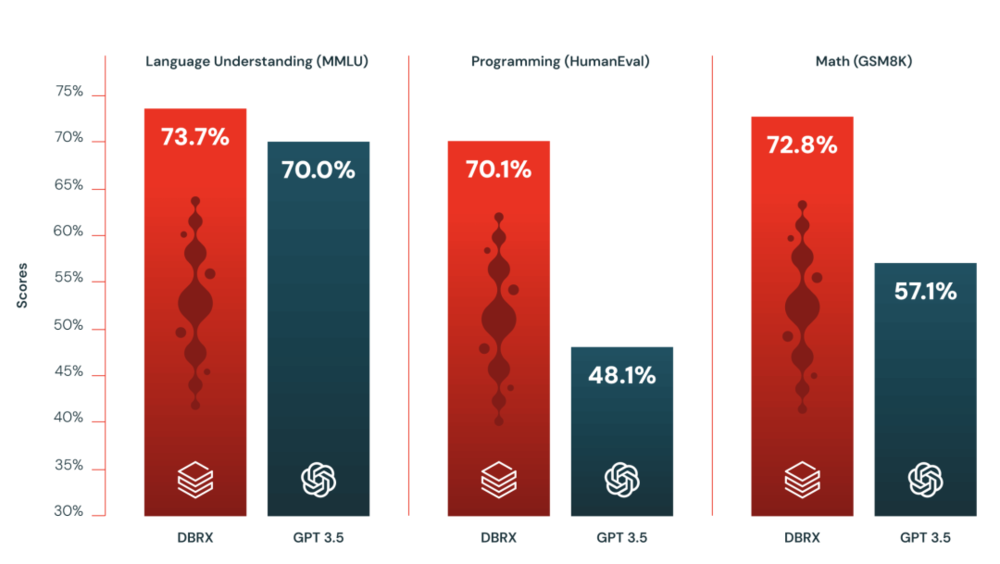
在语言理解测试基准MMLU方面,DBRX Instruct得分高于所有模型,为73.7%。

2. 全面超越GPT-3.5
另外,与闭源模型GPT-3.5相比,DBRX Instruct的性能全面超越了它,还可与Gemini 1.0 Pro和Mistral Medium相较量。
具体来说,DBRX Instruct在MMLU的常识知识(73.7% vs. 70.0%)、常识推理HellaSwg(89.0% vs. 85.5%)和WinoGrand(81.8% vs. 81.6%)方面优于GPT-3.5。
在HumanEval(70.1% vs. 48.1%)和GSM8k(72.8% vs. 57.1%)的测试中,DBRX同样在编程和数学推理方面尤其出色。
此外,在Inflection Corrected MTBench、MMLU、HellaSwag以及HumanEval基准上,DBRX Instruct的得分高于Gemini 1.0 Pro。
不过,Gemini 1.0 Pro在GSM8k的表现上,明显更强。
在HellaSwag基准上,DBRX Instruct和Mistral Medium得分相似,而Winogrande和MMLU基准上,Mistral Medium更强。
另外,在HumanEval、GSM8k、以及Inflection Corrected MTBench基准上,DBRX Instruct取得了领先优势。

在Databricks看来,开源模型击败闭源模型非常重要。
在上个季度,团队成员看到自家12,000多名客户群重大转变,即将专有模型替换为开源模型,以提高效率。现在,许多客户可以通过定制开源模型来完成特定任务,从而在质量和速度上超越专有模型。
DBRX的推出,就是为了加速这个过程。
3. 长上下文任务质量和RAG
DBRX Instruct采用高达32K token上下文进行了训练。
表3比较了它与Mixtral Instruct,以及最新版本的GPT-3.5 Turbo和GPT-4 Turbo API,在一套长上下文基准测试上的性能。
毫无疑问,GPT-4Turbo是执行这些任务的最佳模型。但是,除了一个例外,DBRX Instruct在所有上下文长度和序列的所有部分的表现,都优于GPT-3.5 Turbo。
DBRX Instruct和Mixtral Instruct的总体性能相似。

