2024-04-01 22:15


扫码打开虎嗅APP

本文来自微信公众号:机器之心 (ID:almosthuman2014),作者:机器之心编辑部,原文标题:《吴恩达:别光盯着GPT-5,用GPT-4做个智能体可能提前达到GPT-5的效果》,题图来自:视觉中国
AI 智能体是去年很火的一个话题,但是 AI 智能体到底有多大的潜力,很多人可能没有概念。
最近,斯坦福大学教授吴恩达在演讲中提到,他们发现,基于 GPT-3.5 构建的智能体工作流在应用中表现比 GPT-4 要好。当然,基于 GPT-4 构建的智能体工作流效果更好。由此看来,AI 智能体工作流将在今年推动人工智能取得巨大进步,甚至可能超过下一代基础模型。这是一个值得所有人关注的趋势。

这个关于智能体的演讲在社交媒体上引发了广泛关注。有人表示,这代表着 AI 发展中的范式转变,体现了从静态输出到动态迭代的转变。站在这样一个十字路口,我们不仅要思考 AI 如何改变我们的工作,还要思考我们如何适应它所创造的新环境。

还有人说,这和自己的生活经验是相通的:有些人可以凭借良好的流程胜过那些比自己聪明的人。

那么,智能体的这种效果是怎么实现的呢?
和传统的 LLM 使用方式不同,智能体工作流不是让 LLM 直接生成最终输出,而是多次提示(prompt)LLM,使其逐步构建更高质量的输出。
在演讲中,吴恩达介绍了 AI 智能体工作流的四种设计模式:

反思(Reflection):LLM 检查自己的工作,以提出改进方法。
工具使用(Tool use):LLM 拥有网络搜索、代码执行或任何其他功能来帮助其收集信息、采取行动或处理数据。
规划(Planning):LLM 提出并执行一个多步骤计划来实现目标(例如,撰写论文大纲、进行在线研究,然后撰写草稿......)。
多智能体协作(Multi-agent collaboration):多个 AI 智能体一起工作,分配任务并讨论和辩论想法,以提出比单个智能体更好的解决方案。
在后续的博客中,吴恩达重点讨论了反思(Reflection)模式。吴恩达表示:“反思模式是实现速度相对较快的设计模式,它已经带来了惊人的性能提升效果。”

他在博客中写道:
我们可能都有过这样的经历:提示 ChatGPT/Claude/Gemini,得到不满意的输出,提供关键反馈以帮助 LLM 改进其响应,最终获得更好的响应。
如果将关键反馈的步骤交付给自动化程序,让模型自动批评自己的输出并改进其响应,结果会怎样?这正是反思模式的关键。
以要求 LLM 编写代码为例。我们可以提示它直接生成所需的代码来执行某个任务 X。之后,我们可以提示它反思自己的输出,如下所示:
这是任务 X 的代码:[之前生成的代码]
仔细检查代码的正确性、风格和效率,并对如何改进它提出建设性意见。
有时这会使 LLM 发现问题并提出建设性意见。接下来,我们可以用上下文 prompt LLM,包括:
以前生成的代码;
建设性的反馈;
要求它使用反馈来重写代码。
这可以让 LLM 最终输出更好的响应。重复批评 / 重写过程可能会产生进一步的改进。这种自我反思过程使 LLM 能够发现差距并改善其在各种任务上的输出,包括生成代码,编写文本和回答问题。

我们可以通过给 LLM 提供工具来帮助其评估产出。例如,通过几个测试用例来运行代码,以检查是否在测试用例上生成正确的结果,或者搜索网页以检查文本输出。然后,LLM 可以反思它发现的任何错误,并提出改进的想法。
此外,我们可以使用多智能体框架来实现反思。创建两个不同的智能体很方便,一个提示生成良好的输出,另一个提示对第一个智能体的输出给出建设性的批评。两个智能体之间的讨论推动了响应的改进。
反思是一种相对基本的智能体工作流模式,但它在一些情况下显著改善了应用程序的结果。
最后,关于反思,吴恩达推荐了几篇论文:
“Self-Refine: Iterative Refinement with Self-Feedback,” Madaan et al., 2023
“Reflexion: Language Agents with Verbal Reinforcement Learning,” Shinn et al., 2023
“CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing,” Gou et al., 2024
在下文中,我们整理了本次演讲的内容。
吴恩达:AI 智能体的未来
我很期待与大家分享我在 AI 智能体中所看到的。我认为这是一个令人兴奋的趋势。我认为每个 AI 从业者都应该关注这个趋势。

