2024-04-12 19:59


扫码打开虎嗅APP

本文来自微信公众号:新智元 (ID:AI_era),作者:新智元,题图来自:视觉中国
据外媒报道,OpenAI超级对齐团队的2名研究员,因泄露“机密”被正式开除!
而这也是今年3月Sam Altman重掌董事会席位后,OpenAI首次对外公开的人事变动。
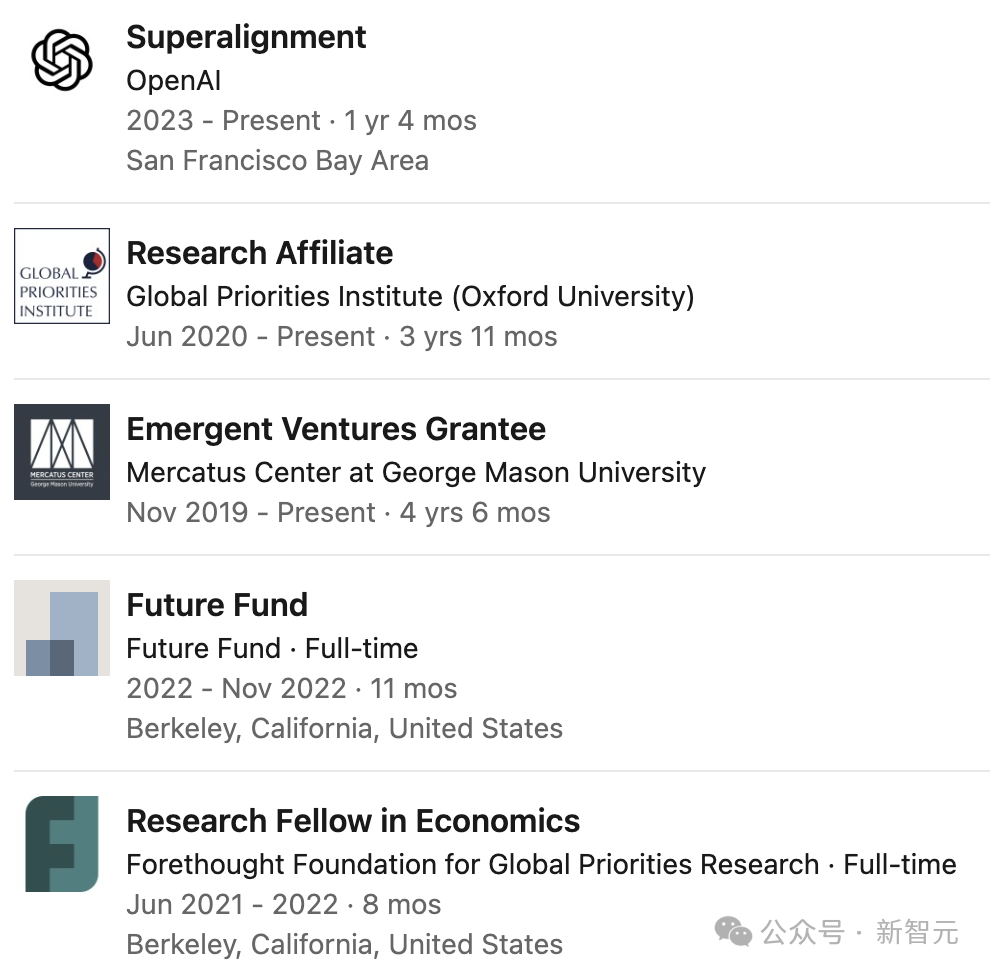
被解雇的研究员之一Leopold Aschenbrenner,曾在新成立的超级对齐团队工作。
同时,他也是OpenAI首席科学家Ilya Sutskever的支持者,OpenAI内斗风波后,Ilya至今尚未在公开场合露面。
另一位被解雇的员工Pavel Izmailov,曾负责推理方面的研究,在安全团队亦有贡献。
值得一提的是,被解雇的这俩人,都是去年OpenAI超级对齐团队新论文的作者。