利用模型上下文的最常见的方法之一是,检索增强生成(RAG)。
在RAG中,从数据库中检索与提示相关的内容,并与提示一起呈现,从而为模型提供更多信息。
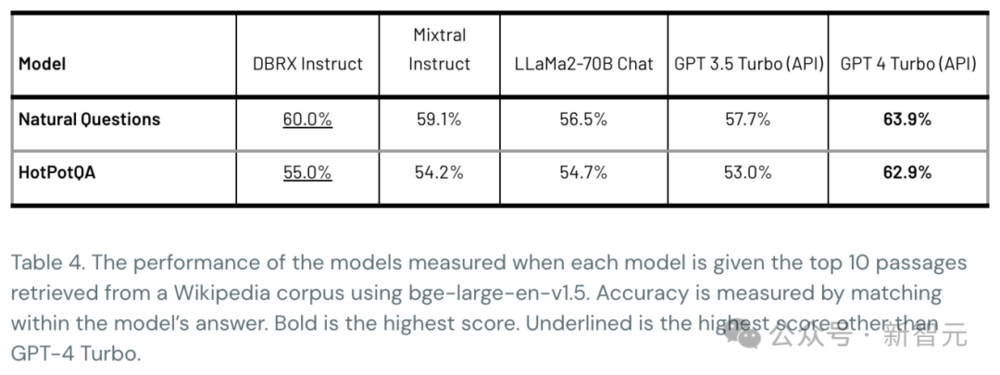
表4显示了DBRX在两个RAG基准测试——Natural Questions和HotPotQA上的质量。
DBRX Instruct与Mixtral Instruct和LLaMA2-70B Chat等开源模型,以及GPT-3.5 Turbo相比,具有很强的竞争力。
4. 训练效率是非MoE模型的两倍
模型质量必须放在模型的训练和使用效率的上下文中,在Databricks尤其如此,研究人员发现训练MoE模型在训练的计算效率方面,提供了实质性的改进(表5)。
比如,训练DBRX系列中较小的成员DBRX MoE-B(总参数为23.5B,活跃参数为6.6B)所需的Flop比LLaMA2-13B少1.7倍,才能在Databricks LLM Gauntlet上达到45.5%的得分。
DBRX MOE-B包含的有效参数也是LLaMA2-13B的一半。
从整体上看,端到端LLM预训练pipeline,在过去十个月中的计算效率提高了近4倍。
2023年5月5日,Databricks发布了MPT-7B,这是一个在1T token上训练的7B参数模型,在Databricks LLM Gauntlet上得分为30.9%。
DBRX系列中名为DBRX MoE-A的(总参数为7.7B,活跃参数为2.2B)得分为30.5%,而FLOPS减少了3.7倍。
这种效率是一系列改进的结果,包括使用MoE架构、网络的其他架构更改、更好的优化策略、更好的分词,以及更好的预训练数据。

单独来看,更好的预训练数据对模型质量有很大的影响。
研究人员使用DBRX预训练数据在1T token(称为DBRX Dense-A)上训练了7B模型。在Databricks Gauntlet上得分39.0%,而MPT-7B为30.9%。
研究者估计,全新的预训练数据至少比用于训练MPT-7B的数据高出2倍。换句话说,要达到相同的模型质量,所需的token数要少一半。
进而,研究人员通过在500B token上训练DBRX Dense-A确定了这一点。它在Databricks Gauntlet上的表现优于MPT-7B,达到32.1%。
除了更好的数据质量外,token效率提高的另一个重要原因可能是GPT-4分词器。
5. 推理效率
总体而言,MoE模型的推理速度,它们的总参数所显示的要快。这是因为它们对每个输入使用的参数相对较少。
DBRX推理吞吐量是132B非MoE模型的2~3倍。
推理效率和模型质量通常是相互矛盾的:模型越大通常质量越高,但模型越小推理效率越高。
使用MoE架构可以在模型质量和推理效率之间,实现比密集模型更好的平衡。