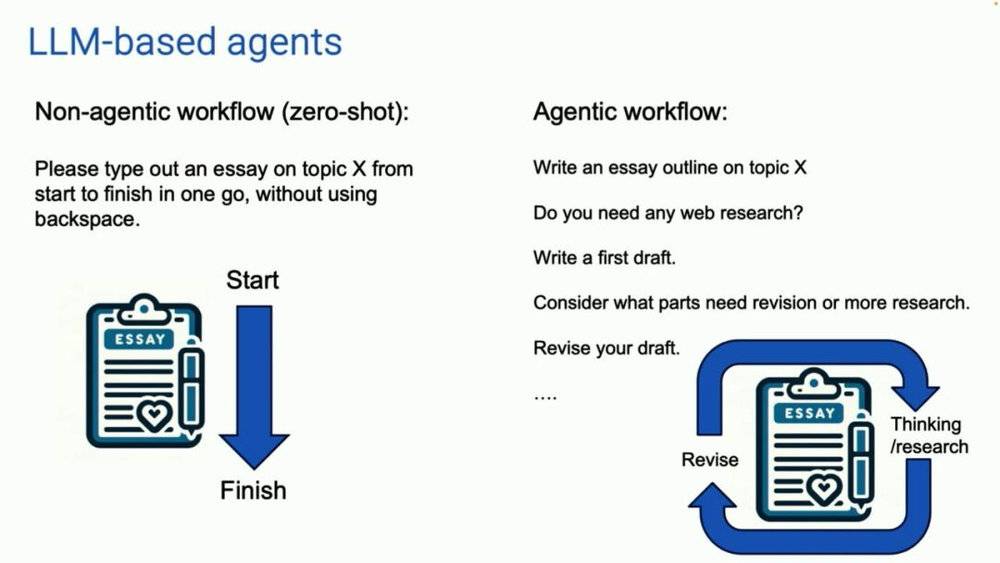
我要分享的是 AI 智能体。现在,我们大多数人使用大型语言模型的方式是这样的:我们在一个非智能体工作流中,你把提示输入到对话框中并生成答案。这有点像是我们让一个人写一篇关于某个主题的文章。我说,请坐到键盘前,从头到尾打出一篇文章,中间不使用退格键。尽管这很难,AI 大模型还是做得非常好。
智能体工作流长这个样子(右图)。有一个 AI 大模型,你可以让它写一份论文大纲。你需要上网查资料吗?如果需要,我们就联网。然后写初稿、读初稿,并思考哪些部分需要修改。然后修改你的初稿并继续推进。所以这个工作流程更容易迭代。你可以让 AI 大模型进行一些思考,然后修改这篇文章,然后继续思考和迭代。按照这个步骤迭代多次。
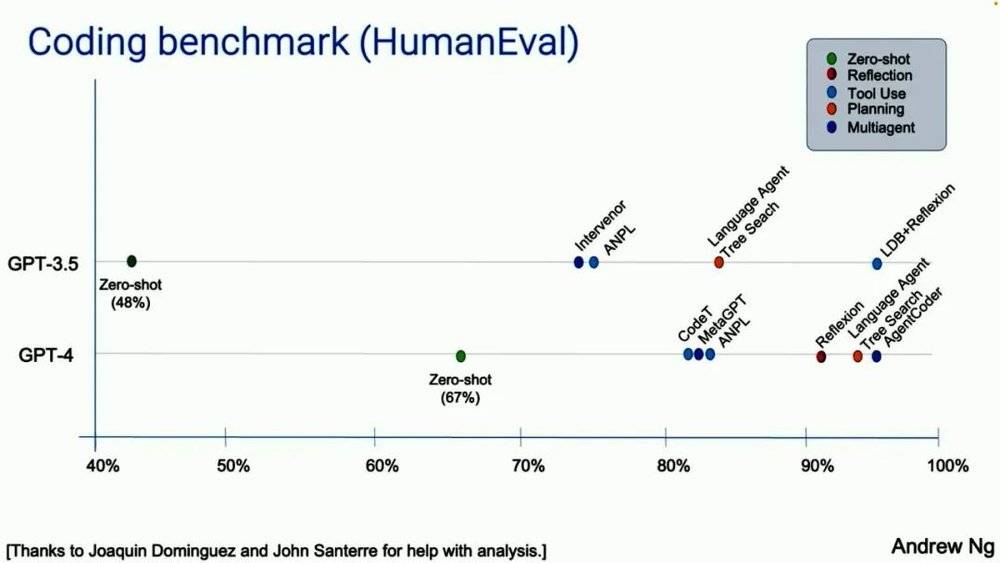
很多人都没有意识到的是,这么做的效果好得多。其实我自己也很惊讶。对于它们的工作决策流程,以及它们优秀的表现。除了这些个案研究,我的团队也分析了一些数据,使用名为 HumanEval 的编程评估基准。这是 OpenAI 几年前发布的。这上面有一些编程问题,比如给定一个非空整数列表,返回位于偶数位置的所有奇数元素的和。AI 生成的答案是像这样的代码片段。