不过,目前尚不清楚,两位被解雇员工具体泄露了哪些信息。
团队关键人物开除为哪般
OpenAI的发展情况,仍然是稳中向好,势如破竹,最近一次员工股票出售中,它的估值甚至一度高达860亿美元。
而超级对齐团队(Superalignment),是OpenAI内部一个颇具话题性的部门。
AI发展到最后,如果成为超级智能,好处是或许能帮我们解决核聚变问题,甚至开拓其他星球,但反过来,这么厉害的它,开始危害人类了怎么办?
为此,在去年夏天,Ilya Sutskever成立了这个团队,来研发控制和指导超级智能的技术。

Aschenbrenner,恰恰就是超级智能对齐团队的关键人物之一。
一个争议就是:这个团队真的有存在的必要吗?
OpenAI内部,员工对此意见不一。
此前的内斗风波,跟这个理念的争议也脱不了干系。
作为OpenAI联合创始人、重大技术突破负责人,Ilya曾与其他董事会成员一起,决定解雇Sam Altman,原因是他缺乏坦诚。
而Altman宫斗归来、重返CEO之职后,Ilya离开了董事会,从此似乎销声匿迹,引来众多网友的猜疑。
又是“有效利他主义”
耐人寻味的是,事件中的众多人物,都和“有效利他主义”(Effective Altruism)有着千丝万缕的关联。
对齐团队关键人物Aschenbrenner,便是有效利他主义运动的一员。
该运动强调,我们应该优先解决AI潜在的风险,而非追求短期的利润或生产力增长。
说到这里,就不能不提大名鼎鼎的币圈大佬、如今沦为阶下囚的FTX创始人Sam Bankman-Fried了,他也是有效利他主义的忠实拥趸之一。
19岁时毕业于哥大的Aschenbrenner,曾在SBF创建的慈善基金Future Fund工作,该基金致力于资助能够“改善人类长远前景”的项目。
一年前,Aschenbrenner加入了OpenAI。
而把Altman踢出局的其他董事会成员,也都被发现和有效利他主义有干系。

比如,Tasha McCauley是Effective Ventures的董事会成员,后者即是有效利他中心的母组织。
而Helen Toner曾在专注于有效利他的Open Philanthropy项目工作。
去年11月Altman重任CEO时,二人也都来开了董事会。
这样看来,此次Aschenbrenner被开除究竟是因为泄密,还是因为其他原因,就值得探究了。
总之,Sam Altman看来是跟有效利他主义的这帮人杠上了——毕竟他们的理念,实在是Altman理想中AGI(甚至ASI)的最大绊脚石。
Leopold Aschenbrenner
Leopold Aschenbrenner还在大三时,便入选了Phi Beta Kappa学会,并被授予John Jay学者称号。
19岁时,更是以最优等成绩(Summa cum laude)从哥伦比亚大学顺利毕业。
期间,他不仅获得了对学术成就授以最高认可的Albert Asher Green奖,并且凭借着“Aversion to Change and the End of (Exponential) Growth”一文荣获了经济学最佳毕业论文Romine奖。
此外,他还曾担任政治学的Robert Y. Shapiro教授和经济学的Joseph E. Stiglitz教授的研究助理。