通过Mosaic AI Model Serving测量,DBRX生成速度明显快于LLaMA2-70B
比如,DBRX的质量比LLaMA2-70B更高,而且由于活跃参数量大约是LLaMA2-70B的一半,DBRX推理吞吐量最多可快2倍。
Mixtral是MoE模型改进的“帕累托最优”(pareto frontier)另一个点:它比DBRX小,质量相对较低,但实现了更高的推理吞吐量。
在优化的8位量化模型服务平台上,Databricks Foundation Model API推理吞吐量每秒多达150个token。

6. 企业免费用
企业可以在Databricks平台上访问DBRX,能在RAG系统中利用长上下文功能,还可以在自己的私有数据上构建定制的DBRX模型。
而开源社区可以通过GitHub存储库和Hugging Face访问DBRX。
项目地址:https://github.com/databricks/dbrx

项目地址:https://huggingface.co/databricks
因为DATABricks是完全基于数据库来构建DBRX的,因此每个企业用户都可以使用相同的工具和技术来创建或改进自己的定制化模型。
用户可以通过Unity Catalog中集中管理训练数据,使用ApacheSpark和Lilac AI提供的工具和服务进行处理和清理。
大规模的模型训练和微调由DataBricks前不久刚刚收购的Mosaic AI提供的服务。对齐问题,也可以通过的他们的平台和服务解决。
纳斯达克,埃森哲等客户和合作伙伴已经用上了这一套服务和工具。
二、收购估值13亿公司,2个月“肝”出来
外媒Wired的一篇报道,为我们详述了世界最强开源模型的诞生过程。