如今我们很多人会使用零样本提示。比如我们告诉 AI 编写代码,并让它在第一个位置运行。谁这样编码?没有人这样写代码。我们只需输入代码并运行它。也许你这么编码,但我做不到。事实证明,如果你使用 GPT-3.5,在零样本提示的条件下,GPT-3.5 的准确率是 48%。GPT-4 要好得多,达到了 67%。但如果你采用的是智能体工作流,并将其打包,GPT-3.5 实际上能表现更好,甚至比 GPT-4 还好。如果你围绕 GPT-4 构建这样的工作流,GPT-4 也能表现很好。注意,处于智能体工作流中的 GPT-3.5 实际上优于 GPT-4。我认为这已经是一个信号。
所有人都在围绕智能体这个术语和任务进行大量的讨论。有很多咨询报告,关于智能体、AI 的未来,等等等等。我想具体一点,分享一下我在智能体中看到的广泛设计模式。这是一个非常混乱、混沌的空间。有很多研究,有很多事情正在发生,我尝试更具体地分一下类,更具体地聊一下智能体领域发生的事情。

reflection(反思)是一种工具,我认为我们中的许多人都在使用。它很有效。我认为“tool use”得到了更广泛的认可,但 reflection 实际上效果也很好。我认为它们都是非常强大的技术。当我使用它们时,我几乎总能让它们工作得很好。规划和多智能体协作,我认为属于正在兴起的技术。在使用它们时,有时我对它们的工作效果感到震惊。但至少在目前这个时刻,我觉得我无法让它们总是可靠地工作。
接下来我将详细解释这四种设计模式。如果你们中的一些人回去自己用,或者让你们的工程师使用这些模式,我认为你可以很快获得生产力的提升。
首先是 reflection,举个例子:假设我问一个系统,请为我编写给定任务的代码。然后我们有一个代码智能体,只是一个接受你编写的提示的大模型。它会写一个如图所示的函数。这里还有一个 self reflection 的例子。如果你给你的大模型写出这样的提示,告诉它这是用于执行某个任务的代码,把你刚刚生成的代码给它,然后让它检查这段代码的正确性、效率等等类似的问题。
结果你会发现,根据你的提示写出代码的那个大模型,可能能够发现代码里的问题,比如第五行的 bug。还会告诉你怎么修改。如果你现在采纳了它的反馈并再次给它提示,它可能会提出一个比第一个版本更好的第二版代码。不能保证一定如此,但它是有效的。这种方法在很多应用中都值得尝试。

这里提前说一下 tool use。如果你让它运行单元测试,而它没有通过,你想知道为什么没通过。进行这样的对话,也许能找出原因。这样你就能试着去改正。顺便说一下,如果大家对这些技术感兴趣,我在每一部分的幻灯片底部都写了一个小小的推荐阅读部分,就在 PPT 底部。里面有更多的参考资料。
这里提前说一下多智能体系统。它被描述为单个代码智能体,你给它提示,让它们进行对话。这种想法的一个自然演变是单个编程智能体。你可以有两个智能体,其中一个是编码智能体,另一个是评价智能体。它们背后的大模型可能是同一个,但你给它们的提示不一样。我们对其中一个说,你是写代码的专家,负责编写代码。对另一个说,你是审核代码的专家,负责审核这段代码。这种工作流实际上很容易实现。我认为这是一种非常通用的技术,适用于很多工作流。这将为大型语言模型的性能带来显著的提升。