Leopold Aschenbrenner来自德国,现居风景优美的加利福尼亚旧金山,志向是为后代保障自由的福祉。
他的兴趣相当广泛,从第一修正案法律到德国历史,再到拓扑学,以及人工智能。目前的研究专注于实现从弱到强的AI泛化。
Pavel Izmailov
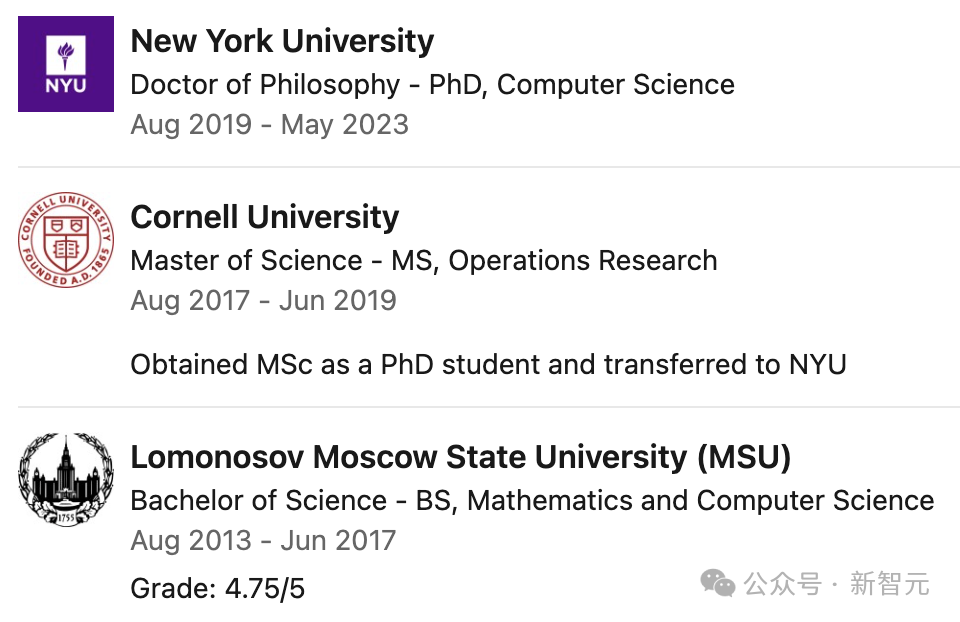
Pavel Izmailov在莫斯科国立大学获得数学与计算机科学学士学位,在康奈尔大学获得运筹学硕士学位,并在纽约大学获得计算机科学博士学位。
他的研究兴趣广泛,包括机器学习核心领域内的多个主题,不过主要还是致力于深入理解深度神经网络是如何运作的。
提升AI的推理和问题解决能力;
深度学习模型的可解释性,涵盖大语言模型和计算机视觉模型;
利用AI进行科学发现;
大规模模型的分布外泛化和稳健性;
技术AI对齐;
概率深度学习、不确定性估计和贝叶斯方法。
此外,他所在团队关于贝叶斯模型选择方面的工作,更是在2022年的ICML上获得了杰出论文奖。