此前,Databricks在业界已经小有名声。
在本周一,Databricks的十几位工程师和高管,在会议室等待着最终的结果——团队花费了数月时间,投入了大概1000万美元训练的LLM,会取得怎样的成绩?
显然,能力测试最终结果出来之前,他们并不知道自己创造的模型有这么强大。
“我们超越了所有模型!”随着首席神经网络架构师、DBRX团队负责人Jonathan Frankle宣布这一结果,成员们爆发出热烈的欢呼和喝彩声。
是的,DBRX就是这样超越了Llama 2、Mixtral这两个如今最流行的开源模型。
甚至马斯克的xAI最近开源的Grok AI,也被DBRX打败了。Frankle开玩笑说:如果收到马斯克发出的一条刻薄的推特,我们就铁定成功了。
最令团队感到惊讶的是,DBRX在多项指标上甚至接近了GPT-4这个机器智能的巅峰之作。
毫无疑问,DBRX现在为开源LLM设立了全新的技术标准。
1. 独角兽重振开源界
通过开源DBRX,Databricks进一步推动了开源运动,加入了Meta对抗OpenAI和谷歌的开源大潮。
不过,Meta并没有公布Llama 2模型的一些关键细节,而Databricks会将最后阶段做出关键决策的过程全部公开,要知道,训练DBRX的过程,耗费了数百万美元。
艾伦人工智能研究所的CEO AliFarhadi表示,AI模型的构建和训练,亟需更大的透明度。
Databricks有理由选择开源。尽管谷歌等巨头过去一年里部署了AI,但行业内的许多大公司,还还没有在自己是数据上广泛使用大模型。
在Databricks看来,金融、医药等行业的公司渴望类似ChatGPT的工具,但又担心将敏感数据发到云上。
而Databricks将为客户定制DBRX,或者从头为他们的业务量身定做。对于大公司来说,构建DBRX这种规模模型的成本非常合理。
“这就是我们的大商机。”为此,Databricks去年7月收购了初创公司MosaicML,引入了Frankle在内的多名技术人才。此前,两家公司内都没人构建过如此大的模型。
2. 内部运作
OpenAI等公司,执着地追求更大的模型。但在Frankle看来,LLM重要的不仅仅是规模,怎样让成千上万台计算机通过交换机和光缆巧妙地连接在一起并且运转起来,尤其具有挑战性。
而MosailML公司的员工,都是这门晦涩学问的专家,因此Databrick去年收购它时,对它的估值高达13亿美元。
另外,数据对最终结果也有很大影响,或许也是因此,Databricks并没有公开数据细节,包括数据的质量、清洗、过滤和预处理。
Databricks副总裁、MosaicML创始人兼CEO Naveen Rao表示:“你几乎可以认为,这是模型质量的重中之重。”
3. 价值数百万美元的问题
有时候,训练一个庞大AI模型的过程不仅考验技术,还牵涉到情感上的抉择。
两周前,Databricks的团队就遇到了一个涉及数百万美元的棘手问题:如何充分利用模型的潜能。
在租用的3072个强大英伟达H100 GPU上训练模型两个月后,DBRX在多个基准测试中已经取得了卓越的成绩。但很快,他们可以使用的时间只剩下了最后一周。
团队成员在Slack上互抛主意,其中一个提议是制作一个专门生成计算机代码的模型版本,或者是一个小型版本供业余爱好者尝试。
团队还考虑了不再增加模型的大小,转而通过精心挑选的数据来提升模型在特定功能上的表现,这种方法称为课程学习。或者,他们可以继续按原计划扩大模型的规模,希望使其变得更加强大。
最后这种做法被团队成员亲切地称为“随它去”选项,似乎有人对此格外情有独钟。
虽然讨论过程中大家都保持了友好,但随着各位工程师为自己青睐的方案力争上游,激烈的观点交锋不可避免。
最终,Frankle巧妙地将团队的方向引向了以数据为中心的方法(课程学习)。两周后,这个决定显然带来了巨大的回报。
然而,对于项目的其他预期成果,Frankle的判断就没那么准确了。他原本认为DBRX在生成计算机代码方面不会有特别突出的表现,因为团队并没有将重点放在这一领域。
他甚至信心满满地表示,如果自己判断错误,就会把头发染成蓝色。然而,周一的结果却显示,DBRX在标准的编码基准测试上胜过了所有其他开源AI模型。
“我们的模型代码能力非常强。”他在周一的成果发布会上说道,“我已经预约了今天去染发。”
4. 风险评估
最后还有一个问题,就是开源模型的风险。
DBRX是迄今最强的开源大模型,任何人都可以使用或修改。这是否会带来不可预知的风险,比如被网络犯罪或者生化武器滥用?
Databricks表示,已经对模型进行了全面的安全测试。
Eleuther AI的执行主任Stella Biderman说,几乎没有证据表明开源会增加安全风险。“我们并没有特别的理由相信,开放模型会比现有的封闭模型大幅增加风险。”
此前,EleutherAI曾与Mozilla以及其他约50个组织和学者一道,向美国商务部长雷蒙多发出了一封公开信,要求她确保未来的人工智能监管为开源AI项目留出足够的发展空间。
信中专家们相信,AI开源有利于经济增长,因为它们有助于初创企业和小企业接触到这项突破性的进展,还有助于加速科学研究。
而这也是Databricks希望DBRX能够做出的贡献。
Frankle说,DBRX 除了为其他人工智能研究人员提供了一个新的模型和构建自己模型的有用技巧外,还有助于加深对AI实际工作原理的理解。
Databricks团队计划研究模型在训练的最后阶段是如何变化的,也许能揭示一个强大的模型是如何涌现出额外能力的。
参考资料:
https://www.wired.com/story/dbrx-inside-the-creation-of-the-worlds-most-powerful-open-source-ai-model/
https://twitter.com/databricks/status/1772957294805856265?t=yM4Rma8C9RQPCmf0YoopMw&s=19
https://www.databricks.com/blog/introducing-dbrx-new-state-art-open-llm
本文来自微信公众号:新智元 (ID:AI_era),作者:新智元

 05:44
05:44









 07:13
07:13
 06:21
06:21
 11:57
11:57
 13:10
13:10
 09:52
09:52
 12:49
12:49
 05:19
05:19
 14:24
14:24
 12:03
12:03