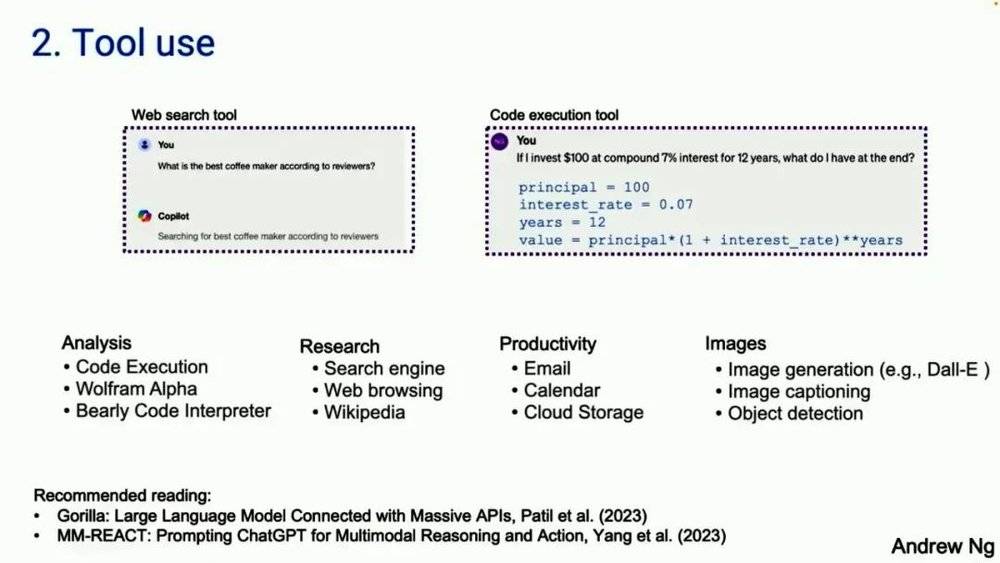
第二种设计模式是 tool use(工具使用)。许多人可能已经见过基于大模型的系统使用工具。左边是一个截图,来自 Copilot。右边的截图,来自 GPT-4。左边的问题是,网上最好的咖啡机是哪个?Copilot 会通过上网检索来解决一些问题。GPT-4 将会生成代码并运行代码。
事实证明,有很多不同的工具被人们用于分析、收集信息以采取行动、提高个人生产力。很多早期工作关于 tool use 的工作,原来都是在计算机视觉社区。因为之前,大型语言模型对图像无能为力,所以唯一的选择就是大模型生成一个函数调用,可以用来操作图像,比如生成图像或者做目标检测什么的。让我们看看文献,有趣的是,tool use 领域的很多工作似乎都起源于视觉社区,因为之前的大模型不会看图像,在 GPT-4V、LLaVA 等模型出现之前。这就是 tool use,它扩展了大型语言模型的能力。
接下来讲 planning(规划)。对于没有大量接触过规划算法的人来说,我觉得很多人在谈论 ChatGPT 时刻的时候,你会觉得,“哇,从未见过这样的东西”。我想你还没有使用过规划算法。很多人看到 AI 智能体会很惊讶,“哇,我没想到 AI 智能体能做这些”。在我进行的一些现场演示中,有些演示会失败,AI 智能体会重新规划路径。我实际上经历过很多这样的时刻,“哇,我不敢相信我的 AI 系统刚刚自动做到了这一点”。
其中一个例子是从 HuggingGPT 论文中改编的。你输入的是:请生成一张图像,一个女孩在看书,她的姿态和图像中的男孩一样。然后用你的声音描述这张新图像。给定一个这样的例子,今天有了 AI 智能体,你可以确定第一件要做的事是确定男孩的姿态。然后找到合适的模型,也许在 HuggingFace 上能找到,提取姿态。接下来需要找到一个姿态图像模型,遵循指令生成一张女孩的图像。然后使用图像 - 文本模型得到描述。最后使用文本转语音模型读出描述。