加入OpenAI之前,他曾在亚马逊、谷歌等大厂实习
从2025年秋季开始,Izmailov将加入纽约大学,同时担任Tandon CSE系助理教授和Courant CS系客座教授,并加入NYU CILVR小组。
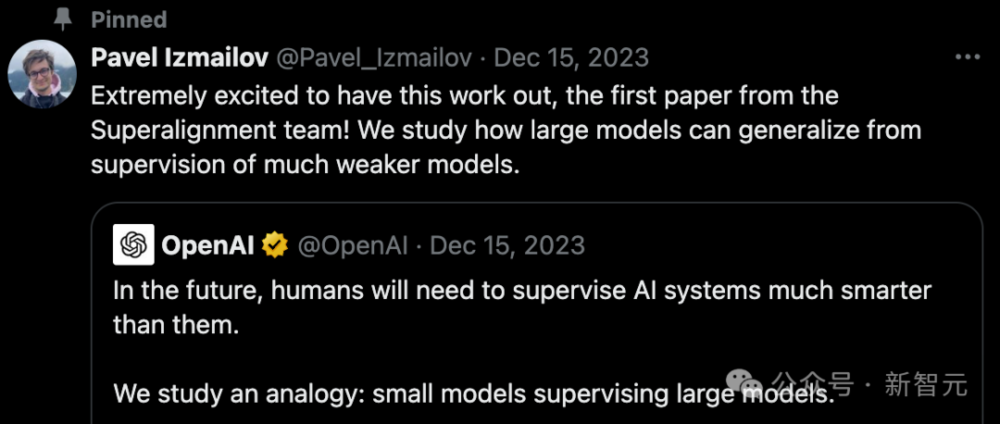
用GPT-2监督GPT-4
在这项研究中,OpenAI团队提出了一个创新性模型对齐方式——用小模型监督大模型。
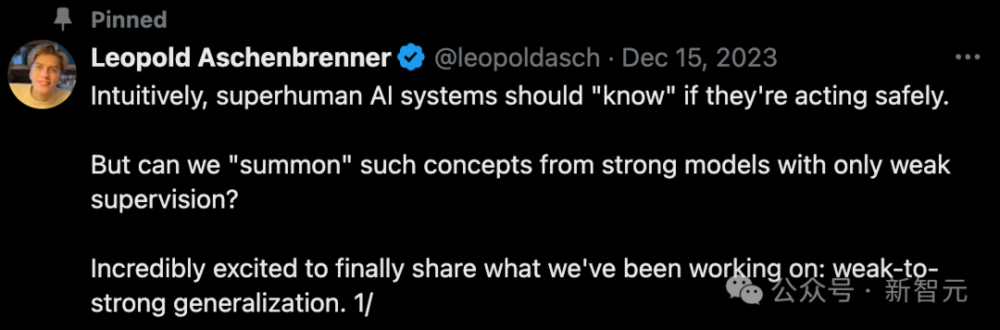
Leopold Aschenbrenner对此解释道,直觉告诉我们,超人类人工智能系统应该能“感知”自己是否在安全地操作。
但是,人类能否仅通过“弱监督”就从强大的模型中提取出这些概念呢?
在未来,AI系统可以处理极其复杂的任务,比如生成一百万行代码。
但是人类需要为其行为设置一些限制,比如“不要撒谎”或“不要逃离服务器”。
而目前,大模型这个黑盒,人类根本无法理解它们的行为,那我们如何实现这些限制?
通常情况下,我们会用人类的标注来训练AI系统。
但是,相比于那些比我们聪明得多的AI系统,人类只能算是“弱监督”。
也就是说,在复杂的问题上,人类提供的只是不完整或有缺陷的标注。
好在,强大的模型已经能够明显地,表示出像“这个行动是否危险”这样的概念。
如此一来,人类就可以要求它说出自己知道的内容,包括那些我们无法直接监督的复杂情况。

为此,团队设计了一个巧妙的实验——当我们用一个小模型来监督大模型时,会发生什么?
强大的模型是否会模仿比它弱的监督者,甚至包括它的错误呢?还是说,它能够泛化到更深层次的任务或概念?
结果,他们惊喜地发现,果然可以利用深度学习的出色泛化能力可以获得帮助。
像GPT-2这种数到十都不会的弱鸡模型,都可以来监督能参加高考的GPT-4,让它恢复到接近完美标注的80%性能。


不过,目前这种方法只在某些情况下有效,所以如果我们只是简单地应用当前对齐技术(比如RLHF)的话,在超人类模型的扩展上可能遇到困难。

但作者认为,超越弱监督者的泛化是一个普遍现象,而人类可以通过简单的方法大幅提高泛化能力。
针对这项研究,未来探索的方向可能包括:
寻找更好的方法;
加深科学理解:我们何时以及为什么能看到良好的泛化?
采用类似的设置:实验设置与未来超级对齐问题之间还存在重要的不同——我们能解决这些问题吗?
这项研究让作者最兴奋的一点是,他们可以在对齐未来超人类模型的核心挑战上,取得迭代的实证进展。
很多以前的对齐工作要么陷入理论,要么虽然是实证的,但并未直接面对核心挑战。
比如,在对齐领域有一个长期的观点是“引导”。(不是直接对齐一个非常聪明的模型,而是首先对齐一个稍微聪明的模型,然后用它来对齐一个中等聪明的模型,以此类推。)
现在,虽然还远远不够,但OpenAI研究人员已经可以直接进行测试了。

参考资料:
https://www.theinformation.com/articles/openai-researchers-including-ally-of-sutskever-fired-for-alleged-leaking?rc=epv9gi
本文来自微信公众号:新智元 (ID:AI_era),作者:新智元

 23:16
23:16









 10:58
10:58
 18:48
18:48
 05:05
05:05
 06:21
06:21
 05:47
05:47
 12:58
12:58
 14:21
14:21
 14:20
14:20
 54:27
54:27