我们今天已经有了 AI 智能体,我不想说它们工作可靠,它们还有点挑剔,并不总是好用。但当它们起作用时,实际上效果是非常惊人的。
有了智能体循环,有时你可以改掉前期的问题。我自己已经在使用研究智能体了。对于我的一些工作,我并不想自己花很多时间进行谷歌搜索。我会把需求发给 AI 智能体,几分钟后回来看看它做了什么。它有时有效,有时不行。但那已经是我个人工作流的一部分。
最后要讲的模式是多智能体协作。这部分很有趣,它的效果比你想象的要好得多。左边这张图来自一篇名为 ChatDev 的论文。它是完全开源的,你们中的许多人都在社交媒体上看过 Devin 的演示。ChatDev 是开源的,它在我的笔记本电脑上运行。
ChatDev 是多智能体系统的一个实例。你可以给它一个提示,它有时扮演软件引擎公司的 CEO,有时扮演设计师,有时又是产品经理,有时是测试人员。这群智能体是你通过给大模型提示来构建的,告诉它们“你现在是 CEO / 你现在是软件工程师”。他们会协作,会进一步对话。如果你告诉它们,“请开发一款游戏”,它们会花几分钟写代码,然后进行测试、迭代,然后生成一个令人惊讶的复杂程序,虽然并不总是能运行。我已经试过了,有时生成结果用不了,有时候又很惊艳。但是这项技术真的越来越好了。这是其中一种设计模型。此外,事实证明,多智能体辩论(你有多个智能体),比如说,你可以让 ChatGPT 和谷歌的 Gemini 辩论,这实际上会带来更好的性能。因此,让多个相似的 AI 智能体一起工作,也是一个强大的设计模式。

总结一下,这些是我看到的模式。我认为如果我们在我们的工作中使用这些模式,我们中的很多人可以很快获得实践上的提升。我认为智能体推理设计模式将会非常重要。这是我的简要 PPT。我预计,今年 AI 能做的事情将大幅扩展,这得益于智能体工作流。

有一件事实际上很困难,就是人们需要习惯在输入提示之后,我们总想立即得到结果。实际上,十几年前,当我在谷歌讨论 big box search 时,我们输入了一个很长的提示。我没有成功推动这一项目的一个原因是,在进行网络搜索时,你想在半秒钟内得到回复。这是人性使然 —— 我们喜欢即时获取、即时反馈。但是对于很多 AI 智能体工作流来说,我想我们需要学会分配任务给 AI 智能体,并耐心地等待几分钟,甚至几小时,等它给出回应。我见过很多新晋管理者,将某事委托给某人,然后五分钟后检查结果。这不是一种有效的工作方式。我想我们需要,这真的很难。我们也需要对我们的 AI 智能体多点耐心。
另一个重要的事情是,快速的 token 生成是非常重要的。因为用这些 AI 智能体,我们一遍又一遍地迭代。AI 生成供人阅读的 token。如果 AI 生成 token 的速度比任何人的阅读速度都快,那就太棒了。我认为,快速生成更多 token,即使用的是质量稍低的大模型,也能带来很好的结果。与用更好的大模型慢慢生成 token 相比,或许这点是有争议的。因为它可能让你在这个循环中反复更多次。这有点像我在前面的幻灯片上展示的大模型和智能体架构的结果。
坦率地说,我非常期待 Claude 4、GPT-5 和 Gemini 2.0,以及其他正在构建的出色大模型。我感觉,如果你期待在 GPT-5 上运行你的任务,以零样本的方式,你可能在一些 AI 智能体应用上接近那个水平的性能,这可能超乎你的想象,有了智能体推理,再加上之前发布的大模型。我认为这是一个重要的趋势。老实说,通往 AGI 的道路感觉更像是一段旅程而不是目的地,我认为这套智能体工作流可以帮助我们在这漫长的旅程中向前迈出一小步。
参考链接:
https://www.deeplearning.ai/the-batch/issue-242/
https://zhuanlan.zhihu.com/p/689492556
https://www.youtube.com/watch?v=sal78ACtGTc&t=108s
本文来自微信公众号:机器之心 (ID:almosthuman2014),作者:机器之心编辑部

 13:10
13:10








 06:21
06:21
 20:24
20:24
 27:05
27:05
 07:13
07:13
 32:45
32:45
 05:53
05:53
 03:40
03:40
 09:39
09:39
 07:12
07:12


